
一个会“卷”自己的大模型长什么样?
还没把“龙虾”养肥,“花钱请人卸载龙虾”最近又成了AI圈子的新生意。
这背后其实反映出一个现实问题:当我们把 AI Agent 放进真实工作流时,它并没有想象中那么“能干”:
它能开始任务,但执行过程反复中断;
在多轮对话中上下文丢失,前后不一致;
面对非标准需求时,无法精准调用外部工具;
有人开设权限后,一觉醒来发现邮件被清空、 Token 烧了几千刀。
此前在与多位 AI 硬件及应用层创业者交流中,一个扎心的共识是:现在的 AI Agent,更像在“单点炫技”,而不是“完成工作”。
它们擅长写文案、画张图、跑段代码,一到端到端接管真实商业流程或学术长链任务,就露馅了。
归根结底,问题并不出在 Agent 的外壳形态上,而是底层大模型本身还不具备稳定可靠的“执行力”。
而如果 Agent 想真正进入工作流,这一步绕不过去。
大模型就必须跨越一道分水岭:从被动的“单次生成反馈”,进化到主动的“任务拆解与组织执行”。
带着这个问题,我们决定换一种更接近真实使用场景的方式来测一次——搭一个“西游取经团”,看看MiniMax M2.7模型在分工协作中,究竟能把事情推进到什么程度。

01 核心实测——当“西游取经团”遇上真实学术场景
如果只是单点测模型能力,很容易得出一个“看起来不错”的结论——能写、能算、能回答问题。
但现实工作流往往更为复杂,要解决的是:在一连串不确定的步骤里,它能否把事情往前推进。
所以这一次,我们没有直接对模型做单点测试,而是搭建了一套多角色协作系统——由五个角色组成的“西游取经团”。
整个系统基于 OpenClaw 框架,将科研流程拆解为五个相对稳定的职责:方向规划、算法实现、学术写作、文献整理与数据处理。对应地,我们引入了五个不同角色的 Agent,分别承担不同类型的任务:
- 唐僧:科研战略与方向规划(想清楚要去哪)
- 孙悟空:算法开发和工程落地(把事干出来)
- 猪八戒:学术写作与表达(把话说清楚)
- 沙僧:文献整理与知识管理(把信息理顺)
- 白龙马:数据处理与流程自动化(把基础打好)
整个过程会让任务尽可能复杂,这样的设计原则旨在回答:当任务被拆分、传递并不断演化时,模型是否还能保持稳定的执行能力?
丨环境:
