在这个 RAG 系列中,我们已经深入探讨了召回优化、知识库构建、响应速度、生成阶段、Embedding 选型到 Query 路由等多个模块。
但后台一直有一个问题被反复问到:
“这些模块我单个都看懂了,但串在一起就懵了,面试官让我从 0 设计一个 RAG 系统,我不知道从哪开始讲、讲到哪结束。”
上周就有一位读者在面试京东时就被这个问题难住了。
面试官开门见山:“假设你现在负责从 0 搭建一个 RAG 问答系统,知识库有 5000 份文档,需要支持多轮对话,你怎么设计?”
他开始讲向量检索……
面试官立刻打断他:“等一下,用户的 query 进来之后,第一步做什么?是直接去检索吗?检索之前不需要做任何处理?”
他愣了一下,说先做 Embedding。
面试官继续追问:“做完 Embedding 就直接去向量库搜了?你的知识库是怎么建的?文档怎么解析的?Chunk 怎么切的?这些都不讲?”
他开始补讲离线流程,但逻辑已经乱了,一会儿讲检索,一会儿讲解析,一会儿又跳到生成,面试官听了两分钟就说了句“好了我了解了”。
这个问题的本质不是不懂技术,而是缺乏全局观。单个模块讲得再好,如果不知道它们之间如何配合、如何影响、如何取舍,在面试官眼中就成了“背了一堆知识点但没做过系统”。
今天这篇文章就是要帮你建立这个全局观,彻底理清 RAG 系统的设计脉络。
一、先画一张全景图:RAG 的四大模块
一个完整的 RAG 系统包含四个核心模块,按数据流顺序排列:
模块一:离线解析(知识库构建) —— 把原始文档变成可检索的结构化内容。负责文档解析、Chunk 切分、Embedding 向量化、向量入库。这是系统的地基,只需要执行一次或定期更新。
模块二:Query 理解(查询预处理) —— 用户 query 进来后,先“读懂”它,再决定怎么处理。包括意图识别、实体提取、Query 改写/扩写、检索路由决策。这是系统的“调度员”。
模块三:在线召回(检索与精排) —— 根据处理后的 query,从知识库中找到最相关的文档片段。包括向量检索、BM25 关键词检索、混合检索融合、Rerank 精排。这是系统的“搜索引擎”。
模块四:上下文生成(LLM 回答) —— 把检索到的片段和用户问题一起喂给 LLM,生成最终回答。包括 Prompt 构建、幻觉压制、多轮对话衔接、引用标注。这是系统面向用户的最终输出。
面试时,先把这四个模块按顺序清晰地列出来,面试官就能立刻意识到你脑子里有一张完整的架构图。然后再逐个展开深入讲解。
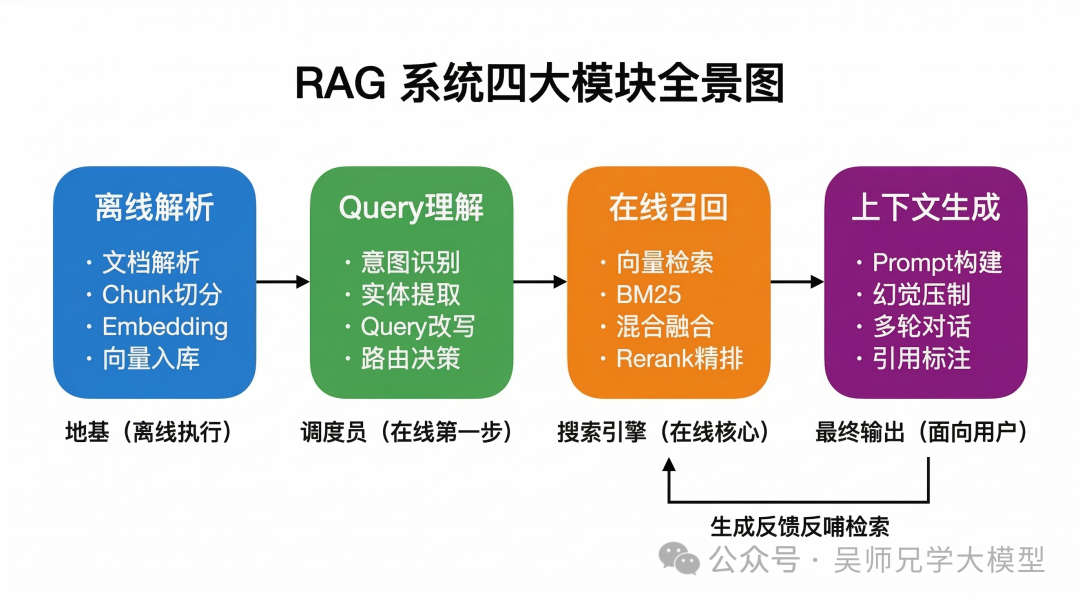
二、模块之间不是独立的——六个关键联动点
这正是大多数人缺失的部分。许多人把四个模块当成孤立的流水线,优化时头痛医头、脚痛医脚。但实际上模块之间有深度的相互影响,理解这些联动关系才是真正的 系统设计 能力。
联动一:离线解析 × 在线召回——Chunk 大小要配合 LLM 窗口
这是最容易被忽视但影响最大的联动。
Chunk 切得太大,LLM 的上下文窗口放不下几个片段,信息覆盖率低;Chunk 切得太小,每个片段语义残缺,检索时匹配不准,而且需要拼凑更多片段才能凑够上下文,容易信息散乱。
