在AI Agent技术快速发展的当下,OpenClaw正成为一个被频繁讨论的项目。很多人初次接触时,会将其理解为“更强大的聊天机器人”;但如果切换到一个工程视角,你会发现它真正有趣的地方,并非仅仅是“更会聊天”,而在于它将AI组织成了一套可以持续运行、能够接入现实世界、并能不断扩展能力的系统。
本文试图从工程角度,厘清几个核心问题:
- OpenClaw到底是什么?
- 它的整体架构是如何分层的?
- 一条消息进入系统后,内部会经历什么流程?
- 它为何能同时具备工具执行、持续会话和长期记忆?
如果用一句话概括OpenClaw,可以这样说:它不是一个单纯的聊天机器人,而是一套连接大模型、工具系统、会话机制、记忆系统和多渠道通信能力的 AI Agent 运行框架。
一、OpenClaw 是什么?
先抛结论:
OpenClaw = 一个连接大模型 + 工具系统 + 多渠道通信的 AI Agent 框架
它并非一个单纯的AI应用,更接近于一个“基础设施层”。从工程角度看,它主要致力于解决三个非常现实的问题:
- AI如何接入真实世界:通过工具系统,让模型不只是“会回答”,而是能搜索、读写文件、执行命令、操作浏览器、管理进程,真正开始“做事”。
- AI如何持续工作:通过会话、状态持久化和记忆系统,让一次对话不会随着页面关闭就彻底消失,而是能够延续上下文、沉淀偏好,逐步形成长期协作能力。
- AI如何在不同渠道统一服务:通过渠道适配器和Gateway,把来自Telegram、WhatsApp、飞书、CLI、Web UI等不同入口的请求,统一接入同一套运行时。
从技术形态上看,OpenClaw本质上可以被理解为:
- 一个 TypeScript CLI 应用
- 一个本地运行的服务进程
- 一个 AI Agent 调度系统
这也是为什么许多人初次使用OpenClaw时,看到的是一个“能聊天的AI”;但再深入一层,你会发现它更像一套让AI真正开始工作的运行平台。
二、整体架构:一个“AI操作系统”
用一句话概括OpenClaw的架构:它是一套以Gateway为中心,驱动Agent执行的调度系统。
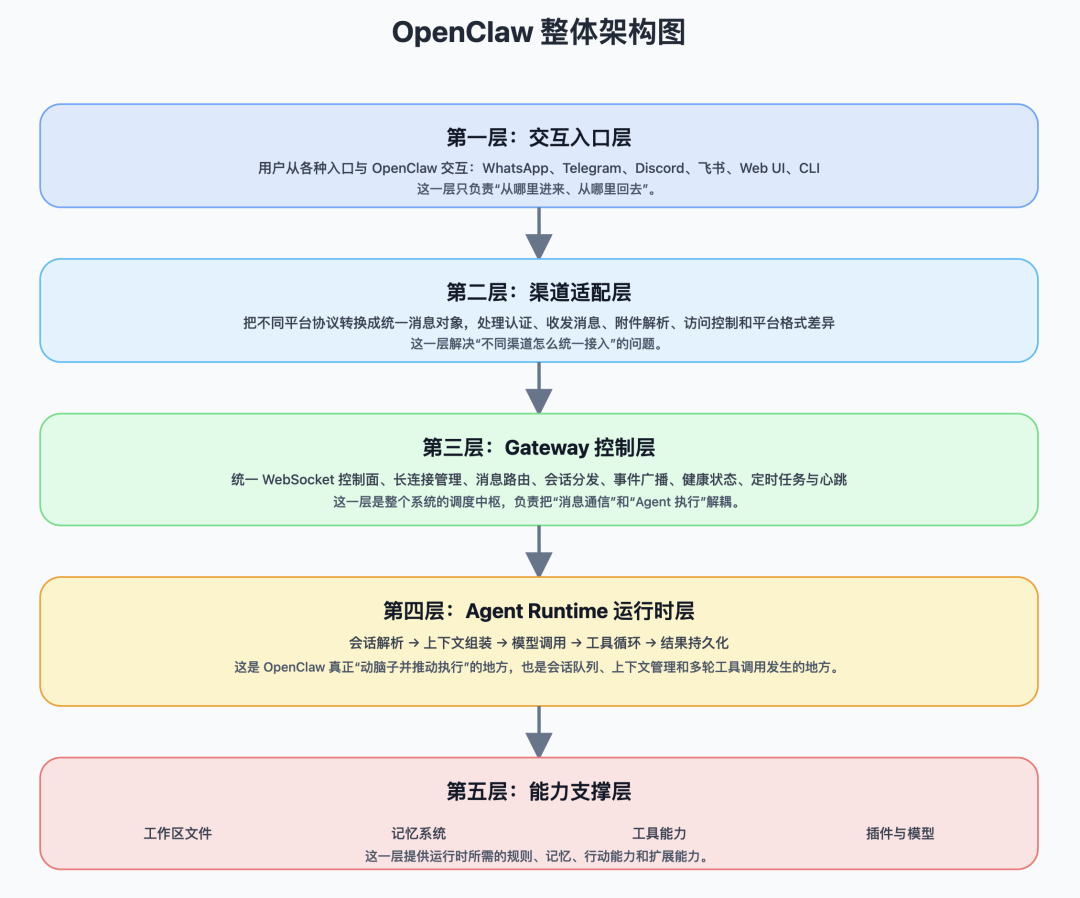
用户从各种入口发来的消息,先经过渠道适配,再进入Gateway调度,随后由Agent Runtime负责真正执行;底层的工作区、记忆、工具、插件和模型能力,则为整个系统持续提供支撑。
1. 交互入口层:用户从哪里进入系统
这一层负责承接所有外部入口。常见入口包括:
- Telegram / WhatsApp / Discord
- 飞书 / 钉钉 / 微信
- Web UI / CLI
这一层解决的问题其实很简单:用户从哪里进入系统,结果又从哪里返回。