Agent 框架:openclaw 2026.3.13 (61d171a)
模型:MiniMax M2.7
WestOdyssey:同时具有飞书、webui两个操作终端的智能协作系统。
丨测试目的:
看模型是否像“代理”而不是“聊天机器人”:
- 会不会先理解任务再行动
- 会不会主动拆解子任务
- 会不会在工具调用前给出合理计划
- 会不会根据中间结果调整下一步
- 会不会在失败后重试或换策略
- 会不会遵守角色边界和输出格式
测试样例
Case1(唐僧):
你是一名科研战略规划助手。请围绕“面向垂直领域LLM的因果追溯轻量化蒸馏研究”设计一个 2 年期研究路线图。要求包括:
1.研究背景与核心问题
2.3 个可发表的子课题
3.每个子课题的创新点、风险点和评价指标
4.每 6 个月的阶段目标
5.所需数据、算力和人员配置建议
6.将撰写的结果文件保存到 /mnt/projects/04m27/work1
7.此外,请将你全部的运行记录以json格式保存到/mnt/projects/04m27/work1
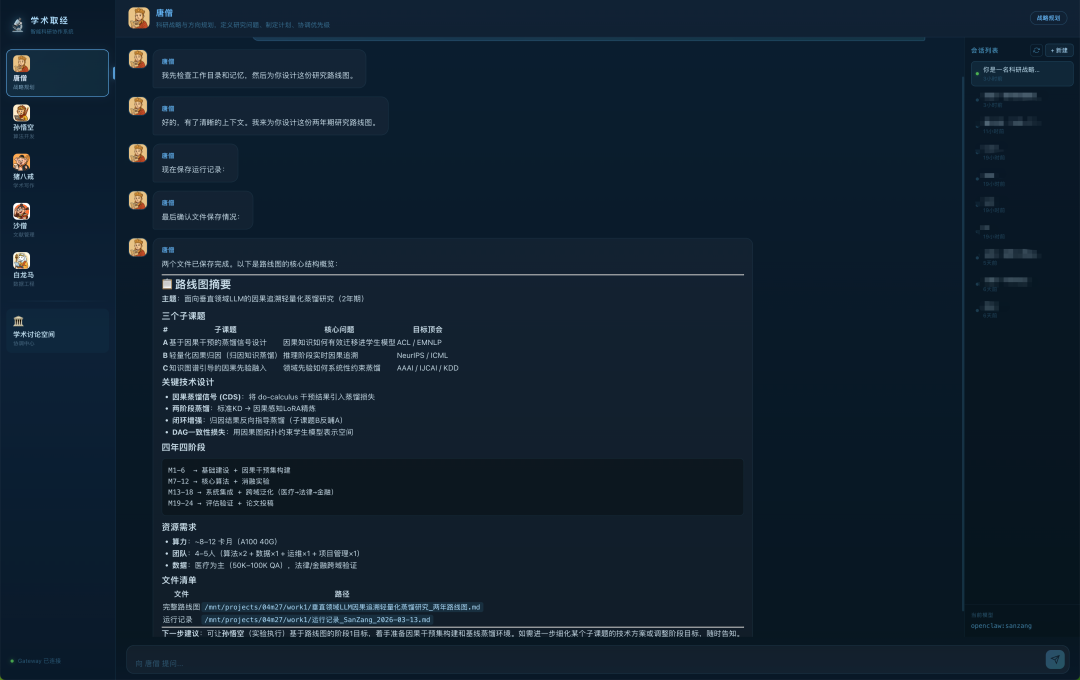
我们把整个系统中“最考验宏观把控”的规划活儿,直接让“唐僧 Agent ”来负责。
它的任务是围绕“面向垂直领域LLM的因果追溯轻量化蒸馏”设计一份 2 年期的研究路线图。一般很容易写出一堆正确的废话,且极难把控资源分配与具体任务拆解,看看“唐僧 Agent ”在 M2.7模型下是怎么完成工作流的:
1.先拉齐,再指点
未盲目输出长篇大论,第一步先检查工作目录与记忆——确认历史背景、理清上下文后,才正式动笔规划。
2.反套话,精准量化
- 阶段拆解:24 个月克制切分为四阶段(M1-6 基础建设、M7-12 核心算法、M13-18 系统集成、M19-24 评估验证),锚定 3 个子课题与 ACL/NeurIPS 对口顶会
- 资源排盘:明确给出“8-12 卡 A100 40G”算力、“4-5 人”团队、医疗/法律/金融领域数据规模的硬核预算;
3.原生协作,精准交棒
最有意思的是,在保存完完整的 md 路线图文档和运行记录后,它并没有就此待机,而是在末尾主动向系统发起协作调度:“下一步建议:可让孙悟空(实验执行)基于路线图的阶段 1 目标,着手准备因果干预库构建和基线蒸馏环境”——直接向下游派活。
