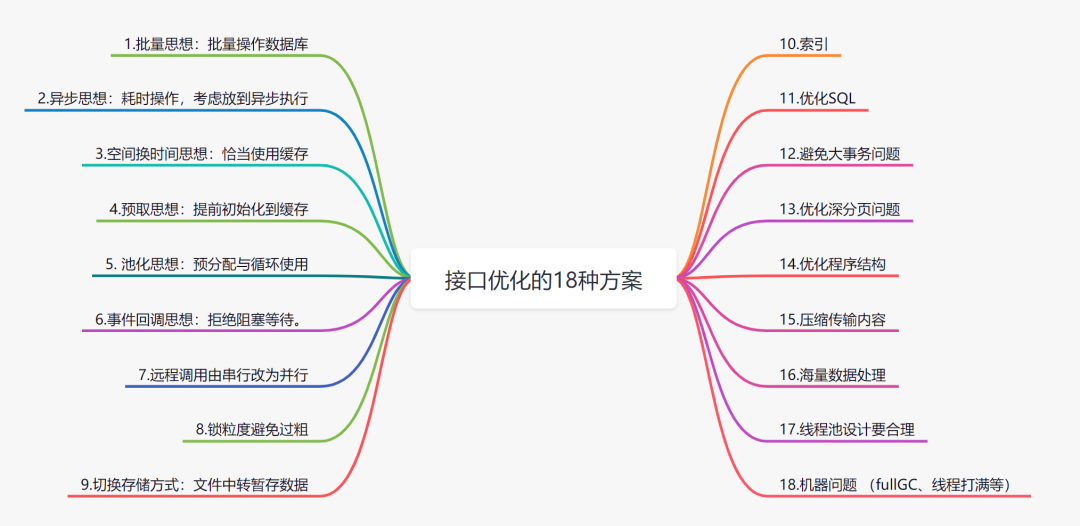
在后台开发中,接口性能直接关系到用户体验和系统吞吐量。一次真实的线上经历——因为接口超时触发了 nginx 配置的 10 秒超时报警,促使我对一个耗时长达 11.3s 的接口进行了深度优化,最终将其降至 170ms。这次优化过程积累了许多具有普适性的思路,我将它们梳理为以下 18 种方案,希望能为你提供清晰的优化路径。
1. 批量思想:批量操作数据库
将频繁的单次数据库操作合并为一次批量操作,能极大减少网络 I/O 和数据库事务开销。
优化前:
// for循环单笔入库
for(TransDetail detail:transDetailList){
insert(detail);
}
优化后:
batchInsert(transDetailList);
这个道理很简单:假设你需要把一万块砖搬到楼顶,电梯一次最多能放 500 块。你会选择一次搬一块,还是一次搬 500 块?答案显而易见,批量处理能显著减少往返次数和时间消耗。
2. 异步思想:耗时操作,考虑放到异步执行
耗时操作可以考虑异步执行,这样可以有效降低接口响应时间。以转账接口为例,其中“匹配联行号”这个步骤比较耗时。
优化前流程(同步执行):
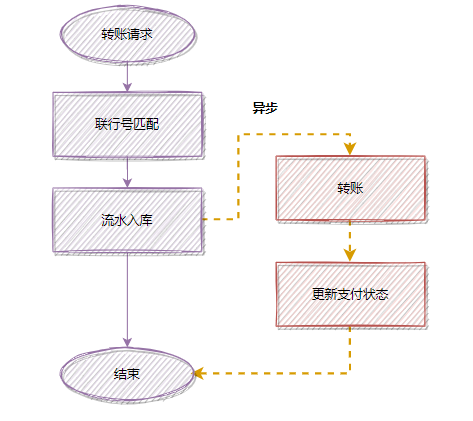
为了更快地给用户返回“受理成功”的响应,我们可以将“匹配联行号”这个步骤改为异步处理。
优化后流程(异步执行):
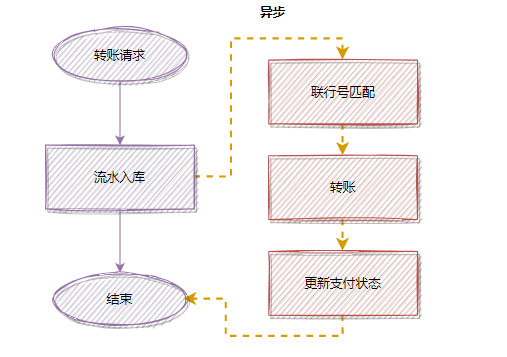
除了转账,日常开发中还有很多场景适合异步化,比如用户注册成功后的短信或邮件通知。实现异步的方式有多种,既可以利用线程池,也可以借助消息队列。
