想象你在训练一个能熟练操作命令行的 AI Agent。直觉可能会告诉你:给它塞越多的练习任务,它的能力就会越强。但腾讯混元团队最新的研究却揭示了一个反直觉的结论:决定训练效果的关键,并不在于任务数量,而在于 AI 在执行过程中经历了多少种 不同的场景与技能组合。

他们构建了一张包含 8.2 万个场景节点 与 5.7 万项技能 的“技能图谱”。通过从这张图中采样出多样化的工作流路径来生成训练任务,成果非常显著:使用该方法训练的 Qwen3-32B(320亿参数)在权威终端 Agent 基准 Terminal-Bench 2.0 上斩获了 29.6% 的得分,直接超越了参数量是它 15 倍的 Qwen 3 Coder 480B(23.9%)。
这似乎说明,在 人工智能 的落地训练中,“多样性”正在碾压“参数量”。
问题核心:堆砌任务数量,却忽略了轨迹多样性
终端 Agent 是指由大语言模型驱动、通过命令行界面完成复杂任务的 AI 系统。训练此类 Agent,依赖海量的“执行轨迹”——也就是 AI 在终端中逐步操作的完整记录。
现有的合成训练数据主要走两条路:
- 让 LLM 生成分类体系以扩展领域覆盖,但这往往与现实使用场景脱节。
- 从 GitHub 仓库反推任务,但这又被局限在软件工程场景。
两条路都只关心“生成了多少任务”,却完全没有控制 AI 在这些任务里到底经历了多少种“场景×技能”的组合。
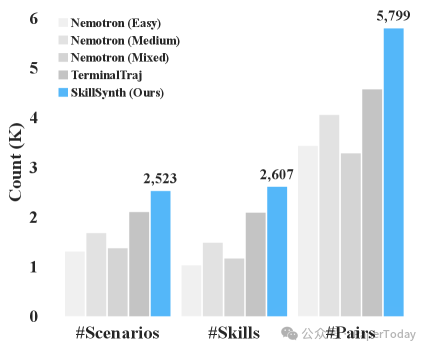
轨迹多样性对比
论文用数据直白地展示了这个痛点:现有数据集中,不同任务让 Agent 经历的场景和技能高度重叠,轨迹冗余极其严重。这就好比让一个学生刷了一万道题,结果发现全是同一个知识点的简单重复,自然收效甚微。
核心解法:用图谱结构控制训练轨迹的多样性
SkillSynth 的核心思路,是将 AI 操作终端的过程抽象为“场景-技能”序列。
