在嵌入式开发领域,像GPIO、ADC、I2C、SPI这些外设模块大家都很熟悉,但DMA(直接内存访问)对不少开发者来说却有点神秘。DMA到底是怎么工作的?它在系统中究竟扮演什么角色?今天,我们就深入探讨一下这个能显著提升系统效率的“幕后功臣”。
1. 理解DMA的核心概念
DMA是“Direct Memory Access”的缩写,中文译为“直接内存访问”,意指无需CPU(中央处理单元)介入,就能在内存与外设之间直接进行数据读写操作。
这里的“内存”主要指嵌入式MCU内部的Flash(程序存储器)和RAM(数据存储器)。那么,“直接”二字究竟意味着什么?
程序运行时,存储器的核心任务就是存取数据。举个例子:外设ADC模块完成一次采样后,数据会暂存在其内部的寄存器里。如果我们想把这个数据保存到RAM中,ADC模块自身是无法做到的。传统方式需要CPU出手:它先访问ADC的数据寄存器读取数据,然后再将数据写入RAM指定的地址。
另一个例子是从Flash读取数据到RAM,同样需要CPU分别访问Flash和RAM,完成“读-写”两步操作。
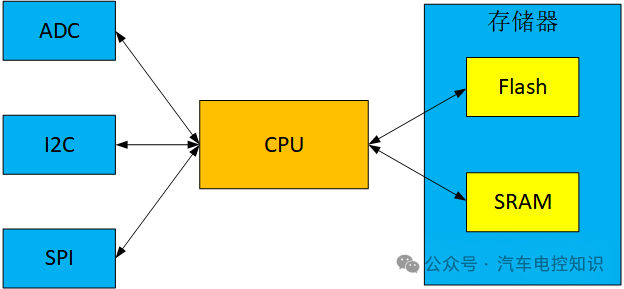
常规存储器访问流程
因此,在传统架构中,只有CPU拥有直接访问所有存储器的“特权”,其他外设模块都不行。每次ADC完成采样、I2C接收到数据,都需要通过中断通知CPU,CPU则暂停手头工作,立刻响应中断去搬运数据。
这种方式虽然便于CPU统一管理和协调所有数据流,但在面对大量、高频的数据传输时,弊端就显现了:简单的数据搬运工作会占据CPU大量时间。而CPU的核心价值在于执行复杂的算法、逻辑判断和数据分析。如果宝贵的时间都耗在搬数据上,系统的整体性能和处理实时性必然大打折扣。
