

日前,美国具身智能独角兽 Physical Intelligence(简称 PI,同 π)推出了一种新的强化学习方法:RL Token(简称 RLT)。这项技术利用视觉-语言-动作模型(VLA)引导在线强化学习,只需几小时甚至几分钟对模型进行微调,机器人就能高效完成多种精细操作任务,将最难环节的执行速度提升最高达3倍。

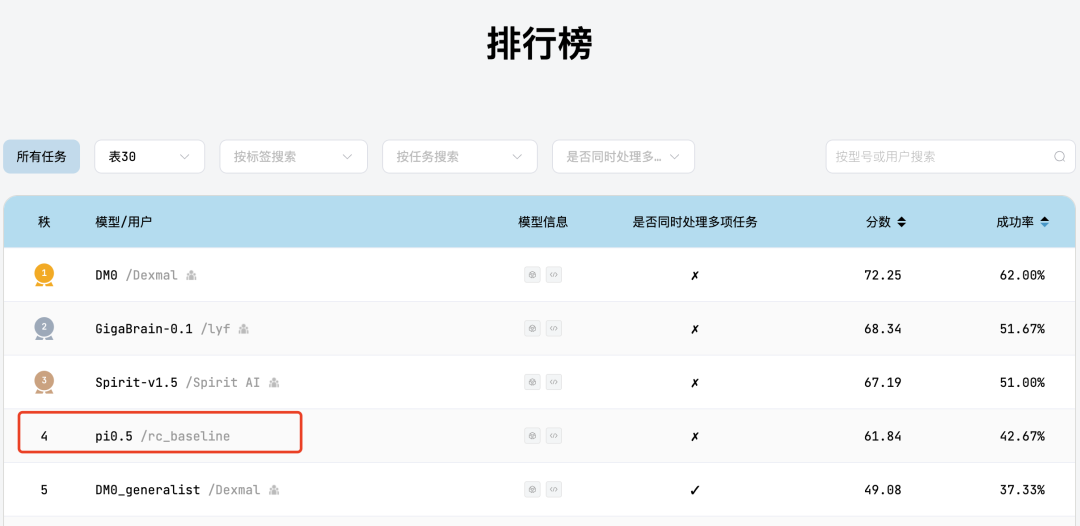
该公司开发的 pi0.5 具身模型曾得到业内广泛关注和借鉴,在权威真机评测基准 RoboChallenge 榜上一直名列前茅,其演示的机械臂叠衣服视频也在网络走红被其他厂商效仿。
进入2026年以来,RoboChallenge 排行榜前三已经易主,被中国厂商千寻智能的 Spirit v1.5 机器人基础模型、极佳视界的 GigaBrain-0.1 具身基础大模型以及原力灵机的 DM0 具身原生大模型占据,pi0.5 目前位列第四。
据了解,RL Token 的关键思想是将最新模型(pi0.6)的“内部表示”压缩成一个简洁的特征向量,该特征向量可以被一个非常小的策略网络(actor)与价值网络(critic)使用,使其能够在机器人执行任务的同时进行实时训练。
借助该技术,机器人可以学习非常精确的任务,在四项真实机器人毫米级/亚毫米级精度任务中,RLT可将任务中最难环节的执行速度提升最高3倍,并在数分钟到数小时的实践内大大提高任务成功率。

攻克“最后一毫米”难题
