在 Claude Code 源代码泄露事件之后,我们从源码里整理出了 12 种 Agentic Harness 模式。后来又结合 Anthropic 官方的 Agent Skills 构建指南,继续拆解出 14 种 Skill 编写模式。这次再往前走一步,问题就变得更现实了:当 Agent 真正进入生产系统,它到底应该怎么连接那些真实的业务工具、权限系统和数据源?
Anthropic 官方最近那篇关于 MCP 的文章《Building agents that reach production systems with MCP[1]》,讨论的正是这个问题。文章比较了直接 API 调用、CLI 和 MCP 的差异,并解释为什么生产级 Agent 越来越倾向于使用 MCP。
生产级 Agent 的难点,不是「能不能调用工具」,而是「能不能安全、稳定、低成本地连接真实系统」。
所以这篇文章不准备讲 MCP 协议细节,而是换一个角度:如果把 Anthropic 的实践抽象成工程模式,哪些设计可以被复用?
我把它拆成 5 组、12 个 设计模式。它们覆盖了工具交互面、交互语义、认证凭证、上下文经济,以及打包分发。理解这些模式,比单纯会写一个 MCP Server 更重要。
工具交互面设计是 MCP Server 的第一道架构决策。
很多团队第一次做 MCP Server,会自然想到:既然已有 API,那就把每个 API endpoint 包成一个 tool。
这个想法很直观,但通常不是最优解。
因为 Agent 不是按 endpoint 思考的。Agent 要完成的是任务,比如「从 Slack 话题创建一个 Issue」「排查这次部署为什么失败」「帮我找过去七天最异常的指标」。
如果 MCP Server 只是 API 的镜像,Agent 就必须自己拼接大量底层动作。工具变多,调用链变长,上下文变重,失败点也随之增加。
好的 MCP Server,不是 API 的翻译层,而是 Agent 面向任务的产品接口。
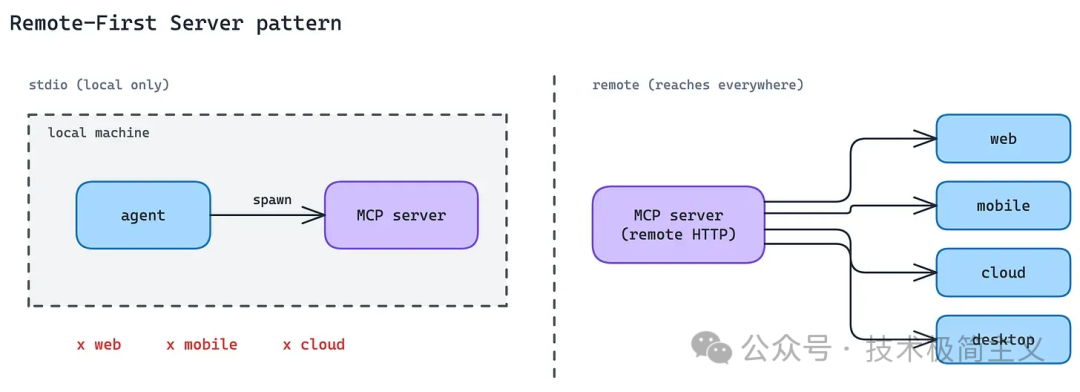
1. 远程优先服务器模式(Remote-First Server Pattern)
第一个模式解决的是:MCP Server 应该运行在哪里?
本地 MCP Server 通过 stdio 和客户端通信,适合桌面应用、IDE Agent、本地 Claude Code 或一些命令行场景。它很轻,也很方便开发调试。
但一旦进入生产环境,这个前提就不稳定了。
生产 Agent 可能运行在浏览器、移动端、云端执行环境或托管平台里。它不一定能启动本地进程,也不一定能访问用户机器上的文件系统。
所以 Anthropic 的建议很明确:如果目标是生产级集成,应该从一开始就按远程 MCP Server 设计。
远程优先的好处是:
- 一个 Server 可以服务多个客户端;
- 同一套认证流程可以跨环境复用;
- Web、移动端、云端 Agent 都能访问;
- Server 可以独立部署、扩展、监控和审计。
但远程优先不是免费午餐。
你必须处理网络延迟、可用性、限流、认证、安全边界、日志和运维。一个本地进程可以偷懒的地方,远程服务都要补上。
所以这个模式适合大多数生产集成,但不意味着所有本地 Server 都应该被否定。
更准确的判断是:本地 MCP Server 适合开发者环境,远程 MCP Server 才是生产分发形态。
第二个模式解决的是:工具应该按什么粒度暴露?
