在准备技术面试,尤其是后端开发岗位时,你很可能被问到这样几个问题:
- 为什么
TreeMap 的查询复杂度是 O(log N)?
- 为什么
HashMap 在 JDK 1.8 之后要将过长的链表转换成树?
- 跳表和红黑树在处理有序数据时有什么区别?
这些问题的答案,最终都会指向同一个核心的数据结构——红黑树。今天,我们就用一篇文章,从原理到实战,帮你彻底搞定红黑树的面试考点。
一、 红黑树是什么?
红黑树本质上是一种自平衡的二叉查找树。它在普通二叉搜索树(BST)的基础上,为每个节点增加了一个颜色属性(红色或黑色)。通过一系列精心设计的颜色约束规则,它可以确保从根节点到任何叶子节点的最长路径,不会超过最短路径的两倍,从而维持了树的近似平衡。正是这种平衡性,保证了红黑树在进行查找、插入和删除操作时,时间复杂度都能稳定在 O(log N)。
试想一下,如果是普通的二叉搜索树,最大的问题就是可能“退化”。比如按顺序插入 1, 2, 3, 4, 5,这棵树就会退化成一条链表:

此时,查找复杂度就退化成了 O(N),性能大打折扣。这就是 AVL 树、红黑树等自平衡二叉搜索树出现的原因,它们通过内部调整机制避免了退化。
那么,红黑树是如何做到这一点的呢?它依靠的是必须严格遵守的五大性质:
- 节点非红即黑。
- 根节点必须是黑色。
- 所有叶子节点(NIL,空节点)都是黑色。
- 红色节点的子节点必须是黑色(即不允许有两个连续的红色节点)。
- 从任意节点到其所有叶子节点的路径上,经过的黑色节点数量必须相同(这个数量被称为该节点的“黑高”)。
其中,第5条性质是核心。“黑高相同” 的约束,是保证树不会长得过高的关键,它确保了最长路径(红黑节点交替)不会超过最短路径(全黑节点)的两倍。
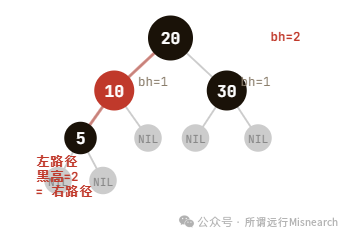
如上图所示,从根节点到各个叶子节点(NIL),经过的黑色节点数都是2,黑高一致。
当我们在红黑树中进行插入或删除操作时,可能会暂时破坏这些性质。这时就需要通过两种操作来修复:
- 变色:改变节点的颜色。
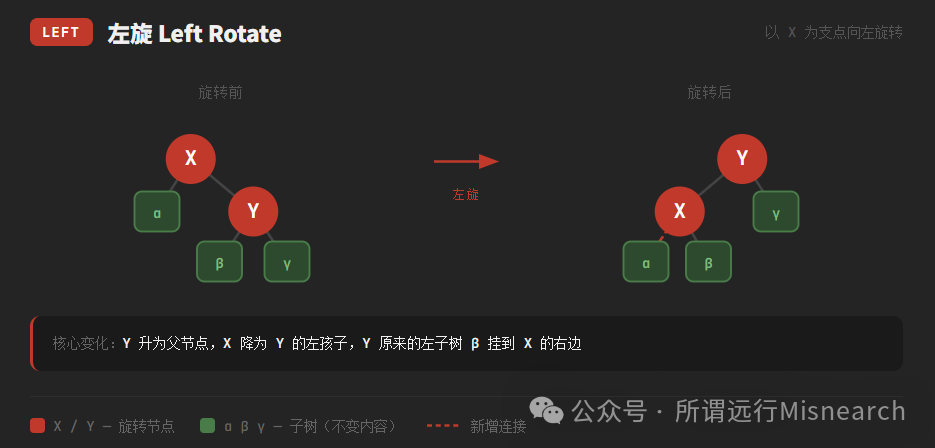
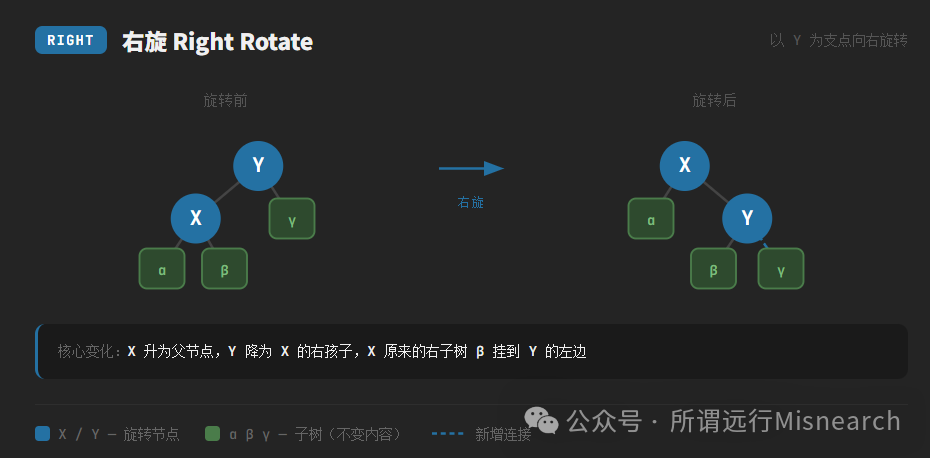
- 旋转:改变节点的父子关系,分为左旋和右旋。
旋转操作的时间复杂度是 O(1),其本质是在不改变树的中序遍历顺序(即不破坏二叉搜索树性质)的前提下,调整局部结构,以降低树的高度或重新满足黑高要求。
二、 Java 中的红黑树:应用场景
红黑树不仅是教科书上的经典算法,更是 Java 集合框架中不可或缺的基石。理解它在实际开发中的应用,能让你在回答面试问题时更有底气。
- TreeMap: 它的底层实现就是一棵红黑树,这也是为什么
TreeMap 能够保证键(key)始终处于有序状态。
- TreeSet: 作为
TreeMap 的“马甲”,TreeSet 的底层同样依赖红黑树来维护元素的有序性。
- HashMap (JDK 8+): 这是红黑树最著名的应用之一。当哈希冲突严重,导致某个桶(bucket)中的链表长度超过阈值(默认为8)并且当前哈希表容量大于等于64时,该链表会自动转换为红黑树,从而将最坏情况下的查找性能从 O(n) 优化到 O(log n)。
- LinkedHashMap: 它继承自
HashMap,因此也继承了链表转红黑树的优化机制。
如果你对 HashMap 如何利用红黑树优化性能的细节感兴趣,可以在 云栈社区的 Java 板块 找到更多深入的源码分析和讨论。
三、 红黑树高频面试题与回答精讲
掌握了基本原理和应用,我们来看看面试官最喜欢怎么问。
面试题1:请简述红黑树及其特性。
回答要点:
- 定义:一种通过颜色约束来保持近似平衡的自平衡二叉查找树。
- 五大性质(务必背熟,重点阐述性质4和5)。
- 时间复杂度:查找、插入、删除的平均和最坏时间复杂度均为 O(log n)。
高分回答示例:

