本文将介绍聪明钱因子(Smart Money Factor)的4.0版本。
这个因子的核心思想源于开源证券的魏建榕老师,他在研报中提出了前两个版本。笔者在《聪明钱因子,IC虽然不高,但分层回测还不错!》和《聪明钱因子模型的2.0版本,思路打开,因子变多也变好!》两篇文章中对其进行过复现。
后来,笔者也尝试过一些“魔改”:先是根据“待著而救”因子改写了一下聪明钱因子(见《根据“待著而救”因子改进“聪明钱”因子,会取得更好的效果吗?》),然后又瞎弄了一个聪明钱因子的3.0版本(见《邪修!聪明钱因子3.0版本,IC和分层回测全方面的提升!》)。
所谓聪明钱因子,其核心是 一段时间内的VWAP(成交量加权平均价)与整个时间段内VWAP的比值。
在V3版本中,笔者将其修改为 一段时间内的VWAP与其余时间VWAP的比值。
因此,改进这个因子的关键,就在于如何定义和选择这“一段时间”。V4版本引入了新的思路,使用 马尔科夫链 的状态转移来界定异常交易时刻。
计算步骤与代码实现
这个因子的计算核心是基于马尔科夫链。我们将每分钟的收益率大于0划分为状态“1”,小于等于0划分为状态“0”。其中,状态的先验概率和转移概率通过当日的市场收益率进行估计。这属于典型的基于数据科学的概率模型应用。
1. 计算步骤
