只用单一工具搭建 AI agent 花不了多少钱。你接上一个本地脚本,让 LLM 去读,每次请求的成本不过区区几美分。
然后你开始扩展。
你用标准的 Model Context Protocol(MCP)连接内部数据库、企业 CRM,以及几十个 microservices。结果呢?AI 还没开始执行任务,你的 token 用量就急剧飙升。延迟爆炸,API 账单跟着起飞。
如果你抓取一个暴露数百个工具的系统的原始请求日志,问题一目了然。你在每一次调用上都支付一笔巨大的、反复出现的“Agent 税(Agent Tax)”。标准的 MCP 架构 在高规模环境中从根子上就有问题。如果你想构建高性价比的 agent 工作流,而用户的 prompt 还没被处理,基线 context window 就已经被塞满,那根本不可能。
我一直在分析这个路由问题的结构性解决方案。它是一个 开源的 gateway,叫做 Bifrost,正是架构层面的补丁。

Bifrost Code Mode:将Token成本降低92%
上下文膨胀的机制
当你追踪标准 Model Context Protocol 实现的执行路径时,扩展的天花板会赫然在目。这个协议依赖的是蛮力式注入(brute-force injection)。
如果你把一个 agent 连到一个 PostgreSQL 数据库、一个 Stripe 实例,再加上一块 Jira 看板,系统并不会给 AI 一个轻量的指针。它会读取每一个已连接工具的完整 JSON schema,把整本“使用手册”——每个 endpoint 的参数、可接受的类型、必填字段等——全都提取出来,然后在每次请求中把这大段文本直接前置到 system prompt 里。
这相当于让一台服务器为了执行一个 ping 命令,就把所有已安装应用的二进制整体加载进 RAM。蛮力手段,规模化必崩。
当你把这种架构推到需要连接上百个企业工具时,系统会在三个方向上出现断裂:
- 延迟剧增:LLM 必须解析并处理成千上万的结构性 tokens,才终于开始关注用户的真实指令。Time-to-first-token(TTFT)呈指数级恶化。
- context window 耗尽:你撞上模型的硬性上下文上限,原因不是复杂的对话历史或深度推理,而是那些静态、重复的工具定义。
- API 账单失控:你为每一个输入 token 付费。强迫 AI 在每次请求中重读 500 份工具 schema,意味着 agent 还没开始执行任务,你就在纯粹烧钱。
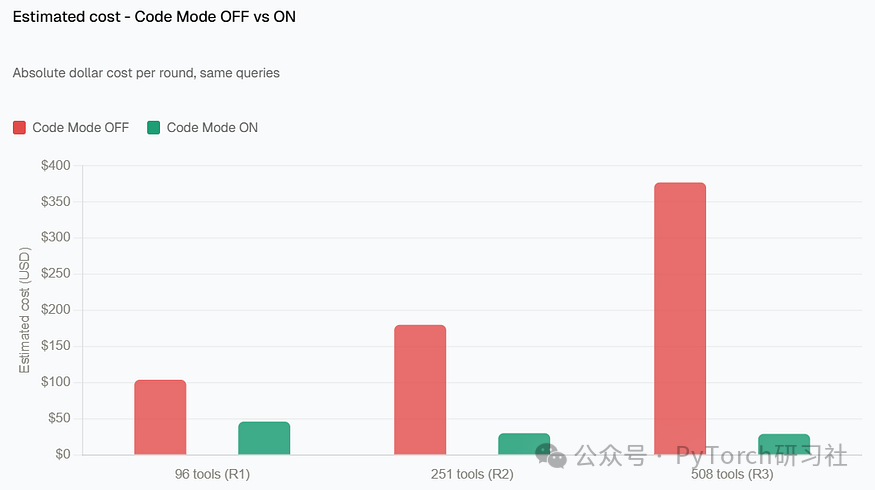
Bifrost 将 508 个工具的执行成本从 $377 降到$29(降低 92.8%),相较于标准 MCP 架构(来源:here)。
范式转变:基于 gateway 的工具编排
打开 Bifrost 的架构图,一个清晰的模型摆在眼前:位于 agent 与基础设施之间的双角色节点。它同时作为 MCP client 连接外部工具,又作为 MCP server 暴露统一的 endpoint。你不再把 LLM 直接怼到一堆分散的数据库和 API 上,而是把连接统一路由到这个中心 gateway。
这种架构启用了一个叫 Code Mode 的结构性变通方案。
