大约一个月前,笔者复现了东吴证券高子剑老师在2022年6月发布的研报《重拾自信选股因子——从过度自信到重拾自信》中的一个核心因子——过度自信因子。
在那篇研报中,还提及了一个名为“重拾自信”的因子,其计算方法相对简单:在每月月末,以过度自信因子作为被解释变量,过去20个交易日的收益率作为解释变量进行截面回归,取其残差即可。不过,这个因子整体上并无太多特殊之处。因此,本文要讨论的并非“重拾自信”因子,而是笔者基于过度自信因子的原始逻辑进行改造后得到的一个新因子。
在研报中,对过度自信因子的解释如下:
我们认为CP的长短与内幕噪声消息的真实程度有关,如果内幕噪声消息的真实程度很低,即更像谣言,那么该消息将很快被辟谣,因此股价在高位持续的时间会很短,即CP很短;反之,如果内幕噪声消息的真实程度很高,股价将维持较长时间的高位,即CP很长。因此,我们以CP值的大小来构造因子,我们称它为“过度自信因子”,CP(高股价持续时间)越长,公司越利好,未来收益就会越高。
基于这个逻辑,笔者萌生了一个想法:能否将原始的分钟收益率替换为经市场模型调整后的残差收益率,来重新计算这个因子呢?这种用残差收益率来优化传统因子的思路,在近期的一些研究中也有所体现,旨在剥离系统性风险,捕捉更纯粹的个股特异收益。
计算步骤与代码实现
计算步骤本身并不复杂。核心在于,将每日的分钟收益率作为被解释变量,市场收益率(可以是所有股票分钟收益率的等权平均,也可以用市值加权)作为解释变量,进行时序回归并取其残差,从而得到残差收益率。
获得残差收益率之后,便可以完全遵循一个月前那篇文章中描述的计算“过度自信因子”的步骤来生成新因子。
以下是核心的代码实现:
def process_single_day(self, idx):
