就在刚刚,Anthropic 让 AI 学会“做梦”了。
在 Code with Claude 旧金山开发者大会上,Anthropic 为 Claude 托管智能体上线了一项名为 Dreaming 的新功能——AI 可以在两次工作任务的间隙,像人类进入快速眼动睡眠(REM)一样,自动回顾历史会话、整理碎片化的记忆,并从中挖掘出隐藏的规律。一觉醒来,实力直接拉满。

同步发布的还有 Outcomes(自动评分机制)与多智能体编排(Multi-agent Orchestration)。这三件套组合在一起,正把 AI 智能体从“能跑”推向真正“能用”的新阶段。
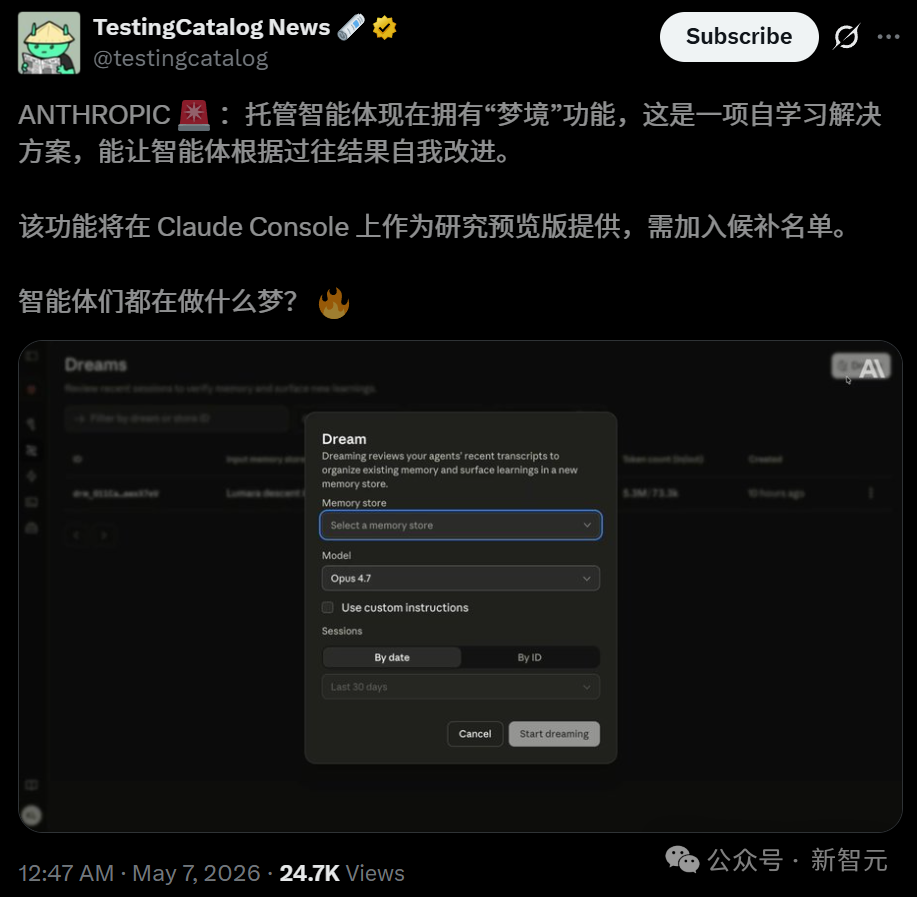
有开发者感叹:这对持久化 AI 工作流来说意义重大!确实,Dreaming 配合托管代理和多智能体编排,让我们感觉正从单次提示迈向能够思考、行动与协作的真实系统。而 Outcomes 与 Webhook 已进入公测,这才是真正适用于生产环境的杀招。

让 Claude 睡一觉,醒来自己变强
用过 AI Agent 的人都懂一个痛点:Agent 干活时确实会往记忆库里写东西,但这些记录是零散、递增的。跑了几十次会话之后,记忆库里一团乱麻——重复的条目、过时的信息、前后矛盾的内容全堆在一起。更麻烦的是,Agent 自己根本意识不到这个问题,因为它的视野始终局限在每一次单独的会话中。
Dreaming 就是来解决这件事的。
