面对“接口性能优化,有哪些经验和手段”这类经典面试题,最好的回答方式莫过于结合真实案例。本文将从一个真实的转账接口优化实践出发,详细拆解六种优化手段,并补充其他常见思路,希望能为你提供一份可复用的优化指南。
一、 转账接口优化实战
记得之前我们系统对外提供的一个转账接口,偶现504超时问题,原因是代码执行时间过长,超过了Nginx配置的15秒上限。经过一轮真枪实弹的优化,最终稳定了接口性能。先看看这个转账接口的核心流程:
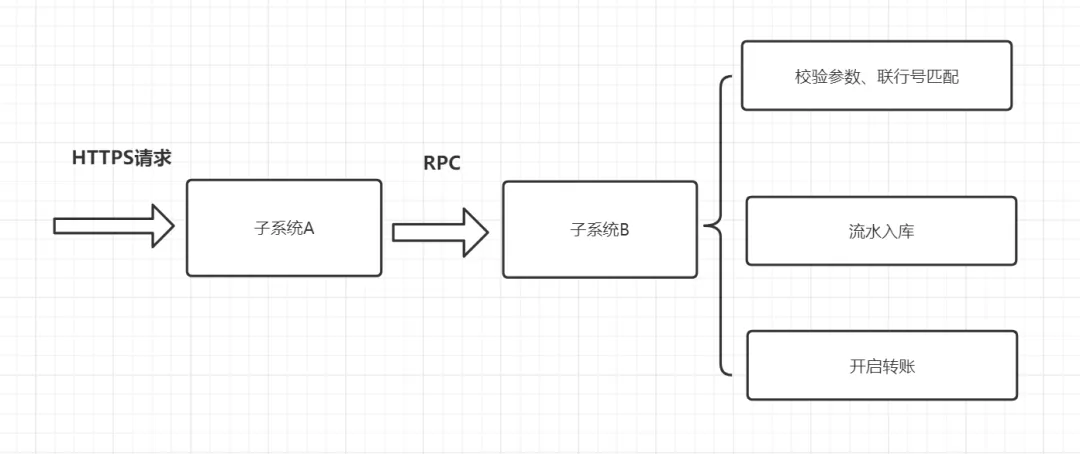
整个优化过程,我主要应用了以下六种方式:批量操作、异步处理、缓存、程序结构优化、SQL优化以及文件暂存数据。
1.1 批量操作取代循环单笔入库
优化前,处理交易明细是循环遍历,单笔插入数据库的:
//for循环单笔入库
for(TransDetail detail:list){
insert(detail);
}
这种方式就像用电梯一次只搬一块砖上楼,效率极低。优化后,我们改为批量入库:
batchInsert(transDetailList);
批量插入能大幅减少网络I/O和数据库事务开销,是提升数据库写入性能的常见且有效手段。
1.2 异步处理耗时操作
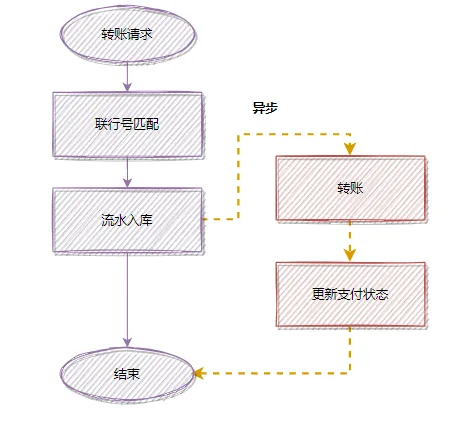
在原先的流程中,匹配联行号(银行编码)的操作比较耗时。为了降低接口整体响应时间,我们将其改造为异步处理。
优化前的同步流程:
优化后的异步流程:
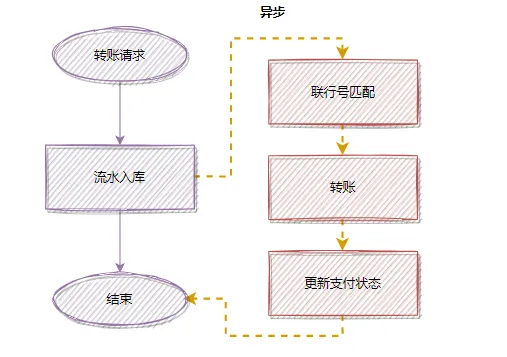
将联行号匹配从主流程中剥离后,接口能快速返回“受理成功”状态,后续的匹配和转账操作在后台异步完成,用户体验得到显著提升。
1.3 恰当使用缓存减少数据库查询
在合适的场景使用缓存,是提升接口性能的利器。本次优化前,每次转账都需要根据客户账号查询数据库并计算匹配联行号,流程如下:
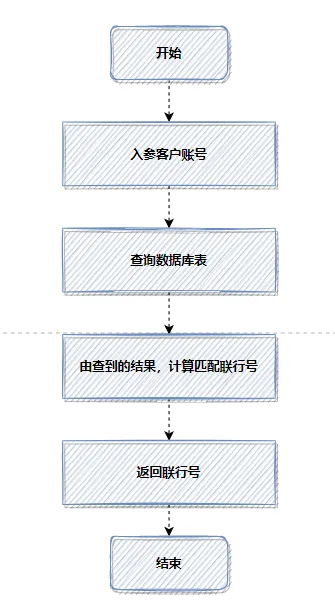
这种频繁查询相同数据的方式非常耗时。我们引入Redis缓存后,流程优化为:
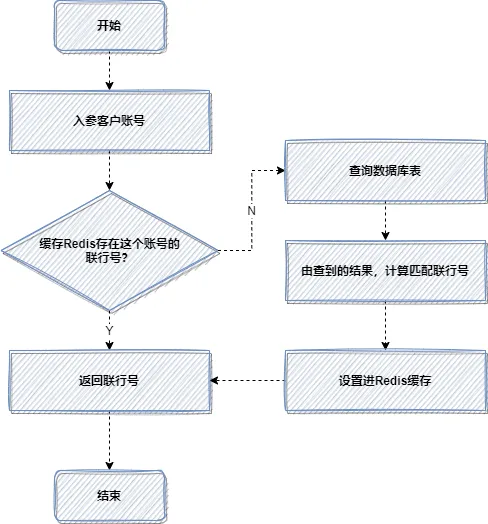
首次查询后,将账号与联行号的映射关系存入缓存,后续请求直接命中缓存,避免了大量的数据库查询,性能提升立竿见影。
