整个 AI 行业把「自主性(autonomy)」当圣杯。大模型实验室比的是谁家的 agent 能跑得最久最远,最好用户输入一句 prompt 就走开。
Mira Murati 的团队在 2026 年 5 月 11 日公开的第一个模型,押的方向恰恰相反。
Thinking Machines——Mira 2025 年 2 月离开 OpenAI 后创立、2025 年 7 月拿下史上最大种子轮 20 亿美元——放出了一篇研究 preview《Interaction Models: A Scalable Approach to Human-AI Collaboration》,同时发布模型 TML-Interaction-Small(276B MoE / 12B active)。这不是又一个 agent harness 论文,而是他们从零训练出来的、明确反对当前 autonomy‑first 范式的第一个生产级模型。
「Interactivity should scale alongside intelligence; the way we work with AI should not be treated as an afterthought.」
在工程层做了几个硬核选择,并在 benchmark 上把 GPT‑realtime‑2.0 的 minimal 档拉开了一个数量级。按他们自定义的新维度来看,「没有一个现有模型能完成这些任务」。

01 业界都在押自主,但模型卡自己已经认怂
Thinking Machines 的论文一开头就摆出一段冰冷的事实:现在的大模型设计目标和用户真实的工作方式根本对不上号。
他们引用了一家头部模型的官方 model card(没点名,但措辞像 Claude Opus 系列的报告):
「Importantly, we find that when used in an interactive, synchronous, ‘hands-on-keyboard’ pattern, the benefits of the model were less clear. When used in this fashion, some users perceived [our model] as too slow and did not realize as much value. Autonomous, long‑running agent harnesses better elicited the model’s coding capabilities.」
这段自白翻译过来就是:我家模型在用户“在场跟它一块儿干活”的场景下表现还不如把它单独丢出去自己跑。于是实验室们的对策就是双押自主,把交互界面做得越“输入完就走”越好。
Thinking Machines 给出的反向判断是这一句:
「Humans get pushed out not because the work doesn’t need them, but because the interface has no room for them.」