第一步,计算全市场所有标的分钟收益率的均值,作为市场收益率。将其按大于0和小于等于0划分为状态1和状态0。
第二步,估计先验概率和转移概率。
- 状态0的先验概率为:状态0出现的次数占比。
- 状态1的先验概率为:状态1出现的次数占比。
- 状态1转移到状态0的概率为:t时刻为状态1且t+1时刻为状态0出现的次数与t时刻为状态1的总次数的比值。
- 其余转移概率可依此类推。
第三步,设定时间窗口为5,滚动计算每五分钟的状态转移序列出现的概率。
第四步,取市场收益率滚动5分钟状态转移序列出现概率的5%分位数,作为阈值。
第五步,对于每个标的,其滚动5分钟转移序列出现的概率若小于第四步得到的阈值,则认为该序列最后一个状态出现的时刻为异常时刻。
第六步,计算所有异常时刻的VWAP价格与所有非异常时刻VWAP价格的比值,即得到聪明钱因子V4。
2. 代码实现
下面的代码展示了单日处理的核心逻辑。计算步骤结合代码会更容易理解。
def process_single_day(self, idx):
# 加载当日分钟数据
file_name = self.files[idx]
date_str = file_name.split('.')[0]
cur_time = pd.to_datetime(date_str) + timedelta(hours=15)
