2023年,生成式AI掀起编程革命;2025年,Agent时代正式开启。在这场浪潮中,DataWorks完成了从“AI辅助驾驶”到“AI自动驾驶”的跨越式升级,推动大数据开发治理迈入“需求即代码”的全新阶段。通过构建专业的工具适配层、实施多维度上下文工程、坚守安全红线,DataWorks正在打造一个专业、可信、开放的Agent生态系统。
平台根基:十年深耕的大数据治理平台
作为一站式智能化大数据研发与治理平台,DataWorks与阿里云ODPS(MaxCompute)同生共长,历经十年深耕,已成为其原生的数据开发与治理体系核心。这一深厚的技术积累,为AI能力的深度集成提供了坚实底座。
权威认证印证了其领先地位:
- IDC 2024 中国大数据平台市场份额、数据治理市场份额均位列阿里云第一
- 入选 IDC MarketScape《面向生成式AI的数据基础设施》报告领导者象限
- 通过中国信通院大数据产品能力评估“先进级(3级)”认证
这些成就,标志着DataWorks不仅是工具平台,更是企业级数据智能转型的关键支撑。

Copilot时代:AI辅助驾驶的效率革命
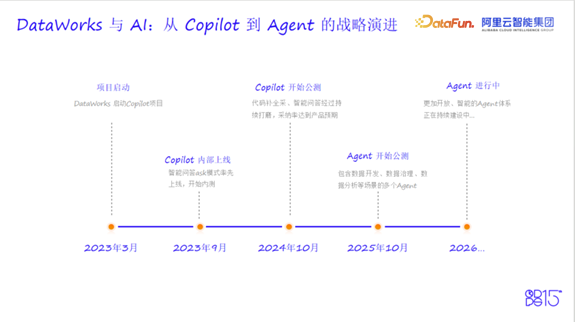
2023年是AI编程界的分水岭。GPT-4问世,GitHub Copilot引爆整个编程圈。DataWorks团队敏锐捕捉到这一趋势,于2023年3月启动Copilot项目,9月开始内部内测,经过严格的邀测机制,在2024年10月正式开始公测,推出代码补全、智能问答等系列功能。
不同于通用型编程助手,DataWorks Copilot专注大数据领域,聚焦SQL场景。它深度集成于SQL编辑器,成为开发者的“智能结对伙伴”:在恰当节点主动推荐一行或多行代码,开发者只需按下Tab键即可采纳。
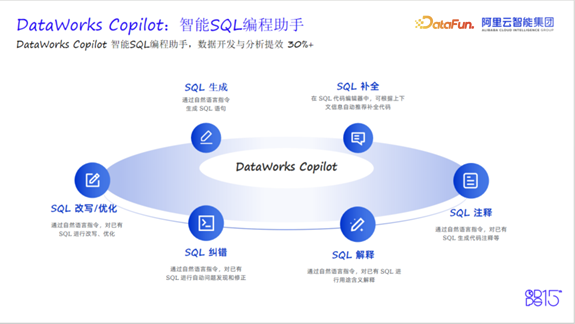
Copilot的核心能力包括SQL生成、补全、改写优化、纠错、解释和注释六大功能。 得益于多维度主动上下文感知能力和丰富的算法工程实现,DataWorks Copilot获得了Spider2.0榜单第一的NL2SQL技术认可,展现出强大的自然语言理解与代码生成能力。
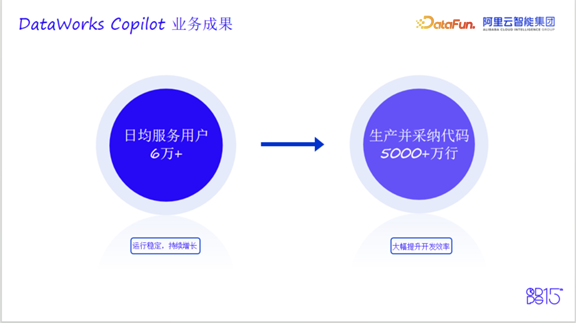
目前,平台日均服务用户超过6万,历史累计生成并被采纳的代码行数超过5000万行,数据开发与分析效率提升超过30%。
