你是否有过这样的体验:用 ChatGPT 内置的图像编辑功能得心应手,但切换到几个开源工具时,效果却时常不尽如人意,甚至频频“翻车”?这并非错觉。当前,顶尖的闭源模型(例如 GPT-Image-1)与开源模型在图像编辑能力上的差距,正在被持续拉大。
究其根源,开源阵营往往缺乏两样关键资产:一是数量庞大且质量优异的训练数据,二是一套能够全面、准确“体检”模型能力的“诊断系统”。
数据生产的挑战在于,它如同走钢丝。纯手工打造的数据集固然质量上乘,但规模难以满足大模型训练的需求;而全自动流水线虽然能量产,却容易在多个环节累积误差——例如,第一步对物体的识别出现偏差,后续所有的编辑指令都会沿着错误的方向发展。
具体而言,现有的图像编辑数据生产方式存在三个主要短板:
- 误差链式传播:一个完整的编辑任务往往需要经过多个工具(如识别 → 分割 → 生成 → 融合),如同“传话游戏”,前一环节的微小偏差会被后续环节放大。
- 质检标准单一:要么只检查“是否生成了图像”而不深究其是否遵循了文本指令,要么投入高昂成本调用 API 来优化文本描述,却忽略了图像本身的视觉质量。
- 评估范围狭窄:现有的评测基准大多局限于“改变颜色”、“添加物体”等基础操作,缺乏对“从空中俯瞰这座建筑”这类空间理解任务,或是“将咖啡壶变为煮沸状态”这类需要常识推理的任务的考察。此外,评分标准本身也存在缺陷——例如,模型悄悄改变了非目标区域(背景)可能不会被察觉,而合理的风格化变化却可能被错误扣分。
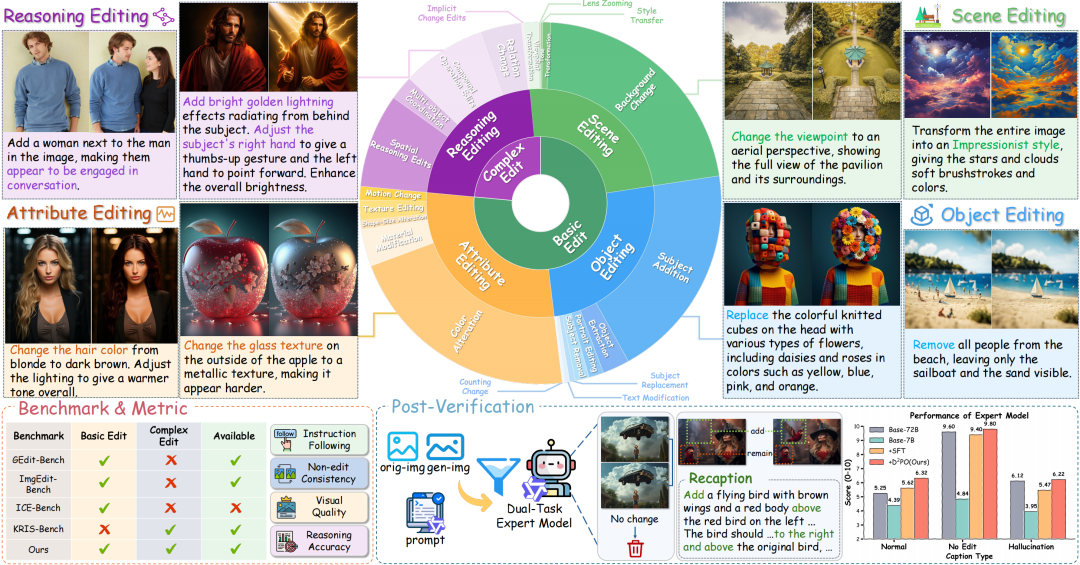
图1:UnicEdit-10M 数据集覆盖了跨越基础与复杂编辑的 22 种任务类型。该数据集采用统一的后验证流程,通过过滤失败样本并精炼指令来产出高质量数据。同时,研究团队还推出了配套的评测基准 UnicBench。