VLA模型 能够从数据中学习种类丰富的操作技能,但它们往往在执行的最后一毫米上表现不佳,尤其在精密任务的关键阶段,微小误差会不断累积,最终导致任务失败。
解决这一问题的自然思路是使用强化学习(RL)对VLA进行微调,但对VLA进行高样本效率的微调仍面临巨大挑战:
一方面,传统针对基础模型的RL训练方法依赖大规模数据,对快速在线自适应而言效率较低;
另一方面,数据高效的现实世界RL方法通常只训练规模小得多的模型,虽然能在数小时内完成优化,却牺牲了VLA的泛化能力。
如何在保留VLA泛化能力的同时,实现轻量级在线RL所具备的训练速度与样本效率?这成为PI团队的研究重点。
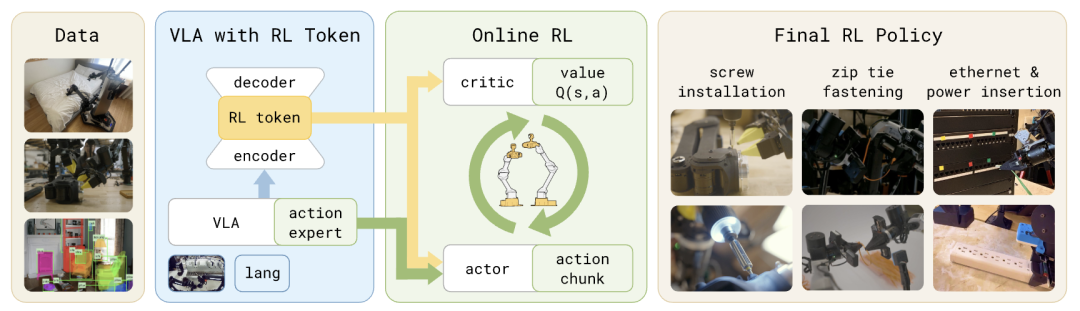
RLT的核心思路是对VLA进行改造,使其对外提供一个紧凑接口,用于实现高样本效率的在线RL。
基于RLT的深度学习实现了清晰的分工:被冻结的VLA提供广泛的感知理解与动作建议;轻量级的Actor与Critic网络则在线优化策略,使机器人能完成任务中最难的部分。
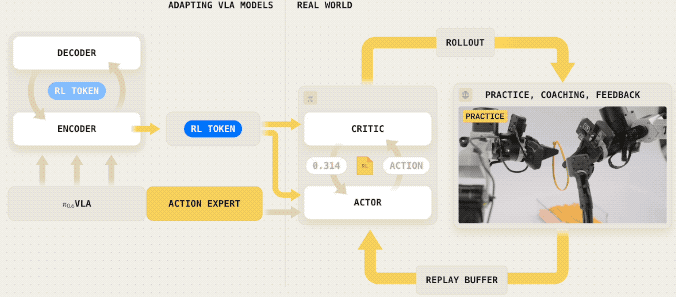
在整个流程中,训练VLA可输出一个RL Token——这是一种压缩表征,能让轻量级在线RL策略获取与任务相关的预训练知识,这样一来,在线RL是对已有良好行为的精细优化,而非从零开始学习。
由于策略与价值网络基于这种压缩表征运行,它们可以用小型网络实现,并直接在机器人上训练,每秒可完成数百次更新。