1.4 优化程序结构,避免重复逻辑
审视并优化程序逻辑本身,往往能发现不必要的性能损耗。例如,在老代码中,联行号查询了两次(校验参数一次,插入数据库前又查询一次):
public void process(Req req){
//检验参数,包括联行号
checkTransParams(Req req);
//Save DB
saveTransDetail(req);
}
void checkTransParams(Req req){
//check Amount,and so on.
checkAmount(req.getamount);
//check payeebankNo
if(Utils.isEmpty(req.getPayeeBankNo())){
//查询一次
String payeebankNo = getPayeebankNo(req.getPayeeAccountNo);
if(Utils.isEmpty(payeebankNo)){
throws Exception();
}
}
}
int saveTransDetail(req){
//再查询一次
String payeebankNo = getPayeebankNo(req.getPayeeAccountNo);
req.setPayeeBankNo(payeebankNo);
insert(req);
...
}
优化后,我们只在参数校验时查询一次,并将结果设置到请求对象中,后续入库直接使用,避免了重复查询:
void checkTransParams(Req req){
//check Amount,and so on.
checkAmount(req.getamount);
//check payeebankNo
if(Utils.isEmpty(req.getPayeeBankNo())){
String payeebankNo = getPayeebankNo(req.getPayeeAccountNo);
if(Utils.isEmpty(payeebankNo)){
throws Exception();
}
}
//查询到有联行号,直接设置进去,入库时无需再查
req.setPayeeBankNo(payeebankNo);
}
int saveTransDetail(req){
insert(req);
...