这就好比一位建筑师,核心工作是设计蓝图和把控结构。偶尔搬几块砖没问题,但如果每天7小时都在搬砖,那他就成了搬运工,本职工作必然被耽搁。最高效的方式,是引入专门的“搬运工”——DMA。它允许外设绕过CPU,直接与系统内存进行高速数据交换,让“建筑师”和“搬运工”各司其职。
2. 剖析DMA的总线架构
我们以常见的STM32系列微控制器为例,来看看DMA是如何在硬件上实现“直接访问”的。首先需要了解其总线架构。
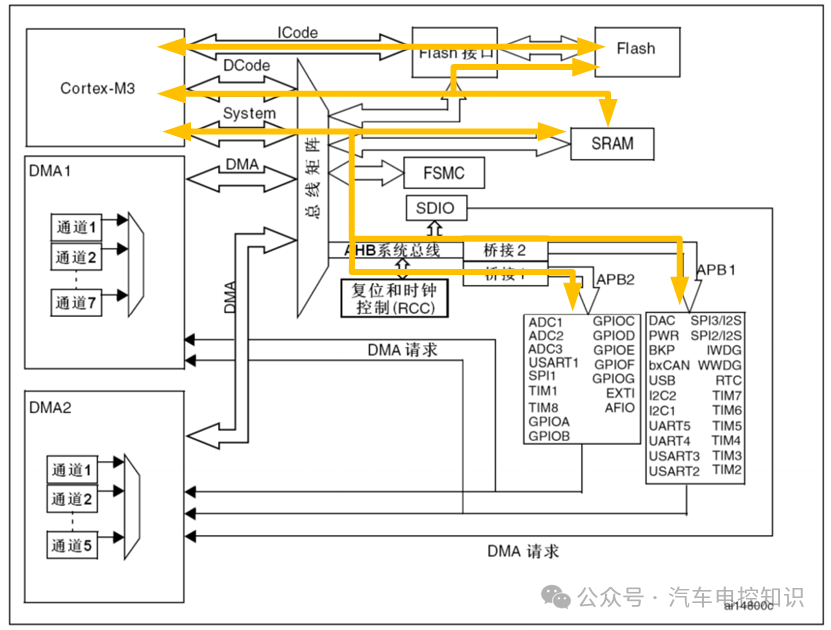
系统总线架构图(以Cortex-M3为例)
如上图所示,CPU(Cortex-M3内核)通过多条总线与外部世界连接:
- ICode总线:用于从Flash中取指令。
- DCode总线:用于访问Flash和
SRAM中的数据。
- System总线:用于访问
SRAM和外设(如ADC、I2C等)的寄存器。
DMA要实现其功能,也必须具备总线通信能力。它拥有自己专属的DMA总线。
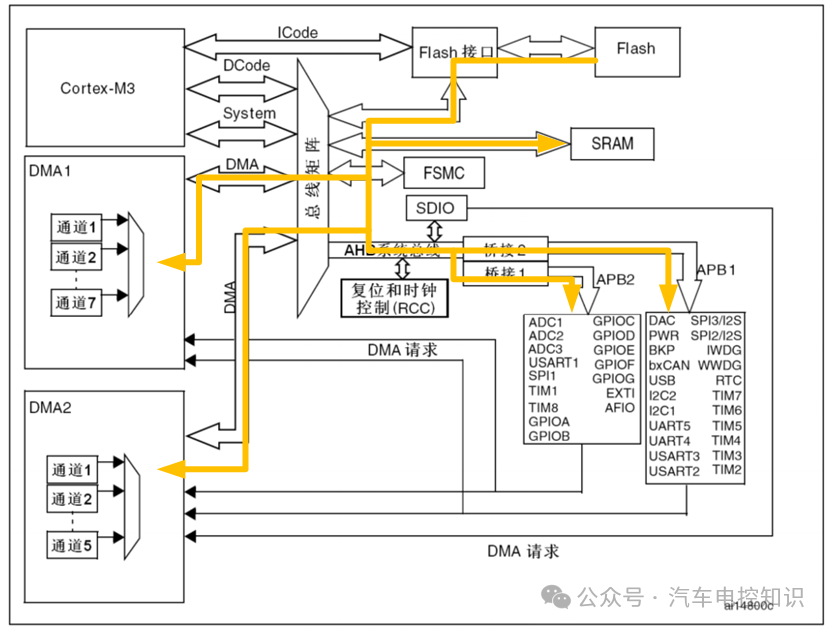
DMA总线架构图
典型的STM32拥有两个DMA控制器:DMA1和DMA2。每个控制器都有专用的DMA总线,通过它可以直接访问Flash、SRAM以及各种外设。
从架构图可以看出,DMA不仅能完成外设与存储器之间的传输,还能实现存储器之间的数据传输(例如从Flash复制数据到SRAM)。不过,DMA通常对Flash没有写入权限,只能读取。
DMA1和DMA2共提供12个独立的通道(DMA1有7个,DMA2有5个)。每个通道就是一条独立的数据传输路径,负责从一个源头搬运数据到一个目的地。例如,ADC到RAM用通道1,Flash到RAM用通道2,它们互不干扰。
外设(如ADC)完成一次操作后,会向DMA发出一个硬件请求信号。
