你一定遇到过这样的场景。
大促刚开始30秒,运营在群里发消息:“商品详情页显示的库存数和实际不一致,用户投诉进来了。”你查了数据库,库存是对的;查了缓存,缓存是错的。重新刷一下缓存,好了。但过了几分钟,又有别的商品出问题了。
你很快定位到原因:并发读写导致缓存里残留了一条脏数据。
在日常流量下,这种问题可能一个月才出现一次,加个TTL兜底就行。但当流量从百万QPS冲到千万QPS,你会发现,缓存不一致不再是偶发事件,而是一种统计学上的必然。
这篇文章,我们来聊聊缓存一致性问题中最核心、也最容易被低估的那个维度:读写时序。
缓存不一致的根因到底是什么?
很多人把缓存不一致归因于“缓存和数据库是两个系统,没有事务保证”。这个说法没错,但太笼统了,笼统到无法指导实践。
我们换一个更精确的视角来理解这个问题。
缓存不一致的根因,是并发场景下读操作和写操作的执行时序失控。
什么意思?我们用最经典的Cache Aside模式来拆解。
Cache Aside的标准流程是:
- 读路径:先读缓存,命中则返回;未命中则读数据库,再回填缓存
- 写路径:先更新数据库,再删除缓存
看起来很简洁,似乎没什么问题。但当读请求和写请求在时间线上交织执行时,破绽就出现了。
来看一个经典的竞态条件:
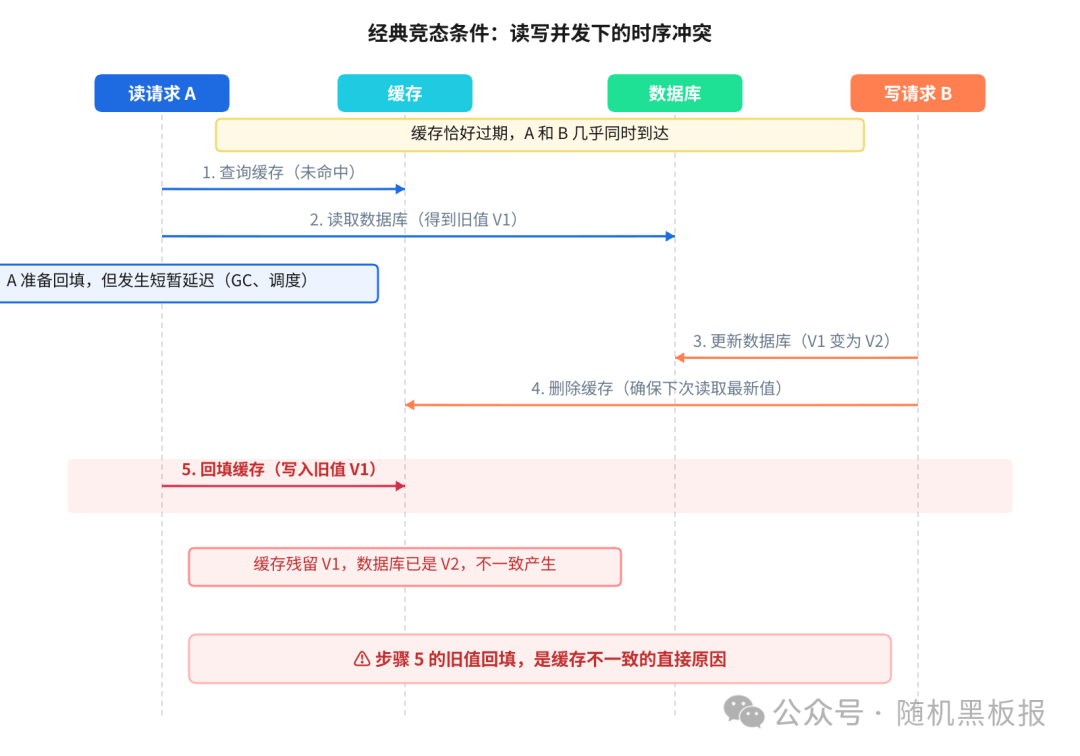
问题出在步骤5。读请求A拿着旧值回填缓存时,写请求B已经完成了数据库更新和缓存删除。A的回填操作等于“把脏数据又写回去了”。
这个竞态窗口有多大?大概是读请求从数据库拿到数据到回填缓存之间的那段时间,通常在毫秒级别。在低并发下,读写恰好撞进这个窗口的概率极低。但是,并发量放大10倍,碰撞概率不是线性增长,而是指数级增长。
规模放大后,时序问题为什么会急剧恶化?