3. 空间换时间思想:恰当使用缓存
缓存是典型的“空间换时间”策略。将需要频繁查询或复杂计算的结果提前存储起来,使用时直接获取,避免重复的数据库查询或计算过程。缓存介质可以是 Redis、JVM 本地缓存或 memcached 等。
我曾优化过一个老版本的转账接口,它每次都会根据客户账号查询数据库并计算匹配联行号。
优化前流程(每次查库计算):
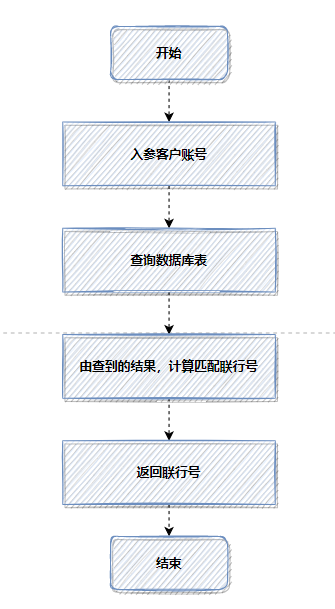
由于每次操作都涉及数据库查询和计算,耗时较长。引入 Redis 缓存后,流程优化如下:
优化后流程(优先查缓存):
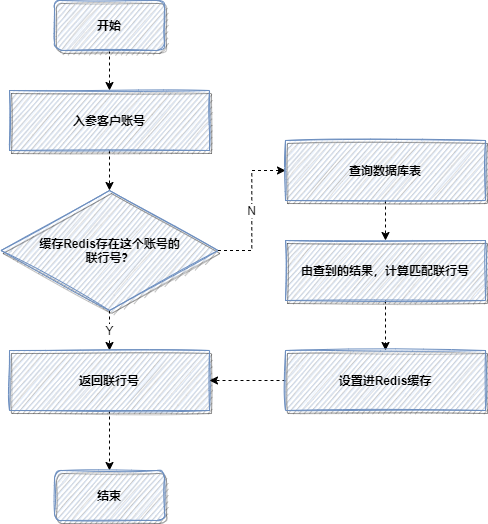
4. 预取思想:提前初始化到缓存
预取是缓存的进阶用法。如果某些数据在未来某个时间点极大概率会被使用,且实时计算成本很高,我们可以在系统空闲或初始化阶段提前算好并放入缓存。例如,在视频直播场景中,可以在服务启动时提前将直播列表相关的用户、积分等信息加载到缓存中,这样接口响应时直接读取即可,性能提升非常明显。
5. 池化思想:预分配与循环使用
池化思想的精髓在于 预分配与循环使用,避免频繁创建和销毁资源带来的开销。最典型的例子就是线程池。如果每次需要线程都去临时创建,会有不小的系统消耗;而线程池可以复用已创建好的线程。类似的思想也广泛应用于数据库连接池、HttpClient 连接池,甚至网络协议中(如 TCP 的 Keep-Alive 长连接)。在代码层面,直接应用这一思想就是使用线程池来管理并发任务,而不是随意地 new Thread()。
6. 事件回调思想:拒绝阻塞等待
