导读
IBM Research 团队祭出一招狠的:用 64 个从未出现过的“乱码”token,替代 AI 动辄几千字的自然语言推理链。推理 token 压缩最高达 11.6 倍,准确率几乎原封不动。更诡异的是——这 64 个符号在训练中自发涌现出类似人类语言的频率分布规律。AI,正在发明自己的语言。
推理模型的“话痨”困境
你有没有想过,每次 ChatGPT 在后台“思考”的时候,它到底在干嘛?
答案是:写作文。
GPT-4o、Claude、DeepSeek-R1……当下所有主流推理模型都遵循同一套逻辑——先用自然语言写一篇“内心独白”,一步步拆解问题,然后才给出最终答案。这就是 Chain-of-Thought(思维链,CoT)推理。
问题是,这篇“内心独白”的成本惊人。一道高中数学题可能就要消耗几百个 token 的“思考”,竞赛级难题更是动辄几千个。每一个 token 都在烧算力、烧时间、烧你的 API 账单。
而这些 token 全都用完整的英语句子写成——主语、谓语、宾语、从句,一个都不少。
但 AI 真的需要这些语法结构来“想事情”吗?
64 个“乱码”:IBM 的疯狂实验
IBM Research 的 Keshav Ramji 团队给出了一个反直觉的答案。
他们从模型词表里划出 64 个从未使用过的特殊 token——<TOKEN_A>、<TOKEN_B>……一直到 <TOKEN_Z> 等等。这些 token 没有任何含义,就是一堆占位符。
然后,他们把整条推理链都替换成了这些符号。
没有主语。没有谓语。没有任何人类能读懂的语句。模型在回答问题之前,先生成一串最多 128 个这样的“乱码”token,然后根据这串符号给出最终答案。
听起来疯了?结果更疯。
“Researchers just taught AI to think 12x faster without using words.”
「研究者刚刚教会了 AI 在不用文字的情况下,思考速度提升 12 倍。」——AlphaSignal AI

▲ AlphaSignal AI 推文,8500+ 次浏览
从“乱码”到“语言”:两阶段炼成记
最大的技术难题在于:这 64 个 token 一开始啥也不代表,怎么让模型学会用它们“思考”?
IBM 的方案分两步走。
第一阶段:信息瓶颈热身
训练时,模型仍然能看到完整的语言推理链。但有一个关键设计——通过块结构注意力掩码,模型在生成最终答案时只能看到提示词和那串抽象 token,完全看不到语言推理链。
这等于在抽象 token 和语言推理链之间制造了一个“信息瓶颈”:如果模型想答对题,就必须把推理链里的关键信息“压缩”进那 64 个符号里。