面试题2:红黑树和 AVL 树有什么区别?
回答要点:
- 平衡标准:AVL 树是严格平衡(任意节点左右子树高度差 ≤ 1),红黑树是近似平衡(最长路径 ≤ 2倍最短路径)。
- 旋转频率:AVL 树在插入/删除时可能需要更多次旋转来维持严格平衡;红黑树通过放宽平衡条件,减少了旋转次数(插入最多2次,删除最多3次)。
- 适用场景:AVL 树适合查询密集、插入删除较少的场景(如数据库索引);红黑树在插入删除操作更频繁的工程实践中综合性能更好(如 Java 的
TreeMap)。
高分回答示例:

简单来说,红黑树牺牲了一点查询的极致性能,换来了更高的插入删除效率和更少的维护开销,这使其在多数工程场景中更具优势。
面试题3:Java 中哪些地方用到了红黑树?
回答要点:
- TreeMap / TreeSet: 基于红黑树实现,用于维护有序的键值对或元素集合。
- HashMap (Java 8+): 用于优化哈希冲突严重时链表的查询性能。
- LinkedHashMap: 继承自
HashMap,同样具备该优化。
高分回答示例:

面试题4:HashMap 在 Java 8 中为什么要引入红黑树?
回答要点:
- 解决性能瓶颈:在极端情况下(如哈希函数被恶意利用),大量元素会进入同一个桶,导致链表过长,查找退化为 O(n)。转换为红黑树可将最坏情况优化为 O(log n)。
- 精妙的阈值设计:链表长度 > 8 且数组容量 ≥ 64 时才树化;树节点数 < 6 时再退化为链表。中间预留了缓冲值7,避免频繁的树化与退化操作。
- 权衡的艺术:红黑树节点比链表节点占用更多内存,这是一种用空间换取时间稳定性的权衡。
高分回答示例:

面试题5:请描述红黑树的左旋和右旋操作。
回答要点:
- 目的:是红黑树在插入或删除后,用于局部调整结构、重新恢复平衡的基本操作。
- 过程简述:
- 左旋:以节点 X 为支点,将其右子节点 Y “提升”为新的父节点,X 则变成 Y 的左子节点,原 Y 的左子树变为 X 的右子树。
- 右旋:以节点 Y 为支点,将其左子节点 X “提升”为新的父节点,Y 则变成 X 的右子节点,原 X 的右子树变为 Y 的左子树。
- 复杂度:都是 O(1) 的常量级操作。
高分回答示例:

面试题6:红黑树的插入和删除过程是怎样的?
回答要点:
- 两阶段法:先像普通 BST 一样执行插入/删除,然后再通过一系列旋转和变色来修复可能被破坏的红黑树性质。
- 插入修复的三种典型情况(围绕新插入的红色节点、其父节点、叔叔节点和祖父节点展开):
- 叔叔节点是红色 -> 执行“变色”。
- 叔叔节点是黑色,且新节点是其父节点的内侧子孙 -> 先通过一次旋转转化为情况3。
- 叔叔节点是黑色,且新节点是其父节点的外侧子孙 -> 通过一次旋转并改变颜色完成修复。
- 删除更复杂:核心思想是,如果要删除的节点有两个非空子节点,会找其后继节点替代;在删除后,通过旋转和变色确保任何路径上的黑色节点数量(黑高)保持不变。
高分回答示例:

面试题7:你能手写一个红黑树的实现吗?
回答要点:
- 面试策略:通常不需要写出全部数百行代码,但必须清晰阐述核心思路和数据结构。
- 核心思路:
- 节点结构:包含 key, value, left, right, parent 指针以及 color 颜色标志。
- 插入方法:先按 BST 规则插入一个红色节点,然后调用
fixAfterInsertion 方法从该节点开始向上修复。
- 修复逻辑:核心是一个循环,根据父节点、叔叔节点、祖父节点的颜色以及当前节点的位置(左子/右子)来决定执行变色或哪种旋转。
示例回答思路:

可以说:“完整的红黑树实现代码较长,但我理解其核心是围绕这几种情况的修复循环。如果需要,我可以画出在特定插入顺序下,树是如何通过旋转和变色一步步调整的。”
面试题8:红黑树和 B+ 树有什么区别?
回答要点:
- 数据结构:红黑树是二叉树,每个节点最多两个子节点;B+ 树是多路搜索树,一个节点可以有多个子节点。
- 设计目标:红黑树主要针对内存操作优化;B+ 树的节点大小通常设计得与磁盘页对齐,旨在最小化磁盘 I/O 次数。
- 应用场景:红黑树用于内存中的有序结构(如
TreeMap);B+ 树广泛用于数据库索引和文件系统。
- MySQL的选择:MySQL 的 InnoDB 引擎使用 B+ 树,主要是因为它范围查询效率极高、所有数据记录都存放在叶子节点形成链表、并且树矮胖,能显著减少磁盘访问次数。
高分回答示例:

面试题9:为什么 Redis 的有序集合用跳表而不用红黑树?
回答要点:
- 实现复杂度:跳表的实现比红黑树简单得多,更容易调试和维护。
- 范围查询:跳表在进行范围查询(如 ZRANGE)时非常高效,因为底层就是有序链表。
- 并发控制:跳表的结构相对更容易进行无锁化或细粒度锁的优化。
- 权衡:虽然红黑树的平均性能可能略优,但跳表在实现简单性、可读性和特定操作(范围查询)上具有综合优势,这对于 Redis 这样的核心组件来说至关重要。
希望这份全面的指南能帮助你理清思路。红黑树相关的算法与数据结构问题确实是面试中的常客,深入理解其原理和设计哲学,远比死记硬背代码更有价值。如果你在准备技术面试求职的过程中遇到其他难题,也欢迎在技术社区交流讨论。
 发表于 2026-3-21 01:38:55
|
查看: 175|
回复: 0
发表于 2026-3-21 01:38:55
|
查看: 175|
回复: 0