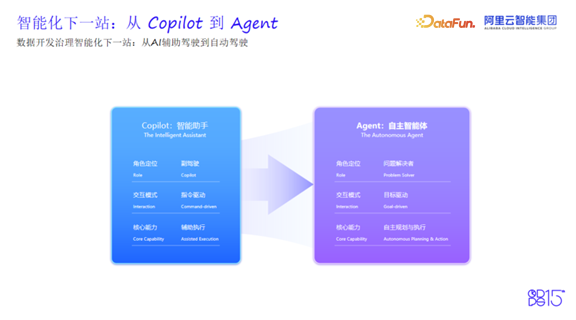
此时的AI,仍处于“人主导、AI辅助”的Copilot模式——高效,但尚未自主。
Agent时代:从辅助到自主的质变
随着AI技术的快速演进,“Web Coding”成为主流,传统的“人找工具、一问一答”的交互方式显得低效繁琐。用户期待的是基于自然语言输入,由AI自动驱动完成整个任务的简单高效模式。
2025年,当Agent成为技术新范式时,DataWorks顺势而上,于同年10月启动Agent系列公测,实现从“指令驱动”到“目标驱动”、从“辅助执行”到“自主规划+执行”的质变。
用一个生动的比喻概括这一转变:“从AI辅助驾驶升级到AI自动驾驶。”用户只需一次自然语言输入需求,AI就能自主规划与执行,完成整个需求开发。
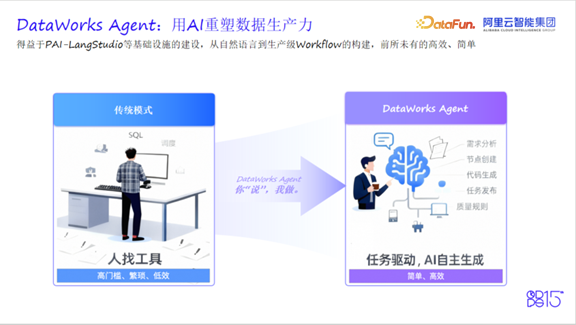
真实场景:自动构建商品销售分析工作流
传统模式下,主播若想深入分析商品销售趋势,需具备多项专业技能:
- 掌握SQL编写与数仓分层逻辑
- 构建Workflow并配置调度
- 在MaxCompute、Hologres、StarRocks、Spark等多个引擎间频繁切换
- 协调多方协作,流程繁琐低效
而在Agent模式下,用户仅需提供一段自然语言描述或上传需求文档。随后,Agent将基于内置工具集和上下文感知能力,自主完成以下动作:
- 解析需求意图
- 规划数据链路与任务依赖
- 自动生成代码与工作流
- 完成调试、调度配置与发布准备
用户仅需在关键节点确认授权,最终即可获得一个可上线运行的生产级工作流。
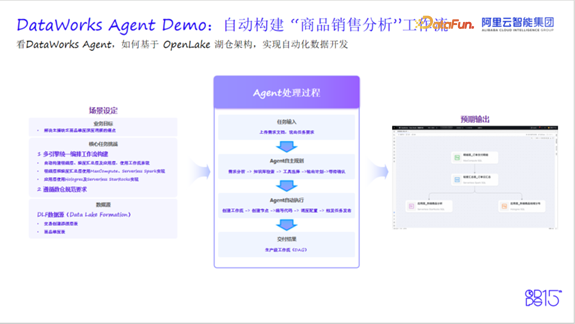
整个过程透明可控,大幅降低使用门槛,让非技术人员也能参与复杂数据分析。
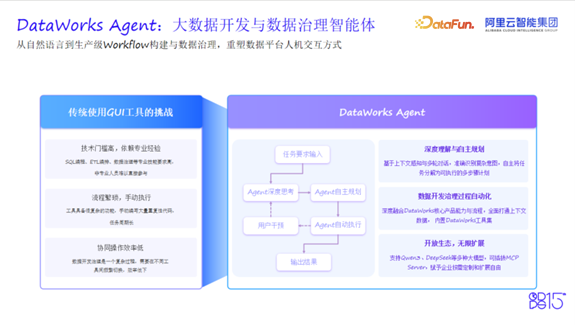
技术基石:构建专业、可信、开放的Agent生态
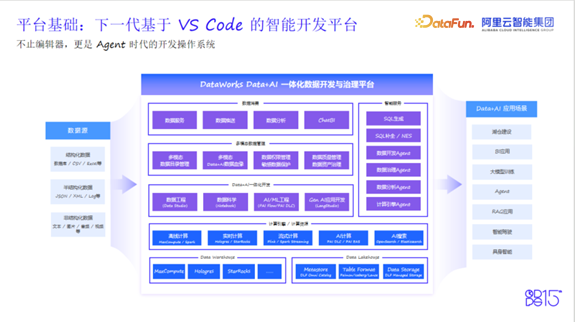
1. 平台基础:VS Code操作系统
DataWorks选择VS Code作为下一代智能研发平台的核心载体,不仅因其是业界最流行的代码编辑器,更因为它已演变为AI时代的操作系统。
其优势体现在:
- 支持Notebooks、Python开发,满足算法工程师多样化需求
- 拥有丰富的企业级插件生态,支持在线/离线多种开发模式