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['close', 'open', 'volume', 'turnover']).to_dataframes()
rtn = data['close'] / data['open'] - 1
rtn['mkt'] = rtn.mean(axis=1)
prob = self.cal_prob(rtn, rtn['mkt'])
thd = prob['mkt'].quantile(0.05)
flag = (prob.iloc[:, :-1] < thd)
res = flag.mean()
res = res.to_frame()
res.columns = ['anomaly_ratio']
res['datetime'] = cur_time
money = data['turnover'].shift(-4).dropna()
vol = data['volume'].shift(-4).dropna()
anomaly_vwap = (money * np.where(flag, 1.0, np.nan)
).sum() / (vol * np.where(flag, 1.0, np.nan)).sum()
norm_vwap = (money * np.where(flag, np.nan, 1.0)
).sum() / (vol * np.where(flag, np.nan, 1.0)).sum()
res['smart_money'] = anomaly_vwap / norm_vwap
return res
- 第1-7行:读取指定日期的分钟级行情数据。
- 第8行:计算每分钟的收益率。
- 第9行:计算市场平均收益率。
- 第10行:调用
cal_prob 方法计算状态转移序列的概率,这是该因子计算的核心,涉及马尔科夫链的概率计算。
- 第13-15行:计算每个标的异常时刻的占比。
- 第17-18行:将成交额和成交量向前平移4分钟,目的是与
prob的计算窗口对齐(9:31的数据对应9:31到9:35的序列)。
- 第19-23行:分别计算异常时刻和非异常时刻的VWAP,并求比值,得到最终的聪明钱因子V4值。
接下来是关键的概率计算函数 cal_prob:
@staticmethod
def cal_prob(data, mkt):
mkt = mkt > 0
prob = mkt.mean()
data = data > 0