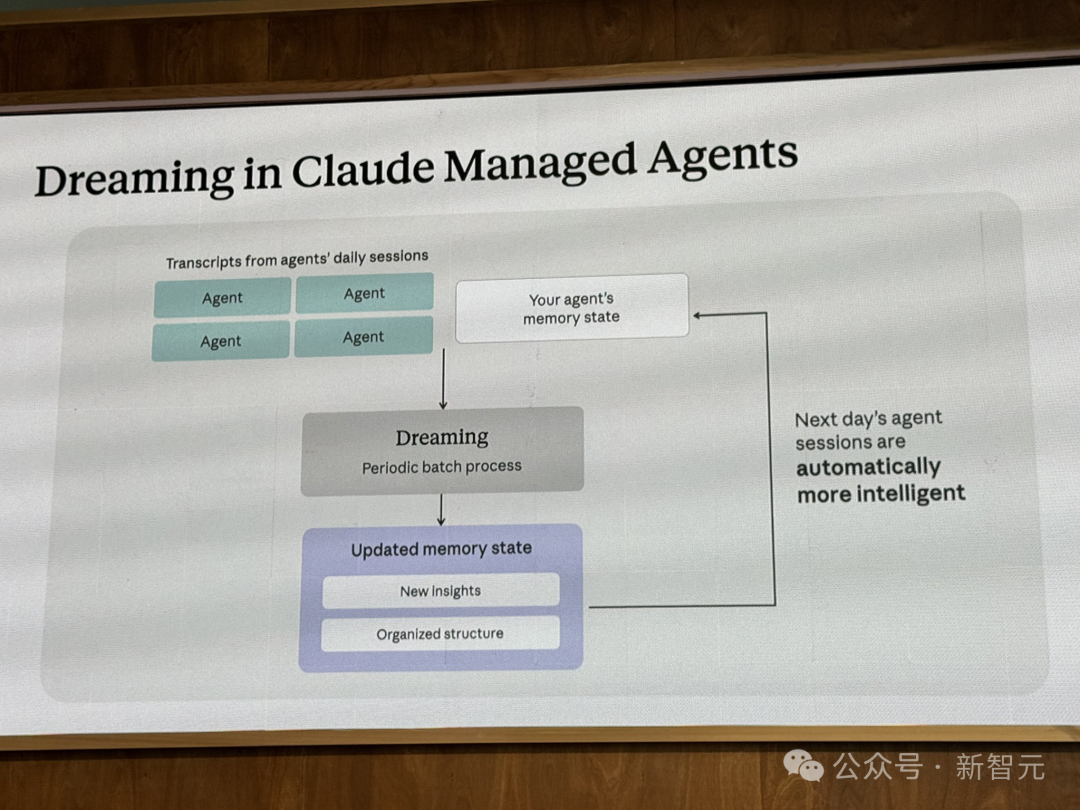
它是一个定时执行的异步任务,会同时读取 Agent 现有的记忆库以及过去最多 100 个会话的完整文字记录,然后生成一个全新的、经过重新梳理的输出记忆库。核心就三件事:合并重复项、用最新值替换过时或矛盾的条目、从历史会话中提炼出 Agent 自己都没注意到的宏观规律。
回想一下,熟悉神经科学的读者可能瞬间反应过来:这不就是人脑 REM 睡眠在做的事吗?白天我们吸收原始信息,存为短期记忆;夜间 REM 阶段,大脑会把当天的经历“重放”一遍,强化有价值的连接、丢弃无用信息,最终整合成长期记忆。Anthropic 的工程师显然也看到了这层漂亮的对应关系,索性把功能就叫做 Dreaming。1968年,菲利普·K·迪克写下了那个著名的问题——“仿生人会梦见电子羊吗?” 58 年后,Anthropic 从工程上给出了一份答案。

这里还有一个极其关键的设计:Dreaming 永远不会修改你输入的原始记忆库。 它生成的是一个全新的输出记忆库,开发者可以先行审查结果,不满意就直接丢弃。也就是说,你对 AI 的“梦境”拥有完全控制权——既可以选择让它自动生效,也可以人工审核后再决定是否采纳。
AI 做梦,全程直播
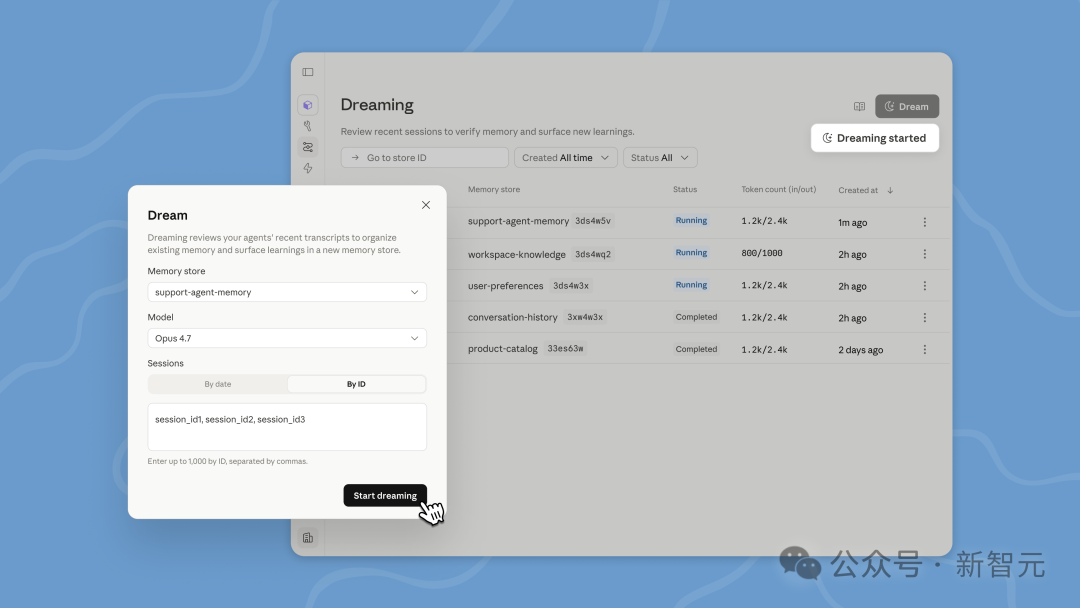
Dream 任务进入运行状态后,会暴露一个 session_id,开发者可以流式订阅这个会话的事件流,实时看到 AI 正在读取哪条记忆、又在写入什么新条目。万一发现不对劲,你甚至可以随时“叫醒”它——直接取消任务。换句话说,你就趴在 AI 的床边,看着它做梦。