}
1.5 优化SQL与索引
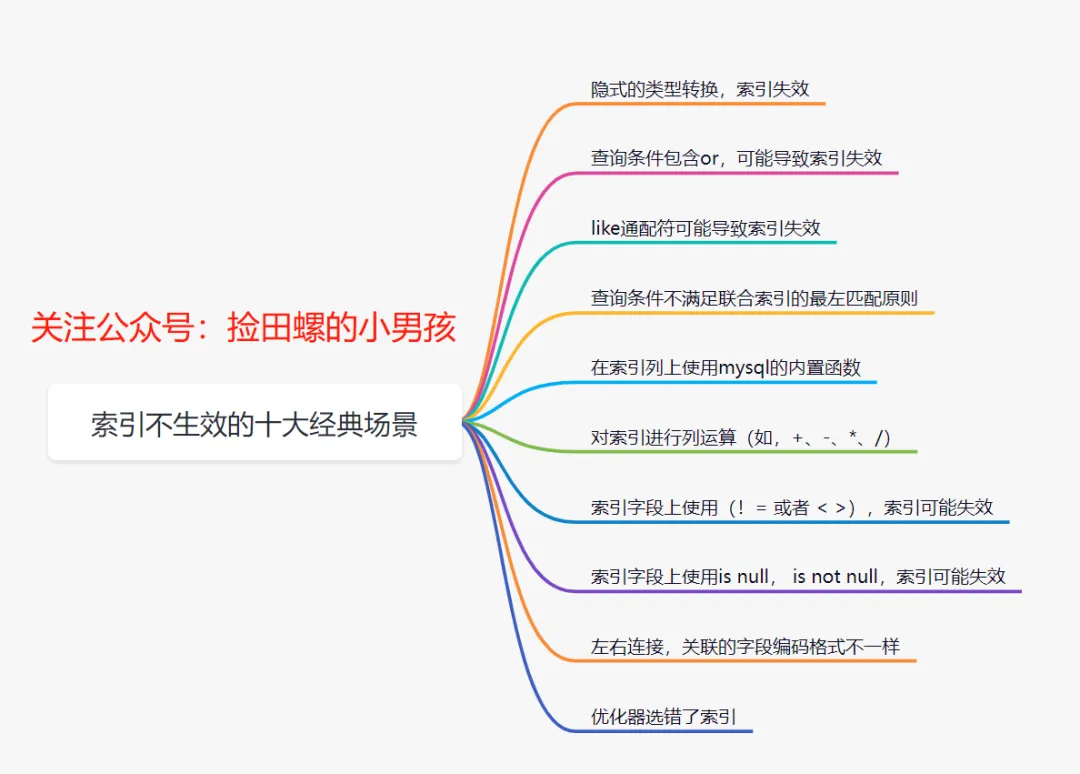
在这次优化中,我发现一个查询“交易中”状态流水的SQL,其索引设置不合理。原索引是分别在 create_time 和 trans_status 上建立的单列索引。结合业务场景分析后,我将其重构为一个 联合索引 (create_time, trans_status),查询效率得到提升。
索引优化是SQL优化的核心,常见的索引失效场景需要警惕,例如隐式类型转换、like通配符在前、不满足最左前缀原则等:
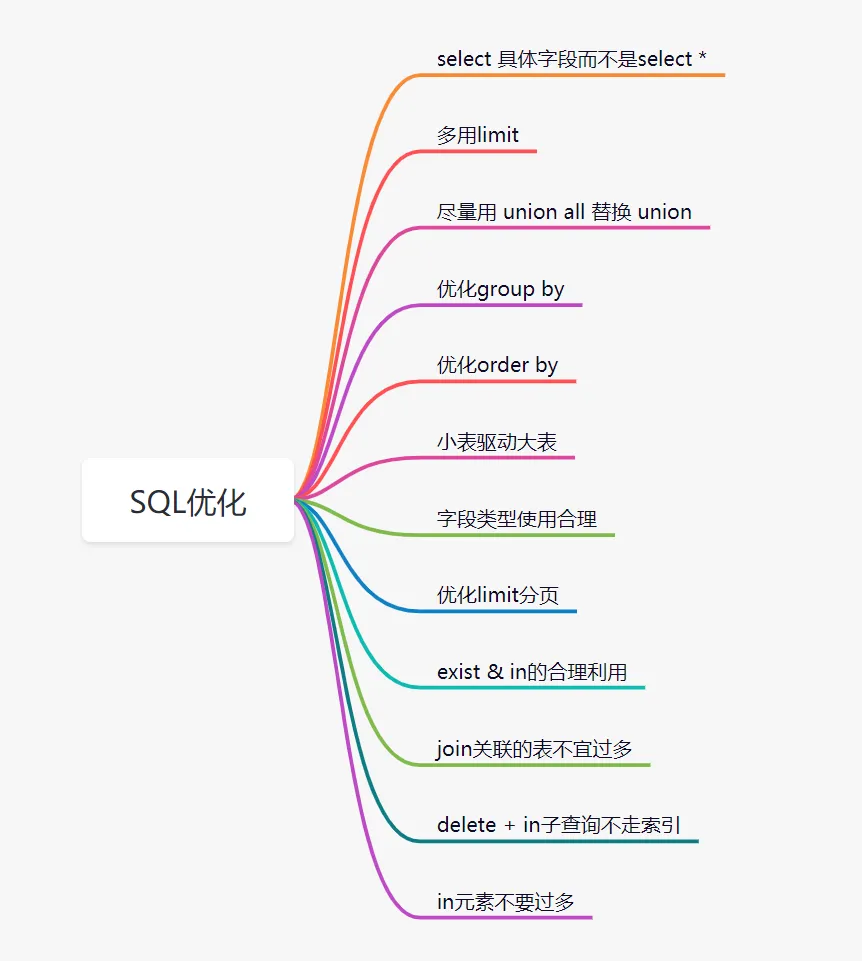
当然,SQL优化远不止索引,还包括避免SELECT *、巧用LIMIT、优化JOIN和子查询等:
1.6 大文件暂存,异步落地数据库
当需要入库的数据量非常大时,直接操作数据库可能会成为瓶颈。在我们的案例中,高并发下批量插入1000笔转账明细到数据库耗时长达6秒左右。
优化前流程:明细先入库,再异步转账。

优化思路转换:我们将这1000笔明细数据先上传到文件服务器,数据库中只记录一条汇总的转账总记录。然后,异步任务再去下载文件,解析明细并执行真正的转账和入库操作。
优化后流程:
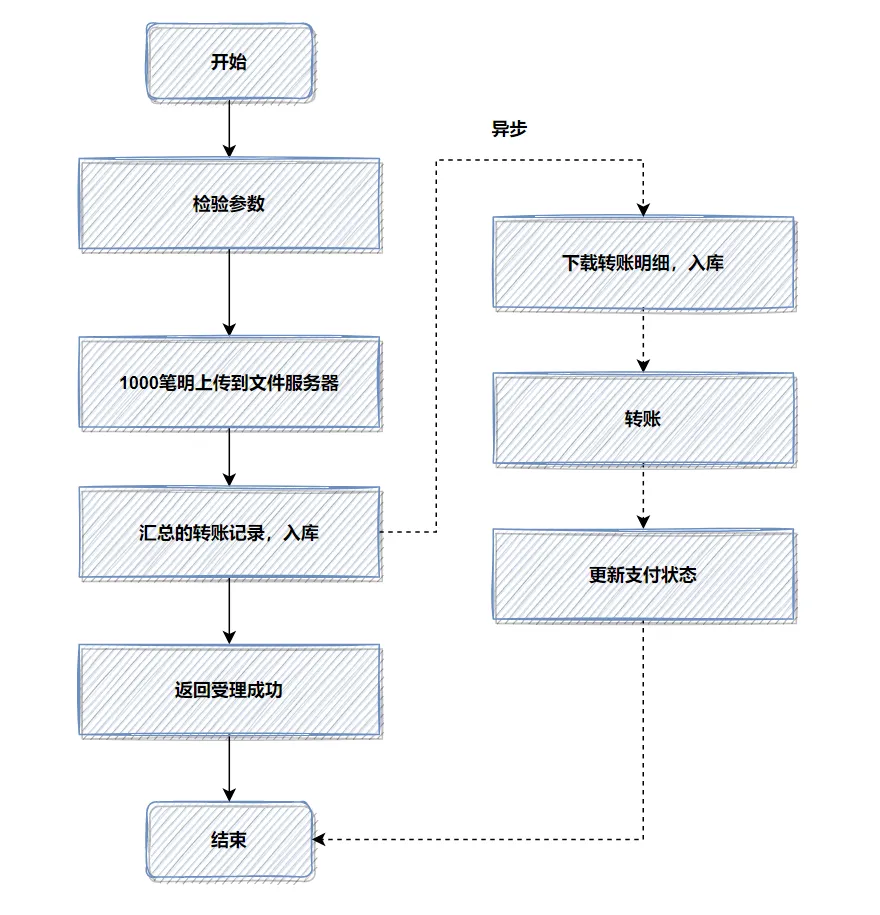
通过这种方式,接口的同步处理时间大幅缩短,性能提升了十几倍。这种思路也可以扩展到使用消息队列(MQ)暂存数据。
二、 其他常见的接口性能优化手段
除了上述实战中的具体方法,还有一些广泛适用的优化思想和手段。
2.1 池化思想:预分配与循环使用