当你调用一个下游系统接口,而该接口处理逻辑需要 10 秒甚至更久时,阻塞等待显然不合理。我们可以参考 IO 多路复用模型 的思想:不阻塞等待,而是先进行其他操作。当下游系统处理完毕后,通过 事件回调 通知我方,我方再执行相应的后续业务。这种模式在复杂的微服务调用链中尤为重要。
7. 远程调用由串行改为并行
假设一个 APP 首页接口需要调用三个下游服务:查用户信息(200ms)、查 banner 信息(100ms)、查弹窗信息(50ms)。
串行调用总耗时:
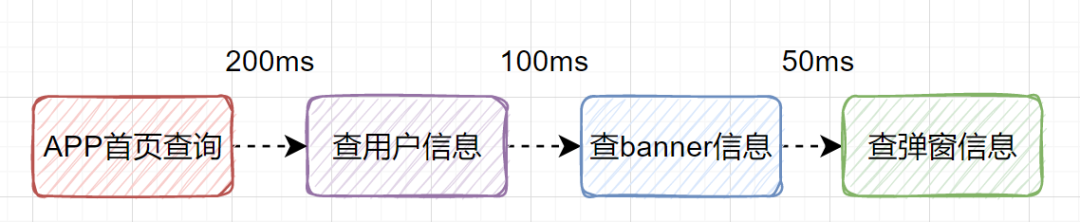
总耗时 = 200ms + 100ms + 50ms = 350ms
如果改为并行调用,同时发起这三个请求:
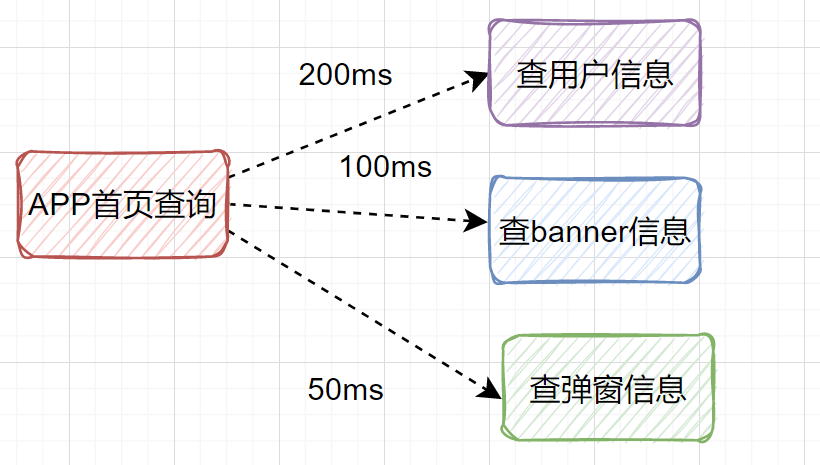
总耗时 ≈ 最慢的那个请求耗时(200ms)
接口耗时得以大幅降低。实现并行调用的方式,可以使用 CompletableFuture 或专门的并行调用框架模板。
8. 锁粒度避免过粗
在高并发场景下,加锁保护共享资源是必要的,但锁的 粒度 至关重要。锁粒度指的是锁住的范围大小。就好比你上厕所只需要锁卫生间的门,而不是把整个家都锁起来。
无论使用 synchronized 还是 Redis 分布式锁,都应该 只锁住真正的共享资源。来看一个例子,一个 ArrayList 在多线程环境下需要加锁,但其中有一段耗时操作 (slowNotShare) 并不涉及共享资源。
反例(锁粒度太粗):
//不涉及共享资源的慢方法
private void slowNotShare() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
}
}
//错误的加锁方法
public int wrong() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