state_prob = data * prob + (1 - data) * (1 - prob)
transfer_11 = mkt.shift(-1)[mkt].mean()
transfer_01 = mkt.shift(-1)[~mkt].mean()
prob_list = [transfer_11, 1-transfer_11, transfer_01, 1-transfer_01]
transfer_list = [data & data.shift(-1), data & (1-data.shift(-1)),
(1 - data) & data.shift(-1), ~data & (1 - data.shift(-1))]
transfer_prob = 0
for flag, prob in zip(transfer_list, prob_list):
tmp_prob = flag * prob
transfer_prob += tmp_prob
transfer_prob = np.exp(np.log(transfer_prob).rolling(4).sum()).shift(-3)
prob = state_prob * transfer_prob
return prob.dropna()
- 第3行:将市场收益率序列二值化为状态(1或0)。
- 第4-6行:计算每个标的每分钟的先验概率矩阵。先验概率即马尔科夫链的初始状态为0或1的概率。
- 第7行:计算从状态1转移到状态1的概率(它与从状态1到状态0的概率之和为1)。
- 第8行:计算从状态0转移到状态1的概率。
- 第9-15行:计算每个标的每分钟的状态转移概率矩阵。例如,9:31的数据代表了从9:31的状态转移到9:32状态的概率。
-
第16-18行:计算滚动5分钟状态转移序列出现的概率。这是算法实现的关键步骤。
简单说明:以9:31的数据为例,它代表从9:31到9:35这五分钟(状态序列 S31, S32, S33, S34, S35)出现的概率。计算公式为:
P(S31) * P(S31->S32) * P(S32->S33) * P(S33->S34) * P(S34->S35)。
代码中通过取对数求和再指数还原的方式,高效地计算了连续4次转移的联合概率。
因子评价
首先,我们来看一下V4版本与V3版本因子的相关性。这里使用的是经过均值/标准差标准化后的因子收益率计算的相关性。
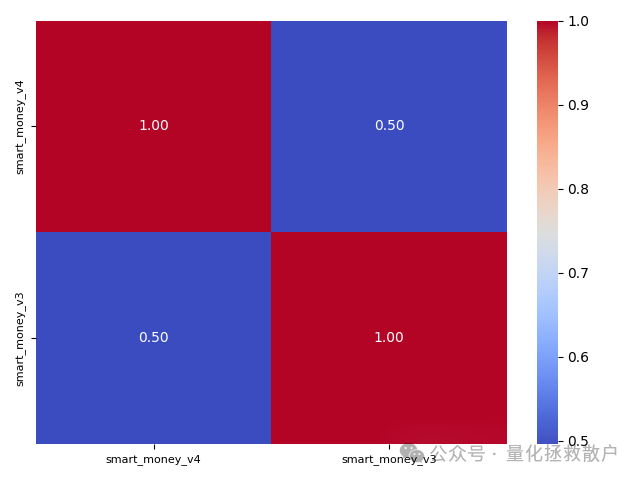