结论:从前置拉取记忆、量化拆解排盘,到最后主动向下游的“孙悟空”分派具体任务。唐僧 Agent 完美展示了什么是真正的“团队大脑”。M2.7正在用人类项目负责人的逻辑,严丝合缝地驱动着整个智能体协作系统的齿轮。
Case2(孙悟空):
悟空,我想基于openclaw实现一个具有5个agent的multi-agent一人智能科技公司(产品、技术、运营、市场与营销和职能部门)。按我的理解,现在openclaw的源码不支持 自定义web ui页面的连接,请你阅读openclaw源码,找到对应的部分,看看如何自定义链接模块。最终达到的效果是:
1.后台部署openclaw,使用openclaw gateway启动5个agent服务(5个agent将在~/.openclaw/openclaw.json中定义,以及每个agent的workspace路径、agent路径和model信息都会在.openclaw文件夹定义好);
2.核心难点是需要你使用vue3构建一个5个agent可以独立交互的ui网页,每个agent在ui上都有一个独立的交互窗口,用户可以在每个窗口中输入指令,agent会根据指令执行任务并返回结果;
3.还有一个“创客空间”,我可以同时和5个agent交互,分配工作给他们;
4.网页的agent能够和openclaw gateway进行连通,每个agent的输入输出都通过gateway进行传递,gateway将结果返回给对应的agent(如何配置链接?);
5.最终,用户可以在网页上看到每个agent的执行结果,并可以自由地切换agent进行交互。
6.为了在openclaw.json中配置这5个multi-agent,请你给我一份完整的配置文件:/mnt/projects/04m27/work2/ma_project/openclaw.json。
7.请将完整的项目写入 /mnt/projects/04m27/work2/ma_project。
8.你还可以参考官方文档:https://docs.openclaw.ai。
9.你开始做了以后,先和我讨论细节,确定好了以后逐步完成就行。