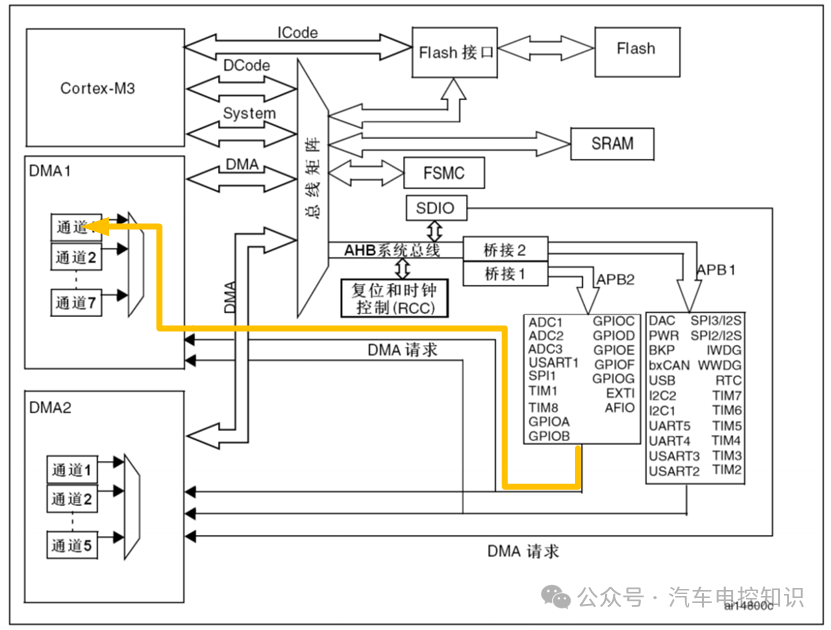
ADC发出DMA请求
DMA控制器收到请求后,便会自动启动一次数据传输。从理论上讲,DMA可以和CPU并行工作。例如,CPU通过ICode总线取指令时,DMA可以通过自己的总线访问外设,两者互不影响。
然而,当CPU需要通过DCode或System总线访问资源,而DMA也恰好需要使用共享的总线矩阵时,就会产生访问冲突。此时,总线仲裁器会根据预设的优先级进行调度。为了保证实时数据(如高速ADC采样值)不丢失,DMA的优先级通常被设置为高于CPU。DMA在获取总线使用权后完成单次传输,然后释放总线。
因此,所谓的“直接内存访问”,并非外设直接触碰存储器,而是外设通过DMA这个专门的数据传输控制器来访问存储器,其“直接性”体现在绕过了CPU的干预。
3. DMA的内部工作机制
看完系统级框图,我们再深入到DMA控制器的内部,看看它是如何运作的。
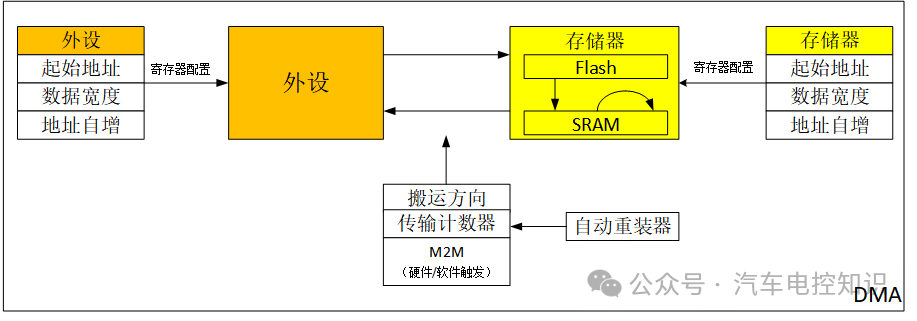
DMA内部结构框图
如图所示,DMA的数据传输方向是可配置的:
- 外设 → 存储器
- 存储器 → 外设
- Flash →
SRAM
SRAM → SRAM(注意,通常不支持SRAM → Flash,因为Flash是只读的)。
方向确定后,源地址和目标地址也随之确定。接下来,还需要配置几个关键参数:
- 起始地址:数据源和目标的起始位置。
- 数据宽度:单次传输的数据位宽,可选字节(8-bit)、半字(16-bit)或字(32-bit)。例如,
ADC结果为16位,就应选择半字。
- 地址自增:传输完成后,地址是否自动指向下一个单元。这对于搬运数组数据至关重要。如果源地址不自增,会一直读取同一个数据;如果目标地址不自增,新数据会不断覆盖同一位置。