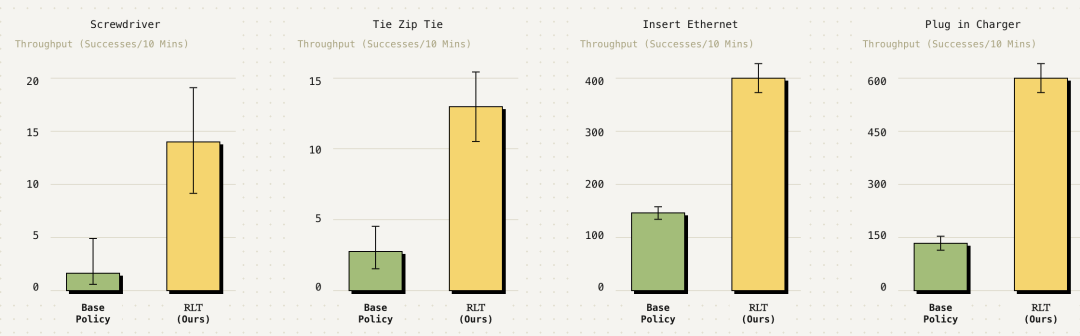
研究人员在四项毫米级/亚毫米级精度的高难度机器人操作任务上评估了RLT:螺丝安装、扎带紧固、网线插入、充电器插拔。

在这些任务中,RLT仅通过数小时的在线训练,就同时提升了成功率与执行速度,最大的提升出现在关键高精度阶段,RLT可将执行速度最高提升3倍,在难度较高的螺丝插入任务中,成功率从20%提升至65%。

在任务中最需要灵巧操作的环节,使用该方法训练的策略在保持可靠性的同时,速度甚至超过了人类专家遥操作。
这些结果表明,将VLA模型与轻量级在线RL相结合,无需大量任务专属工程优化,就能为高性能机器人操作提供一条切实可行的路径。
比基础VLA更高效的“涌现策略”
实验数据显示,RLT使得机器人只需15分钟的真实世界数据,就能改进每项行为中最难的部分,并且强化学习策略的一半试验速度都快于数据集中的任何远程操作演示。
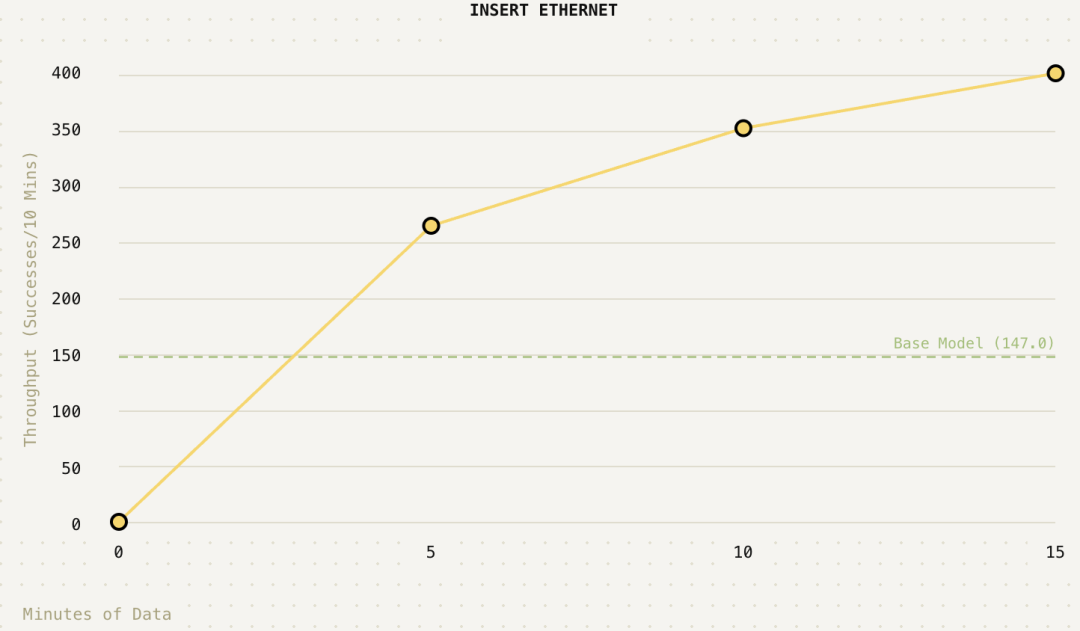
研究人员在论文中回答了几个行业普遍关心的问题:
1、在线强化学习是否优于基础VLA策略?
即使在充电器、以太网接口这类相对简单、基础策略已具备较高可靠性的任务中,RLT学到的策略在关键阶段的执行速度提升约3倍。在难度更高的扎带与螺丝刀任务中,成功率提升更为显著,螺丝刀任务成功率提升了40%,扎带任务成功率提升了60%。
2、RLT与业内其他方法相比表现如何?