对用户来说,不同入口只是“我在哪个平台和AI说话”;但对系统来说,不同入口背后对应的是完全不同的协议、消息格式、附件结构和认证方式。
2. 渠道适配层:把不同渠道统一成标准消息
不同平台之间的差异其实非常大。有的平台使用Bot Token,有的依赖扫码登录;有的侧重群聊,有的更偏私聊;Markdown支持、附件结构、@提及、媒体上传规则也各不相同。
OpenClaw的做法是通过Channel Adapter统一处理这些差异。适配器通常负责4件事:
- 完成认证与连接
- 接收并解析消息
- 做基础访问控制
- 按平台格式发送回复
这一层的价值,其实就一句话:把不同来源的消息统一格式化。
也就是说,不管用户是从Telegram发来一句文本,还是在飞书里附带一张图片,进入Gateway之前,都会先被转换成标准结构。后续执行层就不用再关心平台差异,而只关心“这到底是一条什么请求”。
3. Gateway 控制层:整个系统的调度中枢
Gateway是OpenClaw的核心控制层,也可以将其理解为AI世界里的“流量中枢 + 任务调度器”。
它主要负责:
- 消息路由:发给哪个Agent
- 会话管理:属于哪个session
- 连接管理:统一WebSocket控制面和长连接
- 事件分发:心跳、状态、定时任务、系统事件
- 权限边界:决定消息是否能继续进入执行环节
- 任务排队:避免并发混乱
其中一个关键设计,是OpenClaw倾向于采用“串行优先”的队列模型。很多资料会把它描述为 lane 机制,本质上可以这样理解:
- 每个会话独立排队执行
- 默认串行,优先保证状态稳定
- 只在明确安全的场景下允许并行
这个设计为什么重要?因为AI Agent系统有一个特别典型的问题:并发越多,状态越容易失控。
如果多个执行过程同时读写同一会话、同一份上下文、同一套工具状态,最终很容易出现竞态、日志混乱和权限边界模糊的问题。OpenClaw的做法并不追求“无限并发”,而是优先保证系统可预测、可回放、可维护。
4. Agent Runtime 执行层:真正“动脑子并推动执行”的地方
如果说接入层、适配层和Gateway更像“接消息、做翻译、做调度”,那么Agent Runtime才是真正负责完成任务的地方。这也是OpenClaw最核心、最像“运行时内核”的一层。
在这一层里,系统不只是调用一次模型API,而是会围绕一次请求,构造出完整的执行过程。通常会包含几类内部责任:
Session Resolution:把消息映射到正确会话,并确定隔离边界Context Assembly:从工作区、历史消息、记忆系统中组装上下文Execution Loop:驱动“模型思考 - 调工具 - 结果反馈 - 再思考”的循环Persistence:把会话、工具结果和必要状态持久化