//加锁粒度太粗了,slowNotShare其实不涉及共享资源
synchronized (this) {
slowNotShare();
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
正例(精细加锁):
public int right() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
slowNotShare();//可以不加锁
//只对List这部分加锁
synchronized (data) {
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
9. 切换存储方式:文件中转暂存数据
当需要落地数据库的数据量极大,导致插入操作异常缓慢时,可以考虑先用 文件 暂存。这是一个真实的优化案例:一个转账接口,并发处理 1000 笔明细数据直接入库耗时约 6 秒。
优化前流程(明细直接入库):
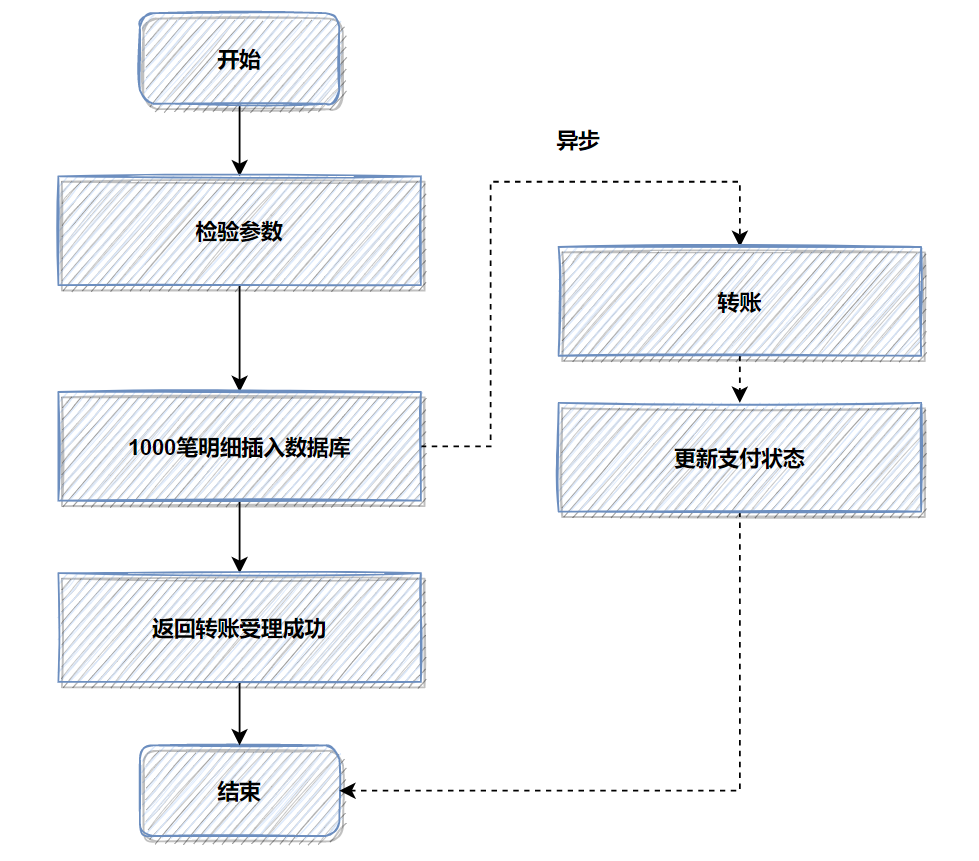
优化思路是:将批量转账明细数据先上传到文件服务器,数据库中只记录一笔汇总的转账总记录并立即返回。然后通过异步任务下载文件,再执行实际的转账和明细入库。
优化后流程(文件中转异步处理):
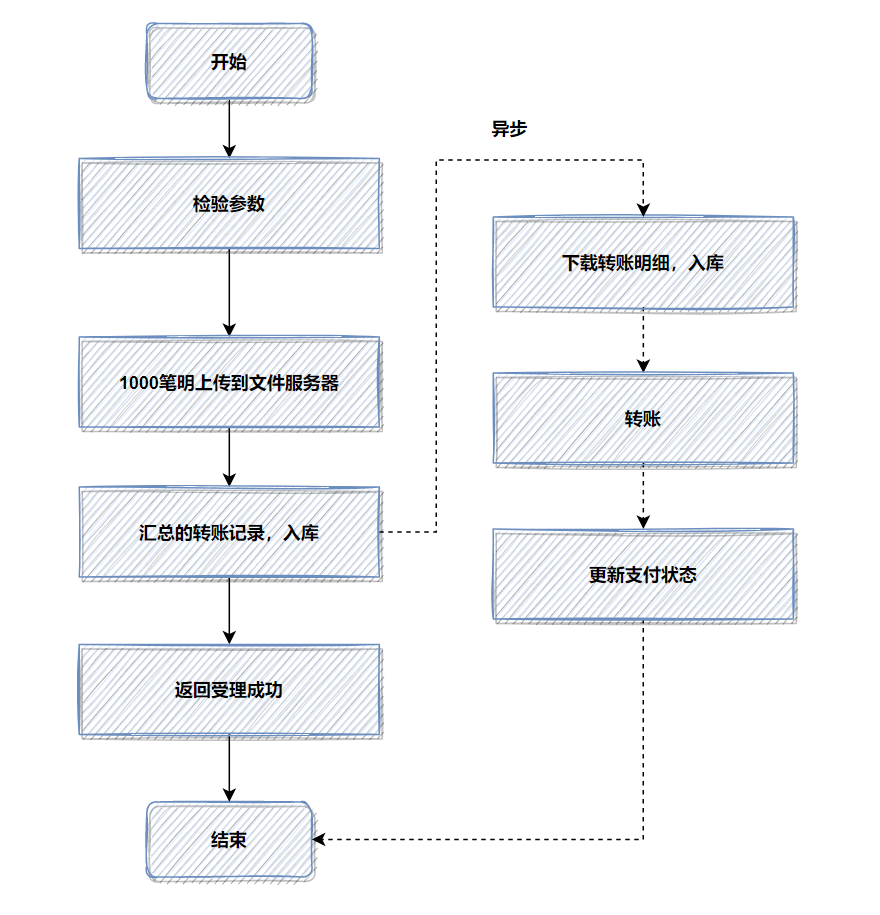
优化后性能提升了十几倍。有时,批量数据落地文件确实比直接插入数据库更高效。
10. 索引
为 SQL 添加合适的索引通常是成本最低、效果最显著的优化手段。优化索引主要从三个维度思考:
- 你的 SQL 加索引了吗?