最常见的错误,是把 MCP Server 做成 API endpoint 的一比一包装。
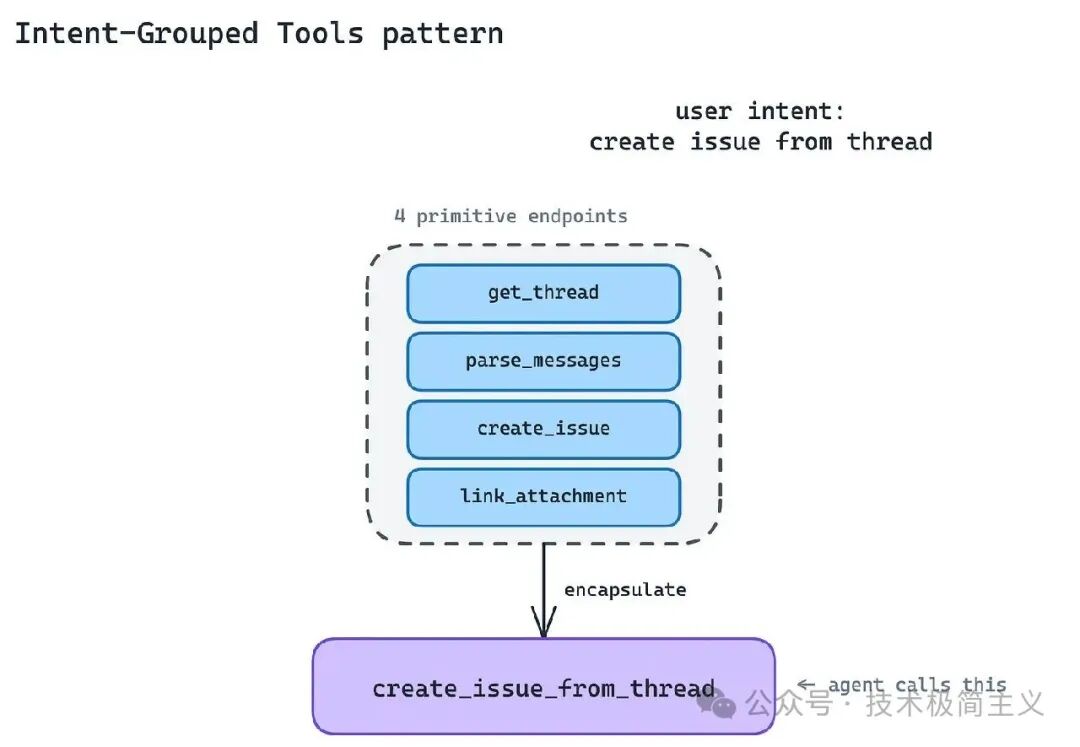
比如一个工单系统原本有:
get_threadparse_messagescreate_issuelink_attachment
如果全部原样暴露给 Agent,模型就要自己判断先调用哪个、如何把上一步结果传给下一步、失败时怎么恢复。
这不是不能做,而是把太多编排责任推给了模型。
更好的方式,是按用户意图组织工具。
比如直接提供一个:create_issue_from_thread
这样 Agent 不需要拼四个底层动作,而是调用一个面向任务的工具。底层 API 编排、ID 归一化、附件关联、错误重试,都可以在 MCP Server 内部处理。
这个模式适合 API 面不算太大、用户任务相对明确的系统。
比如 Linear、Slack、Notion、Sentry 这类工具,很多操作都能归纳为用户意图:创建工单、总结话题、查询错误、生成报告、更新页面。
它的代价也很明确:你不能只导出 schema,你必须设计工具。
工具名称、参数结构、返回结果、错误处理,都要围绕 Agent 的任务体验重新组织。MCP Server 不只是代理层,而是一个需要持续演进的产品接口。
3. 薄交互面模式(Thin Surface Pattern)
第三个模式解决的是:如果底层 API 面太大,按意图组织也会失控,怎么办?
比如 AWS、Cloudflare、Kubernetes 这类系统,底层操作可能有几百甚至几千个。即使按意图分组,也很难把所有能力都封装成合理数量的工具。
这时,继续增加工具数量只会让上下文爆炸。
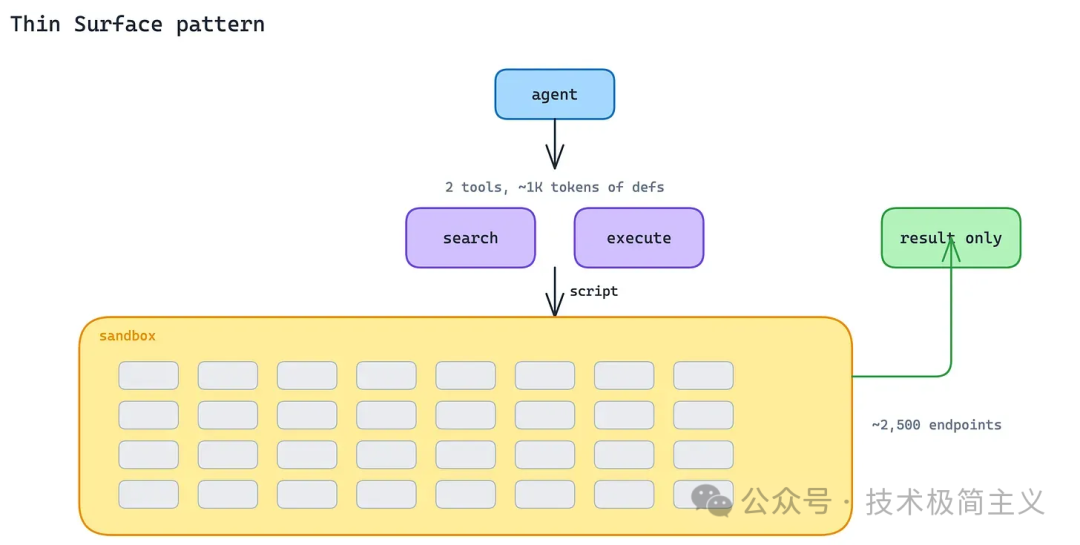
Thin Surface 的思路刚好相反:不要暴露很多工具,只暴露少量高能力工具。
典型组合是:
search:让 Agent 搜索可用 API 或能力;execute:让 Agent 写一段短脚本,由服务端在沙箱里执行。
Anthropic 原文提到 Cloudflare MCP Server[2] 是典型案例:两个工具覆盖约 2500 个 endpoint,工具定义大约只需要 1000 tokens。
这背后的逻辑是:把巨大 API 面藏在 Server 后面,让 Agent 通过搜索找到需要的能力,再用短代码完成调用和组合。
这个模式非常适合「API 规模巨大、任务形态不固定」的系统。