在实战项目中,最终确定的 Chunk 大小是 300-500 token,配合 50 token 的 overlap。这个数字不是拍脑袋定的,而是在“检索召回率”和“LLM 生成效果”之间反复实验出来的——Chunk 太短时 MRR 下降(语义不完整导致匹配不准),Chunk 太长时 LLM 回答质量下降(噪音太多)。
另外,离线阶段存储的元数据越丰富(文档来源、章节标题、发布时间、内容类型),在线召回时能做的过滤就越精准。例如用户问“最新的车险理赔流程”,如果离线阶段存了时间标签,在线就能直接加时间过滤;如果没存,就只能靠语义检索去猜测“最新”的含义,大概率会召回旧版本。
联动二:Query 理解 × 在线召回——解析结果直接指导检索策略
Query 理解模块的输出不是给人看的,是给检索模块用的。
意图识别的结果决定了走哪条检索链路——知识库检索、计算模块、NL2SQL 还是直接拒答。实体提取的结果决定了检索时加什么过滤条件——时间范围、文档来源、内容类别。Query 改写的结果决定了实际送入向量库的是什么文本。
如果这两个模块配合不好,会出现两种典型问题:一是解析准确但检索没用上(比如提取出了时间实体“昨天”,但检索模块没有对应的时间过滤逻辑),等于白解析;二是解析出错导致检索跑偏(比如意图识别错了,该走检索的去了计算模块),比不做解析还糟。
一个更进阶的联动是多索引路由:如果你的知识库按主题分成了多个索引(理赔制度、销售策略、产品信息各一个),Query 理解模块可以根据意图直接选择对应索引检索,而不是在全库里搜索。这样既提高精度又减少计算量。
联动三:在线召回 × 上下文生成——给 LLM 多少上下文是门学问
检索模块返回了 Top 10 个片段,是不是全部喂给 LLM?
不是。上下文过少信息不足,LLM 答不全;上下文过多噪音干扰,LLM 反而被不相关内容带偏。研究表明,LLM 更容易关注上下文开头和结尾的内容,中间部分容易被忽略——这就是所谓的 Lost in the Middle 问题。
在实战中,我们通过 Rerank 精排后只取 Top 5 个片段,并且把相关度最高的放在最前面。如果片段来自不同文档,在 Prompt 中用编号区分清楚。这样 LLM 既能获得足够的信息支撑,又不会被大量无关内容淹没。
另一个关键决策是上下文的组织方式。是按相关度排序?还是按文档原文顺序排列?实践中我们选择按相关度排序——让 LLM 先看到最重要的信息,减少它“忽略中间”的概率。
联动四:上下文生成 × 在线召回——生成反馈反哺检索
这是进阶玩法,也是面试的加分项。
如果 LLM 生成的回答是“无法从资料中找到答案”,说明检索可能没到位。系统可以自动判断这种情况,然后放宽检索条件(比如降低相似度阈值或换一种检索策略)重新检索,拿到新结果后让 LLM 再试一次。
这个闭环被称为反馈式检索——生成模块的输出反过来触发检索模块的重试。它让 RAG 系统从“单次检索”变成了“自适应检索”,对长尾问题的覆盖率有明显提升。
但要注意两点:一是设置重试上限(最多重试 1-2 次),避免无限循环;二是重试时要换策略而不是重复同样的操作,否则结果不会变。
联动五:全链路监控——在哪个环节掉链子?
RAG 系统出了问题,最难的不是修复,而是定位问题出在哪个模块。
用户说“回答不准”,到底是检索没找到正确文档(召回问题),还是找到了但 LLM 没用好(生成问题)?是 Query 理解把意图搞错了(路由问题),还是离线阶段文档解析就出了错(数据问题)?