- 你的索引真的生效了吗?
- 你的索引设计合理吗?
10.1 SQL没加索引
写完 SQL 后,应养成习惯使用 explain 查看执行计划。
explain select * from user_info where userId like '%123';
也可以通过 show create table 命令检查整张表的索引情况。
show create table user_info;
如果发现遗漏,可以使用 alter table add index 添加。通常,where、order by、group by 后面的字段需要考虑加索引。
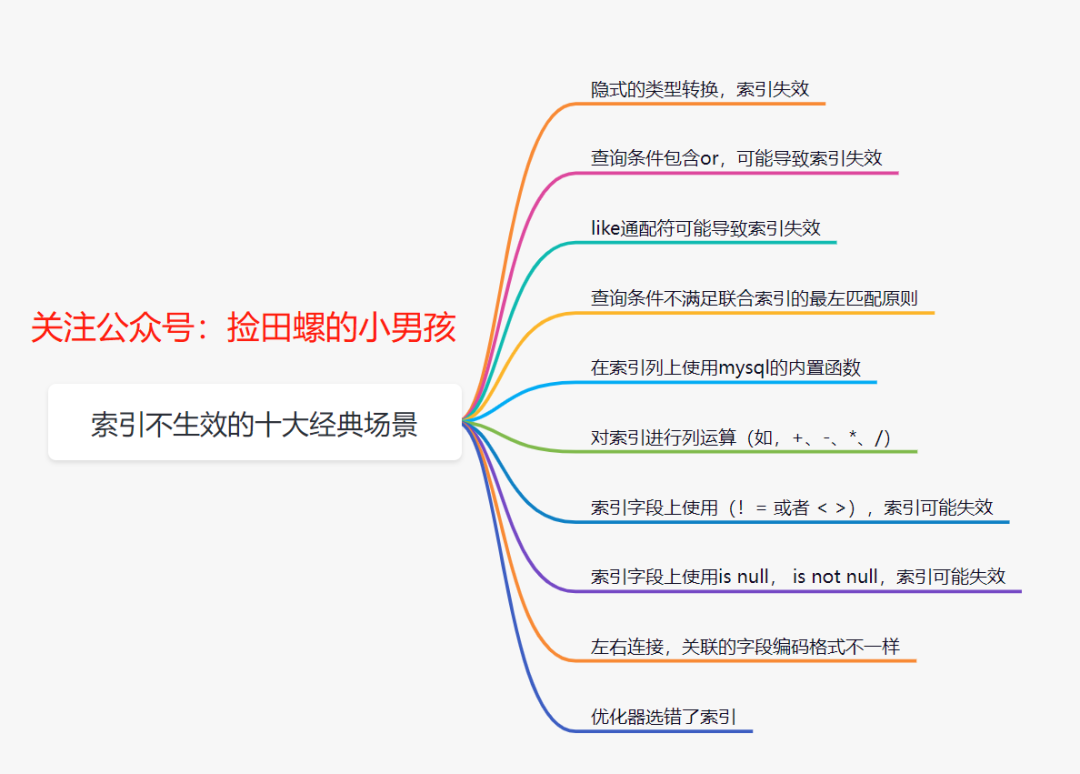
10.2 索引不生效
即使加了索引,在某些情况下索引也会失效。常见的索引失效场景包括:
- 隐式类型转换
like 语句以 % 开头- 查询条件包含
or
- 不满足联合索引的 最左匹配原则
- 在索引列上使用 MySQL 内置函数或进行运算
- 索引字段使用
!=、<>、is null、is not null
- 关联字段编码格式不一致
- 优化器选错索引
10.3 索引设计不合理
索引并非越多越好,需要合理设计:
- 删除冗余和重复的索引。
- 单表索引数量不宜过多(一般不超过5个)。
- 避免在区分度低的字段(如“性别”)上建索引。
- 善用覆盖索引来避免回表。
- 如果你需要使用
force index 来强制走某个索引,就需要反思索引设计是否合理了。
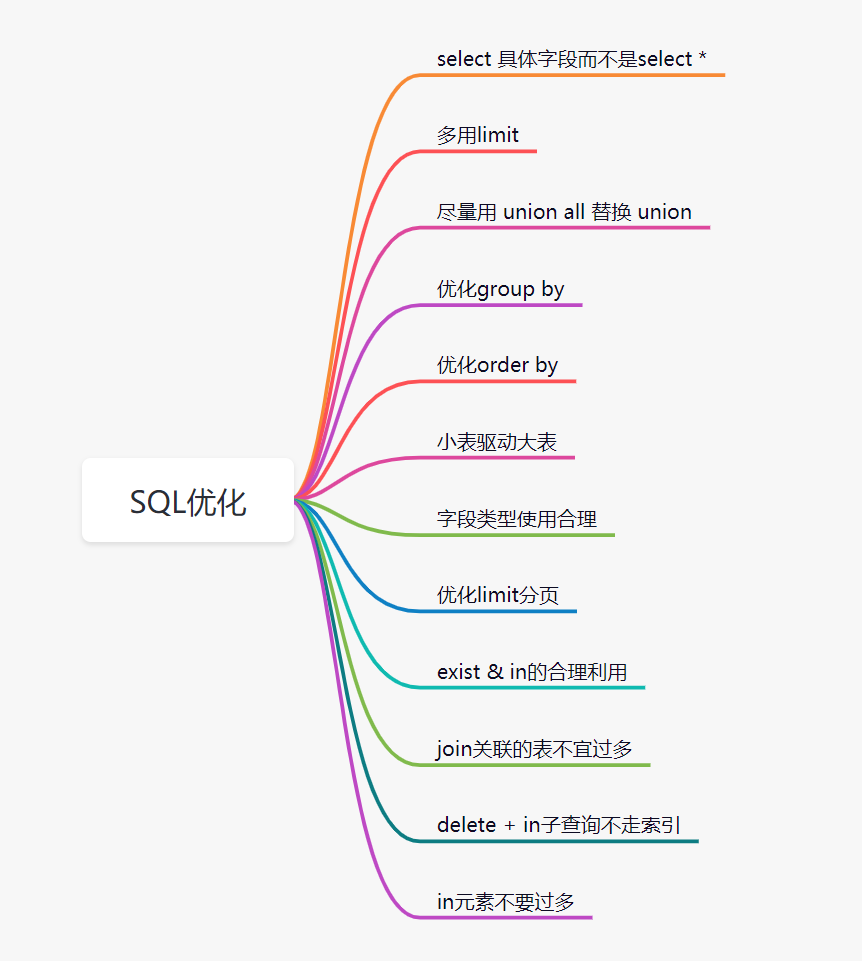
11. 优化SQL
除了索引,SQL 语句本身也有很多优化空间。例如:
select 具体字段而不是 select *- 善用
limit
- 尽量用
union all 替换 union
- 优化
group by 和 order by
- 遵循小表驱动大表的原则
- 使用合理的字段类型
- 优化
limit 深分页
exist & in 的合理利用join 关联的表不宜过多- 避免
delete + in 子查询
in 元素不要过多
12. 避免大事务问题
使用 @Transactional 注解管理事务很方便,但稍不注意就可能引发 大事务问题。大事务是指运行时间过长的事务,它会长时间占用数据库连接,在高并发下可能导致连接池被占满,进而影响其他接口性能,还可能引发接口超时、死锁、主从延迟等问题。
如何规避大事务?