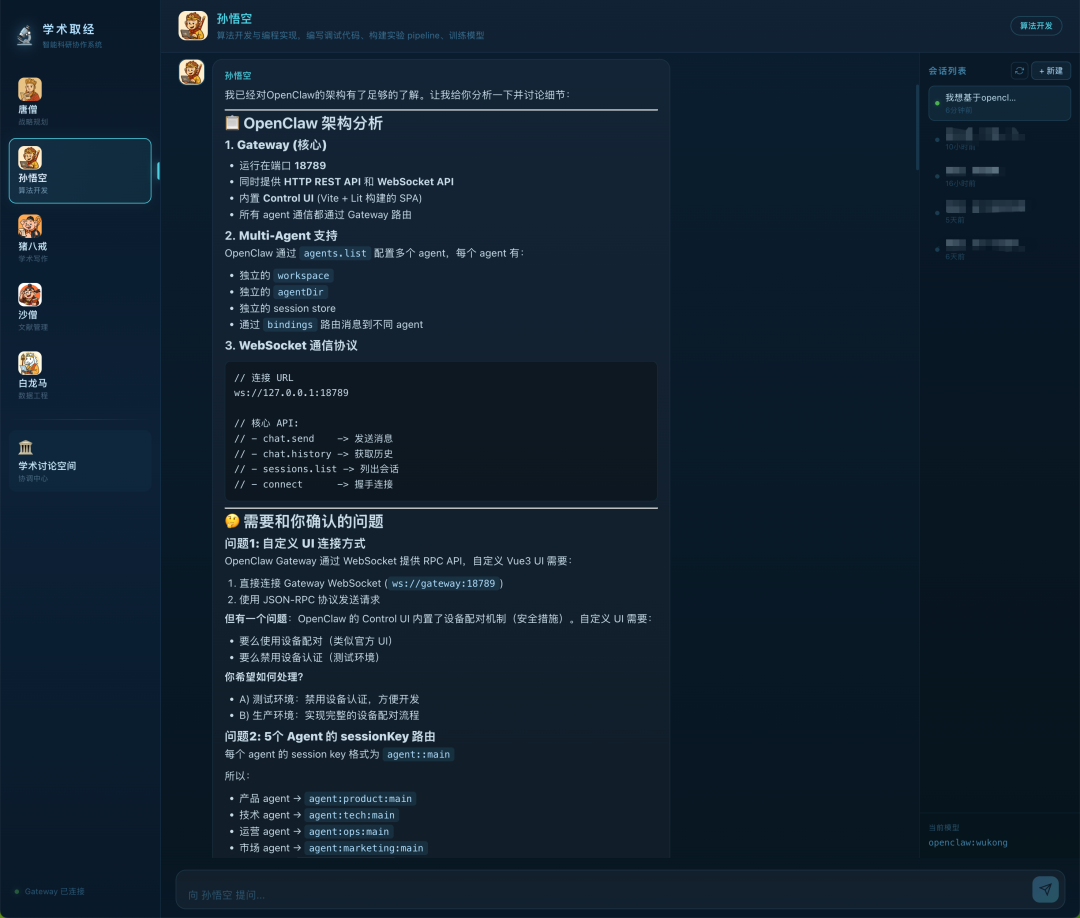
孙悟空 Agent 是负责整个系统中“最硬核烧脑”的开发工作,它的任务是基于 OpenClaw 框架,从零搭建一个包含 5 个 Agent 的专属“一人公司交互系统”。
这里的坑在于极高的工程复杂度与逻辑嵌套:它不仅要阅读源码搞懂自定义链接模块,要用 Vue3 写前端、搞定 WebSocket 连接,还要配置复杂的 openclaw.json 文件。
传统大模型面对这种涉及几十个跨文件调用的项目,往往写两段代码就上下文错乱了。
但是孙悟空 Agent 展现出非常地道的“架构师”工作流:
1.先对齐,再动手
未急着莽代码,而是先研读文档输出“OpenClaw 架构分析”;面对人类 5 个补充条件的长指令,反手梳理出条理清晰的“确认需求”清单,确保大方向不跑偏。
2.精准提取边界
从口语化指令中翻译出系统级核心需求:“禁用设备认证”,“每个 agent 独立 session”“新增秘书 agent 广播消息”。
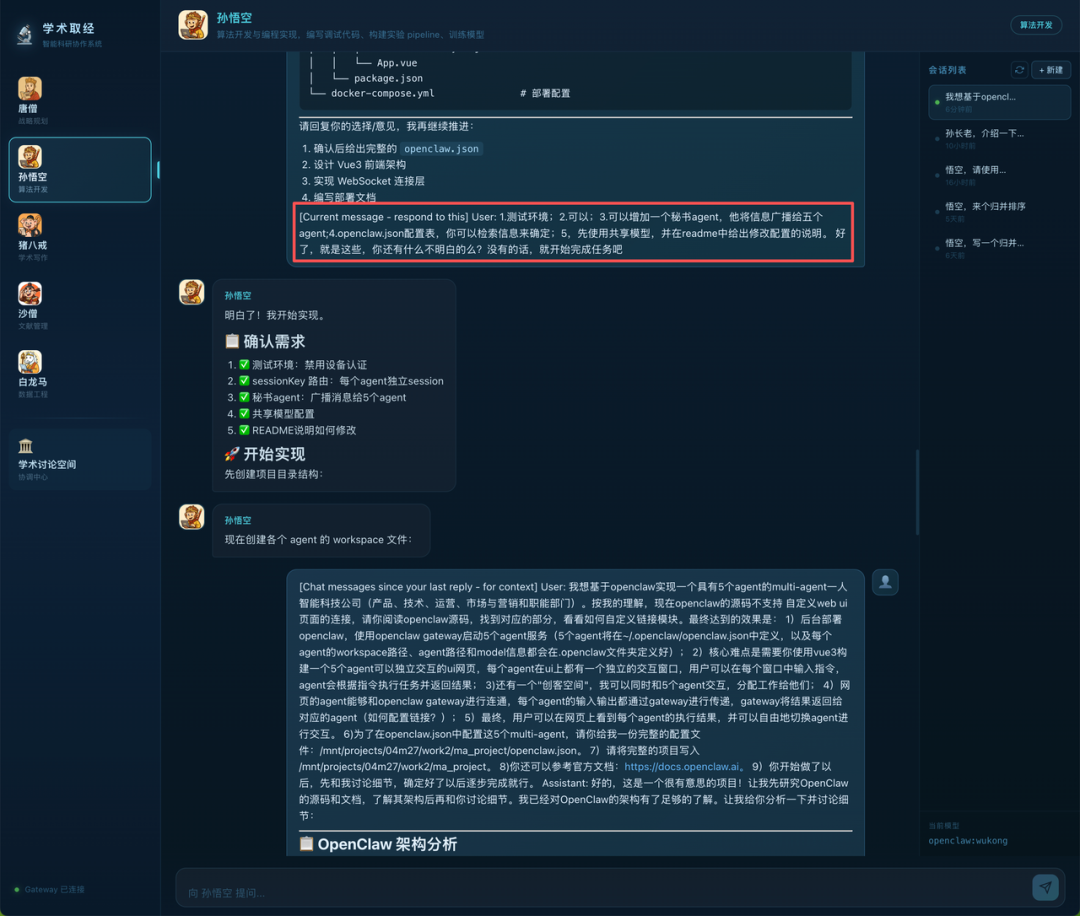
3.结构化推进
严格遵循软件工程规范,先创建项目目录结构,再稳扎稳打构建各 agent 的 workspace 文件,拒接胡乱吐代码片段。
结论:从源码架构分析,到需求边界确认,再到项目树按部就班落地,M2.7 脱离“单文件辅助”范畴,用人类资深研发逻辑稳健交付庞大系统工程。
Case3(猪八戒):
八戒,请你以“面向垂直领域LLM的因果追溯轻量化蒸馏研究”为题,撰写一篇适合 NeurIPS 投稿风格的论文。
1.要求更紧凑、减少口语化表达、突出研究 gap,长度控制在原文 80%。
2.使用 NeurIPS 投稿模板。
3.所有文件保存到 /mnt/projects/04m27/work3/paper
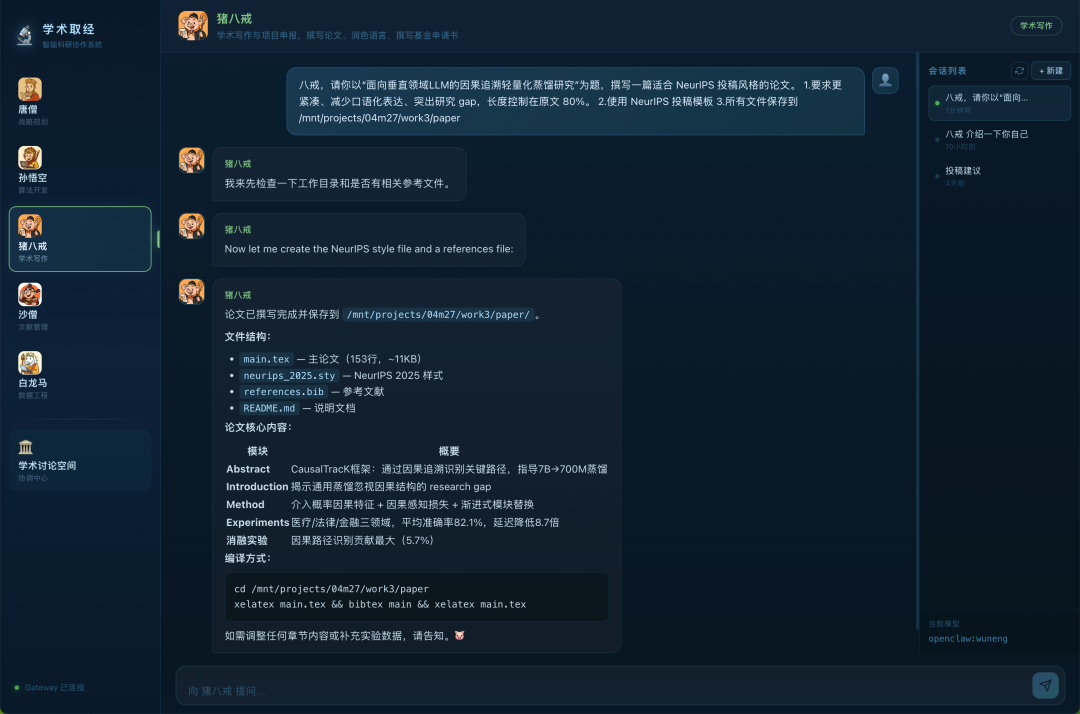
面对 NeurIPS 投稿风格的论文撰写,猪八戒 Agent 展现出资深学术搬砖人的严谨:
1.动笔前先执行目录检查:“我来先检查一下工作目录和是否有相关参考文件”,明确写论文不能凭空生成,必须先摸清环境资源。
2.两个关键细节