- 场景:AI 在某决策点面临的状态(例如“视频文件已下载但未压缩”)。
- 技能:AI 在该状态下执行的一组动作(例如“用 ffmpeg 压缩视频”)。
每个技能都从一个“前置场景”指向一个“后置场景”,由此组成一张有向图。图中的任意一条完整路径,就对应了一个真实的多步骤工作流。
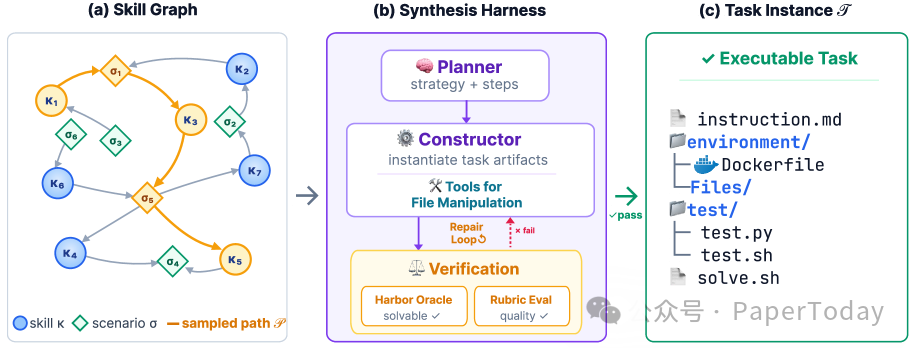
这张图谱的规模相当可观:82,073 个场景节点、57,214 条技能边,以及 185,529 个由 LLM 验证的桥接关系。其中 85.6% 的节点都连通在最大连通分量中,这意味着绝大多数技能都能被串联成完整的工作流,而不是碎片化的单步操作。
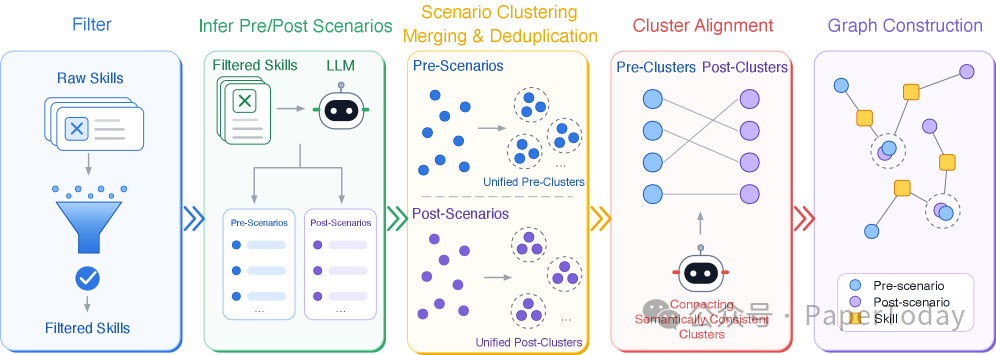
整个构建过程分为五步:从 ClawHub 和 GitHub 过滤技能 → LLM 推断每个技能的前置/后置场景 → 聚类去重 → 跨技能对齐(使得后置场景能精确匹配下一个技能的前置场景)→ 合并过滤。
采样策略同样是关键的一环:它采用了 逆频率加权 机制。这意味着那些被访问得少的节点和边会被优先选中,从而有效避免了路径扎堆在热门节点上,确保采样路径在“场景×技能”空间里覆盖得更加均匀。
自动生成:多 Agent 协作,单次跑出 3560 个验证任务
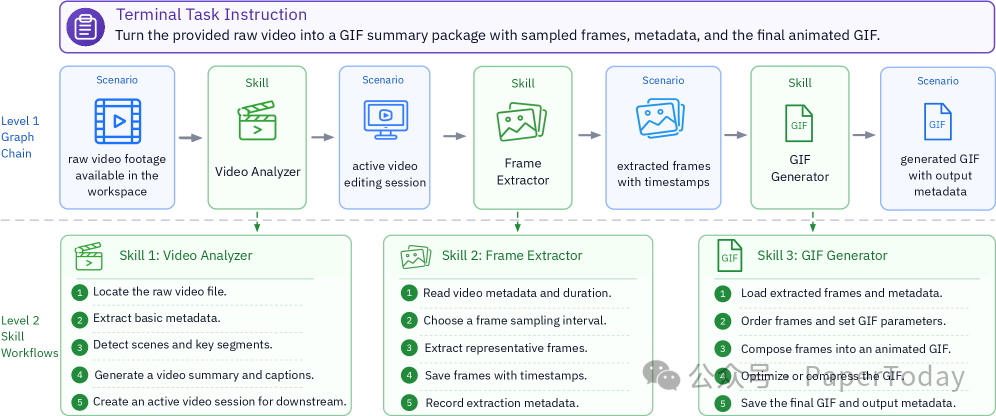
采样出抽象路径后,一个多 Agent 协作流程会将其变为可执行的具体任务:
- 规划器将路径转换为结构化的子目标和预期输出。
- 构造器根据计划生成完整的任务实例,包括指令、文件系统快照、容器环境、验证脚本及参考解法。
- 双验证机制:执行验证(跑参考解法确保任务可解)+ 评分验证(LLM 判断指令和测试是否对齐)。
- 若验证不通过,则会进入修复循环,最多进行 3 轮修复,每轮最多允许 20 次工具调用。