我们来算一笔账。
假设某个热点Key的读QPS是10000,写QPS是100,竞态窗口是5ms。在一秒内,这个Key被读取10000次,被写入100次。每次写入都会打开一个5ms的竞态窗口,那么一秒内竞态窗口的“累计开放时间”是100 × 5ms = 500ms,也就是说,这一秒内有将近一半的时间处于可能产生不一致的危险区。

但数字只是问题的一部分。规模放大后,还有几个因素会让时序问题雪上加霜。
缓存集群多副本带来的写入放大
在千万QPS场景下,缓存通常不是单节点,而是多副本部署。一次写操作要删除多个副本上的缓存,这些删除操作本身也有先后顺序。如果副本A删除完毕但副本B还没删,恰好有读请求打到副本B,又会引入新的不一致。
数据库主从延迟叠加了不确定性
读请求如果走的是从库,而从库的复制延迟是10ms到50ms,那么即使缓存被正确删除了,读请求从从库拿到的仍然可能是旧数据,然后把旧数据回填到缓存里。主从延迟和缓存竞态叠加在一起,不一致的窗口被成倍拉长。
网络抖动和GC停顿变成了常态
在百万QPS量级,偶尔一次网络抖动或GC停顿,可能只影响到几个请求。但在千万QPS量级,每一毫秒都有数千个请求在飞,一次20ms的GC停顿,就可能让几万个请求的时序发生错乱。
下面这张图概括了规模放大后的恶化路径:
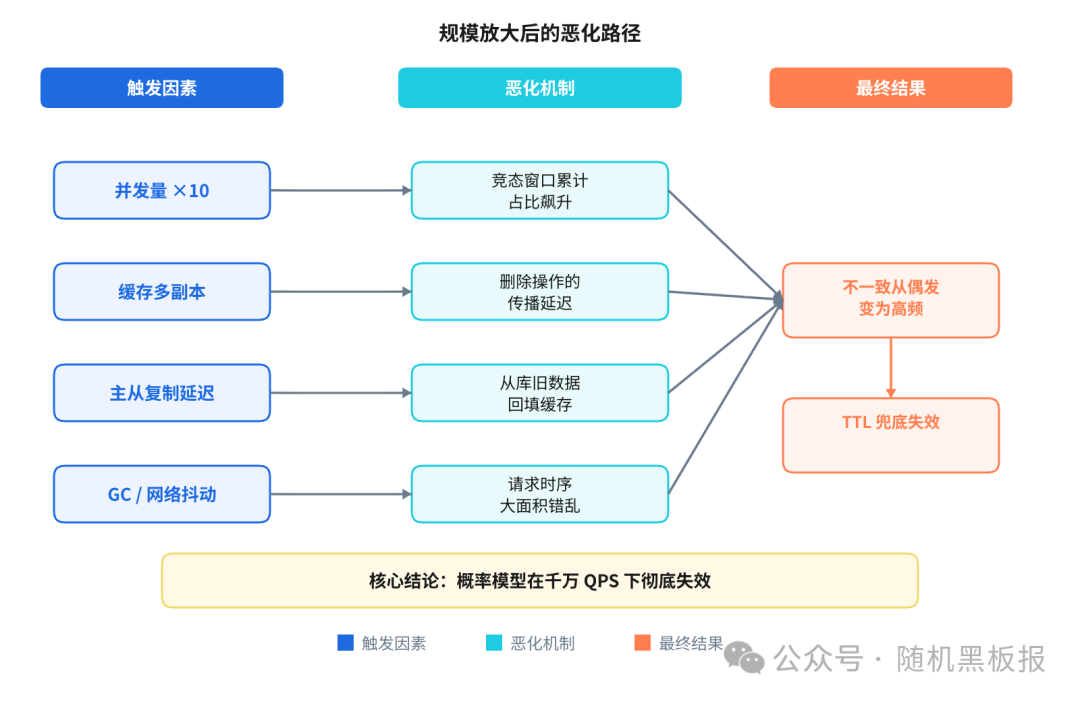