人不是因为活儿不要他们了才被挤出去,而是因为界面没给他们留位置。这句话的分量在于:它把“人被 AI 取代”从一个能力问题(AI 比你强)重新框定成了一个界面问题(界面没给你留位置)。前者看似无解,后者却是工程层可以改的。
他们引了三段哲学论点来支撑这个判断。Clark & Brennan 1991 年的 Grounding in Communication 把高效沟通拆成三个性质:copresence(在场共看)、contemporality(即时反馈)、simultaneity(同收同发)。Walter Ong 1982 年讨论口语和文字的本质区别,强调口语的「evanescence」(瞬时性)天然包含参与性,而文字是冷的、有距离的。James C. Scott 1998 年讨论的 Métis(实践智慧)和 Hayek 1945 年的《知识在社会中的应用》都在说同一件事:真正重要的知识往往是“时间和地点的特定情境”,是没法事先用一句 prompt 讲清的。
今天的 turn‑based 接口逼着用户把所有这种隐性知识压缩进一次性的 prompt,做不到就只能眼看着模型跑偏。
02 200ms 是 AI 的新 token 单位
技术层的第一刀砍在哪里?把整个 turn‑based 架构推翻,换成 time‑aligned 微回合。
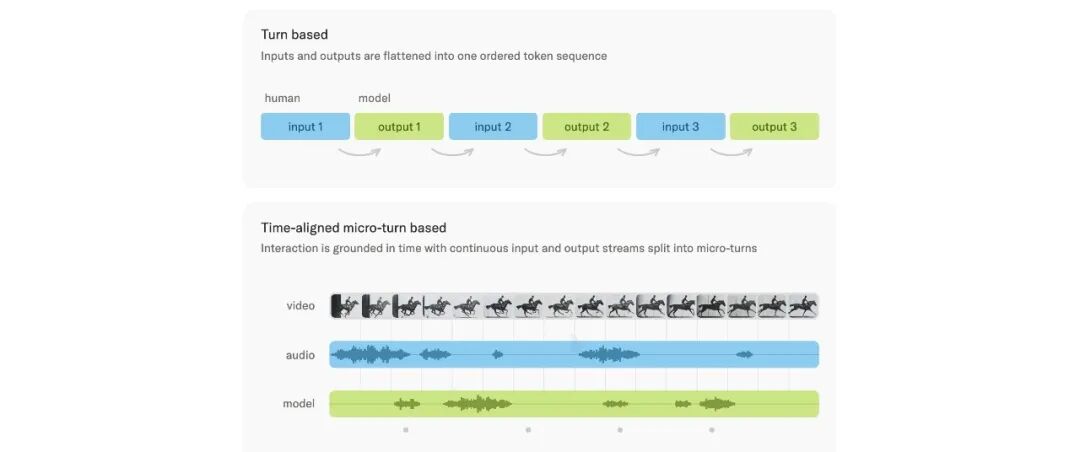
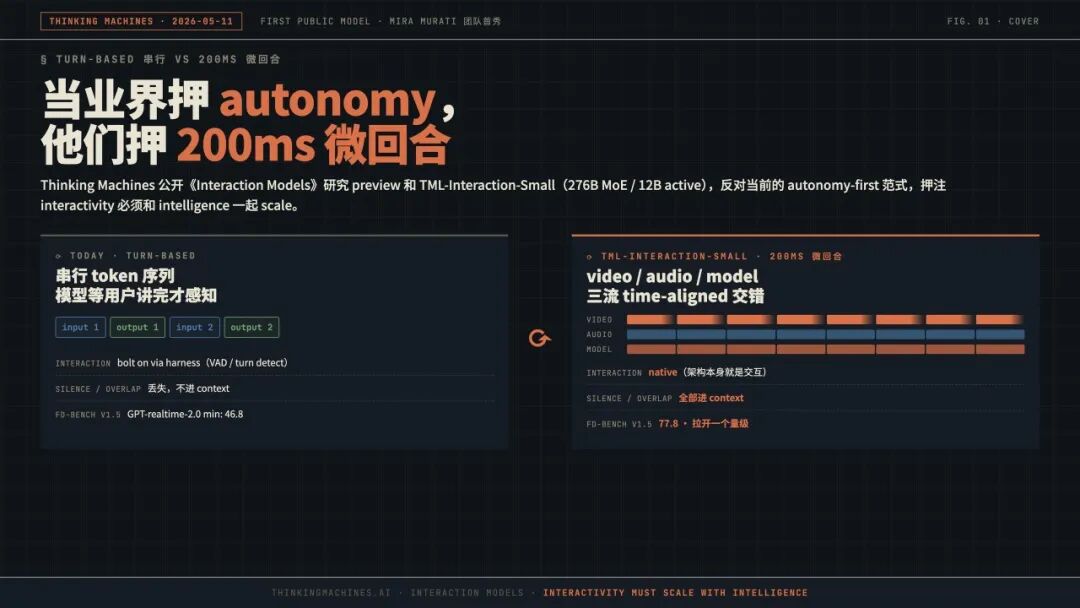
对照图很清楚。Turn‑based:input 1 → output 1 → input 2 → output 2,串行的 token 序列。模型在用户讲话时是“冻结”的,没有感知;模型在输出时是“自顾自”的,不接收新输入。Time‑aligned 微回合:把输入输出都切成 200ms 一个一个的 chunk,交错处理,video / audio / model 三路流同步推进。
200ms 不是随便选的数字,它是 人类感知反馈的物理上限。低于这个值,人感觉不到延迟;高于这个值,对话节奏就会断。
架构这么一改,原本需要靠外部 harness 拼凑的几项能力立刻变成了“模型本身自带”:
| 能力 |
turn‑based 时代 |
微回合时代 |
| 实时打断 |
VAD(语音活动检测)+ turn detect harness |
模型直接判断 |
| 同声翻译 |
不可能(必须等用户讲完一句) |
模型边听边说 |
| 视觉打断 |
没有,所有 API 都是 audio‑only turn detect |
「告诉我代码哪里有 bug」可以做到 |
| 时间感知 |
没有,模型不知道现在过了多久 |
「每 4 秒提醒我呼吸」可以做到 |
| 边回答边搜 |
两个独立调用拼起来 |
tool call 不打断对话流 |
「The model can do things like speak while listening (translate from Spanish to English live) or watching (live‑commentate this sports game).」