针对上述行业痛点,浙江大学与腾讯的研究团队联合进行了一次重要实践。他们不仅构建了一个包含约1000万组高质量样本的“图像编辑习题集”——UnicEdit-10M,还配套推出了一套涵盖22类难度递进任务的“全真模拟考卷”——UnicBench。简而言之,这项研究为 AI 图像编辑模型 领域提供了一套“标准化教材”与“标准化考试系统”。此外,团队还训练了一位“严格判官”(Qwen-Verify),对生成的编辑数据进行严格的筛选与指令优化,确保最终“习题”的答案既正确又优质。

论文标题:UnicEdit-10M: A Dataset and Benchmark Breaking the Scale-Quality Barrier via Unified Verification for Reasoning-Enriched Edits
核心亮点
- 大规模高质量数据集 UnicEdit-10M:构建了包含约1000万(10M)样本的高质量图像编辑数据集。它覆盖了22种编辑任务,不仅包含基础的属性与对象编辑,还涵盖了需要几何空间变换和基于知识推理的复杂任务。同时,该数据集的图像在美学评分上也超越了其他同类数据集。
- Qwen-Verify 后校验专家模型:训练了一个70亿(7B)参数规模的双任务专家模型。该模型能够同步执行细粒度的编辑失败检测与指令重写任务,在计算成本和经济成本远低于 Qwen2.5-VL-72B 的情况下,实现了更优的质检性能。
- UnicBench 综合评估基准:提出了一个覆盖基础编辑、几何空间变换以及基于推理的编辑任务的综合评测基准。它引入了“非编辑一致性”和“推理准确性”等新颖评估指标,能够全面诊断模型的编辑能力短板,为未来研究指明了清晰的方向。
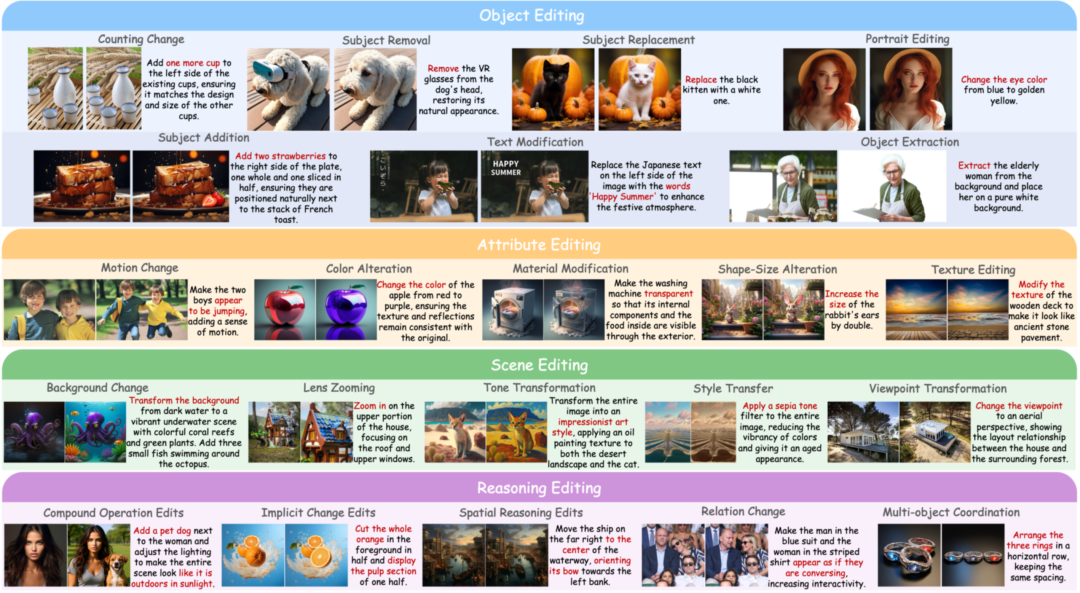
图2:UnicEdit-10M 中所有子任务类别的代表性编辑样例。
UnicEdit-10M数据集构建