所以问题的本质很清楚了:在千万QPS下,靠概率“赌”时序不会冲突,这条路走不通了。我们必须从架构层面,把读写时序从“随机碰撞”变成“有序执行”。
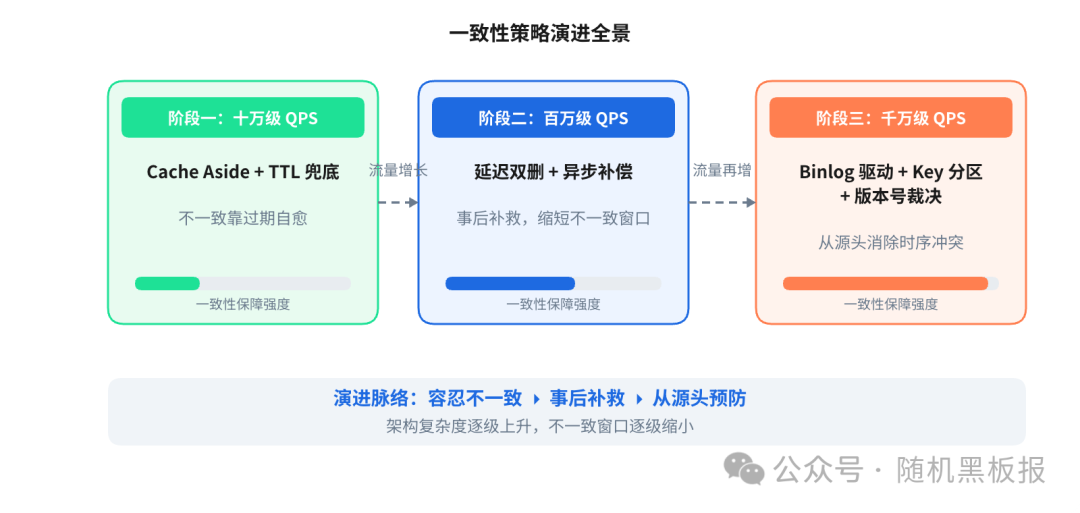
从十万到千万:一致性策略的演进路线
解决时序问题的思路,本质上就是一句话:既然控制不了并发的执行顺序,那就用机制来消除乱序带来的影响。
但不同规模下,需要的机制复杂度完全不同。我们按演进阶段来看。
阶段一:Cache Aside + TTL 兜底(十万级 QPS)
这是最基础的方案。写操作更新数据库后删除缓存,读操作未命中时回填。给缓存设置一个合理的TTL(比如30秒到几分钟),即使出现了不一致,也能在TTL过期后自动修复。
这个方案足够简单,在十万级QPS下表现良好。竞态窗口小、碰撞概率低,TTL是一个低成本但有效的安全网。
但它有一个本质局限:TTL的长短是一致性和命中率之间的博弈。TTL设短了,缓存频繁失效,命中率下降,数据库压力增大;TTL设长了,不一致的持续时间也长。在流量不大的时候,这个博弈空间比较宽裕。流量一旦上来,两头都紧。
阶段二:延迟双删 + 异步补偿(百万级 QPS)
当流量进入百万级,单纯依赖TTL兜底已经不够了。不一致事件的频率在上升,而且业务对数据新鲜度的要求往往也更高(比如库存、价格这类敏感数据)。
延迟双删是一个被广泛使用的改进方案。核心思路是:写操作除了在更新数据库后立即删除缓存,还要在一段延迟之后再删除一次。