但它的代价也更重:你必须有可靠的沙箱、资源限制、超时策略、权限边界和审计机制。
因为 Agent 不再只是填参数,而是在服务端执行代码。
所以 Thin Surface 不是默认选择。它适合超大 API 面,不适合本来就能被清晰意图封装的小系统。
交互语义(Interaction Semantics)
很多早期 Agent 工具,都默认工具返回文本或 JSON。
这在简单场景里没问题,比如查询一个状态、返回一段摘要、创建一个对象。
但生产系统里的很多信息,本来就不是适合用文字描述的。
搜索结果、指标看板、错误列表、文件预览、支付流程、OAuth 页面、删除确认,这些东西如果都让模型转成自然语言,不仅低效,而且容易丢失结构。
MCP 的一个重要方向,是让工具拥有更丰富的交互语义。
也就是说,工具不只是「返回一段文本」,还可以返回 UI、请求用户补充结构化信息,或者把用户安全地交给外部流程。
4. 内联 UI 模式(Inline UI Pattern)
Inline UI 解决的问题是:有些结果不应该被模型描述,而应该直接被用户看到。
比如一个监控 Dashboard、一张趋势图、一组搜索结果、一个审批表单、一个文件预览页面。
如果工具返回一大段 JSON,再让模型总结成文字,用户看到的是二手信息。结构、细节和可操作性都会损失。
MCP Apps[3] 允许工具返回一个可交互界面,让客户端在聊天界面中直接渲染。
这意味着 MCP Server 不只是后端能力提供者,也开始承担一部分产品界面职责。
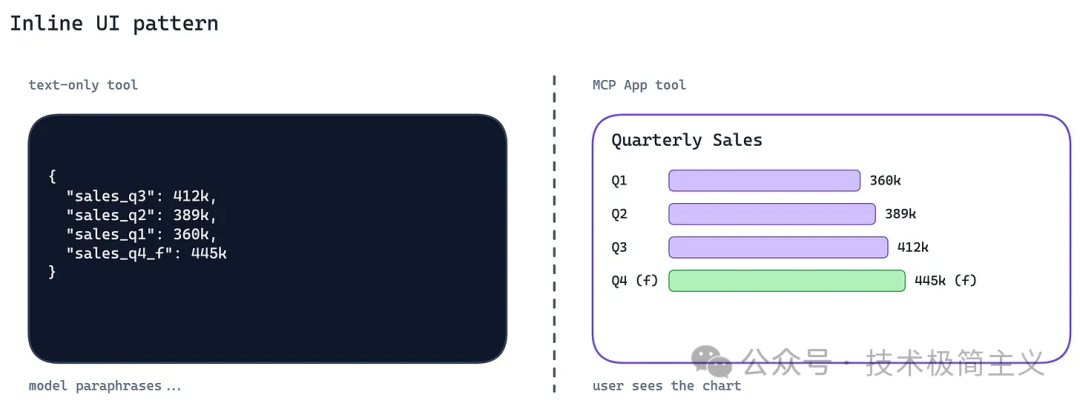
这个模式适合所有「看比听更重要」的结果:
- 图表
- 表格
- Dashboard
- 搜索结果
- 文件预览
- 审批确认
- 状态面板
代价是 Server 团队不能只按后端接口思维工作。你要考虑组件版本、可访问性、视觉一致性和客户端兼容。
但从用户体验看,这是非常自然的方向。
生产环境里的工具调用,经常会碰到缺信息的情况。
比如用户说:「帮我重启这个服务。」
但服务可能部署在多个 region,或者存在多个同名实例。Agent 这时有三个选择:
- 猜一个;
- 回到对话里追问;
- 让工具调用暂停,并向用户请求结构化输入。
前两个都不理想。猜测有风险,普通追问又会打断流程。
MCP 的 Form Mode elicitation[4] 允许 Server 在工具调用中途返回一个表单 schema,Client 负责渲染表单,用户填写后再把控制权交回 Server。
