这两天科技圈有个挺热闹的事:美国AI公司Cursor发布的Composer 2模型,被指出可能基于中国公司月之暗面(Moonshot AI)开源的Kimi 2.5模型开发。一时间,关于技术溯源和合规性的讨论传得沸沸扬扬。
很快,双方就出来澄清了,证实这只是一场误会。
这个事件的背后,其实牵扯到中美AI竞争、技术全球化依赖等宏大叙事,媒体们也分析得很透彻。但对我来说,这件事里更值得玩味的是一个更具体、更实操的话题——开源项目的商业授权,到底是怎么运作的?
月之暗面在公开说明里有一句话,点明了关键:
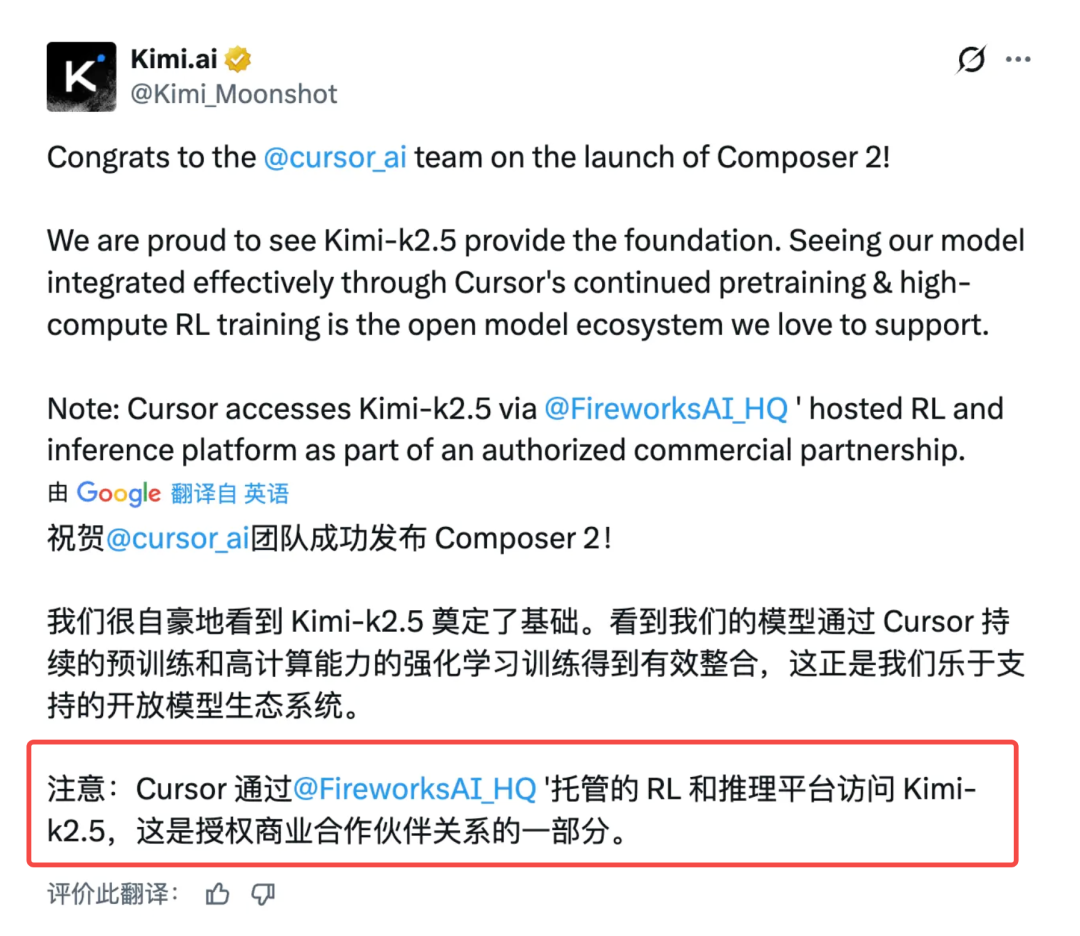
注意我圈出的红框部分:“Cursor 通过 @FireworksAI_HQ 托管的 RL 和推理平台访问 Kimi-K2.5,这是授权商业合作伙伴关系的一部分。”
这句话翻译一下就是:Fireworks AI 这个平台,已经和 Kimi 的模型方完成了商业授权。它拿到授权后,不仅部署了模型,还在此基础上叠加了推理优化和强化学习(RL)能力,打包成一套“模型即服务”(Model-as-a-Service)对外提供。而 Cursor,就是向 Fireworks 采购这套服务的客户。
整个链条非常清晰:

Kimi(模型方)↓ 授权
Fireworks AI(商业托管)↓ API / 服务
Cursor(产品公司)
这下有意思了。我们经常听说开源项目有“商业授权”,也常讨论“双许可协议”或者“社区版 vs 商业版”。但具体到操作层面,很多人其实并不清楚。这次事件,堪称是开源行业一次极其清晰、具体且影响广泛的“商业授权”现场教学。
原来,开源AI大模型的商业授权,可以这么玩(至少这是其中一种主流玩法)。

Fireworks 在这里做了一件非常典型的事:它与模型提供方(Kimi)达成商业授权协议,将模型部署在自己的高性能基础设施上,进行深度优化并增加增值服务(如强化学习),然后以API或服务平台的形式售卖给终端企业。
对于Cursor这样的应用公司来说,它购买的并不是Kimi模型的源代码或权重文件,也不是自己去部署一个开源模型。它做的更简单、更现实:直接向Fireworks付费,使用其提供的、已经处理好一切合规与性能问题的服务。
一旦进入这种“模型-平台-客户”的托管链条,游戏规则就变了。