HIL‑SERL与PLD均为单步在线强化学习方法,在这一包含数百步且奖励稀疏的任务上无法有效学习;对于相对简单的任务,DAgger与DSRL可达到与RLT相近的成功率,但在速度提升方面远不如RLT。RLT在保持基础策略高成功率的同时,将平均完成步数降低为原来的1/2。
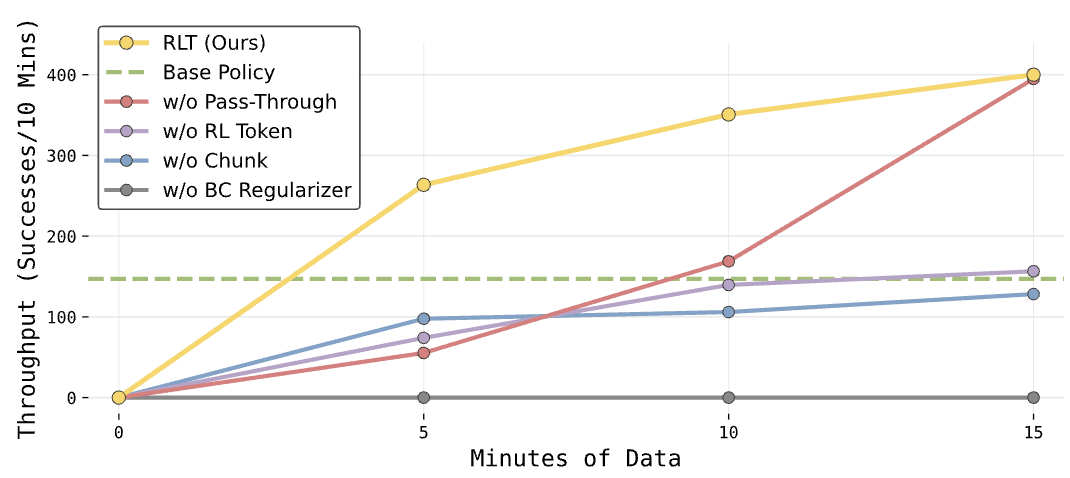
3、各个组件设计分别带来多大增益?
“RL Token、动作块、BC正则化器、参考动作直通”这四种设计均起到了重要作用:用ResNet‑10编码器替换RL Token会使吞吐量下降50%;将动作块替换为单步动作,无法稳定达到基础策略的性能;移除BC正则化器会造成最大的单次性能下降;移除参考动作直通会减慢学习速度,导致早期探索漂移,偶尔还会出现退化行为。
4、RLT是否能产生更高效的涌现策略?
除了量化指标外,在线强化学习还让机器人的任务执行方式发生了质的提升。
基础VLA策略在接近接触时常常表现出试探行为:靠近目标、小幅回退、重新调整、再次尝试,有时要反复多次才能成功。而RLT则是直接靠近接口,以流畅连贯的动作完成插头插入。
即便首次尝试失败,RLT也会施加压力并轻微摆动插头,利用柔顺性完成插入,从而更快成功。这种行为并未出现在演示数据中,完全来自在线探索的涌现行为,表明该方法能够超越对人类策略的简单模仿。
迈向新一代机器人系统
尽管RLT实现了快速高效的学习,但在训练过程中仍需要额外的人工干预,以提供奖励信号、修正干预,并在(关键阶段的)强化学习与(其他阶段的)基础策略之间进行切换。
理论上,这些组件中的一部分可以实现自动化,例如通过奖励模型与进程预测。因此,基于RLT构建一套完全自主的强化学习优化流程,是未来工作中一个极具前景的方向。
该公司在去年11月份推出了能从经验中学习的VLA模型pi0.6。2026年3月初,该公司还开发了一种名为多尺度具身记忆(MEM)的方法,可为模型提供记忆功能,使机器人能够执行诸如彻底清洁厨房或从零开始制作烤奶酪三明治等超长任务。

研究人员认为RLT是迈向新一代机器人系统的重要一步:
未来机器人不仅能从演示数据中学习,还能在实际执行任务的过程中直接自我优化。当这种优化过程快速且可靠时,VLA的预训练阶段只需为下游探索提供一个良好的初始化即可,而最优、最高效的策略,完全可以通过强化学习自主发现。
而一旦模型能够直接从经验中完成所有抽象层级的学习,机器人就会在执行现实世界任务的过程中不断变得更强大。
拓展阅读:
对人工智能前沿技术、机器人学习框架及更多开源项目实践感兴趣?欢迎访问云栈社区,与全球开发者一起探讨具身智能的未来。
 发表于 2026-3-24 07:41:06
|
查看: 166|
回复: 0
发表于 2026-3-24 07:41:06
|
查看: 166|
回复: 0