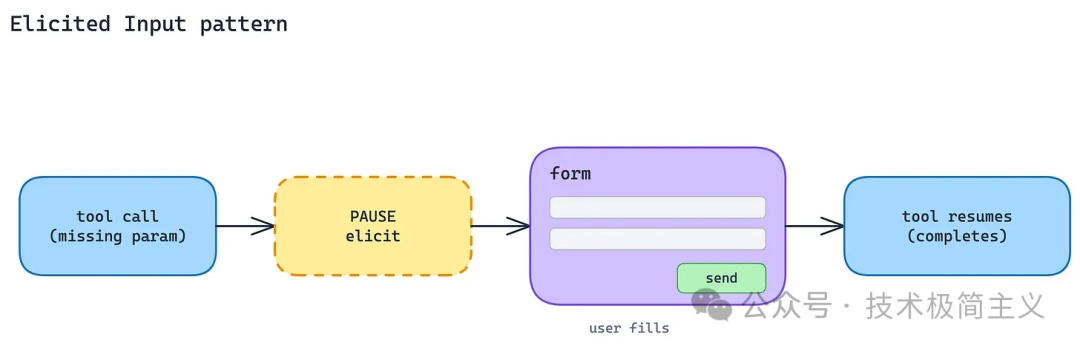
这适合几类场景:
- 缺少 region、环境、项目 ID 等结构化参数;
- 多个候选项需要用户选择;
- 删除、支付、部署等高风险操作需要确认;
- Server 明确知道还缺什么信息。
它的好处是,用户不需要重新发起一轮对话,Agent 也不需要装作自己知道答案。
代价是,每一次 elicitation 都是一次 UX 设计。表单设计得不好,用户会觉得 Agent 在审问自己。
同时,这个模式不适合无人值守场景。如果是 headless Agent 或 batch workflow,没有人在场填写表单,流程就会卡住。
6. 外部跳转交接模式(External Handoff Pattern)
External Handoff 解决的是更敏感的问题:有些信息根本不应该经过 MCP Client。
比如第三方 OAuth、支付流程、银行卡信息、某些合规要求下的敏感凭证。
如果这些信息进入 Agent 上下文,或者经过 MCP Client,就会扩大安全边界。很多时候,正确做法不是让 Agent 处理 secret,而是把用户交给外部系统。
MCP 的 URL Mode Elicitation 就是这个形态。
Server 返回一个 URL,Client 打开浏览器或外部页面,用户在那里完成 OAuth、支付或敏感信息输入。流程结束后,再回到 Server 继续执行。
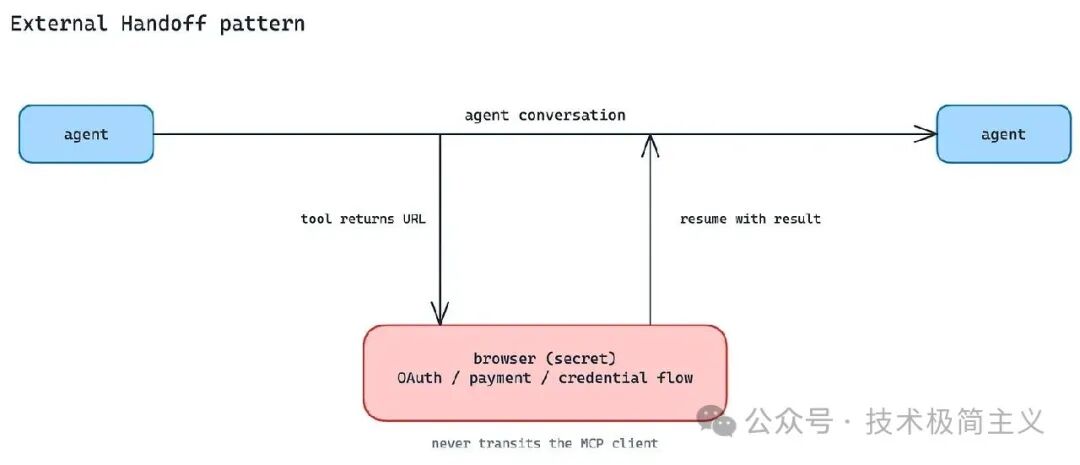
这里要区分 Form Mode 和 URL Mode:
- Form Mode 适合 Server 可以合法接收和处理的结构化输入;
- URL Mode 适合应该由第三方或外部系统处理的敏感流程。
这个模式的代价是用户会离开 Agent 界面。每一次跳转,都可能带来流失和恢复问题。
所以工程上必须设计好 resume-after-redirect,让用户回来后流程还能接上。
认证与凭证流(Auth and Credential Flow)
生产级 Agent 不可能绕开认证。
只要 Agent 要访问真实系统,就要处理用户身份、组织权限、OAuth scope、token 刷新、凭证撤销和审计。
如果每个 MCP Server 都自己发明一套认证方式,用户接入成本会非常高,客户端也很难统一支持。
所以认证不是附属问题,而是 MCP 能不能成为生产连接层的关键问题。
7. 可发现认证模式(Discoverable Auth Pattern)