UnicEdit-10M 的构建遵循一个高效的三阶段自动化流水线:
- 指令生成阶段:使用 Qwen2.5-VL-72B 模型,依据预定义的、均衡的编辑任务分类体系,为每张输入图像自动生成 3 到 7 个多样化且与图像内容相关的编辑指令,完全无需人工标注。
- 图像编辑阶段:使用 FLUX.1-Kontext 和 Qwen-Image-Edit 这两款领先的开源编辑模型,对每一个〈原始图像,编辑指令〉进行处理,生成编辑后的图像,形成初始的(原始图,指令,编辑图)三元组。在此阶段,源图像会经过中心裁剪和缩放预处理,并进行质量检查,丢弃那些需要裁剪超过20%区域以避免关键内容丢失的图像。
- 后校验阶段:所有自动合成的三元组都需经过统一的“后校验”环节。这一步不仅会过滤掉编辑失败的样本,还会对语义对齐不足的指令进行优化重写,确保指令精确匹配视觉上的变化。
最终构建的 UnicEdit-10M 数据集 包含约1000万个三元组,分为四大编辑类型:场景编辑(约306.3万样本)、属性编辑(约352.9万样本)、对象编辑(约324.2万样本)和推理编辑(约174.6万样本)。其中,50%的图像为1024×1024的高分辨率图像。
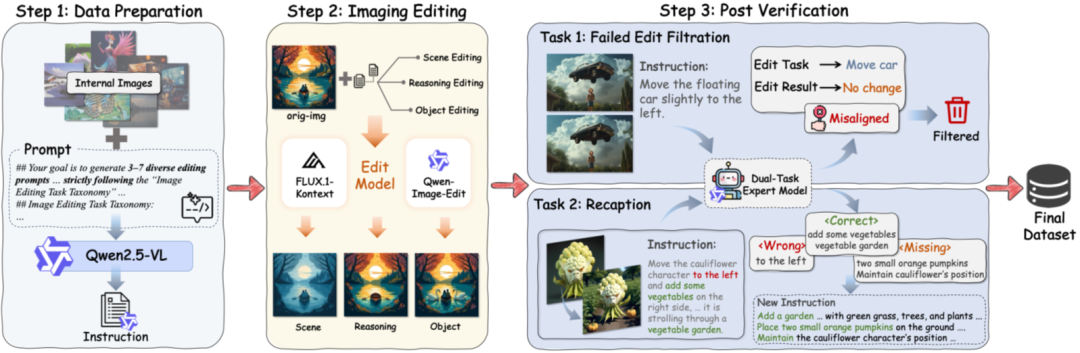
图3:数据构建的三阶段流水线:(1) 数据准备;(2) 图像编辑;(3) 后验证。后验证阶段用于过滤失败的编辑样本并进行指令重写(Recaption)。
后校验专家模型
在后校验阶段,为了实现更精准、高效的质量控制,作者训练了一个70亿参数的双任务后校验专家模型——Qwen-Verify。该模型通过使用人类标注的偏好数据进行偏好对齐,从而实现更可靠的数据筛选。它能同时执行两个关键任务:
- 编辑失败检测:能够细粒度地识别出编辑失败的样本,包括“无编辑”、“产生幻觉”等情况。与传统的 SSIM 等像素级指标相比,Qwen-Verify 具备深层语义理解能力,能准确识别出语义有变化但视觉差异细微的编辑,同时忽略生成过程中无关紧要的像素级噪声。
