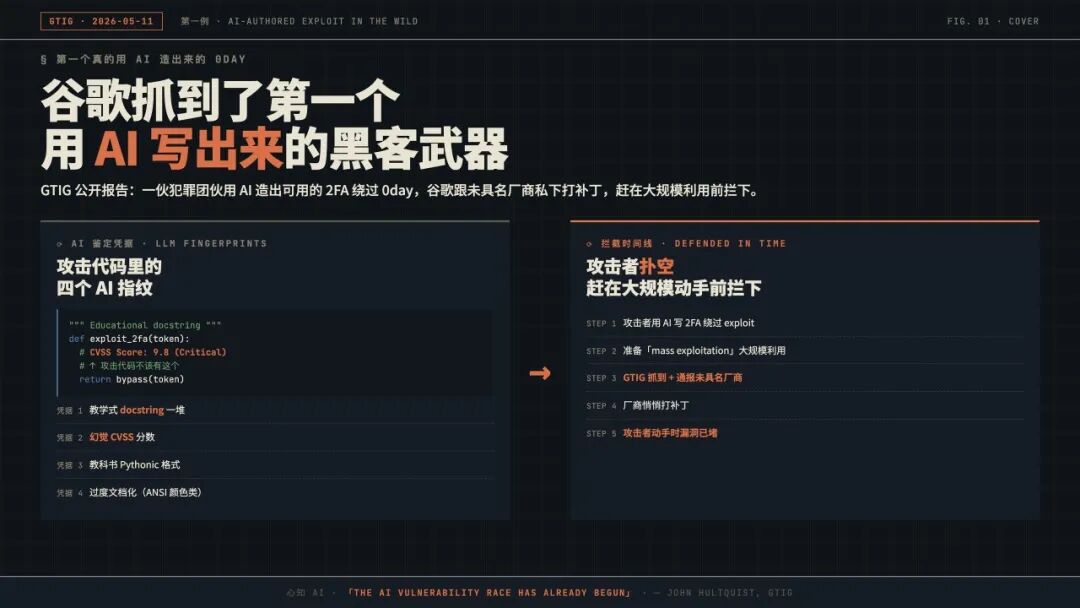
2026年5月11日,谷歌威胁情报组(GTIG)发布了一份让网络安全圈炸锅的报告:他们捕获了一起真实的野外攻击,犯罪团伙用 AI 造出了一个能用的零日漏洞利用工具。所谓“零日漏洞”(0day),是尚未被修复、攻击者拿到即可使用的安全缺陷;“利用工具”则是针对该漏洞编写出的攻击代码。这类话题此前一直在学术圈和红队讨论,而谷歌这种级别的厂商第一次公开确认——它真的在野外发生了。
更戏剧性的是后半段。GTIG 在攻击者准备大规模利用之前就截获了情报,与尚未公开名字的产品厂商私下打好补丁,让攻击最终扑空。GTIG 高级总监 John Hultquist 对此评价很冷静:很多人以为“AI 攻防竞赛即将到来”,事实是它已经开始了。
但这起事件不能孤立地看。同一周还发生了另外两件 AI 安全大事——一件属于防御方的胜利,一件是攻击侧的伪装。三件事拼在一起,才勾勒出这一周的完整分量。
01 GTIG 报告到底写了什么
先把核心事件讲清楚。
GTIG 抓到的漏洞是这样的:攻击者写了一个 Python 脚本,能在一款“被广泛使用的开源网页版系统管理工具”上绕过双因素认证(2FA)。GTIG 没有公开是哪个产品,只透露其使用范围甚广。
漏洞的性质很微妙。它不是传统的“内存破坏型”漏洞——那种攻击者塞一段超长输入把内存撑爆的套路,传统扫描器很擅长发现这类问题。GTIG 这次捕获的是 高层语义逻辑缺陷:开发者在写代码时硬编码了一个“信任假设”,结果与自己同时编写的 2FA 强制逻辑形成了冲突。一边的代码说“这种情况必须验证”,另一边的代码却说“这种情况免验”。两段意图自相矛盾,攻击者刚好从缝隙中钻了过去。
有一个重要前提不能忽略:触发这个漏洞需要先持有合法用户的账号密码,不是无凭据直接拿下系统,而是已经混进系统的人借此绕过二次验证。
GTIG 在报告中给出了直接判断:传统代码扫描器擅长找崩溃、越界这类“机械”漏洞,但前沿大模型 AI 擅长读懂开发者写代码时的意图,找出逻辑层面的自相矛盾——这恰是机器扫描器长年的盲区。
GTIG 与未具名厂商私下沟通后悄悄修复了漏洞。等攻击者准备大规模动手时,入口已经被堵上。事情本来可以就此收尾,但 GTIG 选择公开报告,并附上了他们鉴定攻击代码出自 AI 之手的四项具体证据。
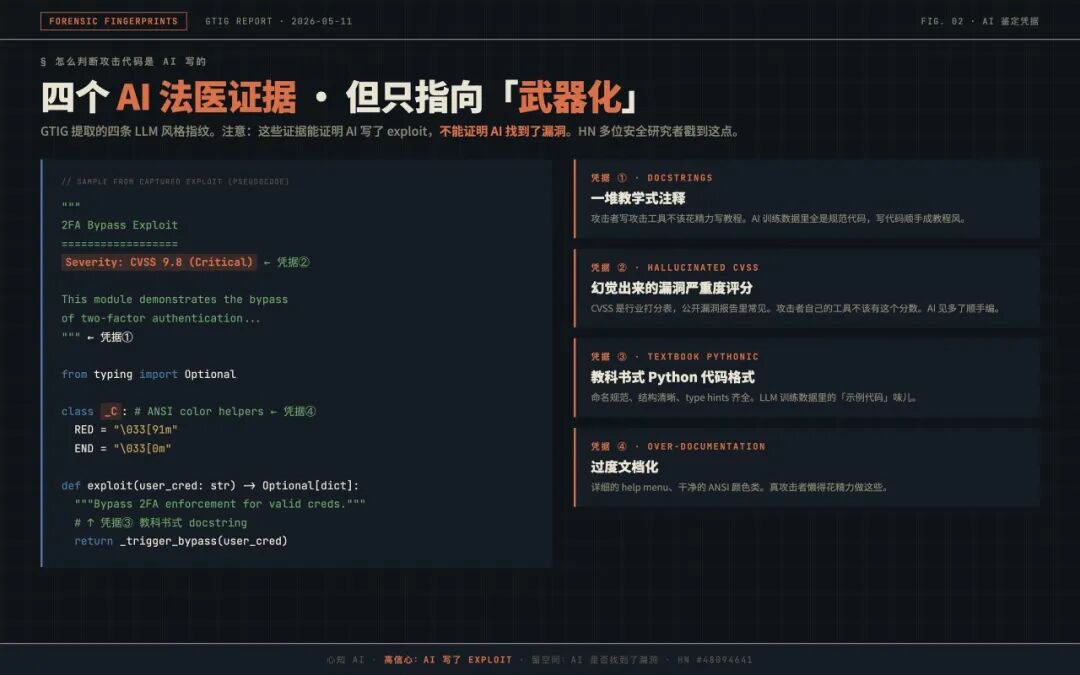
02 怎么判断这是 AI 写的:四个法医证据
GTIG 给出了四条“AI 指纹”:
第一,攻击代码里塞了一堆教学式注释。学过编程的朋友都知道,函数前面那些说明用法的多行注释叫作 docstring。真正写攻击工具的人不会花精力去做这种教程,但 AI 的训练数据里充斥着规范代码,写代码时顺手就把注释写成了教科书风。