然后是自蒸馏——模型扔掉语言推理链的“拐杖”,完全靠自己生成抽象 token 序列,再用这些自产序列继续训练。
两个步骤交替进行,64 个 token 的含义从零开始逐渐涌现。
第二阶段:强化学习加码
热身结束后,用 GRPO(群组相对策略优化)强化学习 进一步打磨。整个 RL 过程严格限制在那 64 个 token 的“私有词汇表”里,一个自然语言 token 都不许生成。
结果:11.6 倍压缩,精度几乎不掉
在 Qwen3(4B/8B/32B)和 Granite 4.0-Micro(3B)四个模型上,Abstract-CoT 的表现让人倒吸一口凉气:
MATH-500(数学推理):推理 token 压缩 10.4–11.6 倍,准确率从 92.6% 轻微下滑到 90.8%——只差了 1.8 个百分点。
AlpacaEval(指令跟随):压缩 1.9–2.2 倍,准确率 60.8% 反超基线的 58.4%——用更少的 token 反而做得更好。
HotpotQA(多跳推理):压缩 4.0–4.3 倍,精度基本持平。
GPQA-Diamond(研究生级科学问答):压缩 7.9 倍。
AIME'25(竞赛数学):压缩 2.7 倍。
做个直观换算:原来需要 1160 个 token 的推理链,现在只要 100 个“乱码”就能搞定。推理 API 账单直接打一折。
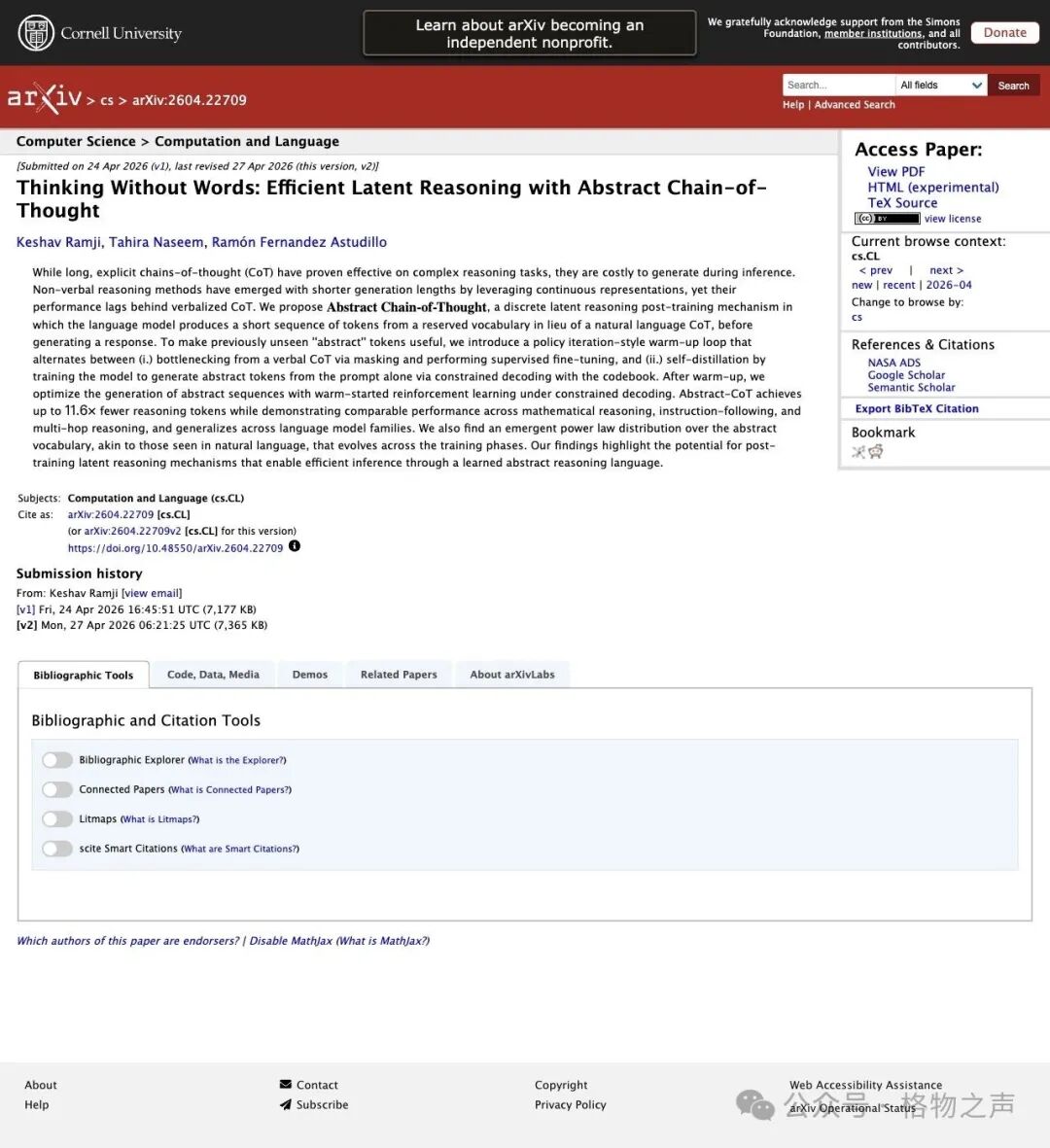
▲ 论文 arXiv:2604.22709,已提交至 ICLR 2026 LIT Workshop
最诡异的发现:AI 发明了自己的“语言规律”
如果说 11.6 倍压缩是工程成就,那接下来这个发现就带着几分“细思极恐”的味道了。
在强化学习阶段,研究者观察到一个没有被任何训练目标显式编码的现象:64 个抽象 token 的使用频率自发形成了幂律分布。
少数 token 被高频使用,大量 token 低频出现——这和人类语言中的 Zipf 定律如出一辙。在英语里,“the”、“of”、“and”这些高频词占据了文本的绝大部分,而大量生僻词出现频率极低。
AI 的 64 个“乱码”符号,竟然自发复现了同样的统计规律。
这意味着什么?某些抽象 token 承担了类似“常用概念”的功能,被反复调用于不同推理场景——模型在那个 64 符号的微型世界里,建起了一套有层级的“概念体系”。
“The emergent power-law patterns in the abstract vocabulary are striking.”