一次全自动运行的“成绩单”如下:从 3,721 条采样路径中,成功产出了 3,560 个通过严格验证的任务实例,Oracle 通过率高达 95.7%,而每个任务的平均生成成本仅为 $27.3。这些任务的难度可不低——哪怕是 Claude Opus 4.6,平均也得需要 37 步 才能解决,其中有 121 个任务在三次尝试中都未能攻克。
实验结果:多样性,始终优于单纯的数量
核心对比数据清楚地展示了 SkillSynth 的领先:
| 方法 |
TB 1.0 |
TB 2.0 |
| Qwen3-8B + 单技能 |
8.7% |
5.3% |
| Qwen3-8B + 随机多技能 |
13.4% |
11.6% |
| Qwen3-8B + SkillSynth |
17.1% |
13.5% |
| Qwen3-32B + 单技能 |
25.4% |
21.3% |
| Qwen3-32B + 随机多技能 |
30.8% |
25.8% |
| Qwen3-32B + SkillSynth |
33.8% |
29.6% |
| Qwen 3 Coder 480B(未用 SkillSynth) |
— |
23.9% |
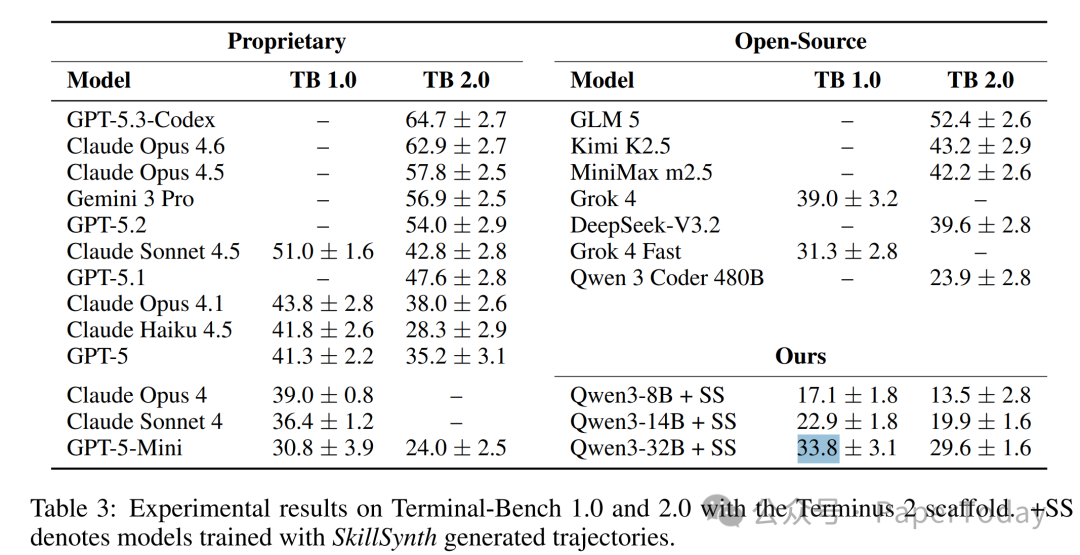
在 TB 1.0 上,SkillSynth 比单技能基线高出 8.4 分,比随机组合多技能基线高 3.0 分。如果单纯看多样性指标,结果会更直观:SkillSynth 生成的轨迹,其唯一“场景-技能”覆盖率比单技能方案高 31%,比多技能随机组合也要高 19%。
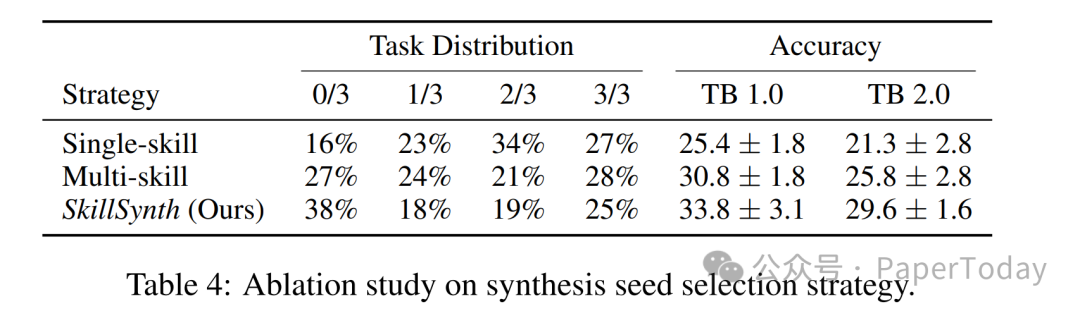
消融实验还额外揭示了一个重要发现:不经过图谱引导,只是随机地拼凑多个技能,效果要差得多。原因在于这种随机组合缺乏 工作流连贯性——生拼硬凑出来的任务往往包含了多个细碎的要求,但实际需要执行的步骤却很少,训练价值大打折扣。
这对咱们意味着什么?