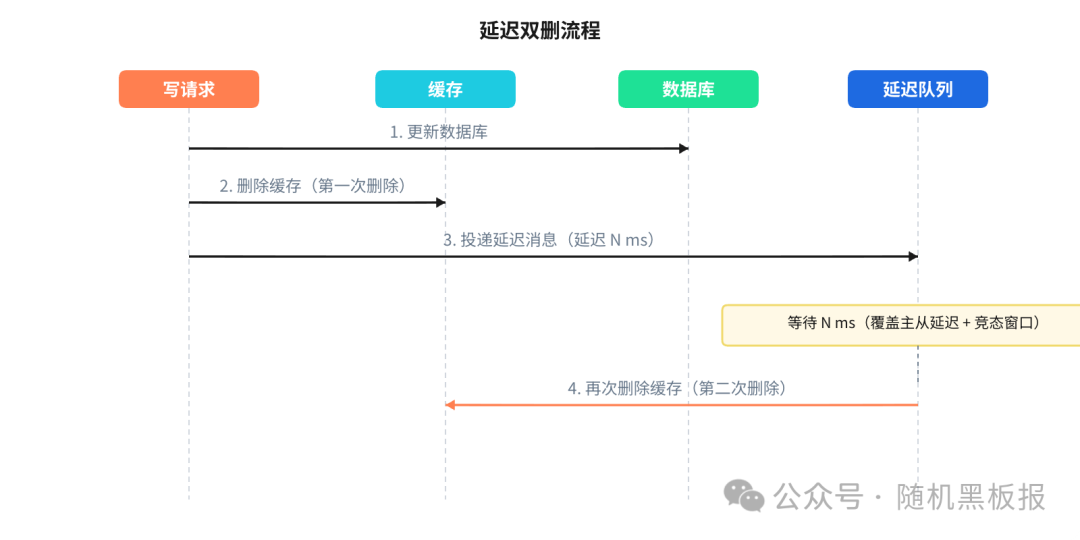
第二次删除的目的是“扫尾”:清理掉在第一次删除之后、因为竞态条件被回填进来的脏数据。延迟的时间通常设置为“主从复制延迟 + 一个安全余量”,一般在几百毫秒到一两秒之间。
这个方案能大幅降低不一致的持续时间,但它仍然有局限性。
首先,延迟时间很难精确设定。设短了可能还没覆盖住竞态窗口,设长了又白白多出一段不一致时间。其次,它依然是一种“事后补救”思路:先允许不一致发生,再尽快修复。在百万QPS下,这已经足够好了。但到了千万QPS,“事后补救”的速度赶不上“制造问题”的速度。
阶段三:基于 Binlog 的有序失效(千万级 QPS)
到了千万级QPS,我们需要转换思路。
前面两个阶段的方案,都有一个共同的隐含假设:由业务代码来负责删除缓存。但业务代码运行在分布式环境中,天然就是多线程、多进程、多实例并发执行的。让这些并发的业务代码去协调缓存删除的顺序,就好比让几千人同时往一块黑板上写字,还要求他们写出来的字不互相覆盖。
换一个思路:不让业务代码删缓存,让数据库的变更日志来驱动缓存更新。
MySQL 的 Binlog(或其他数据库的WAL / Change Stream)天然就是有序的。每一条数据变更都有一个全局递增的位点,这个位点定义了变更的先后顺序。如果我们订阅 Binlog,按照 Binlog 的顺序来处理缓存失效,那么时序问题就从根本上被解决了。
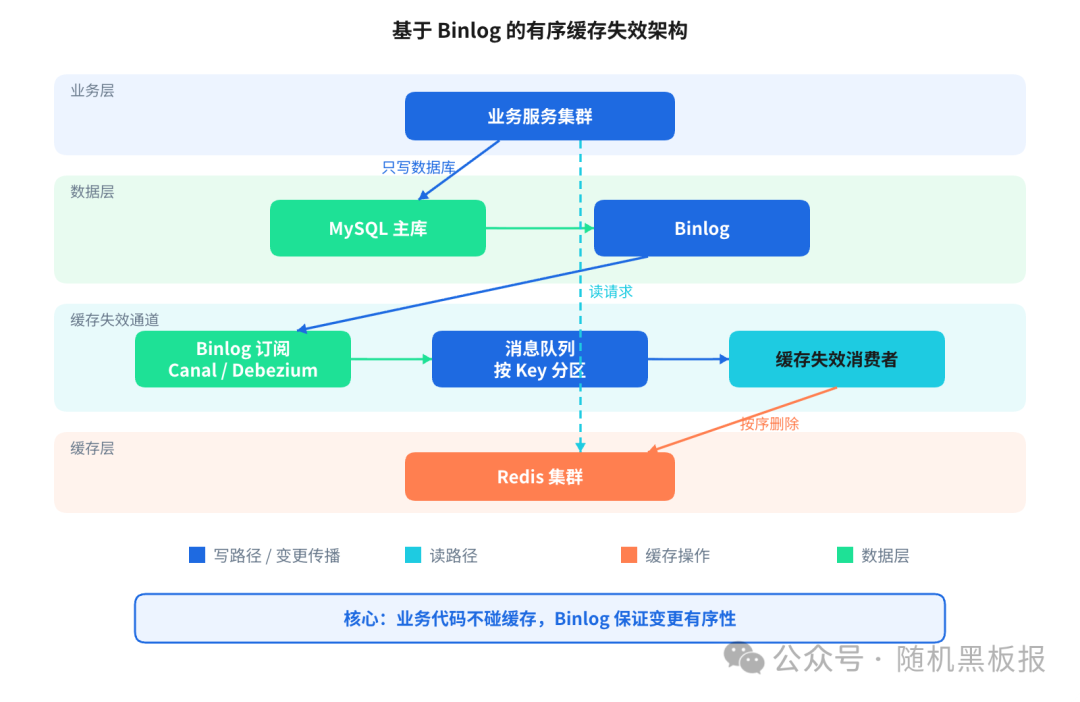