Thinking Machines 在论文里把这条路抬到了 Bitter Lesson 的高度。Sutton 2019 年那篇著名的 Bitter Lesson 论证过:「hand‑crafted systems will be outpaced by the advance of general capabilities」。VAD / turn detection 这些至今还在用的 harness 都是 hand‑crafted 的小聪明,它们在“通用能力 scaling”面前最终都会被淘汰。
逻辑链很硬:你没法一边相信 model scale 是通向 AGI 的路,一边把核心交互逻辑外包给一个比模型本身弱得多的 VAD 组件。今天 OpenAI Realtime / Gemini Live 这类 API 的 turn‑detection 还是后挂的组件,跟模型主权重完全脱离。Thinking Machines 的论证是:等模型一代代变强,这些后挂组件会越来越显得粗糙。该不该解耦,本身就是一个押注。
03 不是塞个 Whisper,是从零共训音频和视频
第二刀砍在 encoder 上。
现在主流的 omnimodal 模型大致走两条路:要么外挂大 encoder(Whisper‑like 处理音频 / CLIP‑like 处理图像)再把 embedding 灌进 LLM;要么走 wrapper 模式把 ASR / TTS 模型串成一条流水线。Thinking Machines 两条路都不走,他们选 encoder‑free early fusion。
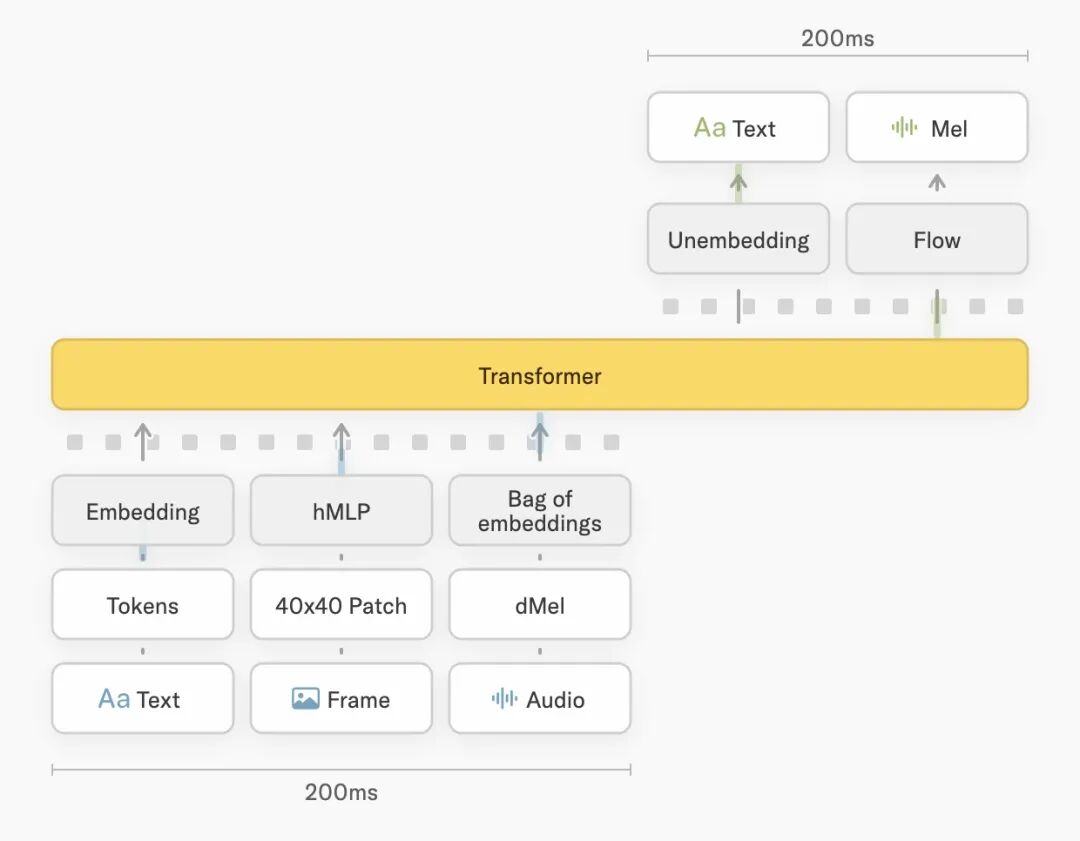
具体到每个模态:
音频 走 dMel(Bai et al. 2024),把 raw audio 压成 Mel 谱再过一层轻量 embedding layer 就直接送入 transformer。
视频 切成 40×40 的 patch,用 hMLP(Touvron et al. 2022)做轻量 patch embedding。
音频 decoder 用 flow head(Lipman et al. 2022),从 transformer hidden state 直接出 Mel 谱再合成音频。
关键是这三条路径跟 transformer 主干是从零开始一起共训的。没有预训练好的 Whisper 当 encoder,也没有预训练好的 TTS 模型当 decoder。所有路径都是 end‑to‑end gradient flow 一次跑通。
这套架构的代价是冷启动慢、工程量大;好处是模型本身就理解音频和视频的时间结构,而不是把模态 embedding 当成一种“特殊 token”往里塞。
接下来还有一个分离架构的决定。
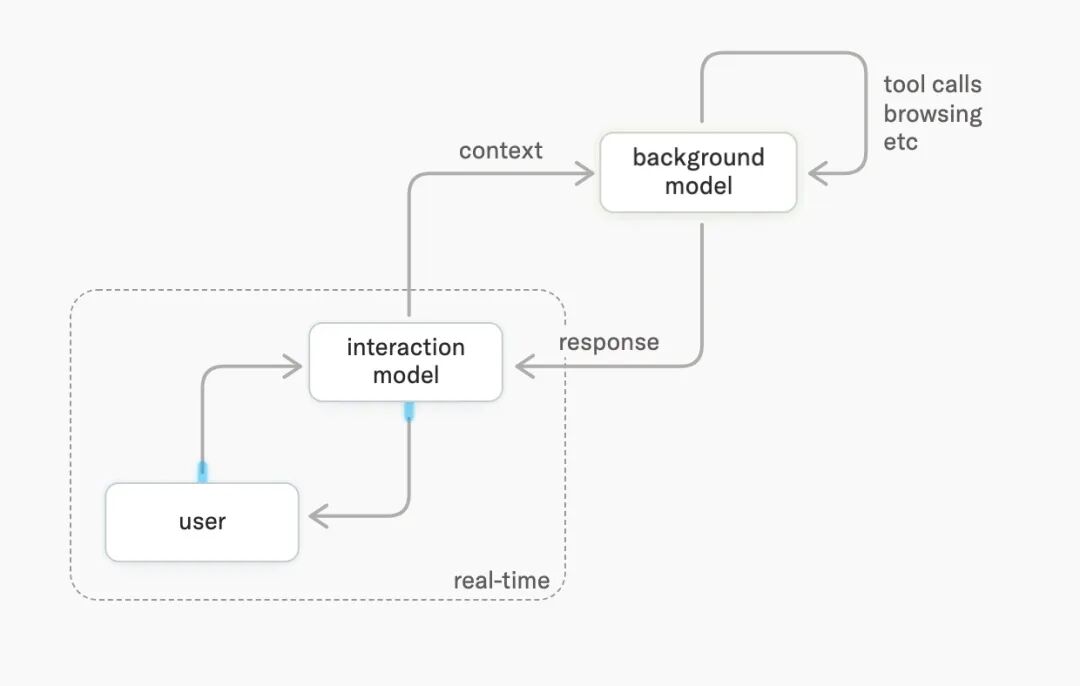