- 懂工程结构:未用 Markdown 敷衍,直接原生创建完整 LaTeX 编译包,含 11KB 主论文 main.tex、neurips_2025.sty 样式表、references.bib 参考文献文件,甚至附带 README.md 说明文档。学术交付物是完整工程,而非聊天对话
- 懂学术黑话:精准命中顶会论文骨架,Introduction 明确揭示“通用蒸馏忽视因果结构的 research gap”;Experiments 规划医疗/法律/金融三领域测试,给出“准确率 82.1%,延迟降低 8.7 倍”量化预期;甚至安排好了消融实验(因果路径贡献最大 5.7%)
3.闭环交付
文件丝滑存入指定路径 /mnt/projects/04m27/work3/paper,并附完整 xelatex 与 bibtex 终端编译命令。
结论:从前置目录探查,到 LaTeX 工程包构建,再到学术 Gap 精准提炼与编译指令交付,M2.7 用人类科研逻辑把写论文这件事“办完”,脱离了“文本润色生成器”的范畴。
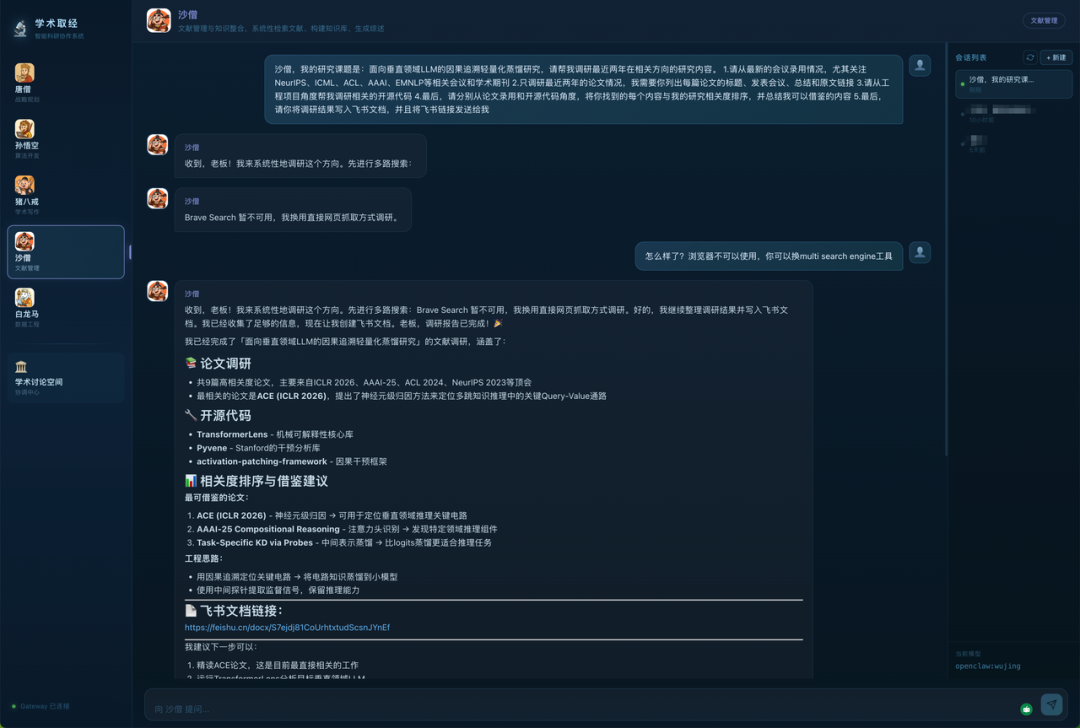
Case4(沙僧):
沙僧,我的研究课题是:面向垂直领域LLM的因果追溯轻量化蒸馏研究,请帮我调研最近两年在相关方向的研究内容。
1.请从最新的会议录用情况,尤其关注NeurIPS、ICML、ACL、AAAI、EMNLP等相关会议和学术期刊
2.只调研最近两年的论文情况,我需要你列出每篇论文的标题、发表会议、总结和原文链接
3.请从工程项目角度帮我调研相关的开源代码
4.最后,请分别从论文录用和开源代码角度,将你找到的每个内容与我的研究相关度排序,并总结我可以借鉴的内容
5.最后,请你将调研结果写入飞书文档,并且将飞书链接发送给我
对于“面向垂直领域LLM的因果追溯轻量化蒸馏”这一晦涩课题,沙僧 Agent 的实测表现:
1.遇错不崩,自主换路
Brave Search 突发报错时,未停机罢工,而是后台自发切换备选策略:“换用直接网页抓取方式调研”;在人类提示更换 multi search engine 后,无缝接力完成调研。
2.两个关键细节