「抽象词汇表中涌现的幂律模式令人印象深刻。」——@avaisaziz

▲ alphaXiv 推文,近 1.4 万次浏览,290 赞
“用汇编语言思考”
社区反响激烈。最精准的类比来自 @sakurayukiai:
“Forcing models to output perfect English syntax just to update their hidden states has always been a massive waste of TPS. Abstract CoT is basically letting them think in assembly.”
「强迫模型输出完美的英语句法只是为了更新内部状态,这一直是对 TPS(每秒 token 数)的巨大浪费。Abstract CoT 基本上就是让它们用汇编语言思考。」
这个类比切中要害:高级编程语言方便人类阅读,但编译成汇编后执行效率高得多。AI 推理的本质需求是“更新内部状态”——它并不需要用人类语法来完成这件事。
对比另一种类似思路——“暂停 token”方法——直接插入特殊占位符让模型多“想”一会儿,但不做专门训练。结果?性能反而低于标准推理基线。Abstract-CoT 两阶段训练的精妙设计由此凸显。
黑箱之忧:看不懂的推理还能信吗?
也有人嗅到了危险的气息。
@Surreal_Intel 的评论一针见血:
“One awkward future problem: the model may reason better precisely when it becomes less narratable.”
「一个令人尴尬的未来问题:模型可能恰恰在变得不可叙述时推理得更好。」
如果 AI 用一套人类完全无法理解的“私有语言”进行推理,安全研究人员要怎么验证它的思考过程?当推理链从可读的英语变成 64 个符号的排列组合,可解释性直接归零。
这和当下 AI 安全领域追求“透明度”的方向构成了尖锐张力——效率和可控,可能无法兼得。
还有更根本的质疑。@P33RL3SS 直言:
“It's not reasoning, that's why it's not efficient or exact. It's just a chain of word outputs.”