从职责上说,模型更像“大脑”,而Agent Runtime更像把大脑接到手脚、记忆和调度机制上的“执行内核”。这个执行过程本身就是复杂系统架构思想的体现。
5. 能力支撑层:工作区、记忆、工具、插件与模型
最后一层不是一条单独的执行链路,而是整个系统的能力底座。它主要由4类能力构成:
- 工作区文件:定义Agent的身份、规则、语气、用户信息和工具约束
- 记忆系统:提供长期记忆、daily memory、检索和召回
- 工具能力:浏览器、命令行、文件系统、进程管理、Webhook、定时任务等
- 插件与模型:渠道插件、Provider、Memory插件、自定义工具和模型提供商
这一层不直接面向用户,但会直接决定:
- Agent能看到什么
- Agent能调用什么
- Agent能记住什么
- 系统可以扩展到什么程度
所以从工程视角看,OpenClaw之所以像一个“AI操作系统”,并非因其功能繁多,而是因为它把接入、调度、执行和能力支撑这些层次真正组织起来了。
三、运行流程:一条消息的完整生命周期
如果从运行时角度看,OpenClaw真正要解决的问题其实是:当用户发来一条消息时,系统内部到底是怎么把它变成一次完整执行的?
下面用一个真实场景的例子,把完整流程串起来:
“帮我总结财联社上昨天最热门的10条新闻,并在每天早上8点发给我。”
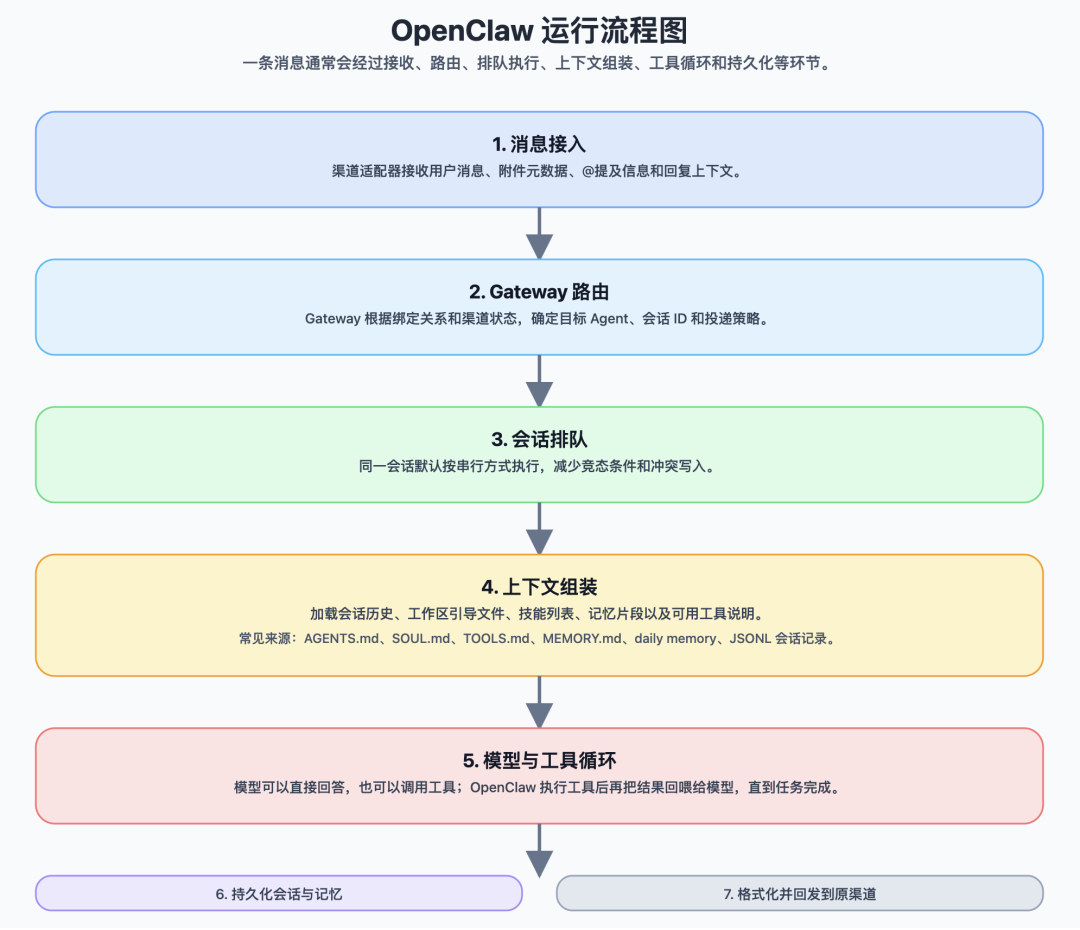
这条消息的处理过程,同时包含了“信息获取”、“内容整理”和“定时发送”三种需求。它至少包含三个子任务:
- 获取财联社上“昨天最热门的新闻”
- 把它们整理成一份可读的Top 10摘要
- 把这件事配置成“每天早上8点自动发送”
这很像真实使用场景中的一句话指令。用户并不是在测试AI会不会聊天,而是希望它像一个真正的助手一样,把“找信息、整理信息、按时推送”整件事一次性接住。
阶段1:消息接入
用户先在某个聊天工具或控制界面发出指令,最先接住它的并不是Agent,而是对应渠道的适配器。
这一步看似基础,实则关键。系统首先要搞清楚:消息是谁发来的,是私聊还是群聊,正文是什么,有无附件、引用或@提及。
走完这一层,OpenClaw会得到一份统一的标准消息结构。对这个例子来说,适配器至少能识别出两类关键信号:
- 这是一条来自当前用户的文本请求
- 这条请求同时包含“新闻获取”、“内容摘要”和“定时发送”三种意图
阶段2:网关处理
消息进入Gateway后,系统才真正开始“调度”。
Gateway在此要做的,不只是简单转发,而是先判断:这条消息应不应该继续执行?该交给哪个Agent?属于哪个 session?以及应该进入哪条队列?换句话说,这一层的任务是:先把权限、边界和顺序理清楚,再谈执行。
如果指令来自主私聊,系统通常会将其归到用户自己的主会话里;如果来自群聊,OpenClaw往往会主动收紧上下文读取范围,甚至限制某些定时发送或写入类操作。