# 加载当日分钟数据
file_name = self.files[idx]
date_str = file_name.split('.')[0]
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['close', 'open'])
rtn = data.to_dataframe('close') / data.to_dataframe('open') - 1
mkt = rtn.mean(axis=1)
resi = []
for i in range(rtn.shape[1]):
if rtn.iloc[:, i].sum() == 0:
resi.append(pd.DataFrame(np.nan, index=data.trade_days, columns=[data.codes[i]]))
else:
resi.append(self.cal_resi(rtn.iloc[:, i:i+1], mkt.to_frame()))
resi = pd.concat(resi, axis=1)
mu = resi.mean()
sigma = resi.std()
up_flag = (resi > mu + sigma).reset_index(drop=True)
down_flag = (resi < mu - sigma).reset_index(drop=True)
res = []
for i in range(resi.shape[1]):
res.append(self.cal_med(down_flag.iloc[:, i]) - self.cal_med(up_flag.iloc[:, i]))
res = pd.Series(data=res, index=data.codes, name=pd.to_datetime(date_str) + timedelta(hours=15))
return res
代码简要说明:
- 第1-6行:读取指定日期的分钟行情数据,并计算基础的分钟收益率。
- 第7-15行:循环计算每只股票相对于市场收益的残差收益率。这里涉及到的残差收益率计算是深度学习和传统量化模型中常用的降噪方法。
- 第16-23行:基于残差收益率,计算改造后的“过度自信因子”。逻辑是找出残差收益率超过“均值+标准差”和低于“均值-标准差”的时段,并计算其中位数位置的时间差。
两个关键的静态方法如下:
@staticmethod
def cal_med(data):
data = data[data]
return np.median(data.index.tolist())