为什么用线程池?因为线程的创建和销毁是重量级操作。池化技术通过预创建和循环利用资源(如线程、数据库连接、HTTP连接),避免了频繁的资源初始化开销。像TCP的Keep-Alive机制、数据库连接池都是这一思想的体现。在Java开发中,直接使用线程池而非频繁new Thread(),就是遵循池化思想。
2.2 预取思想:提前初始化到缓存
预取,顾名思义就是提前准备。对于那些计算复杂、耗时较长,且未来很可能被用到的数据,可以提前算好放入缓存。当真正需要时,直接从缓存中获取,响应速度极快。例如,直播平台提前将热门直播间的用户列表、积分榜等信息预热到缓存中。
2.3 事件回调思想:拒绝阻塞等待
当你调用一个耗时很长的下游服务时,不应该让主线程阻塞等待。可以参考IO多路复用的思想,采用事件回调机制。主线程发起调用后立即返回,去做其他事情。当下游服务处理完毕,通过回调函数或消息通知主线程,主线程再执行后续逻辑。这能极大提高系统的并发处理能力。
2.4 远程调用由串行改为并行
假设一个APP首页接口需要查询用户信息(200ms)、Banner信息(100ms)、弹窗信息(50ms)。如果串行调用,总耗时至少350ms。
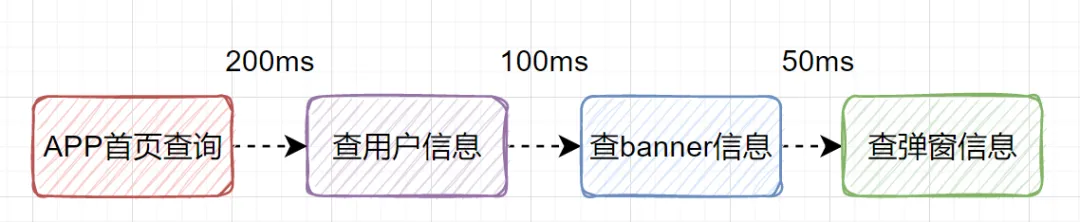
如果改为并行调用,总耗时取决于最慢的那个远程调用,即200ms,性能提升明显。

2.5 深分页问题优化
深分页LIMIT offset, size在offset很大时性能极差,因为它需要扫描并丢弃大量数据。
select id,name,balance from account where create_time> ‘2020-09-19’ limit 100000,10;
常用优化方案有两种:
- 标签记录法:记录上次查询到的最后一条记录的ID,下次查询以此为起点。适用于有连续自增字段的场景。
select id,name,balance FROM account where id > 100000 limit 10;
- 延迟关联法:通过子查询先快速定位到需要的主键ID,再通过主键关联回表查询,减少回表次数。
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > ‘2020-09-19’ limit 100000, 10) AS acct2 on acct1.id= acct2.id;
2.6 压缩传输内容
更小的传输报文意味着更快的网络传输速度。在接口设计上,可以考虑对返回的JSON、XML等数据进行压缩(如GZIP)。对于视频、图片等媒体资源,合理的编码压缩更是必不可少的优化环节。
2.7 排查服务器本身问题
有时接口慢并非代码问题,而是服务器状态异常,例如:
- 频繁Full GC:可能导致应用暂停。曾遇到导出大量Excel时,老版本Apache POI占用内存过大引发Full GC。
- 线程池被打满:所有线程都在忙碌,新请求只能排队等待。高并发场景下必须合理设置线程池参数并引入限流。
- IO资源未关闭:如数据库连接、文件流未关闭,会导致资源泄漏,系统变慢。
接口性能优化是一个系统工程,需要从后端架构设计、代码实现、数据库操作、网络传输等多个层面综合考量。希望本文分享的实战经验和通用思路,能帮助你在面对类似问题时,找到清晰的优化方向。
 发表于 2026-3-23 02:06:02
|
查看: 118|
回复: 0
发表于 2026-3-23 02:06:02
|
查看: 118|
回复: 0