- RPC远程调用不要放到事务里面:这是最常见的坑。
- 查询操作尽量放到事务外:除非必要,只将修改操作包含在事务内。
- 事务中避免处理太多数据:比如大批量的更新或插入。
13. 深分页问题
深分页是导致接口缓慢的常见原因之一。看下面这个 SQL:
select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
limit 100000,10 会扫描 100010 行,然后丢弃前 100000 行,最后返回 10 行,效率极低。优化方案主要有两种:
13.1 标签记录法
记录上次查询到的最大ID,下次查询从这个ID之后开始。
select id,name,balance FROM account where id > 100000 limit 10;
这种方式性能极佳,但要求有类似连续自增的字段。
13.2 延迟关联法
通过子查询先查到主键ID,再利用主键索引关联回原表,减少回表次数。
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;
14. 优化程序结构
优化代码逻辑本身也能节省大量耗时。例如,避免创建不必要的对象、消除重复的数据库查询、使用更高效的算法等。
一个简单的例子:调整复杂条件判断的顺序。假设业务逻辑是:如果用户是会员,并且是首次登录,则发送感谢短信。
原始代码(先判断 VIP,后判断首次登录):
if(isUserVip && isFirstLogin){
sendSmsMsg();
}
假设有 5 个请求,其中 3 个是 VIP,只有 1 个是首次登录。那么 isUserVip 执行了 5 次,isFirstLogin 执行了 3 次。

优化后代码(先判断首次登录,后判断 VIP):
if(isFirstLogin && isUserVip ){
sendMsg();
}
调整后,isFirstLogin 执行了 5 次,而 isUserVip 仅执行了 1 次(只有首次登录的用户才会判断是否为 VIP),效率更高。

15. 压缩传输内容
减少传输数据的大小可以显著降低网络传输耗时。特别是在带宽有限或数据量大的场景下(如视频、图片、大文本传输),对传输内容进行压缩(如 GZIP)是非常有效的优化手段。想象一下,一匹快马驮 10 斤货物,肯定比驮 100 斤跑得快。
16. 海量数据处理,考虑NoSQL
当关系型数据库(如 MySQL)在处理海量数据的模糊搜索、统计分析遇到瓶颈,即使优化了深分页效果也不佳时,可以考虑引入 NoSQL。例如,将数据同步到 Elasticsearch 来处理复杂的搜索查询,或者使用 HBase 来存储海量的明细数据。对于超大规模数据,关系型数据库的分库分表是最终方案,但 NoSQL 往往是更优的 specialized 选择。
17. 线程池设计要合理
使用线程池是为了并行处理任务,提升效率。但如果线程池参数设计不合理,反而会拖累接口性能。需要重点关注:
- 核心线程数:设置过小,无法充分利用CPU并行能力;设置过大,增加上下文切换开销。
- 阻塞队列:选择不当(如无界队列)可能导致内存溢出(OOM)。
- 线程隔离:不同业务应使用不同的线程池,避免核心业务被非核心业务拖垮。
18. 机器问题 (fullGC、线程打满、太多IO资源没关闭等)
有时接口变慢的根源在服务器本身。
- Full GC:例如,我曾遇到用老版本
Apache POI 导出几十万行 Excel 时,因一次性生成数据量过大导致 JVM 内存吃紧,频繁 Full GC,系统几乎卡死。
- 线程打满:某个接口耗时变长,可能导致处理线程全部被占用,后续请求排队。此时需要考虑引入 限流 机制。
- IO资源未关闭:数据库连接、文件流、网络连接等未正确关闭,会导致资源泄漏,系统越来越卡。
总结
接口性能优化是一个系统工程,需要从代码、数据库、架构、服务器等多个层面进行综合审视。本文梳理的 18 种方案,从最基础的批量和异步,到深入的索引、锁、事务、缓存、线程池,再到架构层面的并行、文件暂存、NoSQL 选型,基本覆盖了后端优化的核心场景。希望这些来自实战的总结,能成为你下一次性能攻坚的利器。
这些方案不仅适用于解决已知的性能问题,更应该在系统设计初期就作为指导原则。如果你对其中某一点有更深入的兴趣,或者想探讨具体实现,欢迎来 云栈社区 与更多开发者交流。
 发表于 2026-3-23 02:03:20
|
查看: 173|
回复: 0
发表于 2026-3-23 02:03:20
|
查看: 173|
回复: 0