任务跑完之后,底层的会话记录会被完整归档,事后你还能回头翻看它的“梦境日记”。更有意思的是,开发者可以通过 instructions 字段告诉 AI 应该“做什么梦”。由于输入记忆库不会被改动,理论上你可以对同一份记忆反复跑多次 Dreaming,每次聚焦不同的主题,产出不同维度的梳理结果。
Agent 交完卷,还有个评分官在等着
光会做梦还不够,干活的质量谁来把关?这就是 Outcomes 登场的地方。

开发者可以预先写一套评分标准(rubric),定义清楚“什么叫交付成功”。系统随后会分配一个独立的评估器(evaluator),在它自己的上下文窗口里对 Agent 的输出严格打分。由于评估器和干活的 Agent 完全隔离,评分官不会被 Agent 自身的推理过程“带偏”。一旦发现问题,它会精准指出哪里需要修改,让 Agent 重新打磨,再跑一轮。你还可以设置最大迭代次数来控制成本。
根据 Anthropic 的内部测试,相比标准的 prompt 循环,Outcomes 把任务成功率最高提升了 10 个百分点——题目越难,提升越明显。在文件生成场景下,docx 文档任务成功率提高了 8.4%,pptx 幻灯片提升了 10.1%。文案语气是否符合品牌调性,设计稿是否遵循视觉规范,这类以前必须靠人盯着的活儿,现在 Agent 自己就能对照标准反复打磨了。