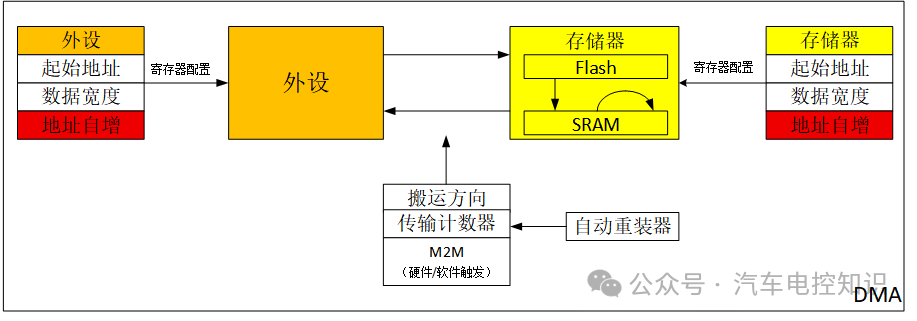
地址自增设置场景示例
-
传输计数器:设定需要传输的次数。比如计数器设为8,数据宽度为字节,则总共传输8字节。每完成一次传输,计数器自动减1,减到0时传输停止,所有自增的地址会复位到起始值。
-
自动重装:如果希望传输计数器归零后能自动重新加载初始值并开始新一轮传输,就需要启用此功能。这对于需要循环缓冲区的应用(如连续ADC采样)非常有用。
-
触发方式:通过M2M(Memory to Memory)位选择。
M2M = 1:软件触发。适用于存储器到存储器的搬运,由软件指令启动,会连续搬运直至计数器归零。M2M = 0:硬件触发。适用于外设参与的传输,由外设的硬件事件(如ADC转换完成、UART收到数据)触发,通常一次事件只搬运一个单位数据。
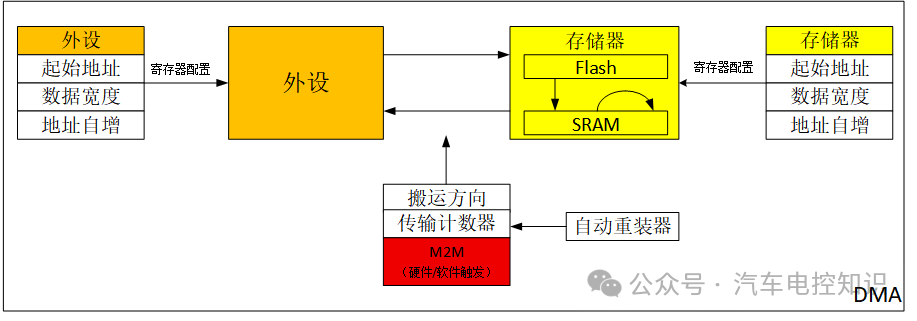
M2M设置决定软件或硬件触发
4. DMA应用代码示例
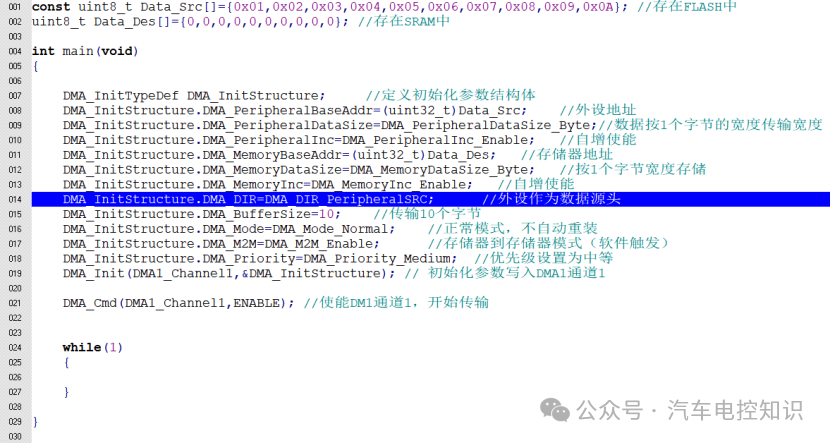
理论说了这么多,我们通过一个实际的C语言代码例子,看看如何配置DMA实现从Flash到SRAM的数据搬运。
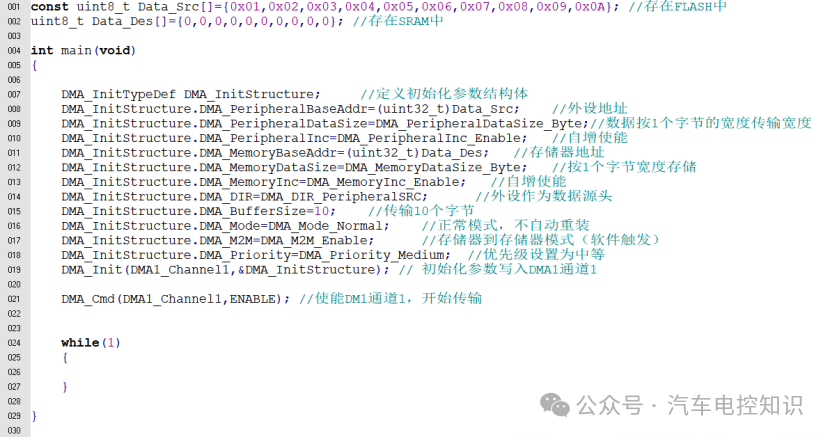
示例:从Flash搬运数据到SRAM
如上图代码所示:
- 定义两个数组:源数组
Data_Src[] 和目标数组 Data_Des[]。用 const 关键字修饰 Data_Src,使其成为常量,确保它被链接到Flash区域。
- 初始化DMA结构体
DMA_InitStructure。
- 外设地址:虽然我们是存储器间传输,但在