这也是OpenClaw很有代表性的一点:session 不只是聊天容器,它本身就是权限边界和执行边界。
阶段3:上下文构建
轮到当前会话正式执行时,Agent Runtime才会开始准备这一轮真正要送给模型的输入。
这一步的重点,不是“把用户刚才的话再发给模型一遍”,而是尽可能把这条请求背后真正相关的信息补齐。系统通常会在此加载历史对话、工作区文件、工具定义、记忆片段,以及当前可用的技能说明。
在OpenClaw里,这一步尤其重要,因为它不是简单拼接聊天记录,而是会动态读取一整套工作区文件,比如 AGENTS.md、SOUL.md、USER.md、IDENTITY.md、TOOLS.md、MEMORY.md 和 memory/YYYY-MM-DD.md。
继续沿用此例,系统在这一层很可能做这些准备:
- 检查工作区是否已定义“新闻摘要”类任务的输出风格
- 读取daily memory或长期记忆,看看用户以前是否表达过对信息来源、语言风格、摘要格式的偏好
- 加载工具说明,确认当前Agent是否具备网页浏览、搜索抓取和定时任务能力
- 把这些内容一起组装进当前prompt
也就是说,模型真正拿到的,不只是那句“帮我总结财联社上昨天最热门的10条新闻……”,而是“用户想要什么、有没有历史偏好、当前又能用哪些工具”。很多时候,任务最后做得像不像一个“可靠助手”,差异恰恰就出在这里。
阶段4:调用大模型
上下文准备完成后,系统才会真正向LLM发起请求。模型可能是GPT、Claude或其他兼容Provider;这些差异通常由运行时统一抽象掉。
从外部看,这只是“一次模型调用”;但在系统内部,这其实是AI真正开始思考的起点。对这条示例消息,模型通常会先把任务拆开理解:
- “财联社上昨天最热门的10条新闻”应如何获取
- 抓到内容后,应用什么结构整理成摘要
- “每天早上8点发给我”应如何落地
如果所需信息已在上下文里,模型可以直接继续推理;如果不够,它就可能触发工具调用或记忆检索。
阶段5:工具执行
如果模型直接给出答案,流程可能很快结束;但如果它判断任务需要动用工具,系统就会进入OpenClaw最典型的Agent Loop。
这个循环的本质很简单:思考 → 行动 → 反馈 → 再思考
模型先给出工具调用意图,系统执行相应动作,再把结果返回给模型,模型据此继续推理,直到任务真正完成。
放回此例,过程大概是这样:
- 模型先判断需要用浏览器或搜索工具抓取财联社昨天热门内容
- 系统调用相关工具,打开目标页面或结果页,提取候选新闻列表
- 若信息不够,模型可能继续调用浏览器翻页、打开具体帖子,或调用文本/文件工具做临时整理
- 拿到足够材料后,模型将内容整理成“最热门的10条新闻摘要”