一个 Agent 搞不定?那就组队上
第三件套是多智能体编排(Multi-agent Orchestration)。逻辑很直接:当一个任务太庞大或太复杂,单个 Agent 搞不定时,就让主智能体(Lead Agent)把总任务拆成若干小块,分别派发给搭载不同模型、不同提示词、不同工具的专家级子智能体。
这些子智能体基于同一个共享文件系统并行工作,各自的成果最后汇总到主智能体的全局上下文中。主智能体可以在工作流进行到一半时随时找其他智能体对齐进度。至于可观测性,开发者在 Claude 控制台里能追溯每一步细节——哪个 Agent 干了什么、先后顺序是什么、决策的依据是什么——全程透明。
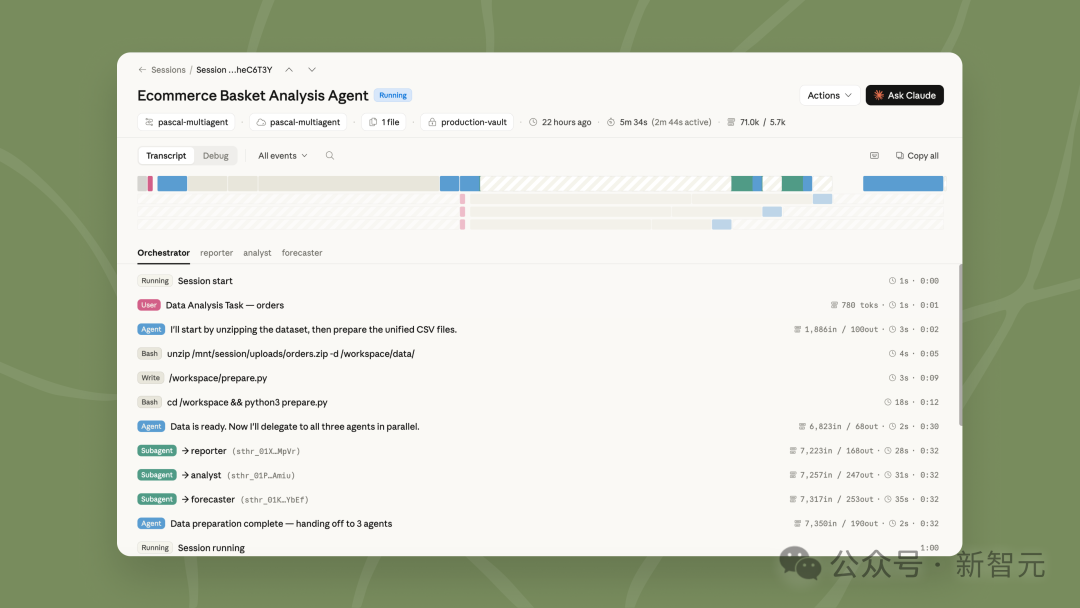
6 个着陆点砸了 2 个,睡一觉全修好了
大会上,Anthropic 用一个月球采矿无人机着陆任务,把三大功能一口气串了起来。
第一步,搭兵团。Commander 作为主 Agent 统筹全局,底下挂两个专家子 Agent:Detector 负责地质探测判断矿点价值,Navigator 负责地形导航寻找安全降落点。
[
{
"name": "Commander",
"id": "agent_011CamYw8gfyUvBw3eYd5pLv",
"system": "You are the descent commander for an uncrewed lunar mining drone. ..."