STM32标准外设库中,数据源的一方统称为“外设基地址”。这里我们将源数组 Data_Src 的地址(即Flash地址)赋给它。注意需要进行类型转换 (uint32_t)。
- 外设数据宽度与自增:设置为字节宽度,并启用地址自增。
- 存储器地址:将目标数组
Data_Des 的地址(SRAM地址)赋给此参数。同样需要类型转换,并设置为字节宽度和地址自增。
- 传输方向:设置为外设为数据源(
DMA_DIR_PeripheralSrc),即从Flash到SRAM。
- 缓冲区大小:设置为10,即传输10个字节。
- 模式:选择普通模式(
DMA_Mode_Normal),传输一次后停止。
- M2M模式:使能,表示使用软件触发。
- 优先级:设置为中等。
- 调用
DMA_Init 函数将配置写入DMA1的通道1。
- 调用
DMA_Cmd 使能通道1,传输立即开始。
数据搬运方向设置对应关系
程序执行后,Data_Des 数组的内容将从全0变为 {0x01, 0x02, ..., 0x0A},与 Data_Src 完全一致,整个过程无需CPU参与。
5. 总结
传统的CPU搬运数据方式,即使在中断驱动下,也会消耗可观的CPU资源与时间。而DMA作为硬件级的数据传输引擎,能够以接近总线带宽的极限速度进行数据搬移,在效率、功耗和实时性方面优势显著。
它尤其适合处理连续、大批量的数据传输场景,例如高速ADC采样、UART串口通信、音频流处理、图像数据传输等。合理运用DMA,将CPU从繁重的数据搬运劳动中解放出来,是优化嵌入式系统性能、实现高效内存管理的关键手段之一。对于更深入的系统架构和底层原理探讨,欢迎在云栈社区与更多开发者交流分享。
 发表于 2026-3-23 02:59:39
|
查看: 206|
回复: 0
发表于 2026-3-23 02:59:39
|
查看: 206|
回复: 0