- 深度对接PAI等AI平台,打通模型训练与数据处理链路
- 兼容多种数据源:MaxCompute、Hologres、Paimon等
- 被Cursor、GitHub Copilot、Zed等顶级AI编程产品共同选择,形成行业共识
在VS Code之上,DataWorks构建了一个面向未来的智能开发环境。
2. 工具适配层:让AI理解复杂系统
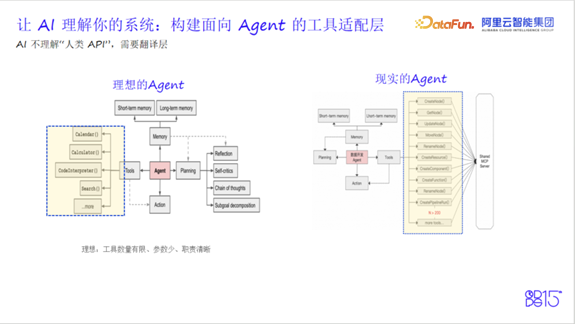
如何让大模型理解和操作一个拥有数千API的企业级平台?这是Agent落地的最大挑战。
直接暴露原始OpenAPI给AI效果不佳,原因有三:
- 工具数量过多,超出模型上下文承载能力
- 参数设计面向人类开发者,层级深、结构复杂(部分API达5层嵌套、30+字段)
- 概念歧义,同一功能存在多种调用路径
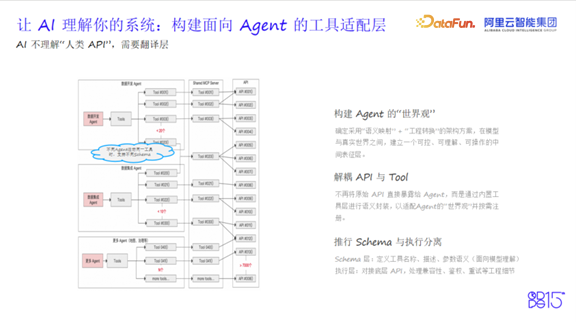
为此,DataWorks构建了面向Agent的工具适配层,采用“语义映射 + 工程转换”架构:
核心设计思想:
- 解耦API与Tool:不再将底层API直接暴露给Agent
- Schema与执行分离:
- Schema层:定义简洁、语义清晰的工具接口(名称、参数含义),供模型理解
- 执行层:负责对接真实API,处理鉴权、兼容性、异常等工程细节
- 统一MCP Server接入机制:支持标准化协议调用,提升扩展性
该架构实现了“多Agent共享一套执行后端,各自拥有定制化语义接口”的灵活模式,显著提升了Agent调用效率与成功率。
3. 上下文工程:让Agent真正“看见”世界
为了让AI能主动帮助用户做事,DataWorks进行了丰富的上下文工程。系统会主动采集6种环境信息:环境(VS Code for Web)、用户信息、工作空间、引擎语言、时间和系统规则。用户也可按需上报7种信息:代码上下文(当前编辑和最近打开的文件)、数据上下文(表信息、数据专辑)、文档上下文(本地或远程文档)、业务规则等。
基于这些上下文工程优化,DataWorks Agent首个Token返回时间平均在1.5秒以内,即使在多轮对话达到80轮时,响应时间依然保持恒定。这种多维度的上下文感知能力,让Agent能够准确理解用户意图,生成更精准的代码。

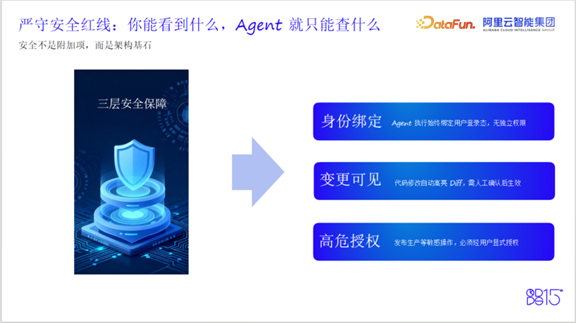
4. 安全红线:Human in the Loop