「这根本称不上推理,所以才不高效也不精确。它只是一串词语输出而已。」
这个批评其实指向了所有基于 transformer 的 CoT 方法——抽象 token 到底是在“推理”,还是只是找到了一种更高效的“模式匹配”捷径?
别急着狂欢:几盆冷水
数据很亮眼,但也要看到另一面。
压缩率差异巨大。 11.6 倍只出现在数学推理任务上,指令跟随任务仅有 1.9 倍。不同场景下的收益天差地别。
精度确实有损失。 MATH-500 上 1.8 个百分点的下降,在竞赛场景下可能意味着从“通过”到“淘汰”的差距。
学术资历尚浅。 这是提交给 ICLR 2026 LIT Workshop 的论文,尚未经过完整的同行评审。有批评者指出论文可能遗漏了高度相关的先行工作。
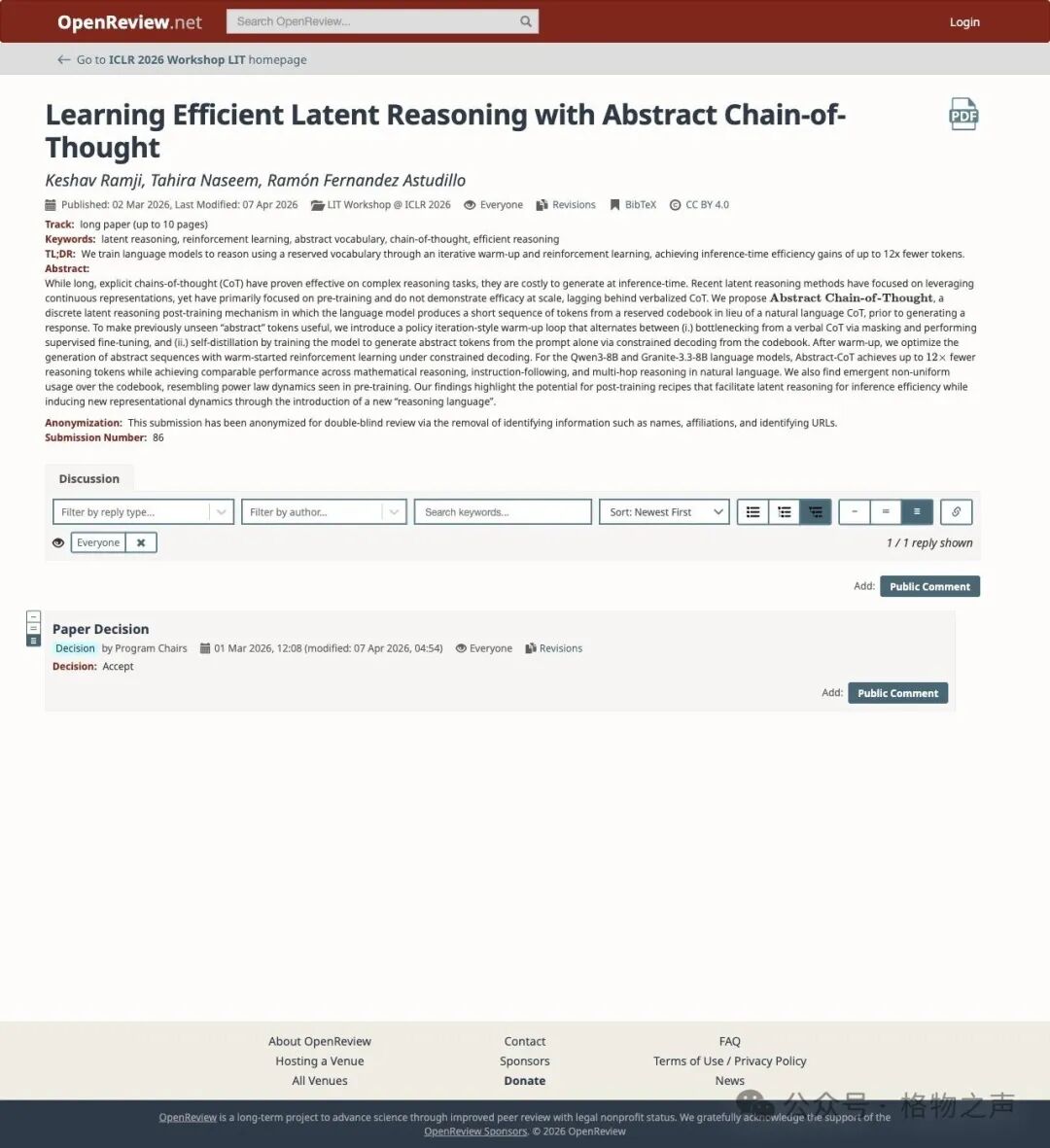
▲ ICLR 2026 LIT Workshop 提交页,确认该论文已被收录
AI 推理的下一章
回到最初的问题:AI 真的需要用文字来思考吗?
IBM 的实验给出了一个阶段性答案——至少在数学推理这类结构化任务上,倾向于“不需要”。64 个无意义的符号,经过精心设计的训练流程,可以承载原本需要上千个自然语言 token 才能表达的推理逻辑。

▲ 论文 HTML 全文首页,详细阐述了两阶段训练方案
这背后隐藏着一个更大的图景:推理 token 是当前 AI 模型最大的成本瓶颈之一。如果 Abstract-CoT 的思路能推广到更大的模型和更复杂的任务,推理 API 的成本结构可能迎来一次根本性的重塑。
但代价同样清晰:当 AI 的思考过程从人类可读的语言变成一串密码,我们和 AI 之间的最后一层“共同语言”也随之消失了。
效率的极限,可能就是透明度的终点。
对前沿 Transformer 推理机制与工程实践感兴趣的朋友,不妨常来 云栈社区 转转,这里有最硬核的技术讨论与资源分享。
— END —
 发表于 2026-5-4 19:56:44
|
查看: 110|
回复: 0
发表于 2026-5-4 19:56:44
|
查看: 110|
回复: 0