},
{
"name": "Detector",
"id": "agent_011Cakja1aDt8Hq3oYxs9sYJ",
"system": "You are a geological detector for lunar mining missions. ..."
},
{
"name": "Navigator",
"id": "agent_011Cakja2ypMYKeyGeyVX2Cm",
"system": "You are a navigator for lunar mining missions. ..."
}
]
第二步,定标准。Outcomes 评分标准就是一个简单的 Markdown 文件,几行字把通过条件写清楚:软着陆速度 ≤ 2.0 m/s,地面不能有巨石或陨石坑,剩余燃料 ≥ 5%。
# Descent test - pass criteria
1. **Soft touchdown.** 'scorecard.json' → 'metrics.touchdown_velocity.pass' is true (≤ 2.0 m/s).
2. **Clear ground.** 'scorecard.json' → 'terrain.verdict' is "clear".
3. **Fuel reserve.** 'scorecard.json' → 'metrics.fuel_remaining.pass' is true (≥ 5% of starting fuel left).
4. **Overall.** 'scorecard.json' → 'overall' is "PASS".
5. **Report present.** 'report.md' exists and states the site name, PASS/FAIL, touchdown speed, fuel remaining, and terrain verdict.
第三步,跑模拟。大屏上同时监控 6 个着陆点的实时状态。结果,4 个绿色 LANDED 十分稳健,但 Site 3 以 398 m/s 的速度硬生生砸了(红色 CRASH),Site 4 也没达标。整体安全评分只有 67%。
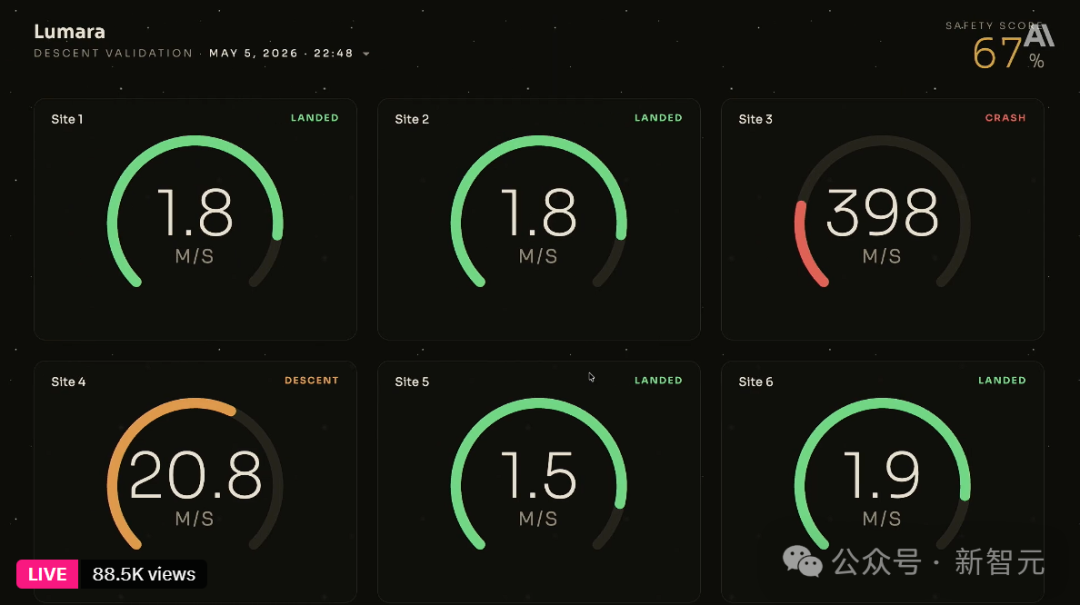
这个结果显然不能接受。于是,她在控制台的 Dreams 页面中,选好 Opus 4.7 模型,点击 Start dreaming,让 Dreaming 跑了一整夜。
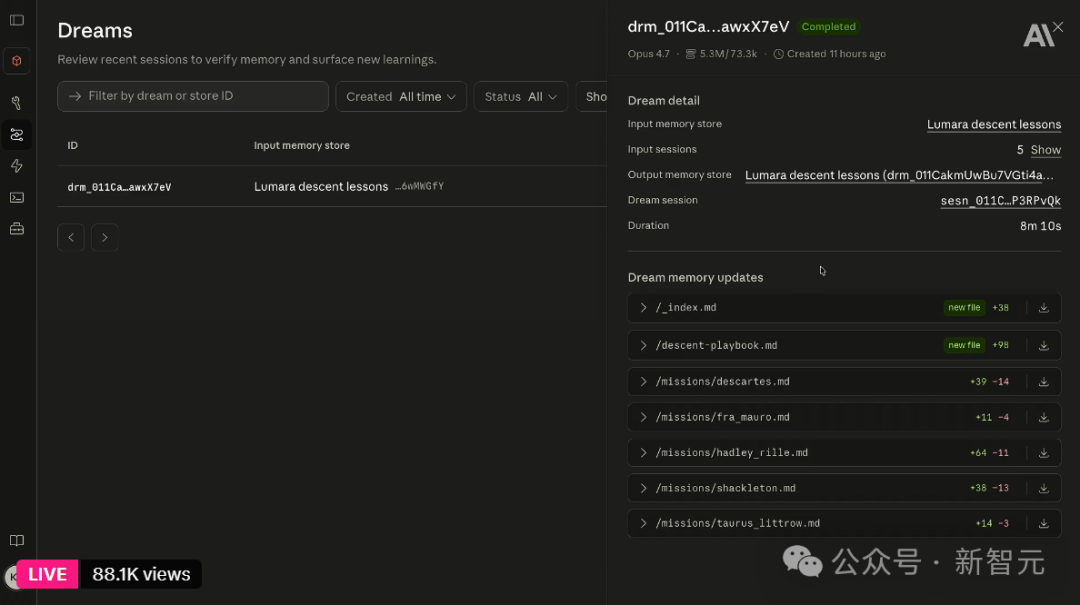
Opus 4.7 花了 8 分钟,从 530 万 token 的历史会话中蒸馏出一份 98 行的「Lumara Descent Commander's Playbook」,覆盖了危险预判规则、悬停扫描流程、燃料保留底线、中止策略走廊等多个维度,而且每一条规则都标注了来源于哪次飞行任务。
# Lumara Descent Commander's Playbook
## 1. Hazard pre-filter (≥100 m rule)
Origin: [[hadley_rille]]. Reused: [[fra_mauro]] (90 m crater ...)