出乎意料的是,这两个因子的相关性约为0.5。按照一些业内的评价标准,低于0.5的相关性通常被认为差异性较好,意味着V4可能提供了与V3不同的信息。
01 IC分析
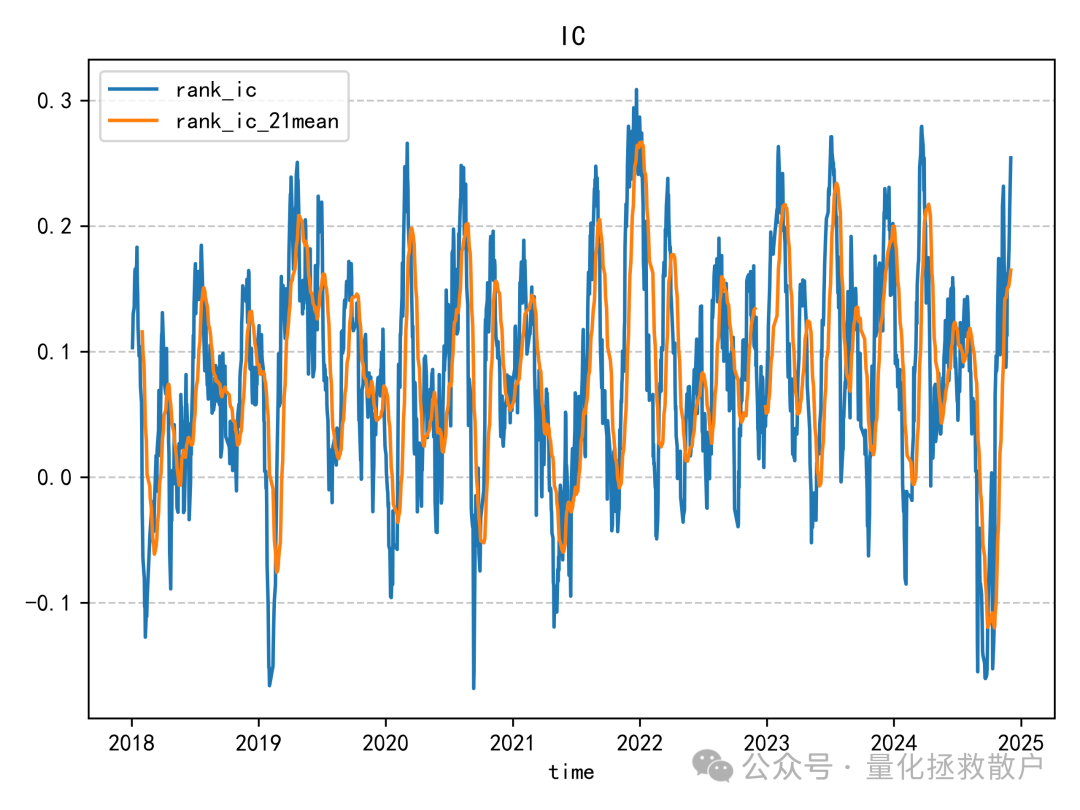
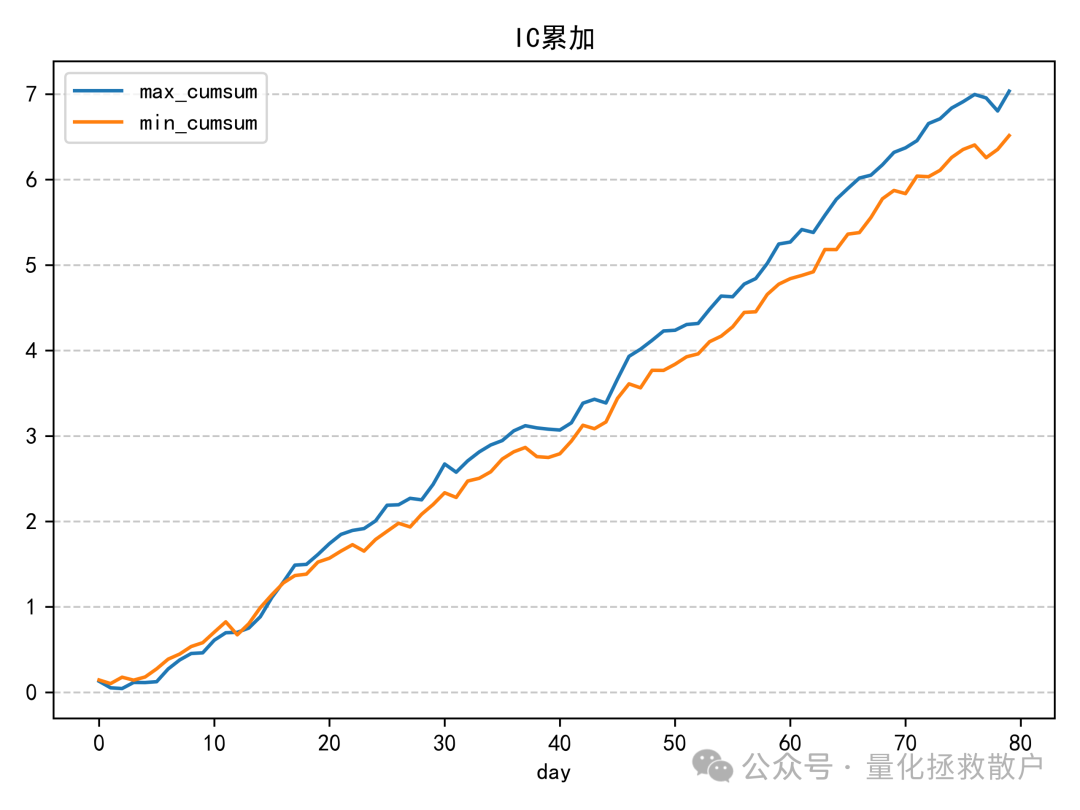
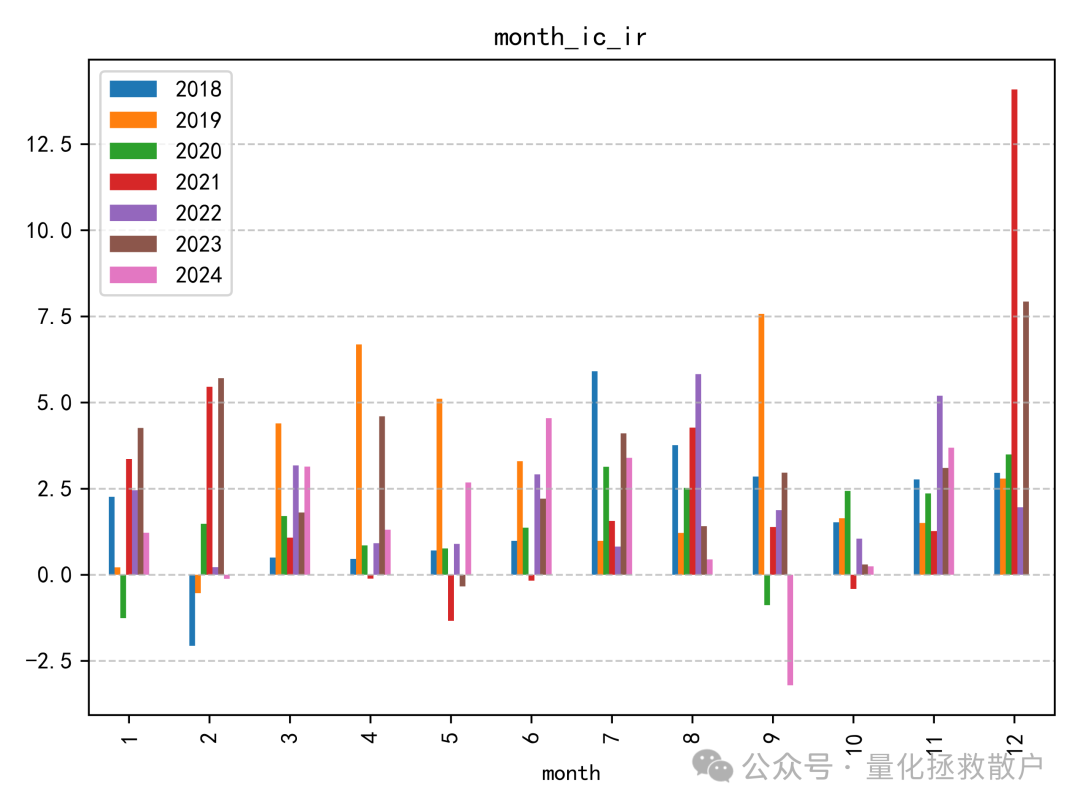
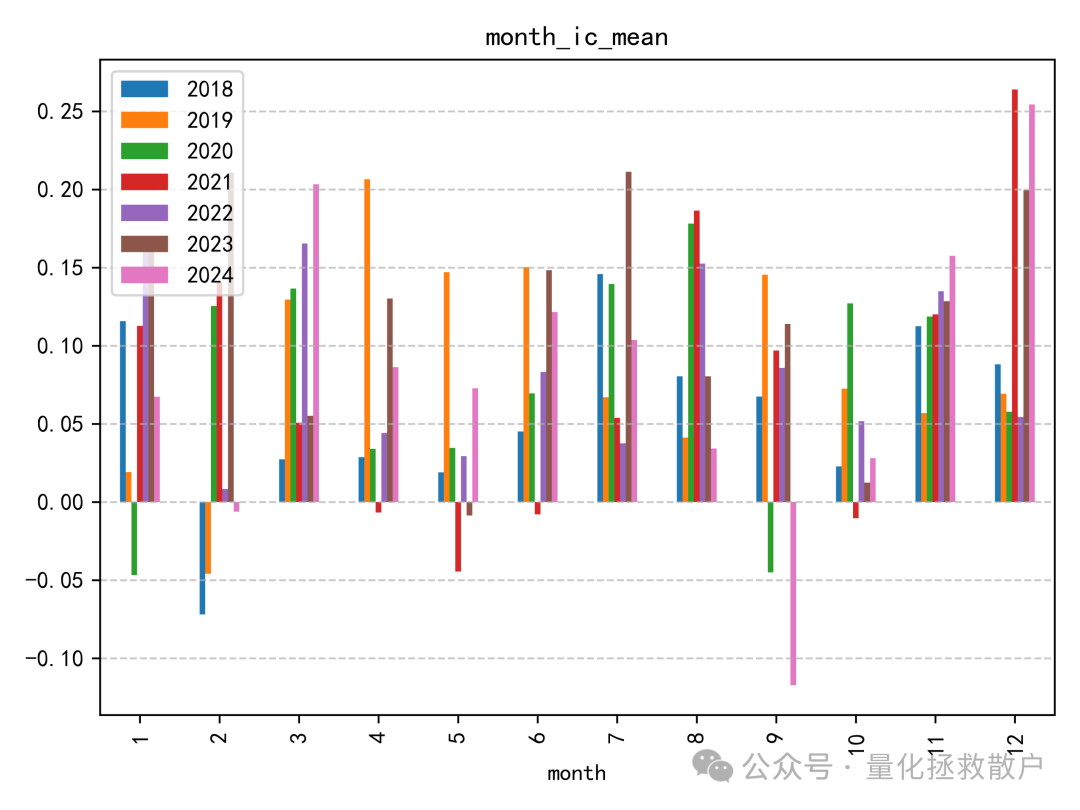
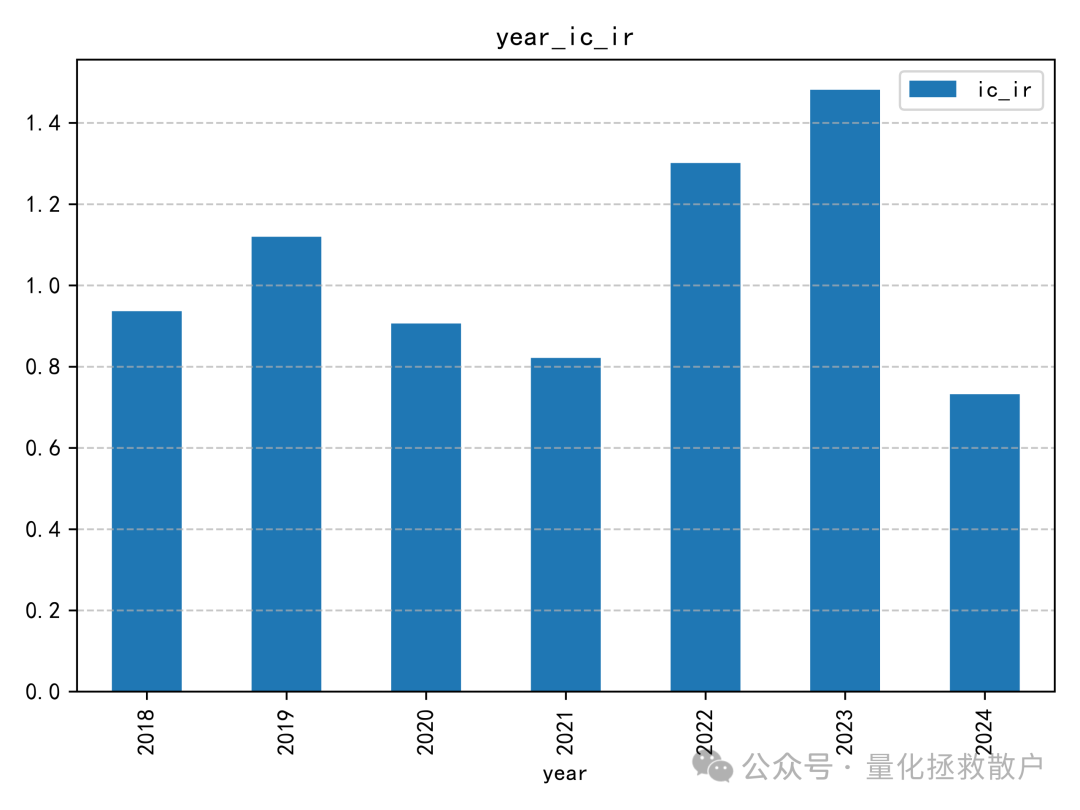
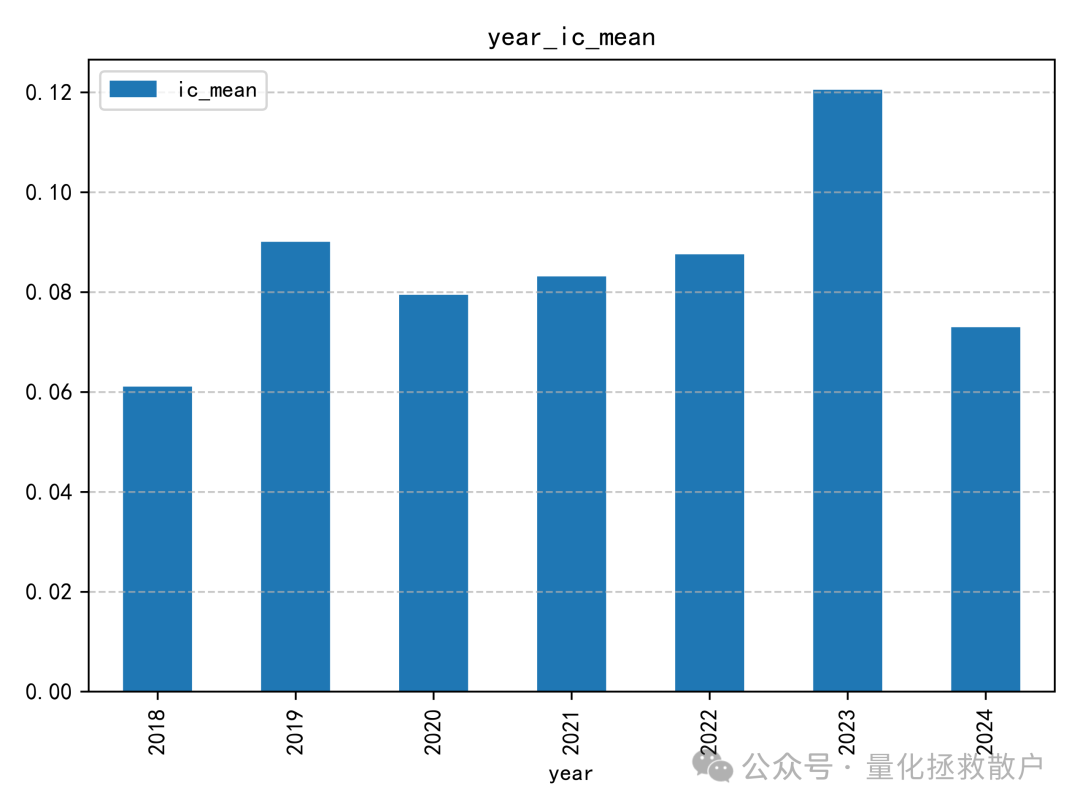
从IC(信息系数)相关的各项指标来看,V4版本的表现略逊于V3版本。
02 回归分析(因子收益率)
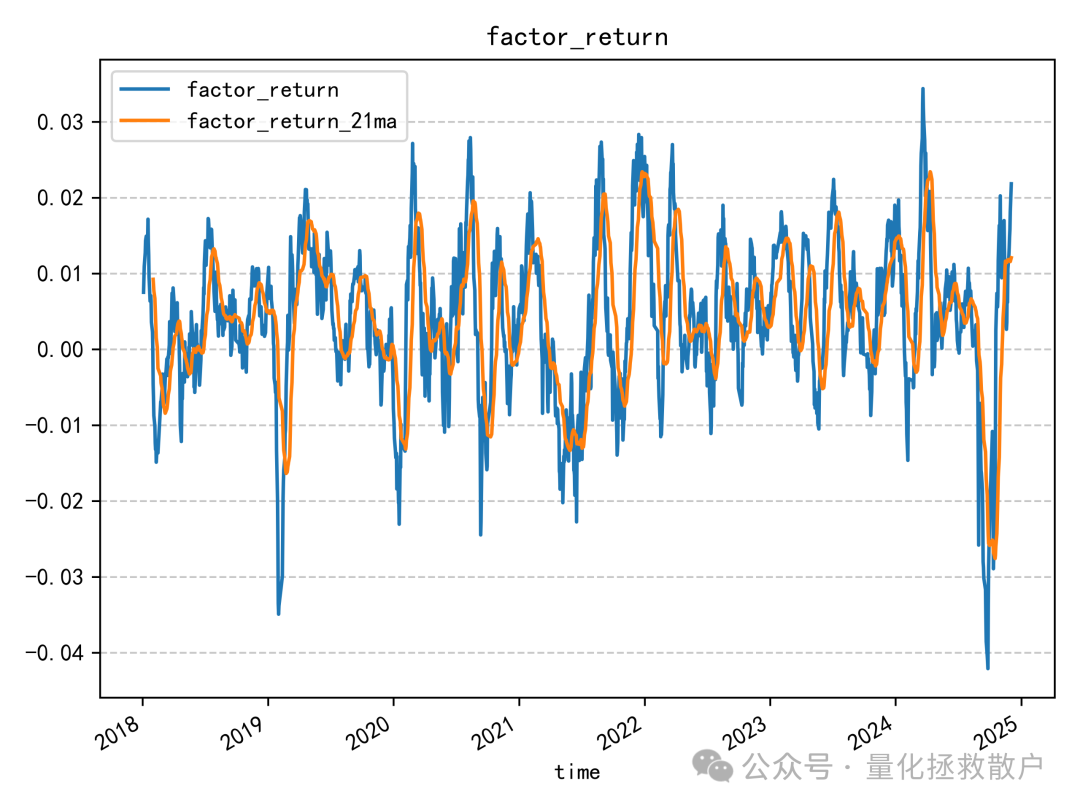
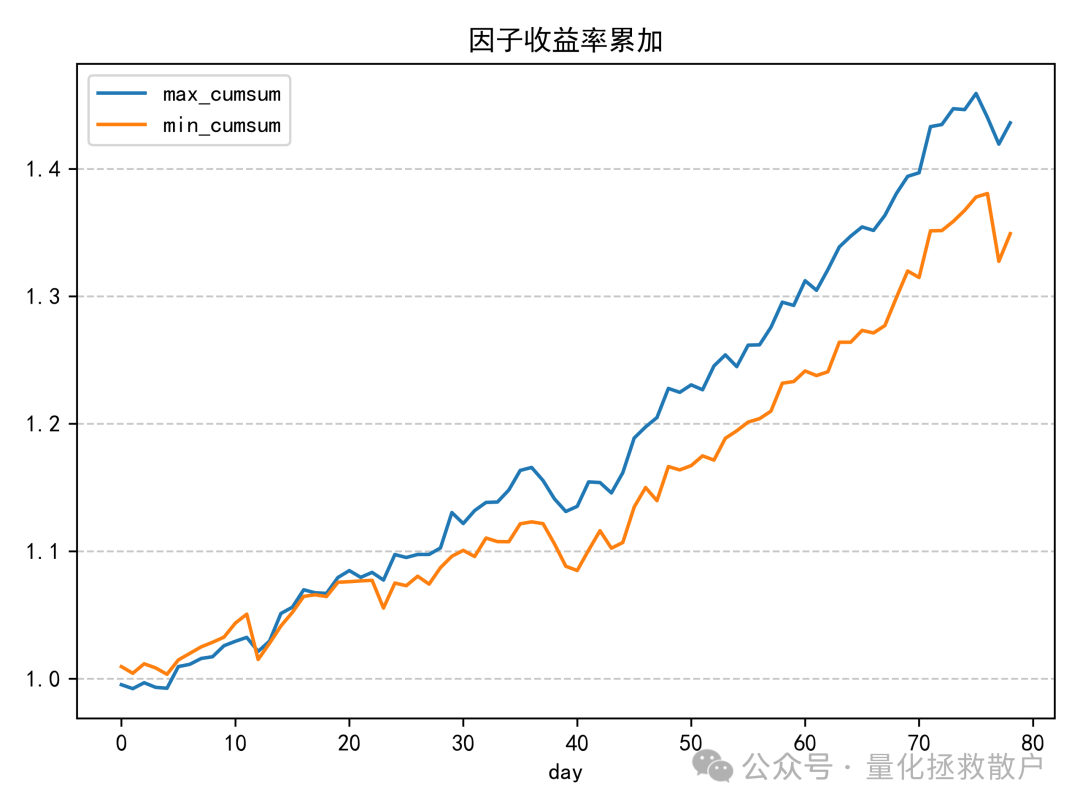
03 换手率分析
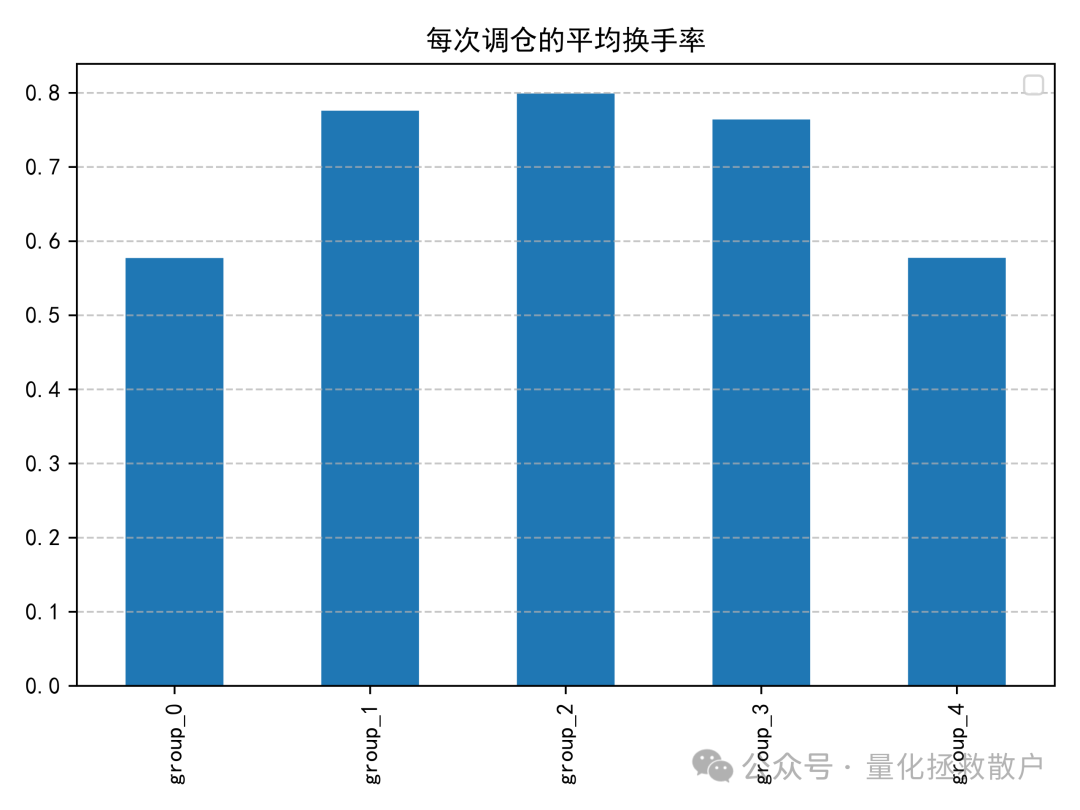
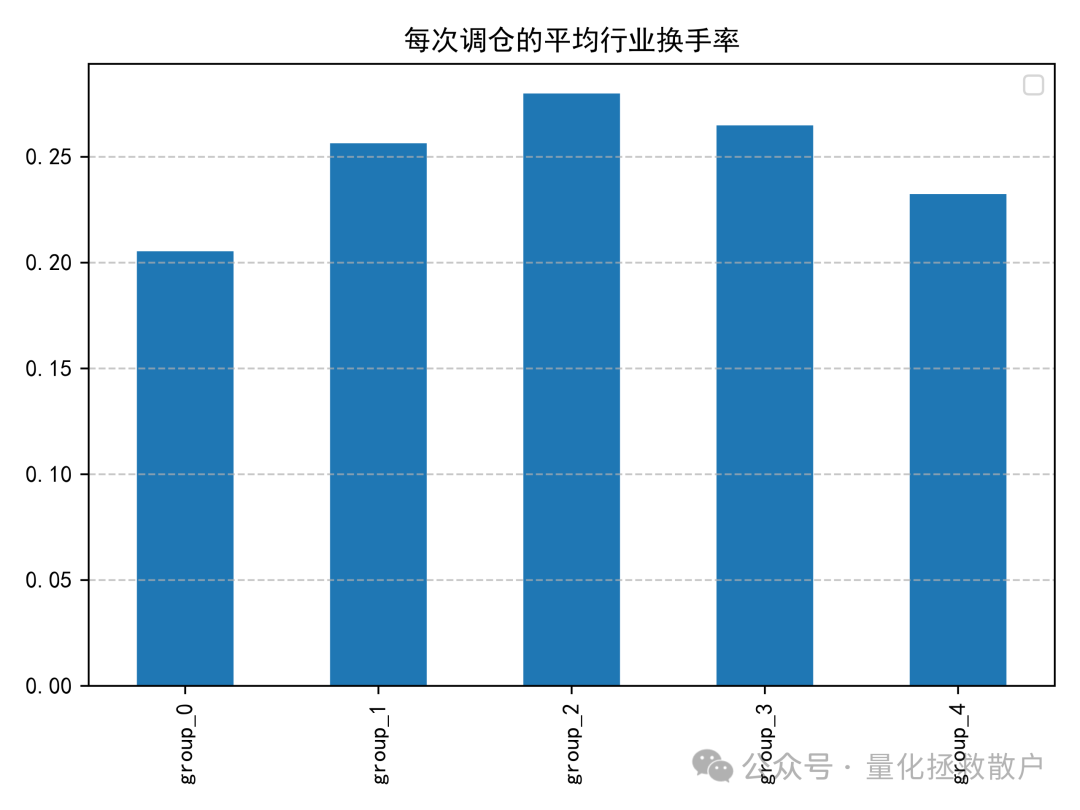
04 分层回测收益分析