- 接着模型判断需调用定时任务、消息发送或webhook工具
- 系统执行相应工具,把“每天早上8点发送摘要”配置为自动任务
- 工具返回成功状态后,模型将“新闻摘要 + 定时发送已配置”整合成最终回复
这样用户最终拿到的,就不只是一份“新闻摘要建议”,而是已整理好的摘要,以及一条已配置好的自动推送任务。这深刻体现了现代人工智能应用从“问答”到“行动”的转变。
阶段6:返回结果
当模型最终产出可直接回复的结果后,系统会把内容重新格式化,通过原始渠道发回。
若消息来自Telegram,就按Telegram规则回发;若来自飞书,就按飞书格式发送;内容过长还可能做分段处理。
对应此例,用户最终看到的回复,通常同时包含两部分:
- 一段对“财联社上昨天最热门10条新闻”的摘要结果
- 一句明确确认,如“已为你配置每天早上8点自动发送”
阶段7:持久化
一轮执行结束后,系统不会把过程直接丢弃,而是将相关状态写回本地。
通常被保存的内容包括:用户输入、模型输出、工具调用、工具结果、相关会话状态。
这些内容通常会写入 session 的JSONL文件,必要时也会更新记忆系统。
对此例,最终被记录的不只是用户提问,还包括:新闻是如何被抓取筛选的、生成了哪10条摘要、定时发送是否创建成功、调用了哪些工具,以及这一轮执行有无产生值得长期保留的新偏好或配置。
到这里,一条消息才算真正走完了OpenClaw的完整生命周期。
四、记忆系统:让AI“不再失忆”
OpenClaw的记忆系统并不追求花哨,相反,其设计相当务实。其核心思想可概括为:把记忆显式落盘、可解释化,并通过检索在需要时重新召回。
从结构上看,OpenClaw的记忆大致分为两层。
1. 会话记录(Session)
这是最原始、最完整的一层记忆。
每次对话、模型输出、工具调用和结果,都会先被写入会话记录,通常采用JSONL格式保存。
其作用主要是:
- 存储完整历史
- 作为当前会话的短期上下文来源
- 支持后续压缩、回放和追踪
这一层更像“短期记忆”,它关注的是:这轮对话里刚刚发生了什么。
2. 长期记忆(Memory)
相比session,长期记忆更偏向“被整理过的稳定信息”。
典型形式包括:MEMORY.md、memory/YYYY-MM-DD.md
其中 MEMORY.md 更适合存长期偏好、稳定事实、长期约定;daily memory更适合存当天事项、短周期上下文、阶段性结论。
这一层解决的是:未来新的会话里,AI还需要记住什么。
记忆的检索方式
OpenClaw的记忆检索通常不是简单字符串匹配,而是采用混合检索思路:
两种方式结合,能同时兼顾“理解用户表达变化”和“精准找到原始内容”。
例如用户问:“我之前提过的写作风格偏好是什么?”即使之前保存的表述不完全一样,系统也可能通过语义匹配找出相关记忆片段。
为何这套记忆设计值得重视?