Bifrost 不再把上百份沉重的 JSON schema 倒进模型的 prompt,而是把暴露面收敛为四个极轻的元工具(meta-tools):List、Read、Get Docs 和 Execute。就这么点载荷。当 AI 需要拉取一条数据库记录并把它写入某个 CRM 时,它会动态读取所需的特定 tool signatures(签名),然后在一个安全的 Starlark sandbox 中写一段临时 Python 脚本来编排步骤。Bifrost 在本地执行脚本,模型只接收最终输出,绕过了中间过程的上下文膨胀。
它能在一次往返(single round‑trip)中处理多个 tool 调用。蛮力式 schema 注入就此被移除。
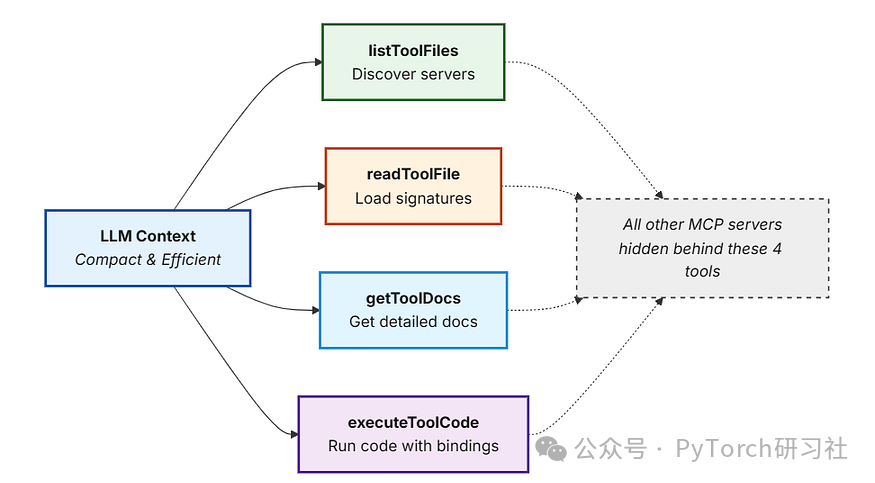
所有复杂的编排都在 sandbox 内部完成。LLM 只接收最终、紧凑的结果——而非每一个中间步骤。(来源:here)
你可以通过这里查看更多技术细节。
零摩擦迁移
架构革新往往意味着要把现有执行逻辑连根拔起,但在这里不需要。
开发者体验被设计成纯粹的即插即用替换。你用不着重写 agent 的推理循环,也不用重构下游 MCP servers。由于 gateway 暴露的 endpoint 与标准 API 协议镜像一致,迁移只需改一行代码:base_url。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
base_url="https://<bifrost_url>/openai",
)
response = client.chat_completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "Hello!"}
]
)
# OpenAI SDK
- base_url = "https://api.openai.com"
+ base_url = "http://localhost:8080/openai"
# Anthropic SDK
- base_url = "https://api.anthropic.com"
+ base_url = "http://localhost:8080/anthropic"
# Google GenAI SDK
- api_endpoint = "https://generativelanguage.googleapis.com"
+ api_endpoint = "http://localhost:8080/genai"
你只需把客户端流量指向 gateway 的 URL。Bifrost 会在启动时通过 STDIO、HTTP 或 SSE 传输自动发现已连接工具的 schema。你拉起来、换个 endpoint,gateway 就接管路由。这是一分钟的配置变更,却能从根本上改变系统的成本曲线。
执行指标:架构的可扩展性
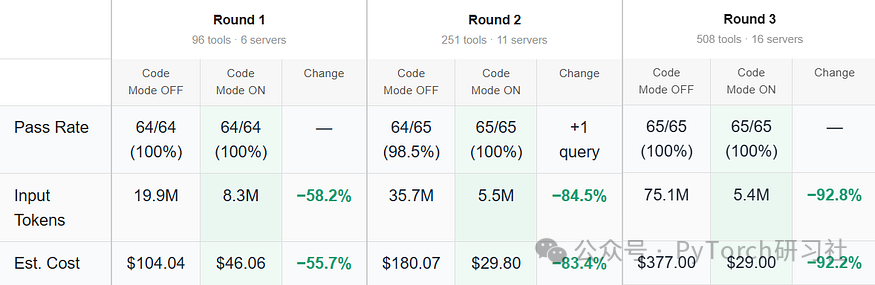
基准数据表明,在 508 个工具规模下,Code Mode 维持 100% 任务通过率,同时将 token 量与成本降低 92%+。(来源:here)
看过基线扩展测试后,数据很直白。测试把 agent 的环境从连接 96 个工具一路扩展到 508 个。