SkillSynth 早已不是一篇停留在纸面上的论文了。用它生成的任务实例,已经被腾讯混元团队实实在在地用于训练 Hy3 Preview 模型,直接拔高了终端场景下的 Agent 能力上限。
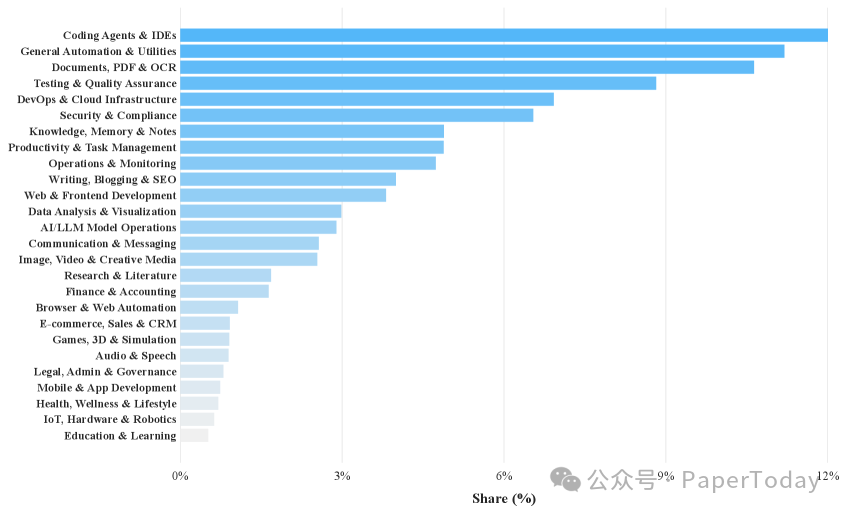
技能领域分布
图谱本身仍在持续“进化”。随着 ClawHub 社区贡献出更多技能,这张图谱可以自动生长,不断拉升任务的多样性。目前,图谱的覆盖范围已经触及编码、文档处理、DevOps、安全等常见领域,并延伸到了音频语音、3D 仿真、IoT 硬件等长尾领域。
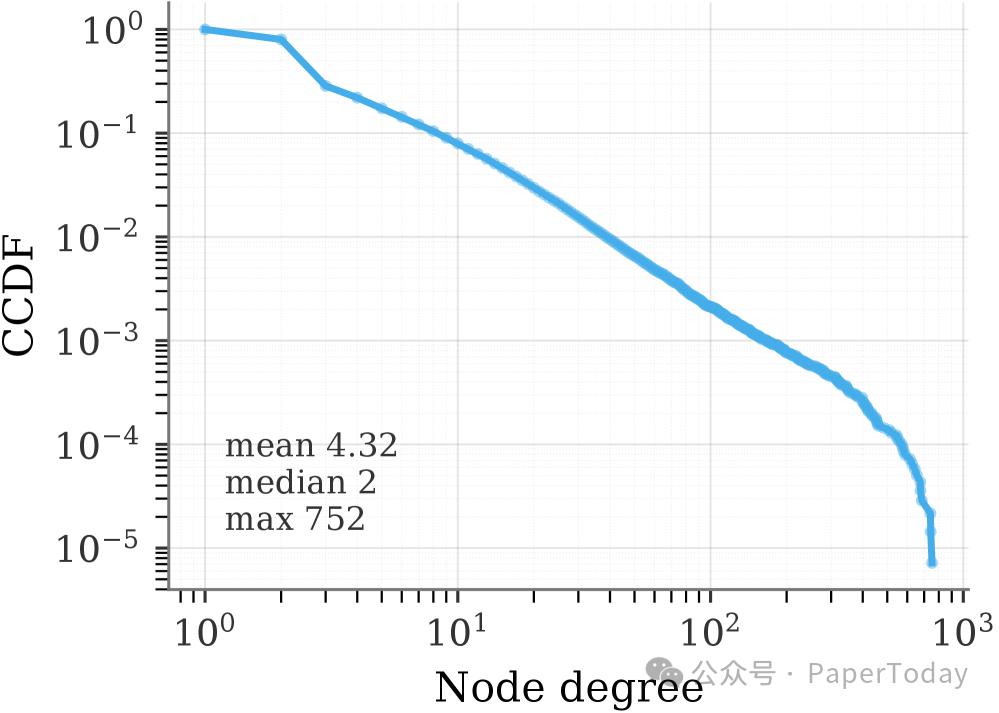
图谱度分布
对于各位 AI 从业者来说,这篇论文传递的核心信息非常直白:训练 Agent 的胜负手,既不在参数量,也不在任务数量,而在于训练轨迹的多样性。与其盲目地堆数据量,不如学学用图谱结构,去精细地控制“场景×技能”的覆盖密度。毕竟,让模型见多识广,远比让它反复背题要有效得多。
论文标题: Toward Scalable Terminal Task Synthesis via Skill Graphs
论文链接: https://arxiv.org/abs/2604.25727v1
 发表于 2026-5-3 21:13:08
|
查看: 112|
回复: 0
发表于 2026-5-3 21:13:08
|
查看: 112|
回复: 0