Thinking Machines 把整个系统拆成两个模型:interaction model 跑在前台保持实时在场,background model 在后台跑深度推理 / tool call / web browsing。两个模型共享 context,interaction model 在合适的时机把 background 的结果织进对话。
「The planning, tool‑use, and agentic workflows of reasoning models at the response latency of non‑thinking ones.」
读论文的时候,我觉得这是整篇里最聪明的工程决策之一。它没有硬装“一个模型全能干”,而是承认深度推理和实时在场是两类延迟特征完全不同的任务,应该用两类优化方向不同的模型来分担。这和 Anthropic 系列里“Sonnet vs Opus”的分层思路类似,只不过 Thinking Machines 直接把它做进了系统架构。
04 工程硬选择:streaming sessions upstream 到 SGLang + Blackwell bitwise alignment
200ms 微回合架构对推理 infra 有一个相当另类的需求:高频小 prefill / decode 循环,每一个都必须满足严格的延迟。
传统 LLM 推理库的设计假设是“prefill 一次输入完成,decode 一次产出 N 个 token”,这种 N=N 的批处理对单次大请求很高效,对 200ms / 200ms 的小循环极度不友好。每次都要重新分配 GPU 内存、重算 metadata。
Thinking Machines 的解法是 streaming sessions:客户端把每个 200ms chunk 当成独立请求发出去,服务端把这些 chunk 追加到一个在 GPU 内存里持续存在的 sequence 上。这套机制已经被他们 upstream 到了 SGLang 主仓库。
并行上还有一系列 kernel 级别的优化,包括:
- Bitwise trainer‑sampler alignment:training 和 inference 产生的数字 bit‑by‑bit 相同。这在多数实验室里不可能做到(不同 parallelism 策略下数值精度会漂移)。
- NVLS deterministic on Blackwell:在 NVIDIA 最新一代 GPU 上拿到了 deterministic 的低延迟通信 kernel。
- batch‑invariant attention kernel + 一致的 Split‑KV 切分(4096 token/块,left‑aligned)。
batch‑invariant 通常只是 training 稳定性的工具,这里被拿来当工程级 debug 杠杆。论文脚注里还有一句很有意思的话:
「Funnily enough, for some period of time using the batch‑invariant kernels was actually faster e2e, due to the custom communication kernels which were not only batch‑invariant but also much lower latency.」