这个架构有几个关键的设计点。
- 业务代码只负责写数据库,不操作缓存。 这从根源上避免了业务代码并发删除缓存带来的时序混乱。读路径依然是先查缓存、未命中查数据库、回填缓存。
- 消息队列按 Key 分区,保证同一个 Key 的变更串行处理。 这是有序性的关键。Binlog本身是全局有序的,但全局串行处理的吞吐量太低。按Key哈希到不同分区后,既保证了同Key有序,又通过分区并行提升了整体吞吐。
- 消费者做的是删除缓存而不是更新缓存。 为什么不直接从Binlog里拿到新值写入缓存?因为删除是幂等的,而更新不是。如果消费者处理速度有波动导致消息积压,多条针对同一个Key的变更消息堆在一起,删除操作无论执行多少次结果都一样,但更新操作如果乱序执行就又出问题了。删除缓存让读请求去“拉”最新数据,比“推”更新到缓存更安全。
这种方案的一致性延迟取决于Binlog消费链路的端到端延迟,通常在百毫秒级别。对于绝大多数场景来说已经足够。
但我们还需要考虑一个现实问题:从Binlog变更到缓存删除之间,仍然存在一个短暂的窗口。在这个窗口内,读请求可能读到旧的缓存值。对于大部分业务来说,这个亚秒级的延迟是可以接受的。但对于极端敏感的场景,比如库存扣减、余额变动,还需要叠加一层版本号机制。
进阶:版本号 / 时间戳裁决
不管采用哪种缓存更新策略,最终都面临一个问题:当缓存为空、多个读请求同时去数据库回填时,谁的值应该生效?