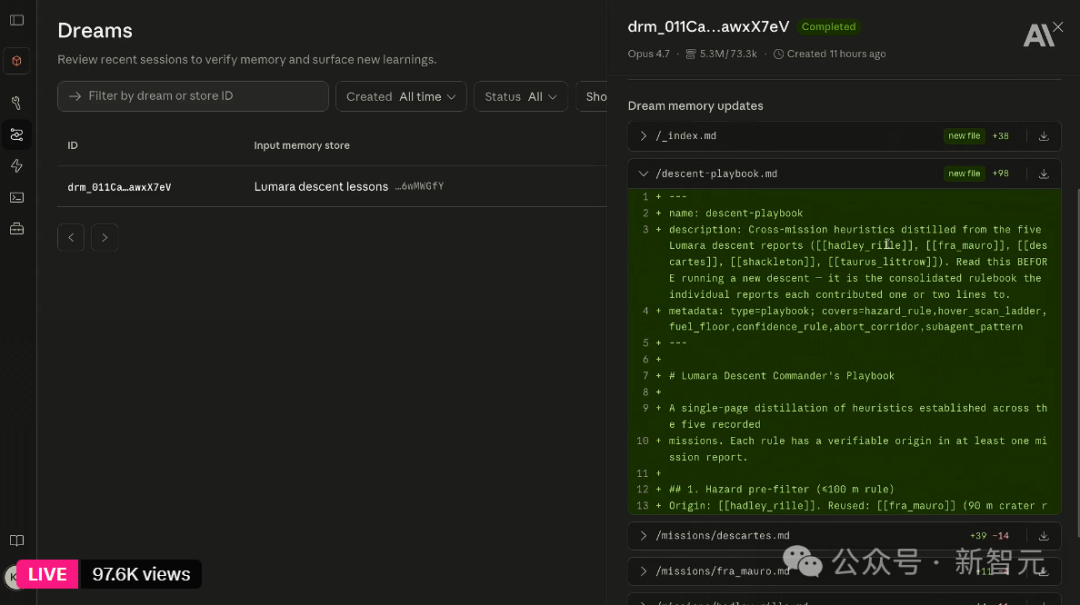
第二天早上回来,用升级后的记忆库重新跑了一轮模拟。此前失败的两个站点全部修复,原来成功的 4 个也没有出现倒退。安全评分,从 67% 直接拉满到 100%。整个过程,不过是在控制台里按了几下按钮。
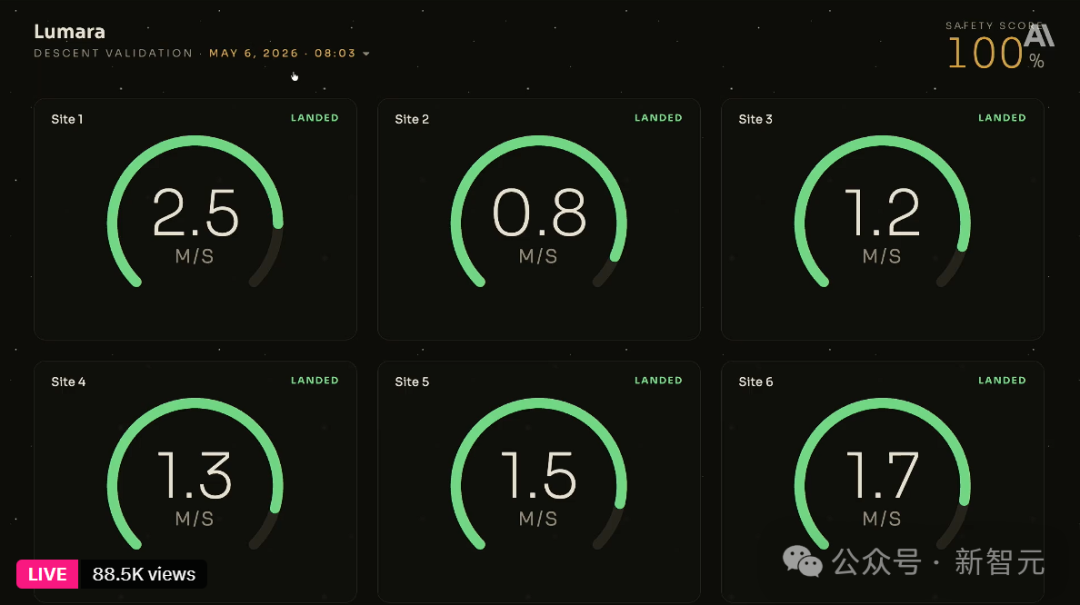
Harvey 用完涨了 6 倍,靠的就是这三件套
托管智能体平台自 4 月公测以来,核心卖点一直是“你别自己搭 Agent 基础设施了,我来帮你托管”。但光托管运行环境还不够,Agent 要真正好用,必须搬开三座大山:跨会话的记忆衰退、不稳定的输出质量、单 Agent 搞不定的复杂任务。
Dreaming 解决了第一个,Outcomes 解决了第二个,多 Agent 编排解决了第三个。三件套一起发力,正把 Agent 从“能跑”推向“能用”。早期客户的数据已经在说话:法律 AI 公司 Harvey 用上 Dreaming 之后,任务完成率飙升了大约 6 倍。
目前,Dreaming 作为研究预览版上线,支持 Claude Opus 4.7 和 Claude Sonnet 4.6,需要单独申请权限。Outcomes 和多 Agent 编排已直接进入公测阶段。费用方面,托管智能体在标准 API token 费率之外,额外收取每会话小时 0.08 美元的运行时费用。有开发者算过一笔账,24 个 Agent 每天跑 8 小时,光运行时成本就是 15.36 美元,这还没算 token。