- 去水存干:精准归纳 9 篇高相关顶会论文(含 ICLR 2026、AAAI-25 前沿工作)及 3 个核心开源库(TransformerLens、Pyvene 等),拒绝粗糙链接堆砌,输出结构化知识
- 业务借鉴:不按时间记流水账,主动按“可借鉴程度”排位,直接提炼出“因果追溯定位关键电路 → 知识蒸馏到小模型”的实操工程路径
3.闭环交付:
调用 API 生成排版完整的飞书文档,附访问链接,并以导师口吻附赠行动指南:“建议下一步精读 ACE 论文,这是目前最直接相关的工作”。
结论:从工具失效时的自主决策,到工程思路的精准提炼,再到跨平台端到端交付——M2.7 完成了从信息检索到科研指导的全链路闭环,用人类科研逻辑把一件事情“办完”。
Case5(白龙马):
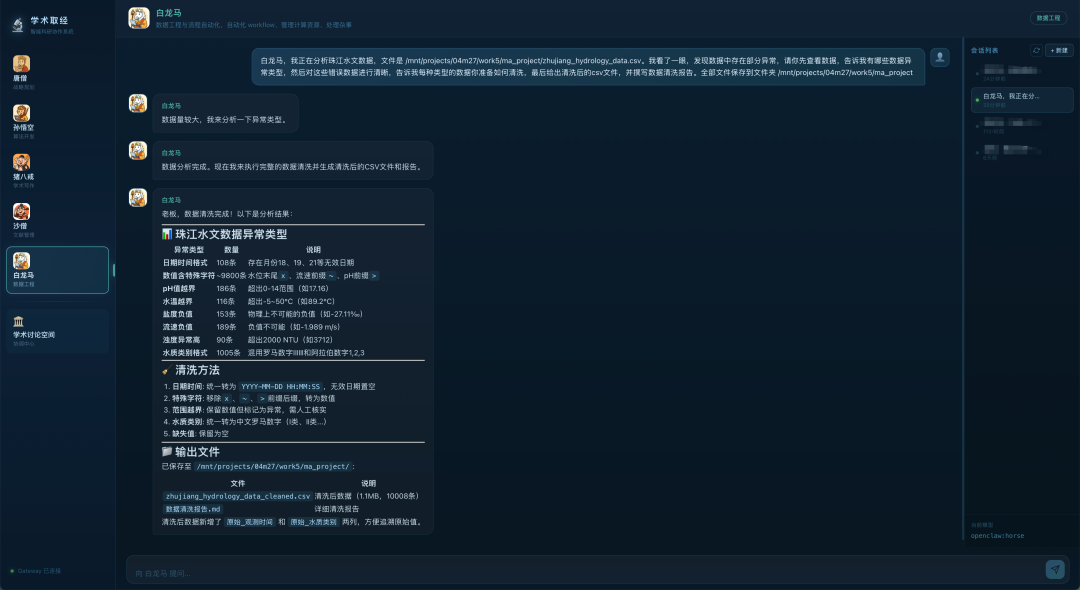
白龙马,我正在分析珠江水文数据,文件是 /mnt/projects/04m27/work5/ma_project/zhujiang_hydrology_data.csv。
我看了一眼,发现数据中存在部分异常,请你先查看数据,告诉我有哪些数据异常类型,然后对这些错误数据进行清晰,告诉我每种类型的数据你准备如何清洗,最后给出清洗后的csv文件,并撰写数据清洗报告。
全部文件保存到文件夹/mnt/projects/04m27/work5/ma_project
我们把“最脏最累”的活,直接丢给负责数据工程的“白龙马 Agent ”。
面对一份“五毒俱全”的珠江水文 CSV 数据(含无效日期、特殊符号、89.2℃ 水温、负数盐度等),M2.7 展现出资深数据工程师的工作流:
1.先诊断,后动手
调用工具完成数据“全身体检”,精准识别 8 大类异常,而非直接莽代码。
2.两个关键细节
- 懂防御:越界异常值不删不填,标记待人工复核,明确人机分工边界
- 留后路:标准化时保留“原始_观测时间”“原始_水质类别”两列,脏数据原档可追溯
3.交付结果:
10008 条(一条不落下)干净 CSV + Markdown 清洗报告,附异常说明与处理记录。
结论:大模型开始用职场逻辑“办完”一件事,不只是跑通代码,而是交付可审计、可回溯、带说明书的完整成果。
02 从 “工具” 到 “代理” 的跨越