- 编辑指令重写:能够对那些与编辑结果语义对齐不足的原始指令进行重写,确保文本指令与实际发生的视觉变换精确匹配。
对比实验显示,Qwen-Verify 在正常编辑、无编辑和幻觉检测的准确率上,均显著优于 Qwen2.5-VL-7B、Qwen2.5-VL-72B 等基线模型。在关键的人脸一致性指标上,经 Qwen-Verify 校验后的 UnicEdit-10M 数据得分高达 0.89,远优于 GPT-Image-Edit-1.5M 数据集的 0.3025,展现了其在保持关键主体细节方面的卓越能力。
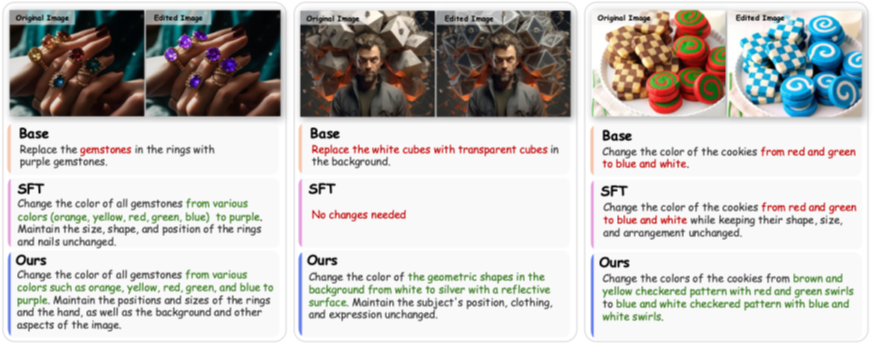
图4:后校验专家模型工作效果对比示例。其中:Base 表示 Qwen2.5-VL-7B 模型;SFT 表示经过第一阶段指令微调后的基础模型;Ours 表示本文提出的双任务专家模型 Qwen-Verify。
UnicBench:综合编辑能力评测
UnicBench 是一个旨在全面评估模型在基础编辑、几何空间变换以及基于推理的编辑任务上能力的综合基准。其构建采用了视觉语言模型(VLM)与人工审核相结合的工作流:首先由 Qwen2.5-VL 生成候选评测指令,再由人类专家进行审核,移除模糊或语义不一致的提示,并重写指令以精确匹配特定的编辑任务类别,每个类别包含 50 个测试用例。
为实现更精准的评估,UnicBench 引入了四个专门的评估指标:
- 指令遵循度(IF):通过基于 VLM 的跨模态对齐分数,衡量编辑后的图像满足原始指令要求的程度。
- 非编辑一致性(NC):评估非目标编辑区域的保留情况,对编辑区域之外发生的意外变化进行惩罚。
- 视觉质量(VQ):基于指令评估编辑后图像的自然度、整体连贯性以及视觉风格的一致性。