工程师写论文写到“funnily enough”,一般是真的踩到了反直觉的坑。batch‑invariant 本意是“牺牲一些吞吐换数值确定性”,但因为顺手给它配的通信 kernel 延迟极低,阶段性端到端反而更快了。这种细节在论文里看着不起眼,工程师却能闻出味儿来。
05 数据:TML‑Interaction‑Small 把 GPT‑realtime‑2.0 minimal 拉开一个量级
光有架构和工程不够,benchmark 得真打过。
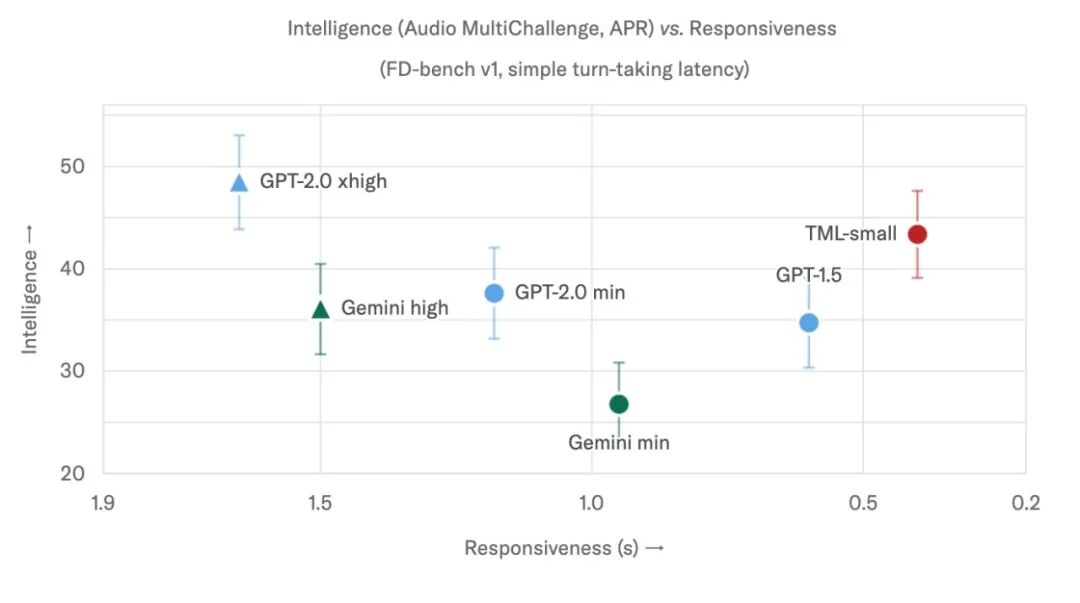
这张图是论文里我认为最值钱的:横轴 responsiveness(turn‑taking latency,越往右越快),纵轴 intelligence(Audio MultiChallenge APR)。所有模型在 Pareto 前沿上排开:GPT‑realtime‑2.0 xhigh 智能高但延迟 1.63s,Gemini‑3.1‑flash‑live high 中等智能、延迟 0.94s,TML‑Interaction‑Small 在右上角 intelligence 43.4 + latency 0.40s 同时拿下。
具体数字:
| 指标 |
TML‑Interaction‑Small |
GPT‑realtime‑2.0 minimal |
Gemini‑3.1‑flash‑live minimal |
Qwen 3.5 OMNI‑plus‑realtime |
| FD‑bench V1 latency |
0.40s |
1.18s |
0.57s |
2.14s |
| FD‑bench V1.5 average |
77.8 |
46.8 |
54.3 |
39.0 |
| FD‑bench V3 RQ / Pass@1 |
82.8 / 68.0 |
80.0 / 52.0 |
68.5 / 48.0 |
60.0 / 50.0 |
| Audio MultiChallenge APR |
43.4 |
37.6 |
26.8 |
- |
| IFEval VoiceBench |
82.1 |
81.7 |
67.6 |
80.3 |
在 instant 类(不开 thinking)里它全面碾压 GPT‑realtime‑2.0 minimal。开了 background agent 之后,BigBench Audio 拿到 96.5,跟 GPT‑realtime‑2.0 xhigh 的 96.6 几乎齐平。要知道 GPT‑realtime‑2.0 xhigh 可是带 thinking 的版本。
更狠的是新维度。Thinking Machines 自己造了五个 benchmark 测 「proactive audio + visual proactivity」:
- TimeSpeak:模型能不能在用户指定的时间点主动开口?(「我练呼吸,每 4 秒提醒我吸气呼气」)