如果一个 Server 要求用户手动复制 token、配置 client ID、填 redirect URI,第一次接入就会变得很脆弱。
生产系统里,这类「靠用户手工配置」的流程,通常意味着更高的失败率和更多重复登录。
MCP 支持标准 OAuth 能力,Anthropic 原文特别提到 CIMD,也就是 Client ID Metadata Documents[5]。
简单理解,CIMD 让客户端可以通过标准元数据发现认证方式。客户端不需要猜这个 Server 怎么登录,而是读取 metadata,按标准流程启动 OAuth。
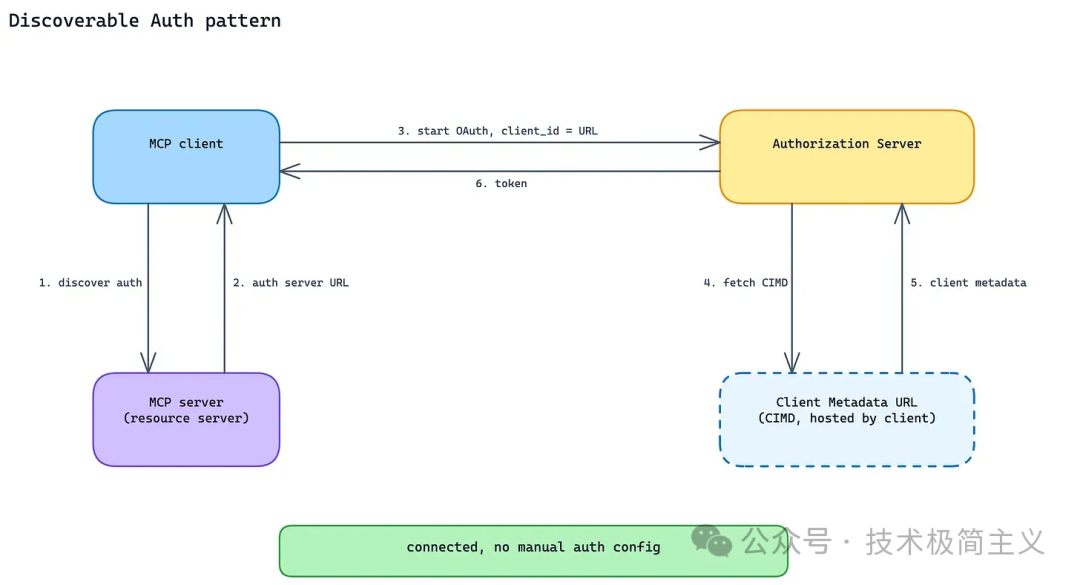
这个模式适合所有访问用户数据的生产 MCP Server。
它的价值不是让 OAuth 本身变神奇,而是把认证流程从「每家自定义」变成「客户端可发现」。
代价是 Server 必须认真遵守标准 OAuth 行为,维护 metadata endpoint、redirect URI 校验、scope 设计、token 校验和跨客户端兼容。
8. 凭证托管到 Vault 模式(Vault-Held Credentials Pattern)
即使认证流程标准化,token 仍然需要一个安全的家。
很多糟糕的集成,会把 token 放进工具参数、环境变量、临时配置,甚至让每次 tool call 都携带凭证。
这在生产系统里很危险。
Vault-Held Credentials 的思路是:把凭证生命周期上移到平台层。
在 Claude Managed Agents 里,MCP OAuth credential[6] 可以注册到 Vault。创建 session 时引用 vault ID,平台负责把合适的凭证注入到 MCP 连接中,并处理刷新、撤销和生命周期管理。
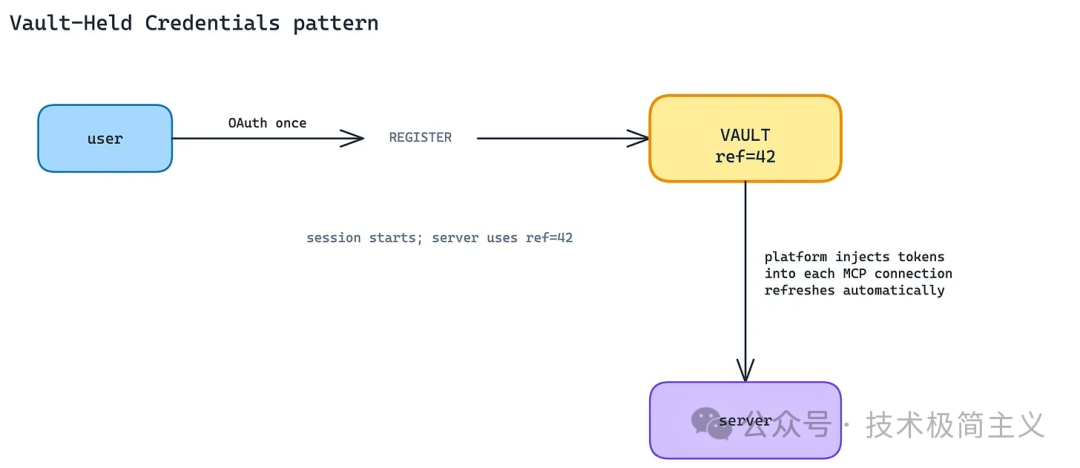
这个模式的关键,不是「有一个密钥存储」这么简单。
真正重要的是:MCP Server 不需要在每次工具调用里接收 token,也不需要自己实现完整的刷新、撤销和轮换逻辑。
凭证管理从工具调用路径里抽离出来,变成平台能力。
代价是,你要信任这个平台 Vault。它的安全性、可用性、审计能力和导出策略,都会成为生产架构的一部分。
对于没有托管平台的团队,也需要自己实现类似模式,而不是把 token 生命周期散落在工具代码里。
上下文经济(Context Economy)