版本号机制提供了一个简洁的裁决规则:每条数据携带一个单调递增的版本号(可以是数据库的自增版本字段,也可以是Binlog的位点),回填缓存时做一个比较。只有当新值的版本号大于缓存中已有的版本号时,才允许写入。
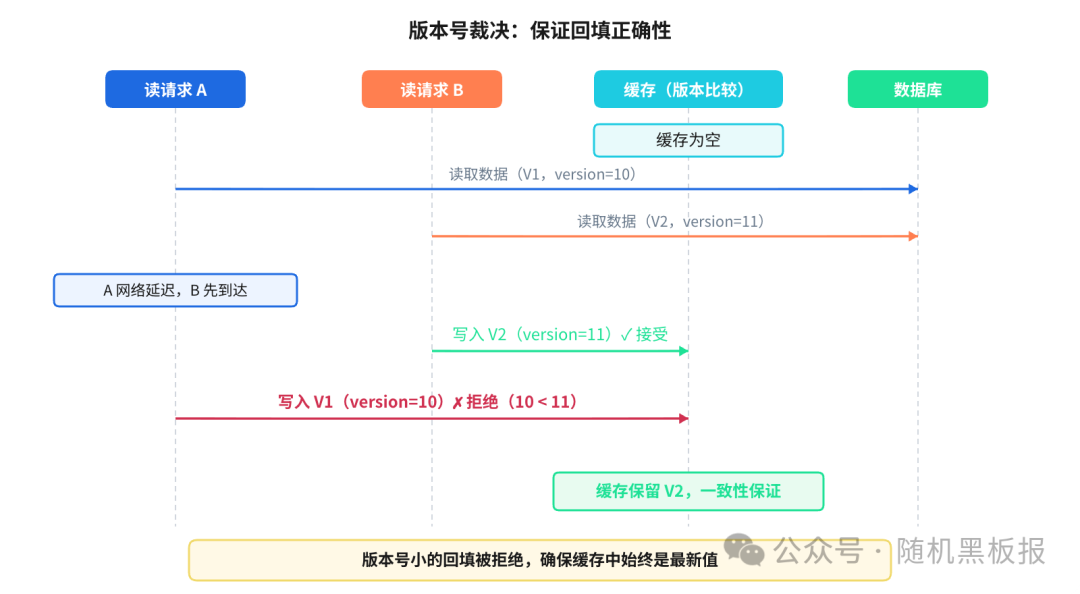
这个机制可以用 Redis 的 Lua 脚本实现原子性的“比较并写入”操作。它和Binlog驱动的缓存失效是互补关系:Binlog保证了“删除”的有序性,版本号保证了“回填”的正确性。两者结合,才构成了完整的时序保障体系。
三个阶段的全景对比
我们把三个阶段的方案放在一起看:
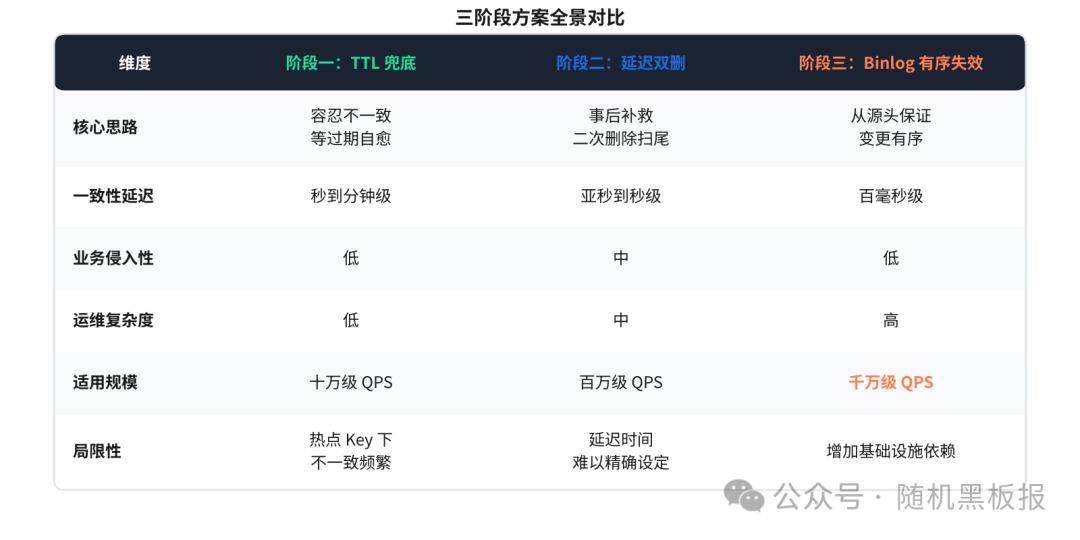
从这张表可以看出一个清晰的演进脉络:解决一致性问题的手段,从“容忍”到“补救”再到“预防”,架构复杂度逐级上升,但不一致窗口逐级缩小。
这也是千万QPS架构的一个典型特征:你不能指望简单方案在极端规模下依然有效,必须用更精密的机制去替代“靠概率兜底”的做法。
落地时容易踩的几个坑
在实际落地 Binlog 驱动缓存失效的过程中,有几个问题值得提前关注。
- Binlog 消费延迟的监控和告警是必须的。 Binlog订阅链路本身也会遇到性能瓶颈。如果消费者处理不过来,消息堆积会导致缓存失效延迟从百毫秒膨胀到秒级甚至更长。需要对消费延迟做实时监控,并设置合理的告警阈值。一旦延迟超标,要有降级策略,比如临时切换回业务代码直接删除缓存的模式。
- 分区数量的设计影响并行度和有序性的平衡。 分区太少,消费吞吐跟不上;分区太多,运维成本增加,而且需要确保分区调整时不丢消息。一般的做法是,分区数量以热点Key的数量级为参考,留出足够的余量。