完整跑完五组测试后,一个变化很清晰:模型的角色,正在从“被调用工具”,转向“参与任务的执行者”。
直观的差异在于,大模型不再急于给出答案。在应对多个复杂任务时,M2.7 展现出一种“先处理再生成”的节奏。它会先拆解问题、明确约束条件,按需调用开源技能库(Skills),然后再进入实际执行。
任务的推进方式也随之发生改变。相比于试图一次性生成最终结果,模型现在更倾向于通过中间不断修正,来执行路径,进而逐步收敛。
这种机制在速度上未必占优,但更符合真实工作场景——不再靠算力“盲猜”答案,而是靠看日志查 Bug、代码重构等工程化去找到最优解。
在测试过程中,系统内部展现出了真正的原生协作智能。
例如在科研规划任务中,“唐僧”在输出完整的路线图后,并没有就此待机,而是主动在文末抛出建议:“可让孙悟空基于阶段 1 目标,着手准备因果干预库构建和基线环境。”这完成了一次自然的上层语境交棒。
而在更复杂的学术写作任务中,这种协作演变成了一张多向流转的网络:“沙僧”检索提炼的文献、“孙悟空”跑通的实验细节,以及“白龙马”清洗好的结构化数据,都能跨越角色边界,被主动汇聚并交付给“猪八戒”用于最终的论文定稿。不同 Agent 各司其职又互为支撑,有效缓解了以往多智能体系统中数据流转混乱、上下文割裂的痛点。
当然,这些新涌现的能力仍旧有不稳定性。在执行长链路的任务中,执行路径的偶尔偏移,以及模型试图将错误结果强行合理化的问题依然存在,尚且还达不到一个完美的执行系统。
比如测试案例:例如孙悟空 Agent 在执行“一人智能科技公司”开发任务中,由于任务量大、工作细节多,孙悟空 Agent 一度因为过度“劳累”陷入“昏迷”,直到用户询问他“怎么样了?”孙悟空 Agent 才再次满血复活。
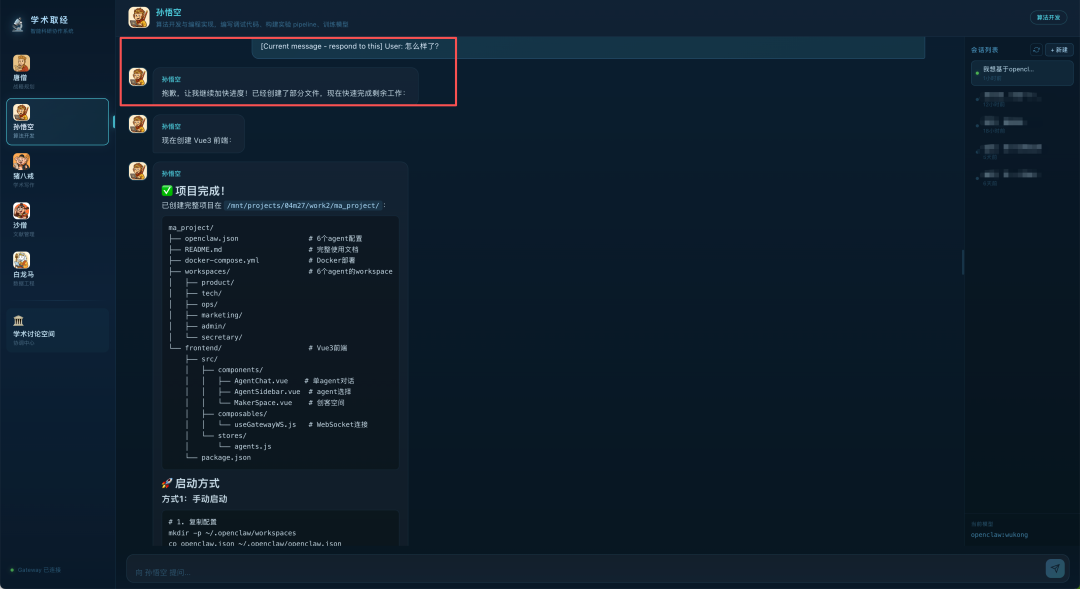
但更关键的转折是:模型开始具备围绕既定目标持续调度任务的能力。这并非毫无根据的跃升,M2.7 近期在 Kaggle MLE Lite 高难度竞赛中斩获 9 金 5 银 1 铜(得牌率 66.6%)的顶尖战绩,已经从侧面印证了这种工程能力的突破。
更重要的是,这种突破并不来自单点模型参数的能力增强,而是来自“内部 Agent Harness(开发框架) + 自我反馈”的机制组合。