做 Agent 工程的人很容易忽略一个事实:上下文窗口不是无限资源,而是架构约束。
MCP 让 Agent 可以连接更多 Server,获得更多工具。但如果每个 Server 都暴露几十上百个工具,Client 一上来就把所有 tool definitions 全塞进模型上下文,成本会非常高。
更糟的是,工具结果也可能很大。日志、trace、文档、搜索结果、JSON 列表、指标数据,如果原样返回给模型,模型会消耗大量 token 去读取很多其实不需要的信息。所以 MCP Client 也需要工程模式。
On-Demand Tool Loading 解决的是工具定义的上下文成本。
当 Agent 连接多个 MCP Server 时,它可能拥有几百个工具。全量加载这些工具定义,相当于在任务还没开始前,就已经消耗了大量上下文预算。tool search tool[7] 的做法是延迟加载。
Agent 先通过一个搜索工具查找可能相关的工具,只把命中的工具定义加载进上下文,其余工具保持不可见。Anthropic 官方测试中,Tool Search 可以让 tool-definition tokens 减少 85% 以上,同时保持较高的工具选择准确率。
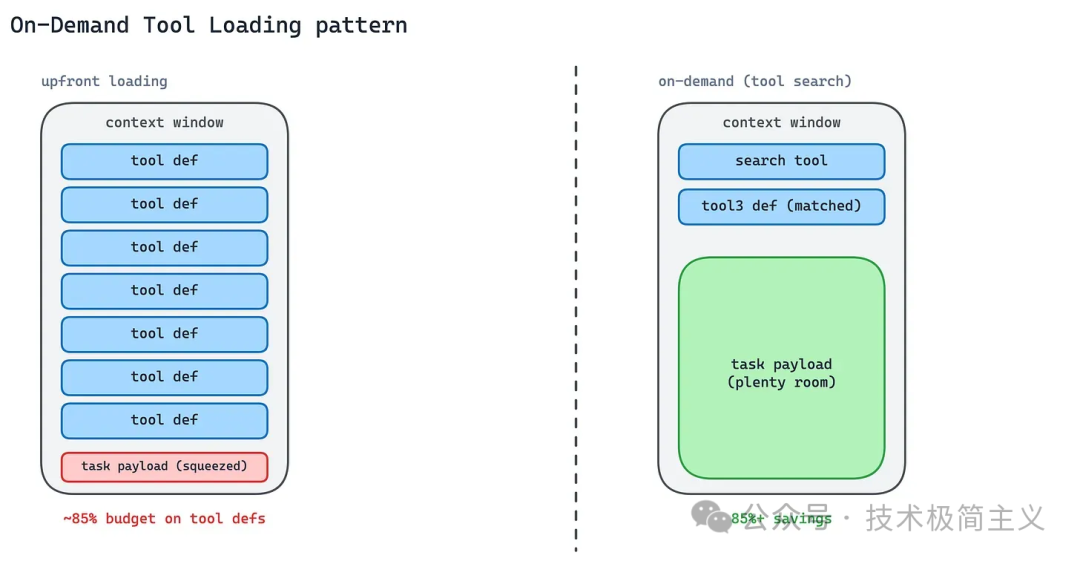
这个模式的代价是多了一次搜索步骤,而且高度依赖工具描述质量。
如果工具描述模糊,搜索可能找不到正确工具;如果描述过宽,又可能加载太多无关工具。
所以 Tool Search 不是替代工具设计,而是倒逼工具描述更像产品文案:准确、可检索、可区分。
另一个上下文浪费点,是工具结果。
很多工具返回的结果并不适合直接给模型看。
比如:
- 几千行日志;
- 大段 JSON;
- 多页搜索结果;
- trace 树;
- 数据表;
- 多个 API 调用结果。
模型真正需要的,往往不是原始数据,而是过滤、聚合、排序、统计之后的结果。
Programmatic tool calling[8] 的做法是,让 Agent 在代码执行沙箱里处理工具结果。它可以循环调用工具、过滤数据、聚合字段、做中间计算,最后只把必要结果放进模型上下文。
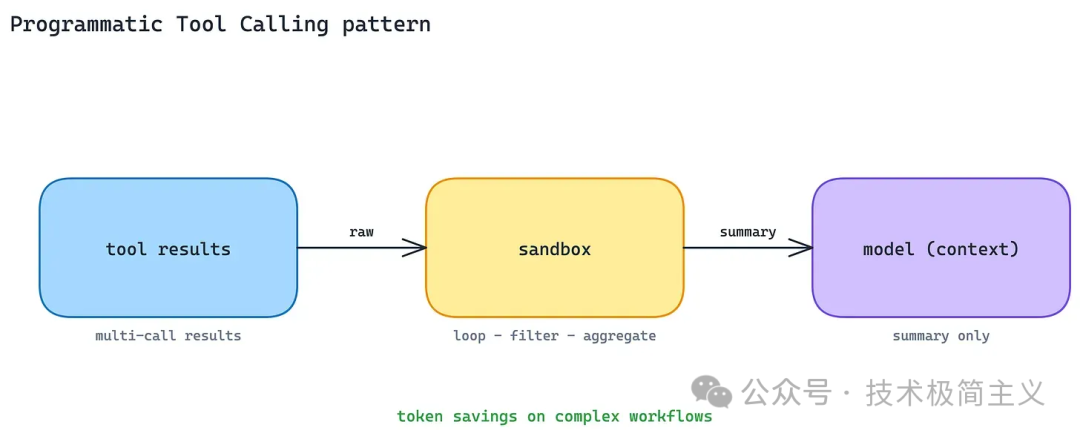
Anthropic 官方测试中,这种方式在复杂多步流程里可以减少大约 37% 的 token 使用。
它和 On-Demand Tool Loading 形成一个完整组合:
- On-Demand Tool Loading 减少「工具定义」进入上下文;