@staticmethod
def cal_resi(y, x):
lr = LinearRegression()
lr.fit(x, y)
resi = y - lr.predict(x)
return resi
cal_med:计算布尔序列中值为True的索引的中位数。cal_resi:使用线性回归计算收益率序列y相对于市场序列x的残差。
因子评价
首先,我们来看一下这个基于残差收益率改造的因子与原始“过度自信因子”的相关性。
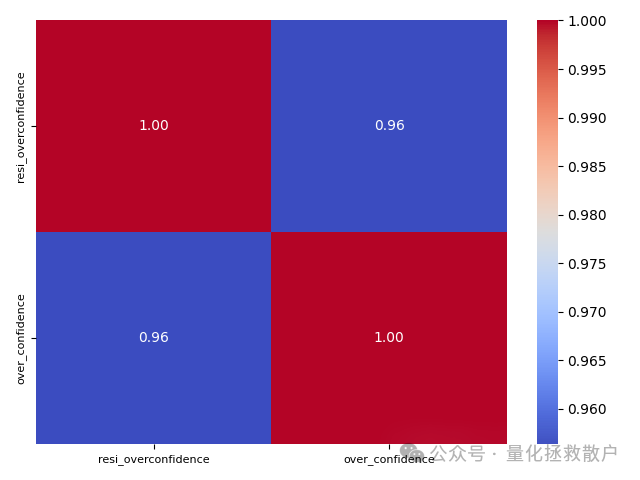
从热力图可以看出,两者的相关性高达0.96,这说明改造并未从根本上改变因子的性质。尽管如此,我们仍将其单独列出,因为它在分层回测中展现出了不同的特征。
IC分析
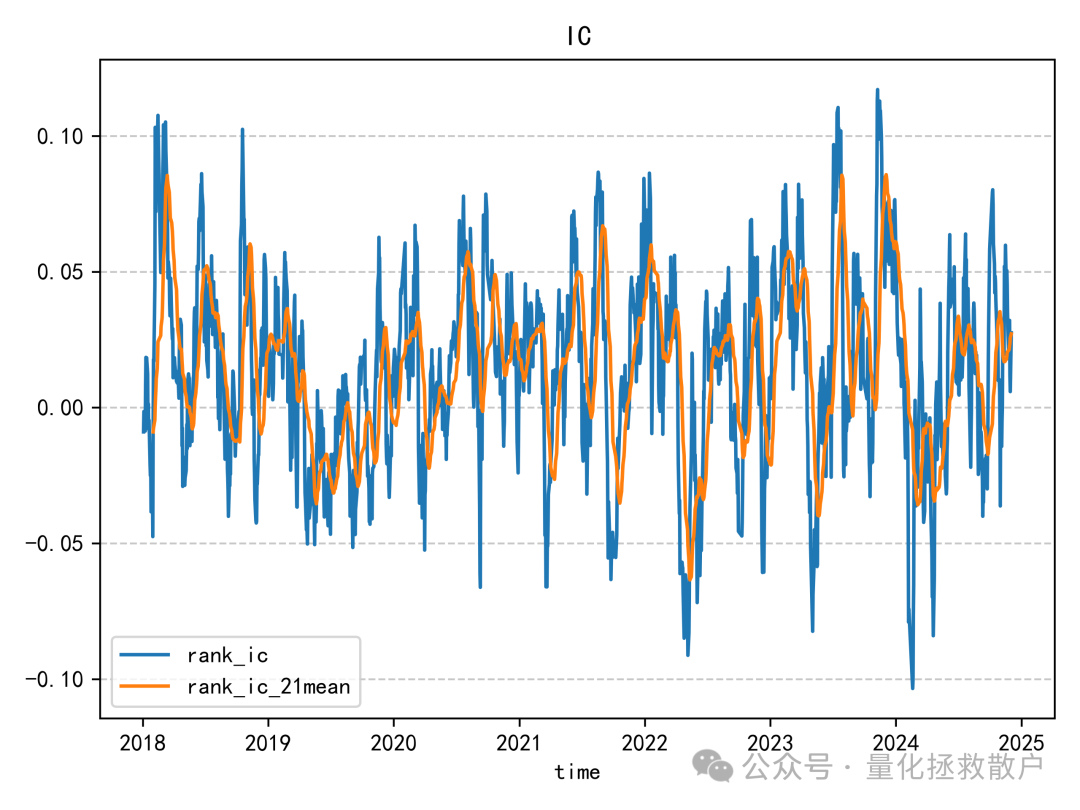