采用标准架构时,schema 注入把输入 token 量推得极高,单次运行成本飙到 $377。把完全相同的工作负载经由 gateway 路由,成本骤降至$29,输入 tokens 降低了 92.8%。
可是,如果路由层自己成了瓶颈,再便宜也没意义。
任何工程师看到这个设定都会立刻想到那个显而易见的权衡:在 LLM 与数据库之间塞进一个安全 sandbox 外加一次 Python 执行,按理说会显著增加延迟。
然而并不会。gateway 的内部开销约 11 微秒。更关键的是,Code Mode 把串行的 tool 调用折叠为一个可执行脚本,消除了多次网络往返。你不用再等模型请求读取、等待载荷、再请求写入、然后写入。脚本一次性在本地处理完逻辑。
净结果是执行流水线快了 40%。上下文膨胀砍掉 92%,agent 实际完成任务的速度反而比直接无路由的连接更快。
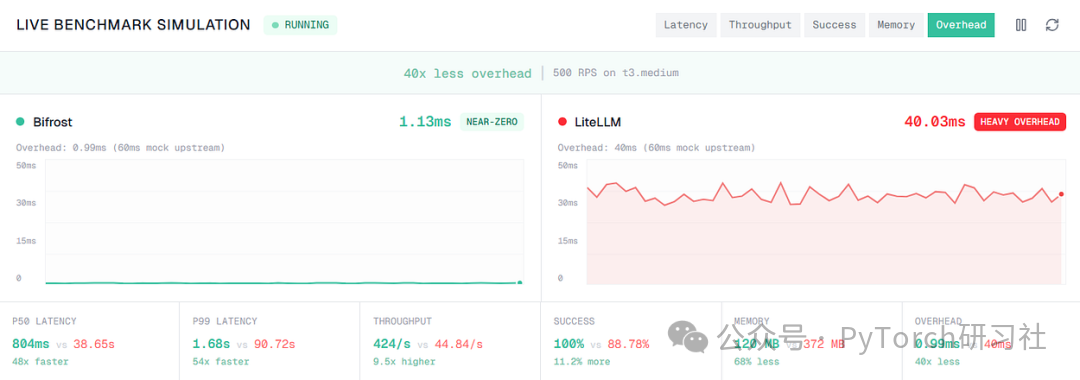
实时基准遥测对比 Bifrost 与 LiteLLM,证明 gateway 在保持近乎零开销(1.13ms)的同时,实现了 48x 更快的 P50 latency 和 9.5x 更高的 throughput。(来源:here)
治理的基础设施
审计企业级 agent 部署时,我最在意的从来不是延迟,而是访问控制。如果你把一个 LLM 接进生产网络却没有强约束,就等于在制造风险。
就算一个出现幻觉的模型不慎把生产库的表给删了,执行再快、token 再省也白搭。gateway 架构的解法是把治理从 prompt 工程层下沉到网络层,通过两大类机械控制来执行:
- Scoped Virtual Keys:标准 MCP 往往给 agent 对某个已连接 server 的“全域访问”——就像把 root 权限交给一个前端脚本。Bifrost 用范围化虚拟密钥取而代之。你生成一个只允许访问特定 Jira read-endpoint 的密钥,并在物理层面阻断其他一切访问。如果模型“失控”,试图进行未授权的数据库写入,gateway 直接丢弃请求。安全边界是绝对的。
- 细粒度审计日志(Granular Audit Logging):在直连架构下,你通常只有在收到巨额 API 发票时,才惊觉 agent 早已陷入执行循环。Bifrost 作为中心路由,会拦截并记录遥测,按工具统计 token 消耗与执行成本,一目了然。看一眼 gateway 日志,立即就能发现某个 CRM 的 read-action 正在烧掉 80% 的预算。你获得了绝对可见性,能在账单周期结束前限流或重写集成。
你可以在这里找到治理的具体细节。
架构结论
搭建 agent 很容易。但要让它们在既不掏空 API 预算、也不暴露内部网络的前提下扩展,才是真正的难点。
标准 MCP 路由在负载下会碎裂。引入中心化的 gateway 能终结上下文膨胀、强制执行高效,并把安全边界“硬编码”进去。它把一团乱麻的工具调用变成可治理的基础设施。
如果你想验证机制或拉取仓库,这里是主要入口:
更多关于 MCP 网关的落地实践,欢迎在 云栈社区 交流讨论。
 发表于 2026-4-27 23:45:04
|
查看: 249|
回复: 0
发表于 2026-4-27 23:45:04
|
查看: 249|
回复: 0