第二,代码里冒出一个“幻觉式的”漏洞严重度评分。CVSS 是行业通用的漏洞打分体系,常见于公开漏洞报告,但攻击者自己写的工具不该出现这种分数。AI 在训练数据中看过太多 CVSS 评分,随手就编了一个塞了进去。
第三,教科书式的 Python 代码格式——干净、结构化、命名规范,充满 LLM 训练数据里那种“示例代码”的味道。
第四,过度文档化:详细的命令行帮助菜单,甚至还有一个完整的 ANSI 颜色类,用来给终端输出加色彩。真正的攻击者懒得在这些花活上费工夫。
GTIG 的结论是:高信心认为攻击者使用了某个 AI 模型,但不是谷歌自家的 Gemini。这句澄清非常关键,谷歌显然不希望自家模型被绑到这起事件上。
但这里有一个方法学问题,Hacker News 上多位资深安全研究者都戳到了:四条证据只能证明 AI 写了这个攻击工具,不能直接证明 AI 找到了漏洞。评论者 adrian_b 讲得很透彻:这只能说明有个 AI 代码助手写了 exploit,没法证明漏洞本身由 AI 找出。“找漏洞”和“写攻击代码”是两件事。GTIG 在报告里用了“发现 + 武器化”这个词组把两者打包,但提供的证据更支持“武器化”这一半。
这并非否定 GTIG 的发现,而是校准分量:确凿的是 AI 已被攻击者用于攻击代码的生产,留有想象空间的是 AI 在漏洞发现过程中究竟参与了多深。
03 不只这一个:朝鲜、中国、俄罗斯都在干什么
GTIG 这一次没有只讲一个 0day,而是把整个生态摸了一遍。报告点名的国家级 APT 组织至少包括下面几个:

APT45(GTIG 将之归为朝鲜背景):使用“递归式 prompt”,一边让 AI 给出答案,一边把答案再送回去问下一轮,把成千上万个已公开漏洞编号(CVE)喂给 AI,让它验证是否可用。报告首次点名了两个 agent 工具 OpenClaw 和 OneClaw,攻击者用它们在隔离环境中测试漏洞。
UNC2814(GTIG 将之归为中国背景):用“资深安全审计员”“C/C++ 二进制专家”这类人设 prompt 让 LLM 扮演专家,目标瞄准嵌入式设备固件,比如 TP-Link 等家用路由器。
APT27(GTIG 将之归为中国背景):用 Gemini 加速开发一个“舰队管理”工具,为 ORB 网络(利用受感染家用路由器搭建的中转网络,用于隐匿真实出口 IP)服务。代码中能看见硬编码的 maxHops=3 这类工程化细节,已经不像玩票,而是产线在跑。
俄罗斯背景的组:用 AI 生成“诱饵代码”(让恶意软件看起来像正常程序的伪装层),造出两个新恶意软件家族 CANFAIL 和 LONGSTREAM,用来攻击乌克兰组织。还有一个名为“Operation Overload”的行动,利用 AI 语音克隆冒充记者进行信息战。
更让安全圈震动的是一个具体样本 PROMPTSPY:恶意软件直接内置 LLM 调用,程序里硬编码 gemini-2.5-flash-lite 模型名,运行时通过 HTTP 请求直接调谷歌接口。不再是“外挂 AI”,而是“原生内置 AI”。它运行时会读取屏幕、动态生成指令、自己决定下一步做什么。