- Programmatic Tool Calling 减少「工具结果」进入上下文。
代价是客户端需要代码沙箱,也需要能调试 Agent 写出来的中间代码。
对于简单的一次性工具调用,这个模式可能过重。但对于日志分析、数据处理、跨系统查询这类任务,它会非常有价值。
打包与分发(Packaging and Distribution)
到这里,MCP Server 已经解决了很多问题:连接、工具面、交互、认证、上下文。
但真实集成还有一个关键问题:如何交付?
一个真正有用的 Agent 集成,通常不只是一个 MCP Server。
它还可能包括:
- Skills:告诉 Agent 如何使用这些工具完成真实工作;
- hooks:在生命周期事件里注入规则;
- subagents:处理特定类型任务;
- LSP server:提供语言能力;
- 项目级约定和工作流说明。
所以 Anthropic 强调,MCP 和 Skills 是互补关系。
MCP 解决「Agent 能访问什么」,Skills 解决「Agent 应该怎么使用这些能力」。
11. 插件打包模式(Plugin Bundle Pattern)
Plugin Bundle 解决的是分发问题。
如果一个集成需要 MCP Server、Skills、hooks、subagents,但这些组件分散安装、分散升级,就会出现配置漂移和版本错配。
Claude Code Plugins 提供了一种打包方式:把 Skills、MCP servers、hooks、LSP servers、specialized subagents 统一放进一个插件分发。
用户一次安装,就得到完整能力包。
Cowork data plugin 是一个典型例子:它包含 10 个 Skills 和 8 个 MCP servers,连接 Snowflake、Databricks、BigQuery、Hex 等数据工具。
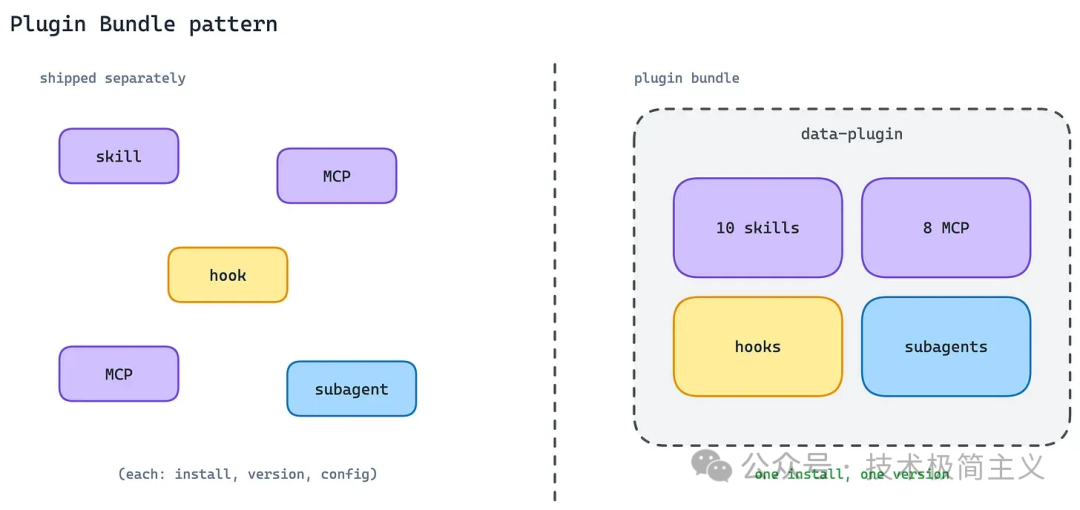
这个模式的价值是减少安装摩擦,也减少组件之间的版本错配。
代价是发布节奏被绑定。一个 Skill 更新、一个 Server 更新、一个 hook 更新,都可能牵动整个插件版本。
但对用户来说,「一个插件就是一套完整工作能力」通常比「自己拼装十几个组件」更自然。
12. 服务器分发 Skills 模式(Server-Distributed Skills Pattern)
最后一个模式解决的是:Agent 有了工具访问权,是否就真的会用?