作为大数据平台,数据安全是DataWorks不可逾越的红线。很多用户关心权限问题:会不会出现越权?DataWorks在开发Agent过程中没有独立构建一套权限体系,而是严格绑定当前用户登录态——用户能看见什么,Agent就只能看见什么,有效避免了越权风险。
对于生产业务代码的变更,每次变更都会生成高亮Diff,需要人工确认(可全部确认或逐条确认)后才会对线上代码生效,实现了“Human in the Loop”的设计思想。对于发布生产等高危操作,必须严格要求每次人工授权。Agent可以帮助唤起发布页面,但最后的发布按钮必须由用户自己点击。
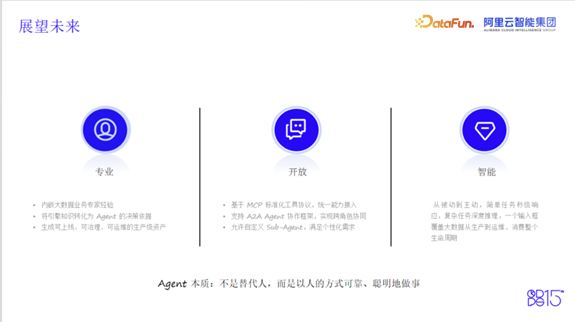
展望未来:专业、开放、智能的大数据研发平台
强调,Agent的本质不是简单地替代人,而是以人的方式可靠、聪明地协助大家做事。DataWorks的努力目标是构建一个专业、开放、智能的大数据研发平台:
- 专业层面,内嵌大数据业务专家经验,将引擎知识转化为Agent的决策依据,生成可上线、可治理、可运维的生产级资产。
- 开放层面,基于MCP标准化工具协议统一能力接入,支持A2A Agent协作框架实现跨角色协同,允许自定义Sub-Agent满足个性化需求。
- 智能层面,从被动到主动,简单任务秒级响应,复杂任务深度推理,一个输入框覆盖大数据从生产到运维、消费的整个生命周期。
DataWorks的目标是将专业的业务知识转化为可执行的策略,同时保持开放,将用户已有的AI或工程化能力融合进来,确保AI在可控范围内智能自主地完成用户需求,让用户有更多时间沉浸在自己的业务之中。
总结
从Copilot到Agent,DataWorks完成了从提效工具到自主智能体的进化。这一转变不仅是技术层面的升级,更是交互范式的革新——从“人找工具”到“工具找人”,从“指令驱动”到“目标驱动”。通过构建面向Agent的工具适配层、实施丰富的上下文工程、严守安全红线,DataWorks为大数据开发治理领域树立了AI应用落地的标杆。
未来,随着Agent生态的不断完善,“需求即代码”的开发体验将让数据开发变得前所未有的简单高效。更多关于AI与大数据的实践与讨论,欢迎访问云栈社区进行交流。
 发表于 2026-3-25 02:40:38
|
查看: 180|
回复: 0
发表于 2026-3-25 02:40:38
|
查看: 180|
回复: 0