- CueSpeak:模型能不能在合适的时机说出语义正确的话?(「我每次切换语言时,告诉我那个词的原语翻译」)
- RepCount‑A:视频里数对方做了多少个动作(俯卧撑)
- ProactiveVideoQA:等视频里出现答案的时机再开口
- Charades:实时标注一个动作的起止时间
论文里对这部分总结得非常干脆:
「No existing model can meaningfully perform any of these tasks.」
没有一个现有模型能完成这些任务。GPT‑realtime‑2 minimal 在这些 benchmark 上要么沉默要么乱答,包括开了 thinking 的高配版。
这一节的真意不是“TML‑small 把别人打爆了”,而是 Thinking Machines 在论证一件事:他们押注的这条路(interactivity 必须 native)打开的能力空间,今天的 turn‑based 模型连入场券都没有。你可以选择不在乎这些能力,但你不能假装它们和现在主流的实时 API 是同一类东西。
整篇论文读下来,最大的认知更新有两个。
交互不是模型之外的工程脚手架,而是模型本身的特性。今天所有 real‑time API 都靠 VAD + turn detection 这类 harness 拼出“实时”的感觉,但只要 model scale 一上去,这些 harness 就会被吃掉。Sutton 那句话还会再应一次。
自主(autonomy)和交互(interactivity)是两条独立的 scaling 轴。今天主流实验室在自主这条轴上猛推,把 agent 跑得越长越远当作核心 KPI。而 Thinking Machines 的第一发模型明确指出:还有第二条轴需要 scale。两个方向不矛盾,但谁也取代不了谁。
Mira Murati 团队选择把这篇论文作为 Thinking Machines 的第一个模型发布出来,这个选择本身就是一种立场:不是跟 GPT 比 reasoning,也不是跟 Anthropic 比 alignment,他们押的是第三条赛道。据称 research preview 今年晚些会开放有限内测,更大的模型也会陆续放出。
短期看,这套架构对消费者级 AI agent 的最大冲击可能出现在两个领域:实时翻译/同传类应用第一次有可能不再像“延迟 1 秒讲一句”的人形对讲机;写代码场景下“你写错的时候我直接打断你”这种交互,第一次有可能从 demo 变成产品默认行为。
更长期看,如果 interactivity 真的能跟 intelligence 同步 scale,那我们今天讨论的“Agent 该不该全自动”这个问题本身就会被重新框定。它不再是非此即彼的选择,而是回到人类协作的本来样子:在某些任务上让 AI 完全跑,在另一些任务上让 AI 在场陪你跑,两者都能 scale。
本文由云栈社区整理,关注实时交互与多模态前沿。
 发表于 2026-5-13 18:28:48
|
查看: 150|
回复: 0
发表于 2026-5-13 18:28:48
|
查看: 150|
回复: 0