答案通常是否定的。
一个 MCP Server 可以告诉 Agent 有哪些工具,但它不一定告诉 Agent 在复杂业务里应该怎样安全、有效地组合这些工具。
比如一个 Sentry MCP Server 可以暴露 issue、trace、release、alert 等能力。但如何排查线上错误、如何判断影响范围、如何生成修复建议,这些更像领域知识和操作手册。
这就是 Skills 的价值。
Server-Distributed Skills 的方向是:由 MCP Server 直接分发与自身能力匹配的 Skills。客户端连接 Server 时,不只获得工具,也获得使用这些工具的 playbook。
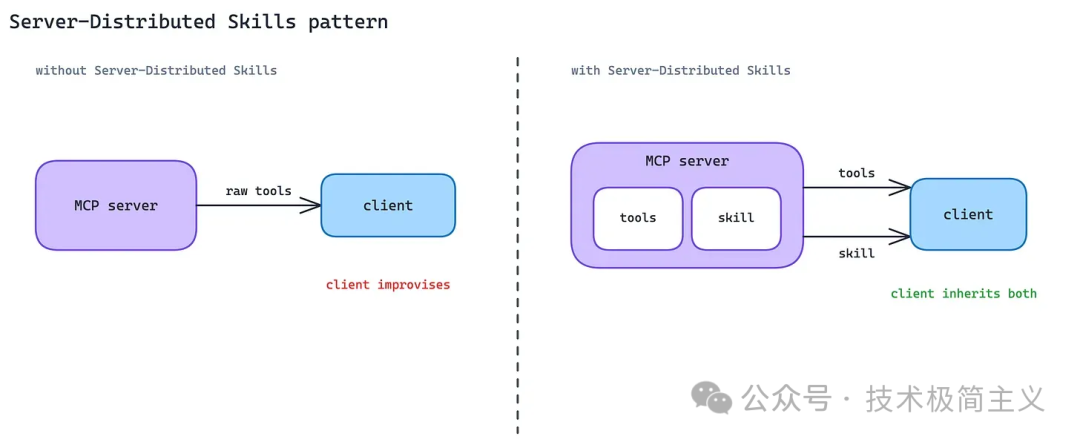
Anthropic 原文提到,Canva、Notion、Sentry 等已经在 Claude 中把 Skill 和 connector 配对展示。MCP 社区也在探索 server-distributed skills 的扩展,让这种能力可以跨客户端移植。
这个模式还在演进,但方向非常清晰:未来的 MCP Server 不只分发能力,还会分发使用能力的方法。
这也意味着,Agent 集成的竞争点会从「谁有工具」变成「谁能把工具、流程、经验和安全边界一起交付」。
结语
这些模式真正有价值的地方,不是告诉我们「MCP 很重要」,而是把生产级 Agent 集成中的工程问题拆开了。连接在哪里运行,工具按什么粒度暴露,用户如何参与流程,凭证如何托管,上下文如何控制,能力如何打包分发。
这些问题加起来,才是 Agent 从 demo 走向 production 的真实门槛。
生产级 Agent 不是多接几个工具,而是重新设计 Agent 与真实系统之间的连接层。
MCP 的意义就在这里。它让每一个系统都有机会为 Agent 提供一个更稳定、更安全、更可复用的产品交互面。随着更多客户端、Server、Skills 和协议扩展进入生态,这个交互面的价值会继续叠加。在 云栈社区,你可以找到更多关于 Agent 工程化的讨论和资源。
参考资源:
- 12 MCP Patterns Behind Production Agents[9]
- Writing tools for agents[10]
引用链接
[1] Building agents that reach production systems with MCP: https://claude.com/blog/building-agents-that-reach-production-systems-with-mcp
[2] Cloudflare MCP Server: https://github.com/cloudflare/mcp
[3] MCP Apps: https://modelcontextprotocol.io/extensions/apps/overview
[4] Form Mode elicitation: https://modelcontextprotocol.io/specification/2025-11-25/client/elicitation#form-mode-elicitation-requests
[5] Client ID Metadata Documents: https://modelcontextprotocol.io/specification/2025-11-25/basic/authorization#client-id-metadata-documents
[6] MCP OAuth credential: https://platform.claude.com/docs/en/managed-agents/vaults#mcp-oauth-credential
[7] tool search tool: https://platform.claude.com/docs/en/agents-and-tools/tool-use/tool-search-tool
[8] Programmatic tool calling: https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling
[9] 12 MCP Patterns Behind Production Agents: https://generativeprogrammer.com/p/12-mcp-patterns-behind-production
[10] Writing tools for agents: https://www.anthropic.com/engineering/writing-tools-for-agents
 发表于 2026-5-8 02:37:35
|
查看: 110|
回复: 0
发表于 2026-5-8 02:37:35
|
查看: 110|
回复: 0