解决方案是在每个模块的输出环节埋点记录:Query 理解模块记录识别出的意图和实体、召回模块记录返回的片段 ID 和相关度分数、生成模块记录 LLM 的回答和置信度。出了问题就沿着链路回溯,很快就能定位瓶颈。
在项目中,每周会抽查 50 个 badcase,按“解析问题/检索问题/生成问题”分类。连续三周发现某一类问题占比最高,就集中优化对应模块。这种数据驱动的迭代方式,比凭感觉调参靠谱得多。
联动六:缓存跨模块复用——空间换时间
缓存不是某一个模块的事,而是贯穿整个链路的。
Embedding 缓存:相同 query 的向量不需要重复计算,存在 Redis 里复用。检索结果缓存:高频问题的检索结果直接缓存,跳过向量库查询。答案缓存:FAQ 类问题直接缓存完整回答,实现毫秒级响应。
三层缓存配合使用,热门查询的端到端响应时间可以从秒级降到 50ms 以内。但要注意给缓存设 TTL(过期时间),知识库更新后旧缓存要及时清除。
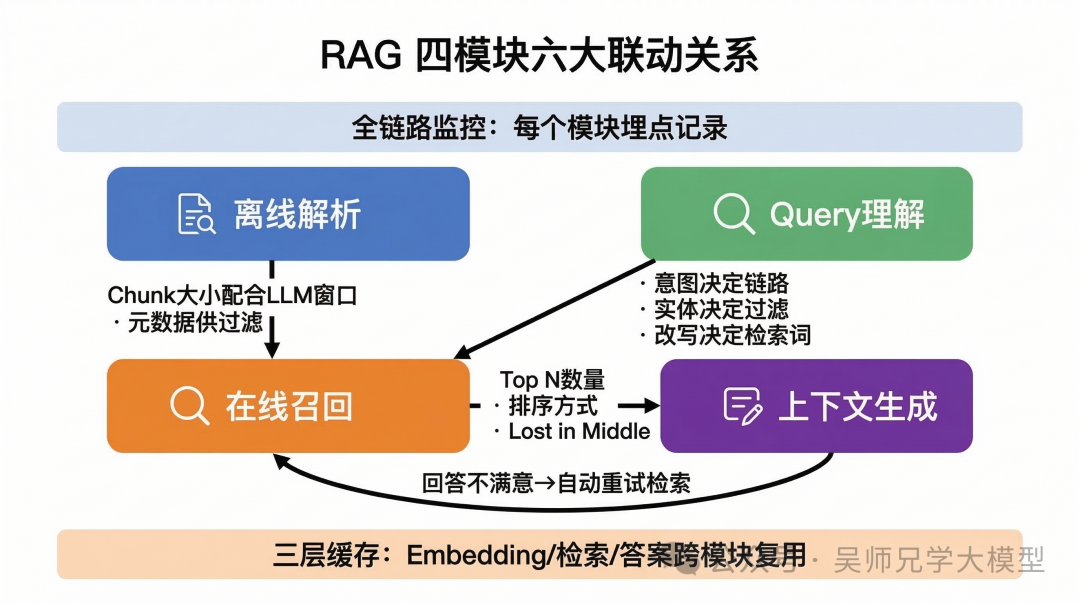
三、面试怎么答“从 0 设计 RAG 系统”?
这是面试中最高频的系统设计题。很多人一上来就开始讲技术细节,面试官根本跟不上。正确的回答框架是先全景后细节、先离线后在线:
第一步:画全景图(30 秒)。
“一个 RAG 系统包含四个核心模块:离线解析、Query 理解、在线召回、上下文生成。离线解析是地基,只需要执行一次;后面三个模块在每次用户查询时按顺序执行。”
第二步:讲离线流程(1 分钟)。
“首先是知识库构建。原始文档通过工具做版面分析和 OCR 提取结构化文本,然后基于文档层级结构做智能 Chunk 切分(300-500 token + 50 overlap),每个 Chunk 带上章节路径、内容类型、来源页码等元数据。最后用 BGE-M3 等模型生成 Embedding 向量,存入向量库(如 Milvus),同时建立 BM25 倒排索引以支持混合检索。”
第三步:讲在线流程(2 分钟)。
“用户 query 进来后,先经过 Query 理解模块做意图识别和实体提取,决定走检索、计算还是其他模块。走检索的话,对 query 做适当的改写和扩写后,同时发起向量检索和 BM25 关键词检索,用 RRF 等方法融合结果,再用 Cross-Encoder 等模型做精排取 Top 5。最后把精排后的片段和 query 一起构建 Prompt,喂给 LLM 生成回答,并在 Prompt 中要求模型标注引用来源。”
第四步:讲关键联动(1 分钟)。
“几个关键的模块联动:Chunk 大小要配合 LLM 上下文窗口,不能孤立调参;Query 理解的输出直接指导检索策略,比如提取出时间实体就自动加时间过滤;如果 LLM 回答‘不知道’,系统可以自动触发二次检索。整个链路设置三层缓存(Embedding/检索结果/答案)进行加速,热门查询可以做到 50ms 响应。”
四步讲完,面试官对你的全局设计能力就有了清晰的判断。然后他会挑某个模块深入追问——而这些追问的细节,通常就体现在你对这些联动关系的理解深度上。
写在最后
这篇文章是整个 RAG 系列设计的“总纲”。之前的文章深入各个模块,如召回优化、知识库构建等,今天这篇则把它们串成了一张完整的系统架构图。
如果你是跟着这个系列一路看过来的,现在回头看应该能感受到一件事,RAG 不是某一个技巧或组件,而是一整套系统工程。每个模块都有自己的优化空间,但真正决定系统效果上限的,是模块之间的精密配合和全局性取舍。
这也是面试官最想考察的:你是只会优化某一个环节的“螺丝钉”,还是能站在全局视角做出合理技术决策的“架构师”。更多关于系统架构和 AI 开发的深度讨论,欢迎到 云栈社区 交流分享。
 发表于 2026-3-21 01:35:20
|
查看: 108|
回复: 0
发表于 2026-3-21 01:35:20
|
查看: 108|
回复: 0