- 缓存回填时的“惊群”问题。 当一个热点Key被删除后,可能有成千上万个读请求同时发现缓存未命中,一起去查数据库。这就是经典的缓存击穿。在千万QPS场景下,这个问题尤为突出。常见的应对手段是使用分布式锁或者singleflight模式,确保同一时刻只有一个请求去回填,其他请求等待或者使用短暂的旧缓存值。
写在最后
回头看这整条演进路线,核心思路其实很朴素:当无序带来的问题变得不可容忍时,就要在架构中引入有序性。
从TTL兜底到延迟双删,再到Binlog驱动的有序失效,我们做的事情本质上都是在给混乱的读写时序“加约束”。约束加得越精准,一致性保障越强,但架构复杂度和运维成本也随之上升。
这和很多架构决策一样,没有“银弹”。在十万QPS的系统里上Binlog订阅链路,是过度设计;在千万QPS的系统里只靠TTL兜底,是心存侥幸。选择哪个阶段的方案,取决于你的业务规模、一致性要求和团队的运维能力。
最后留一个开放性的问题:在读多写少的场景下,Binlog驱动方案效果很好。但如果你面对的是一个写多读少的场景,每秒有上万次写操作打到同一个Key,Binlog消费者还没处理完上一条,新的变更又来了。这种情况下,你会怎么设计缓存一致性策略?
希望这篇文章能为你构建高并发系统提供一些思路。更多关于 系统架构 和 数据库 的深度讨论,欢迎访问 云栈社区 与大家一起交流。
 发表于 2026-3-25 04:34:50
|
查看: 156|
回复: 0
发表于 2026-3-25 04:34:50
|
查看: 156|
回复: 0