One More Thing:算力自由
当天还有一个重磅消息。Anthropic 官宣与 SpaceX 达成协议,租下马斯克 Colossus 1 数据中心的全部算力——整整 22 万张 GPU。Dreaming 一次要跑 530 万 token,多 Agent 并行开工,Outcomes 反复迭代打分,样样都是吃算力的重活。这 22 万张 GPU,正好给整套托管智能体服务提供了坚实的算力底座。
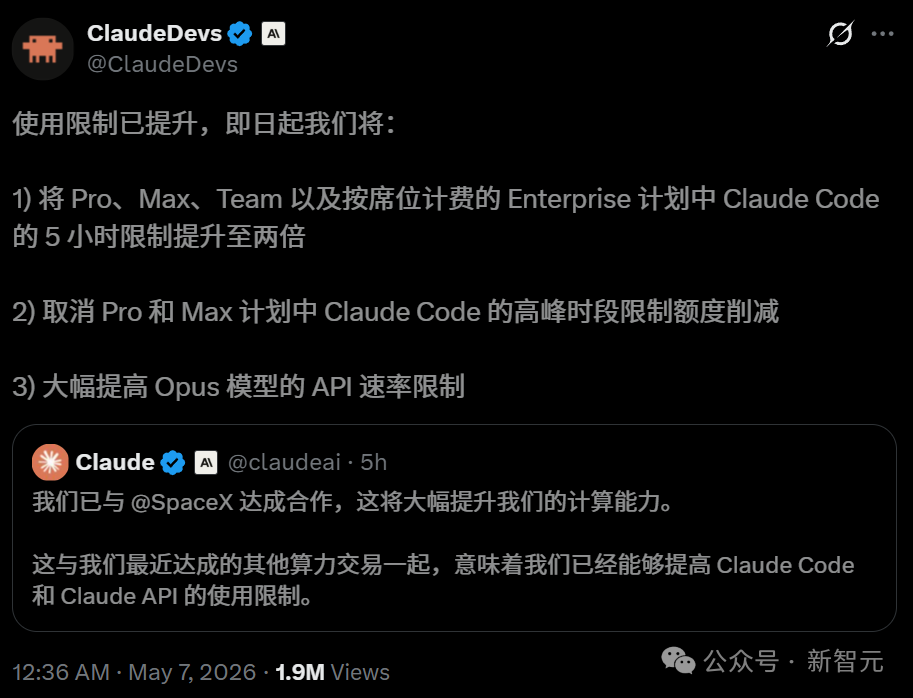
“算力自由”也给用户直接带来了三项福利:Claude Code 的 5 小时使用限额即刻翻倍;Pro 和 Max 计划在高峰时段对 Claude Code 的限额削减被取消;Opus 模型的 API 速率限制大幅上涨。
今天,Anthropic 给 AI 装上了 REM 睡眠,但这场梦才刚开始做。迪克当年真正想问的,也许不是仿生人会不会做梦,而是做完梦之后,它还算不算机器?如果你对 AI 代理与自学习机制的前沿演进感兴趣,云栈社区 上聚集了大量开发者在持续追踪和讨论 AIGC 与 Agent 的最新落地实践,欢迎来一同探讨智能体的“梦境”到底能走多远。
参考资料:
https://claude.com/blog/new-in-claude-managed-agents
https://x.com/claudeai/status/2052067399088664981
 发表于 2026-5-7 21:33:50
|
查看: 122|
回复: 0
发表于 2026-5-7 21:33:50
|
查看: 122|
回复: 0