- 推理准确性(RA):针对需要知识推理的编辑任务,VLM 会利用一份经过人工核验优化的“推理要点”列表,与实际编辑变化进行对比打分。
对主流模型的评估结果揭示了几个关键发现:闭源模型在整体能力上显著优于开源模型,其中 GPT-Image-1 在英文和中文任务上均取得了最高的综合得分,展现了最优的通用编辑能力。在开源模型中,Qwen-Image-Edit 表现最佳,正在缩小与闭源模型的差距。
然而,一个普遍且突出的问题是:所有模型在“推理准确性(RA)”这一指标上均出现了显著的性能下降。这表明,当前模型在执行需要复杂逻辑推理或世界知识辅助的编辑任务时,存在普遍的局限性,这也为未来的研究方向提供了明确的指引。
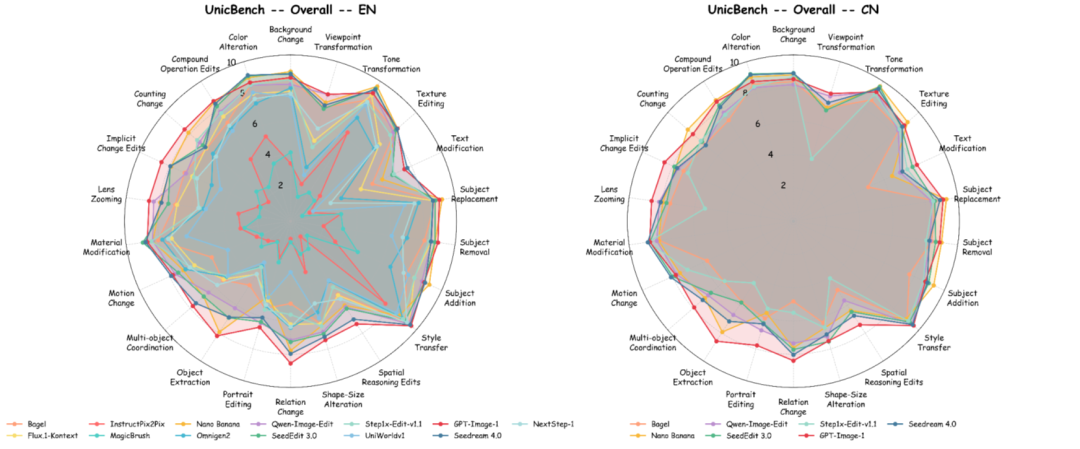
图5:各模型在 UnicBench 各子任务上的综合评分雷达图,左侧为英文(EN)指令结果,右侧为中文(CN)指令结果。所有结果均由 GPT-4o 进行评估。
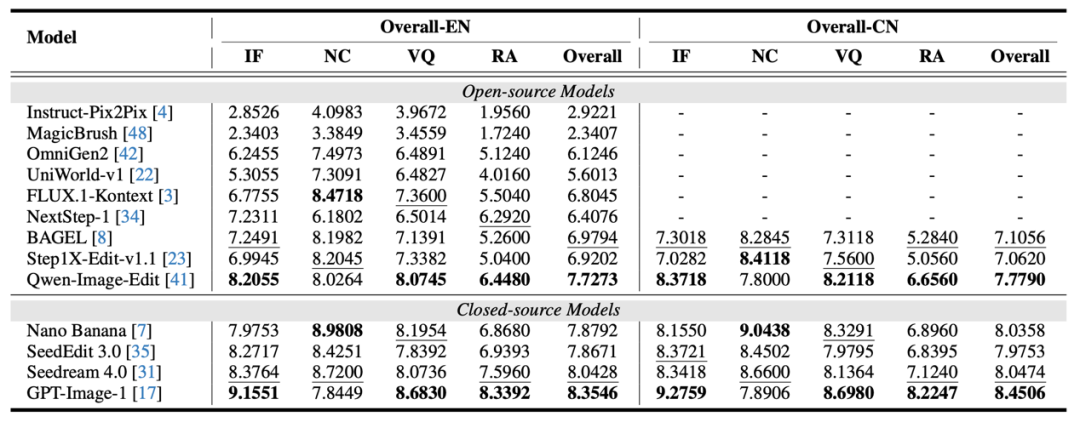
表1:不同模型在 UnicBench 上的综合性能表现。开源模型与闭源模型的结果分别列出,其中最优性能已加粗标出,次优性能以下划线标出。
这项由浙江大学与腾讯合作完成的工作,通过提供大规模高质量的数据集(UnicEdit-10M)和全面细致的评估体系(UnicBench),为开源图像编辑模型的发展提供了坚实的“基础设施”。它不仅有助于缩小开源与闭源模型之间的差距,也为整个社区探索更复杂、更可靠的图像编辑技术铺设了道路。对于从事相关研究和应用开发的开发者而言,这无疑是一个值得深入关注和利用的宝贵资源。想要了解更多前沿的AI技术与开源实战,欢迎持续关注云栈社区的更新。
 发表于 2026-3-21 02:18:17
|
查看: 159|
回复: 0
发表于 2026-3-21 02:18:17
|
查看: 159|
回复: 0