在这个结构里,Cursor完全不需要关心Kimi模型采用的是哪种开源协议,也不需要自己组建团队去部署和运维一个动辄数百GB的AI大模型。它只需要和Fireworks签一份商业合同,然后按调用量或资源使用量付费。
换句话说,约束Cursor行为的,不再是开源许可证,而是它与Fireworks之间的商业合同。
从本质上看,这不是一次技术合作或开源贡献,甚至不完全是“使用某个模型”,而是一笔标准的SaaS(软件即服务)采购。就好比:
- 你使用阿里云ECS,不等于你在直接使用和管理开源Linux内核。
- 你使用Amazon RDS,也不等于你在手动配置开源的MySQL。
- 同理,Cursor使用Fireworks的服务,也不代表它在直接使用“开源”的Kimi模型。
这条路径,实际上已经脱离了传统的“开源使用”范畴,进入了成熟的“商业服务体系”。
所以再强调一次关键点:一旦模型被托管在商业平台上,交易对象就从“模型”本身变成了“服务”,核心约束力也从“开源协议”转移到了“商业合同”。
整个过程的合规性,根植于平台方(Fireworks)与模型方(Kimi)之间的商业授权协议,而不再是开源许可证本身。Fireworks通过商业合作获得了模型的分发与商业化使用权,并整合自身能力提供服务。像Cursor这样的公司,通过采购服务来获得AI能力,这条商业链路是清晰且合规的。
这也揭示了AI大模型时代的一个现实:由于训练和推理成本极高(即便是部署成本也不菲),开源大模型的主流采用路径,早已不是传统开源软件的 “开源软件 → 终端用户” 模式,而是变成了 “开源模型 → 商业平台 → 应用公司 → 终端用户” 的链条。这个商业模式的话题,对于做AI产品的朋友来说也很有探讨价值,以后可以再细聊。
最后提个醒:下次再看到不同厂商的模型表现类似,先别急着下“抄袭”的结论。很可能,它们只是采购了同一家商业平台提供的、基于同一开源基础模型优化的服务。这在人工智能的商业化生态中,正变得越来越常见。
如果你对这类开源与商业结合的实战案例感兴趣,欢迎来云栈社区一起交流讨论,这里聚集了不少关注前沿技术落地的开发者。
 发表于 2026-3-24 03:11:12
|
查看: 178|
回复: 0
发表于 2026-3-24 03:11:12
|
查看: 178|
回复: 0