04 中间件生态:让大厂封号也没用的“中转层”
读到这里,可能有人会问:大模型厂商不是都有内容护栏吗?OpenAI、Anthropic、Google 不是会封禁可疑账号吗?
GTIG 给出的答案是:攻击者已经发展出一整套“中转层”,让大厂的封号形同虚设。
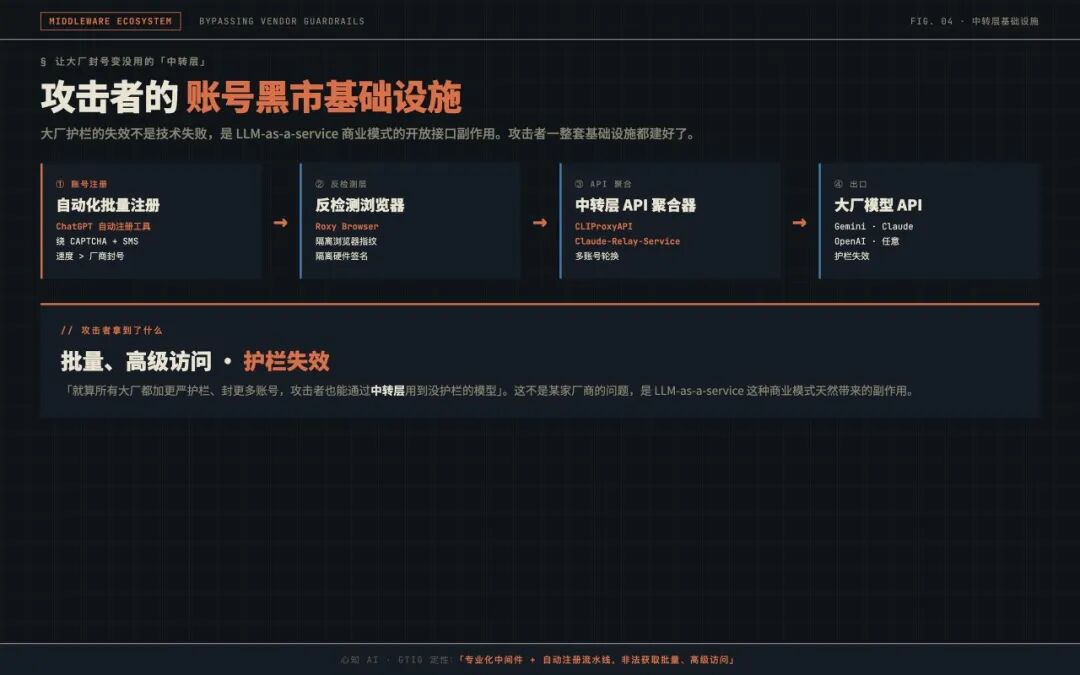
这套基础设施包含四类组件。API 聚合器(如 CLIProxyAPI)把多个 API 钥匙拼成统一接口,Claude-Relay-Service 则聚合 Gemini、Claude、OpenAI 等多家账号;攻击者维护账号池,个别被封不影响整体业务。账号注册自动化能自动绕过图形验证与短信验证,注册速度超过厂商的封号节奏。反检测浏览器 Roxy Browser 可隔离浏览器指纹和硬件签名,防止厂商通过指纹把多个账号关联到同一人。
GTIG 将整套基础设施定性为“专业化中间件 + 自动注册流水线”,非法获取大模型的批量、高级访问权限。
这里的关键含义是:即使所有大厂都叠上更严的护栏,攻击者仍能通过中转层用到没护栏的模型。这不是某一家厂商的失败,而是 LLM-as-a-service 商业模式天然带来的副作用。
05 同一周另外两件事:Mythos 防御 + TanStack 伪装
这起事件不能孤立看待,因为同一周还有两件事让全景图变得完整。

5月7日:防御侧的胜利。 Anthropic 一个月前发布的安全专用模型 Claude Mythos Preview,帮助 Mozilla 在 Firefox 浏览器源码里找出 271 个问题。成果在 4 月 Firefox 150 发布时正式落地。2026 年 4 月,Firefox 一个月修复了 423 个漏洞,对比 2025 年同期只修复了 31 个,放大 13.6 倍。
但这里必须给出一个 nuance:Mythos 找出的 271 不等于 271 个 CVE。Firefox 150 官方公告中只有 3 个明确归功于 Claude 的 CVE 编号(CVE-2026-6746 / CVE-2026-6757 / CVE-2026-6758),其余多数是低危、深度防御类或不可利用代码路径上的问题。Mozilla 自己也说得非常实在:“没有一个超出精英人类研究员的能力范围”。Mythos 的价值在于速度和规模,而不是发现了什么全新攻击类别。
5月11日:攻击侧的伪装。 就在 GTIG 报告公开的同一天、早几个小时,有人在 npm 平台上攻击了被广泛使用的 React 工具库 TanStack。19:20 到 19:26 UTC,仅 6 分钟,攻击者向 42 个包发布了 84 个恶意版本。