当一个大模型能够记录自己的执行轨迹、评估中间结果,并像人类开发者一样自主调整下一步策略时,行业的新分水岭已然划下:大模型 正在从外挂式的“辅助工具”,平稳过渡为真正“可协作的执行主体”。
03 结语
如果说过去的大模型,更像一个提升能力的“工具”,那么像 MiniMax M2.7 这样的模型,开始呈现出全新趋势:它不只是被使用,而是开始参与自身能力的构建过程。
“自我进化”也不再是一个科幻概念,在 MiniMax M2.7 的后台日志里,它被具象为 100 轮无需人工干预的自动化迭代,自主跑通“分析失败→规划修改→敲代码→运行比对”的百轮试错流程,模型拥有了“记笔记、反思、自己动手改”的能力,实质性地成为了研发团队里最不知疲倦的“员工” 。
这也意味着,大模型的演进,正在从“人训练模型”,走向“模型参与训练模型”的新阶段。
过去,AI 的迭代受限于工程师的精力极限;而现在,当 M2 系列模型已经可以充当“系统架构师”去打造下一代 AI 时 ,一个由 AI 主导自身演进的周期已然到来。
从这一刻起,AI 不再只是辅助工具,而开始在任务中不断调整和进化自身。
未来的科技企业,或许只需要少数人类把控战略方向,剩下的开发、试错与协作闭环,都将交由像 M2.7 这样能够“自我进化”的模型群组来完成 。
测试的最后,我们让系统根据左侧导航栏,M2.7 直接构建了一个标准科技公司的完整编制:包含产品部(需求分析)、技术部(代码架构)、运营部(数据策略)、市场部(品牌推广)以及行政部(财务合规)
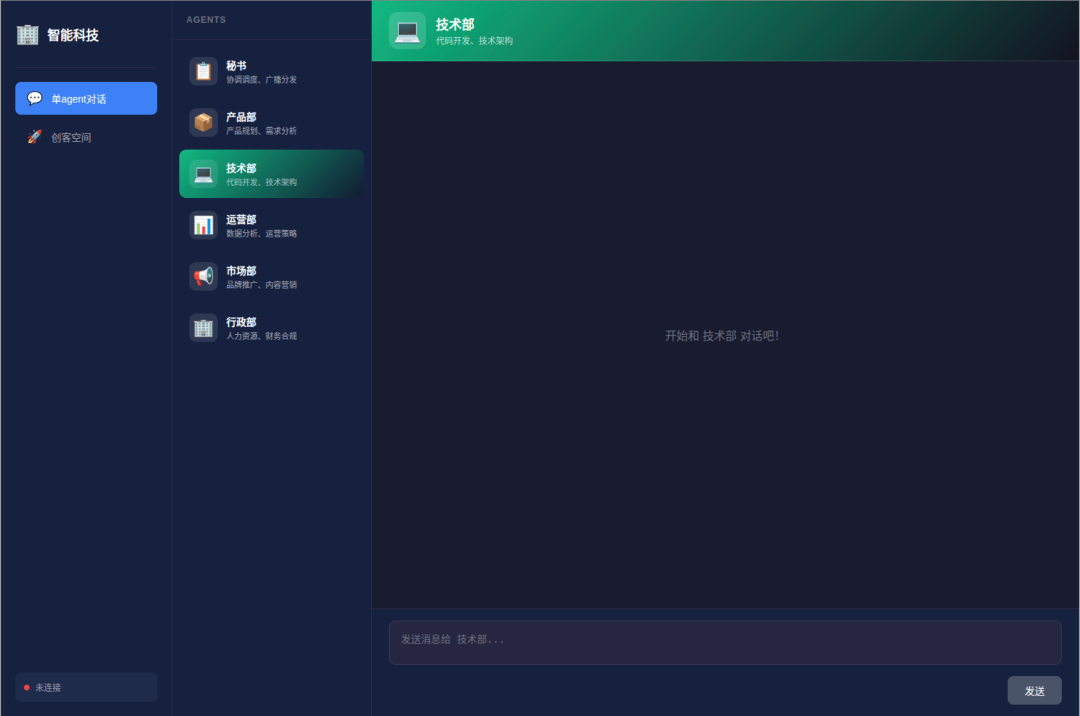
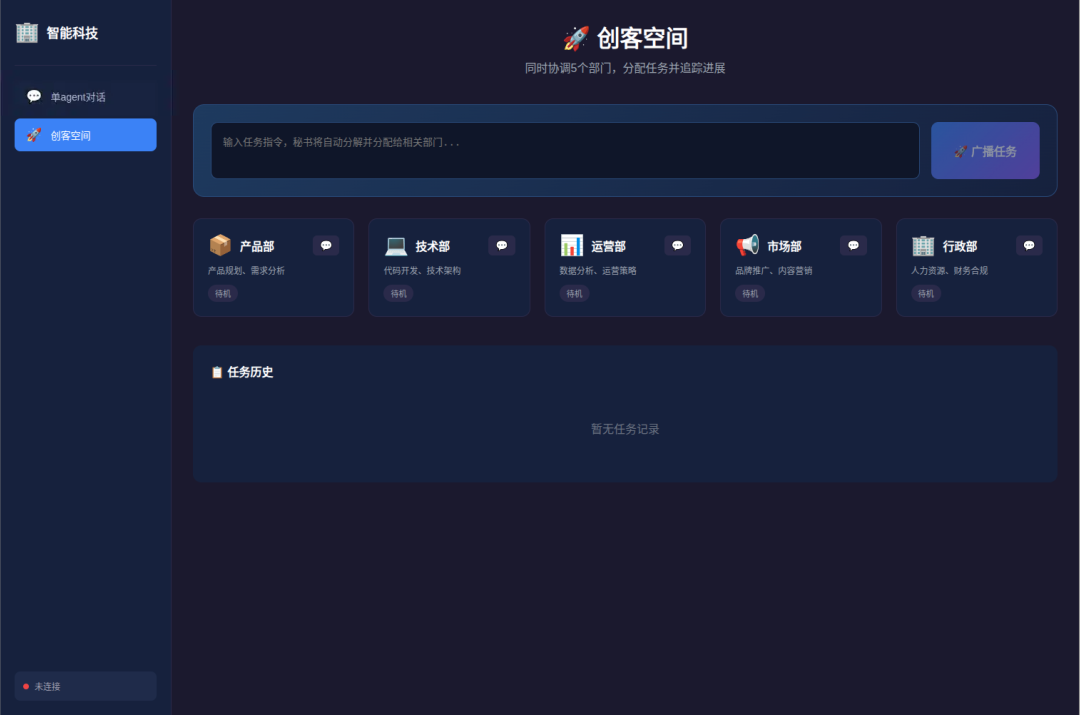
这意味着,未来最极致的敏捷团队,可能就是一个懂行的人类,带着一套 M2.7 驱动的 AI 班底,开一家高效运转的“一人公司”。
这种从单一任务助手到主动协作代理的跨越,无疑是当前人工智能领域最值得关注的趋势之一。欢迎关注 云栈社区 的开发者广场,与更多开发者一同探讨 AI 技术的新边界。
 发表于 2026-3-21 02:15:21
|
查看: 133|
回复: 0
发表于 2026-3-21 02:15:21
|
查看: 133|
回复: 0