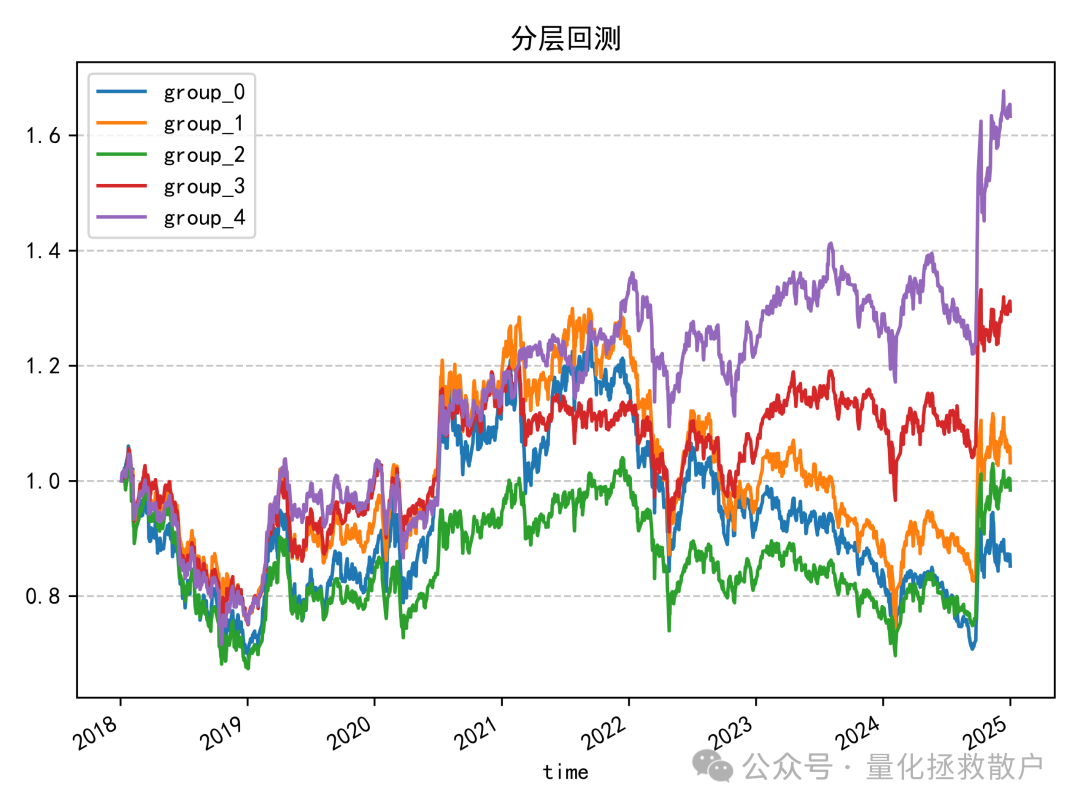
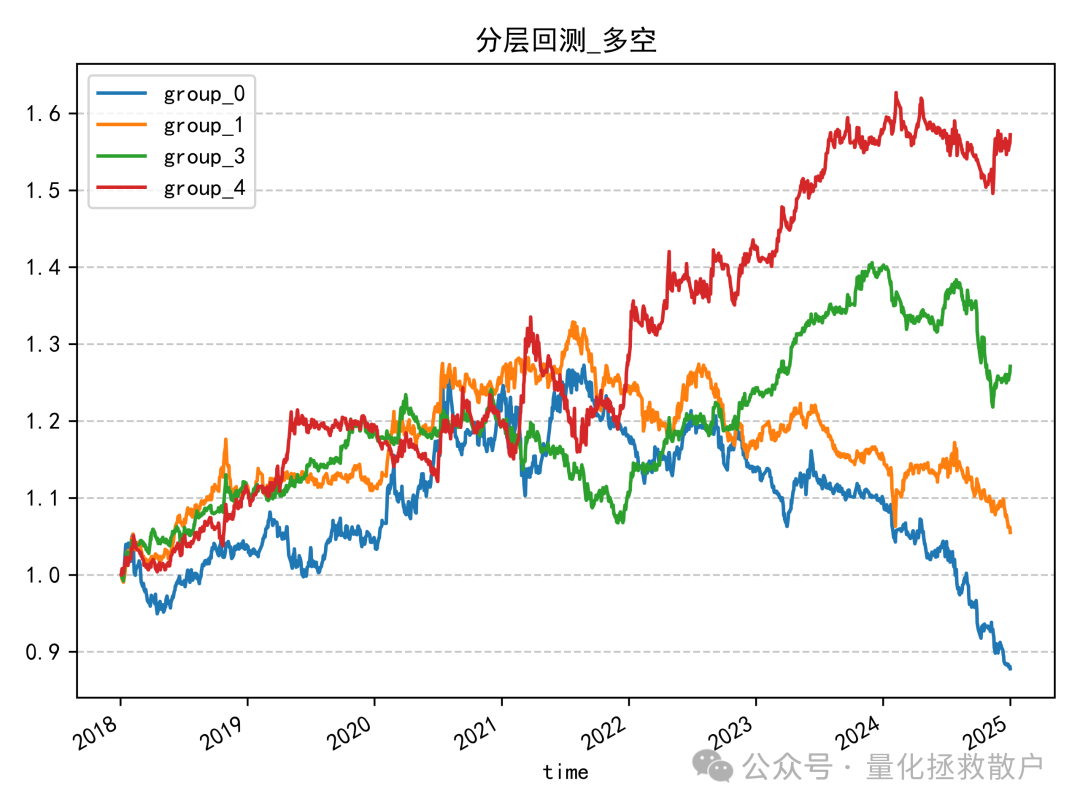
这是V4版本最大的亮点。 在V3版本的分层回测中,代表最高因子值组的紫色线(group_4)在2019年至2023年间,表现时有波动,并非始终领先。然而,在V4版本中,紫色线在同一时间段内的稳定性和领先优势更加明显,分层效果(各组别净值曲线的区分度)总体优于V3版本。
总结
基于马尔科夫链状态转移概率来识别异常交易时刻的聪明钱因子V4,与V3版本的相关性较低,提供了不同的信息维度。虽然在IC表现上不及V3,但其在分层回测中展现出了更优的区分度和稳定性,这对于实际构建量化交易策略而言是一个积极的信号。
一个有趣的思路是,尝试将V3和V4版本所识别的“异常时刻”取交集或进行其他方式的融合,也许能产生“lollapalooza效应”,获得一个更强大的合成因子。这或许是未来可以探索的方向。
关于量化投资与算法因子的更多深度讨论和实践分享,欢迎在云栈社区与大家交流。本次对聪明钱因子V4的介绍就到这里。
 发表于 2026-3-24 04:25:53
|
查看: 162|
回复: 0
发表于 2026-3-24 04:25:53
|
查看: 162|
回复: 0