最戏剧性的是攻击者所使用的伪装身份——claude <claude@users.noreply.github.com>,伪造的 Git 提交者字段看起来像是 Anthropic 官方的 Claude 在提交。TanStack 在事后复盘时专门澄清:“这不是真的 Anthropic Claude,而是用 GitHub 通用 no-reply 邮箱伪造的”。
同样有一个 nuance 需要指出:“冒充 Anthropic”并非伪造 GitHub App 的加密签名。GitHub 的 commit 作者字段只是文本元数据,任何人填什么都可以。但视觉效果上,UI 会显示这条 commit 是由“claude”提交的,对值班工程师的混淆效果不可忽视。
第三方研究机构(Aikido、StepSecurity、Wiz)通过套路指纹将攻击归因到一个叫 TeamPCP 的组织,该组织此前在 3 月攻击过 Trivy、4 月攻击过 Bitwarden CLI。TanStack 官方没有进行任何归因,只贴出了攻击者账号 zblgg 和 voicproducoes。
06 一周看完,看到了什么
把三件事按攻防类型重新排列:
防御侧 AI 已经能将人类找漏洞的速度放大 13 倍(Mythos × Firefox,但贡献多数在低危、规模化层面)
攻击侧 AI 已被用来编写真正可用的漏洞利用工具(GTIG,但“找漏洞”这一半还未被实锤)
攻击侧 AI 已在供应链层面伪装成另一家 AI 厂商的身份(TanStack,利用了 GitHub 的弱元数据)
不要把这三件事浪漫化成“攻防对决进入新阶段”的宏大叙事。它们各有各的 nuance:Mythos 的 271 不是 271 个 CVE;GTIG 的四个法医证据更多指向“武器化”,未必能证明“漏洞发现”;TanStack 的“冒充”依赖于 commit 元数据的弱信任,而非签名被破。
但有几条线索已经很难绕开。
大模型擅长发现“逻辑型漏洞”——开发者写代码时两段意图打架的那些缝隙,正是传统扫描器长年的盲区。这项能力被防御方还是攻击方率先工程化,目前还是平手。Mythos 已经进了 Firefox,而 GTIG 抓到的犯罪团伙也已在准备大规模利用。
攻击者一方的中间层基础设施已经建成。“不让攻击者拿到强 LLM”的护栏对这一层基本失效,他们用的未必是大厂接口,可能是中转,也可能是开源模型在本地跑。
身份验证的脆弱环节会被反复打击。从 npm 提交元数据可以任意伪造,到 LLM 厂商的账号护栏能被反检测浏览器加自动注册绕过,攻击面上的共同点是“身份信号脆弱”。AI 时代之前这些问题就已存在,AI 只是让攻击成本呈现断崖式下降。
再回想 Hultquist 那句话:它已经开始了。这一周并不是开始的标志,而是它停止伪装“还没开始”的那一周。
 发表于 2026-5-13 18:24:12
|
查看: 130|
回复: 0
发表于 2026-5-13 18:24:12
|
查看: 130|
回复: 0