因为没有记忆,Agent再强,也很容易退化成一次性执行器。
而有了session和长期记忆后,OpenClaw才具备以下能力:
- 记住用户长期偏好
- 在多轮任务中延续状态
- 区分短期上下文和长期知识
- 在新会话中继续保持一致性
另外,OpenClaw还强调:记忆和上下文不是一回事。
- 上下文:当前这一轮真正送给模型看的内容
- 记忆:已保存在磁盘上、未来可重新召回的内容
这意味着系统不会“自动记住一切”,而是通过持久化和检索机制,让记忆变得可控、可解释、可维护。
五、插件机制:可扩展的核心设计
OpenClaw一个重要的工程优势在于:它不是靠不断修改核心代码来扩展功能,而是尽量通过插件机制扩展能力。
常见可扩展方向包括4类:
- Channel插件:用于接入新的消息平台或渠道。
- Tool插件:用于增加新的工具能力,让Agent能执行新动作。
- Memory插件:用于替换或扩展记忆存储与检索后端。
- Provider插件:用于接入新的模型提供商、本地模型或私有部署模型。
这套设计的价值在于,它把OpenClaw从一个单一产品,变成了一个可扩展的平台。换句话说,用户不必修改核心架构,就可以逐步接入新的渠道、工具、模型和存储能力。这种设计模式是开源实战中项目保持生命力的关键。
六、安全与执行环境
因为OpenClaw不只是“回答问题”,还能访问文件系统、执行命令、操作浏览器和调用系统资源,所以安全设计变得非常关键。
其总体思路可概括为:在可控风险下,给予AI尽可能多的行动能力。
1. 工具执行隔离
OpenClaw在许多场景下会采用隔离执行思路,例如:
- 默认在Docker沙箱内执行命令
- 对不同会话配置不同权限边界
- 根据工具类型区分风险级别
这样可以尽量降低AI直接操作宿主环境带来的风险。
2. 命令审批机制
对于具有副作用或潜在风险的命令,系统通常会给用户审批选项,例如:
这使得OpenClaw并非“无条件放权”,而是在执行层面为用户保留最终控制权。
3. 危险操作拦截
对于一些明显危险的shell结构或高风险操作,系统会做额外拦截,例如:
- 重定向敏感系统文件
- 子shell执行
- 命令注入式组合
这说明OpenClaw的安全设计不是单点权限判断,而是同时考虑了执行环境、命令结构和用户授权。
七、总结
如果用一句话总结OpenClaw:它不是一个聊天机器人,而是一套让AI真正“能工作”的操作系统。
其核心价值可总结为3点:
- 让AI有执行力:Tools
- 让AI有持续性:Memory + Session
- 让AI有组织能力:Gateway + Agent Runtime
OpenClaw的流行,在于做对了一件事:把AI从一个工具,组织成了一个系统。 对于希望深入理解和应用此类前沿技术的开发者,持续关注云栈社区等技术社区,参与讨论和开源实战,是快速成长的捷径。
参考资料
 发表于 2026-3-25 05:15:00
|
查看: 159|
回复: 0
发表于 2026-3-25 05:15:00
|
查看: 159|
回复: 0