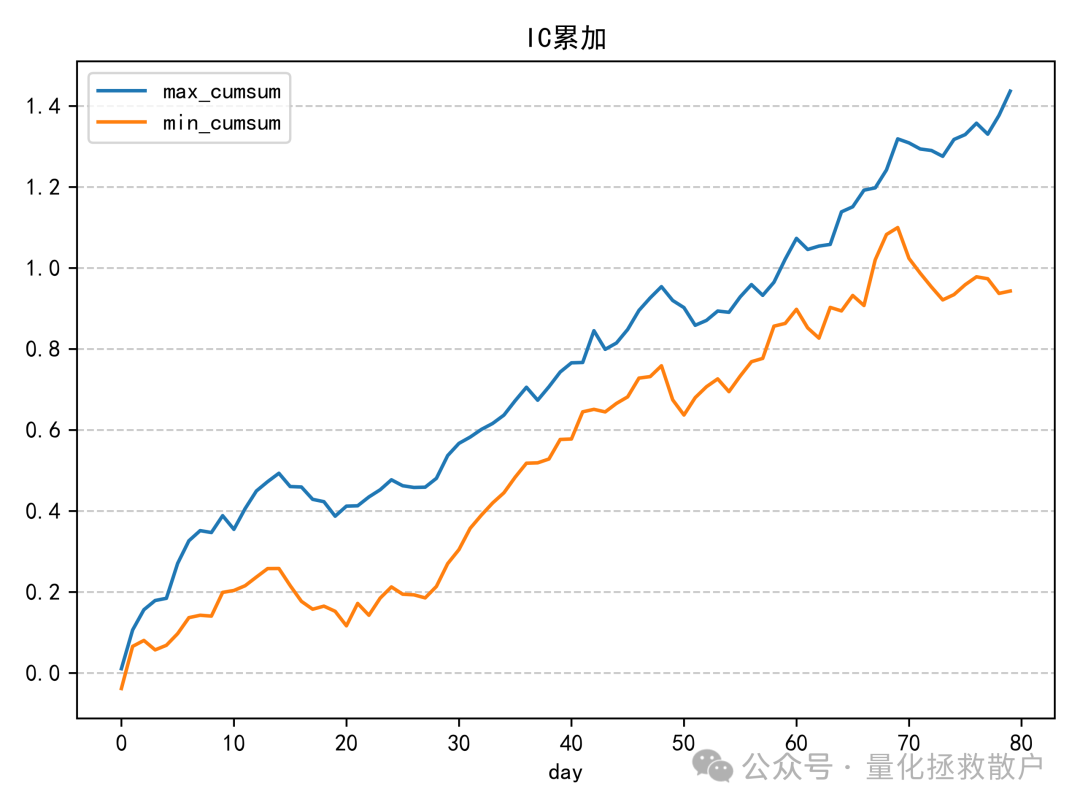
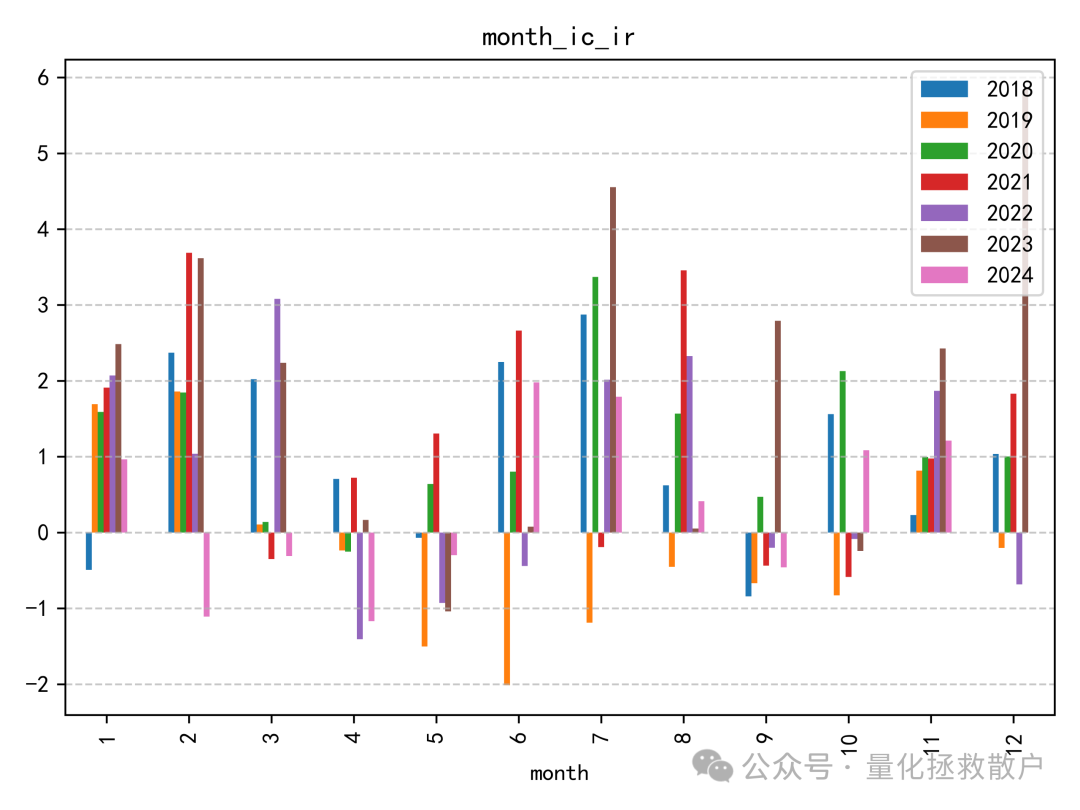
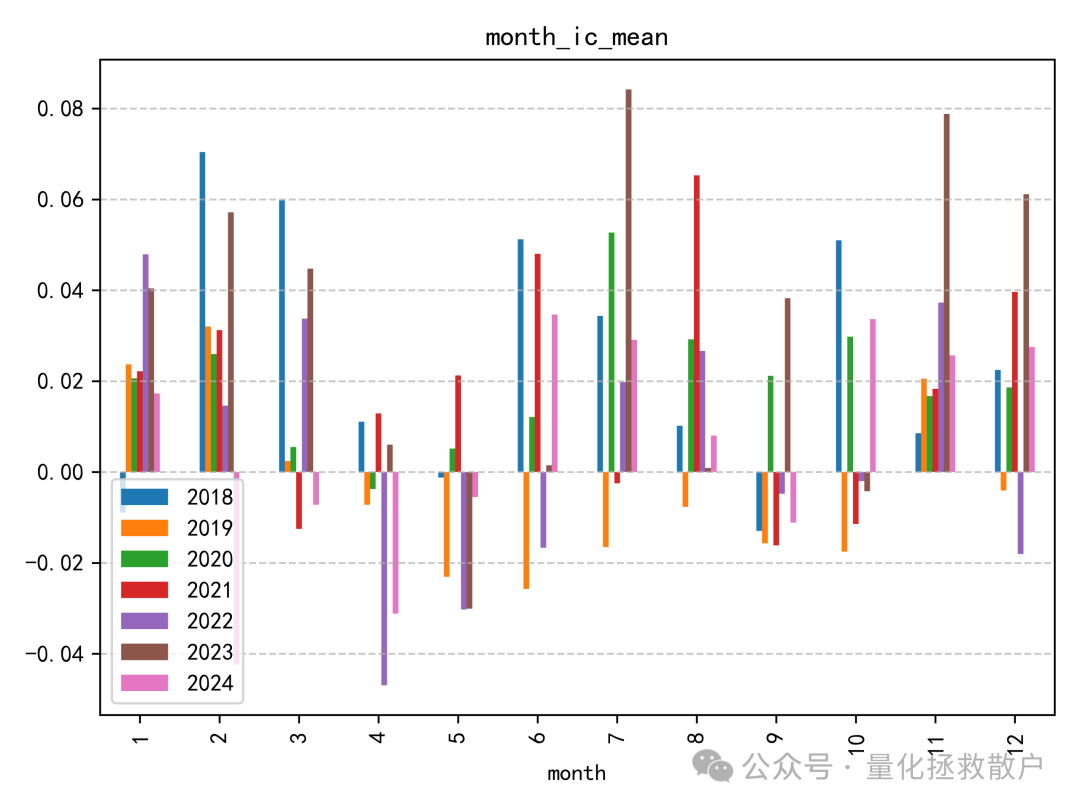
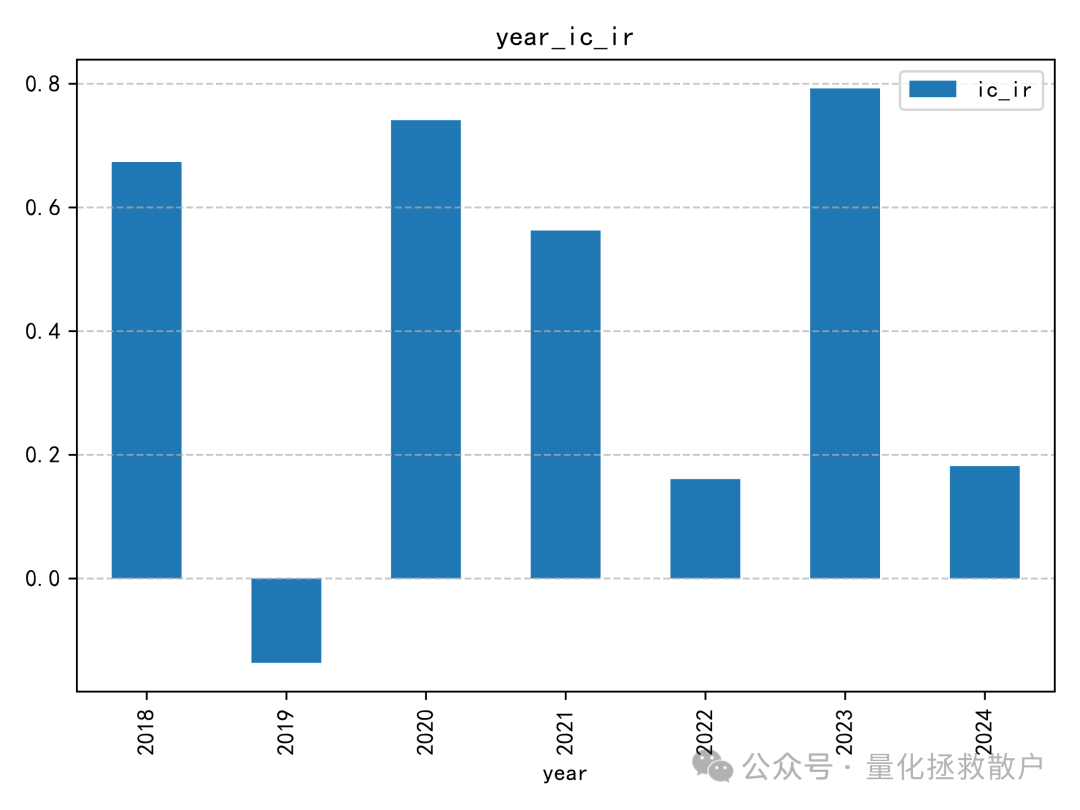
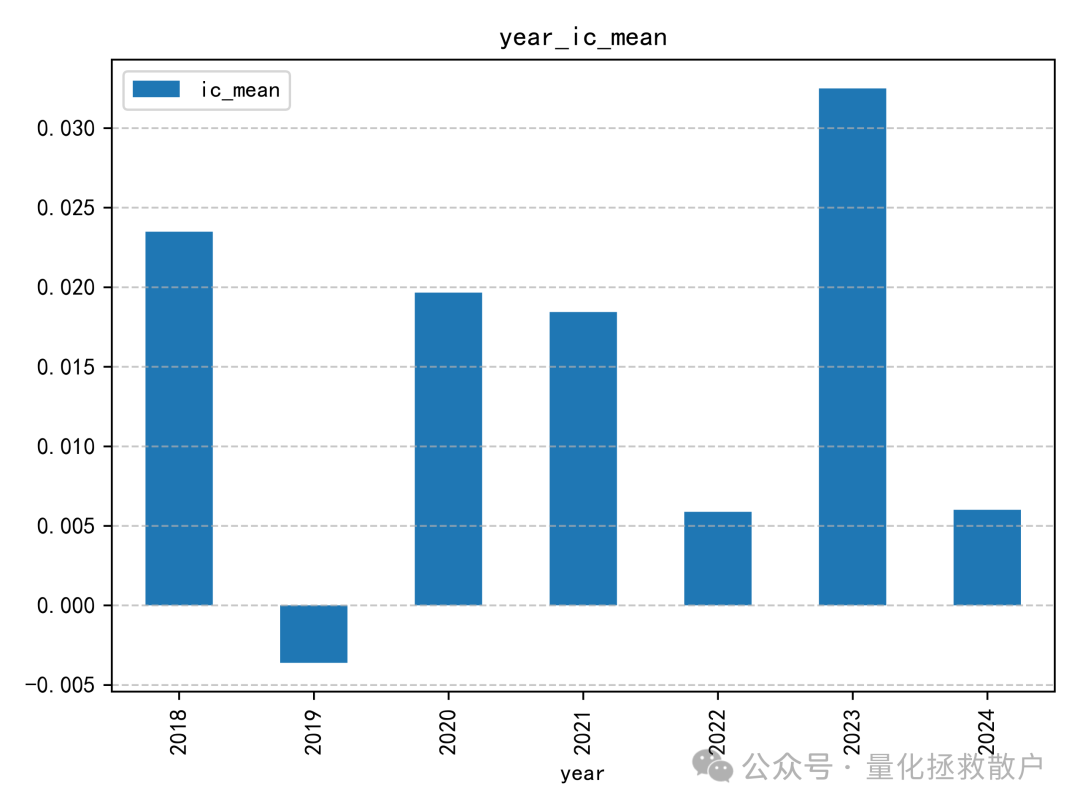
在信息系数(IC)表现上,新因子相较于原版有所下降。一个明显的现象是在2019年,其IC方向与其他年份相反,这提示我们在使用该因子时可能需要关注其在不同市场环境下的稳定性。
回归分析
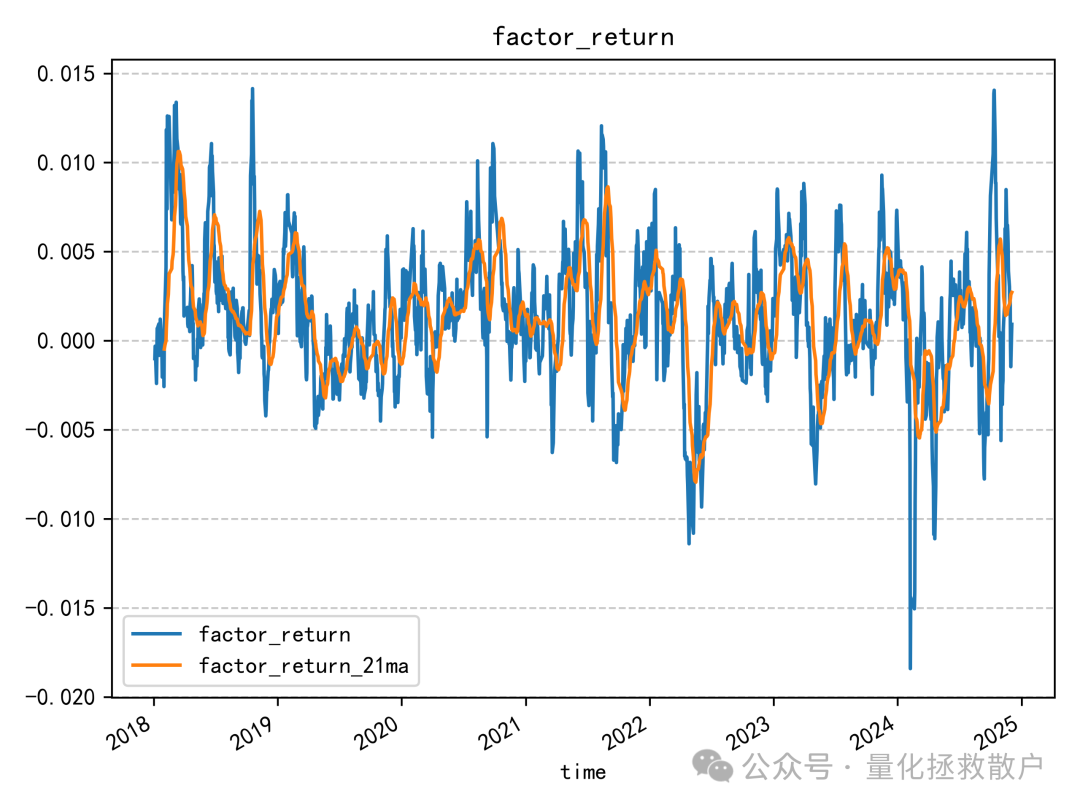
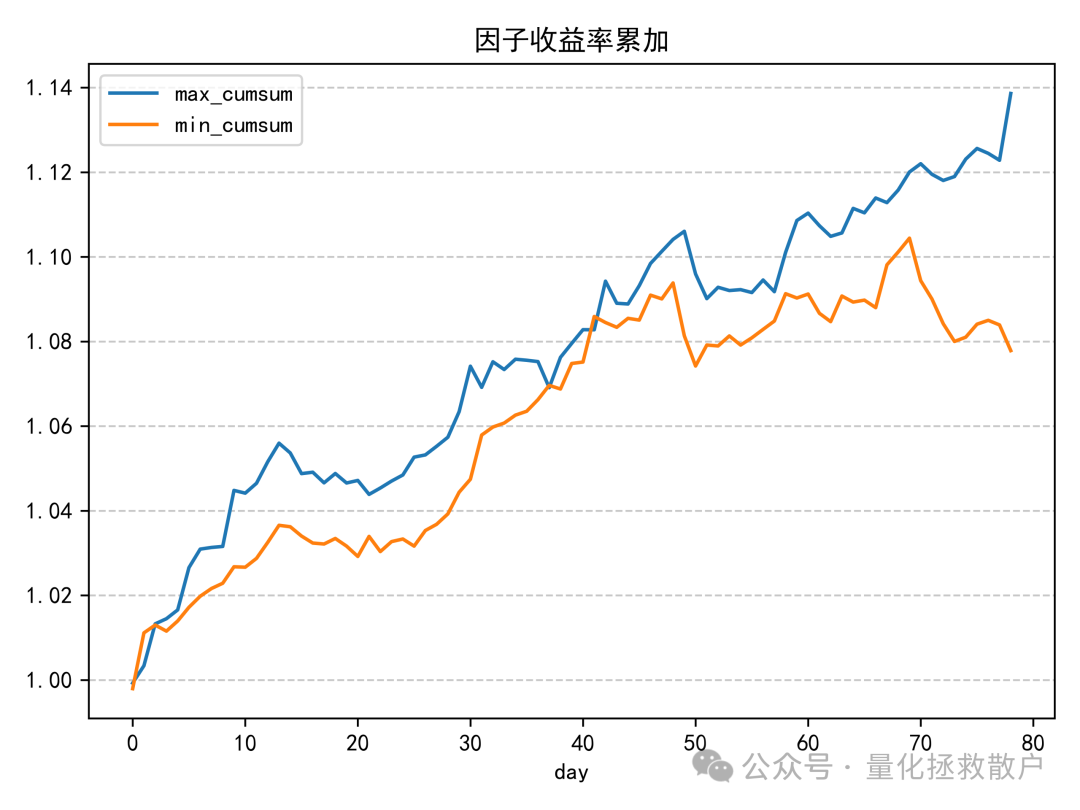
换手率分析
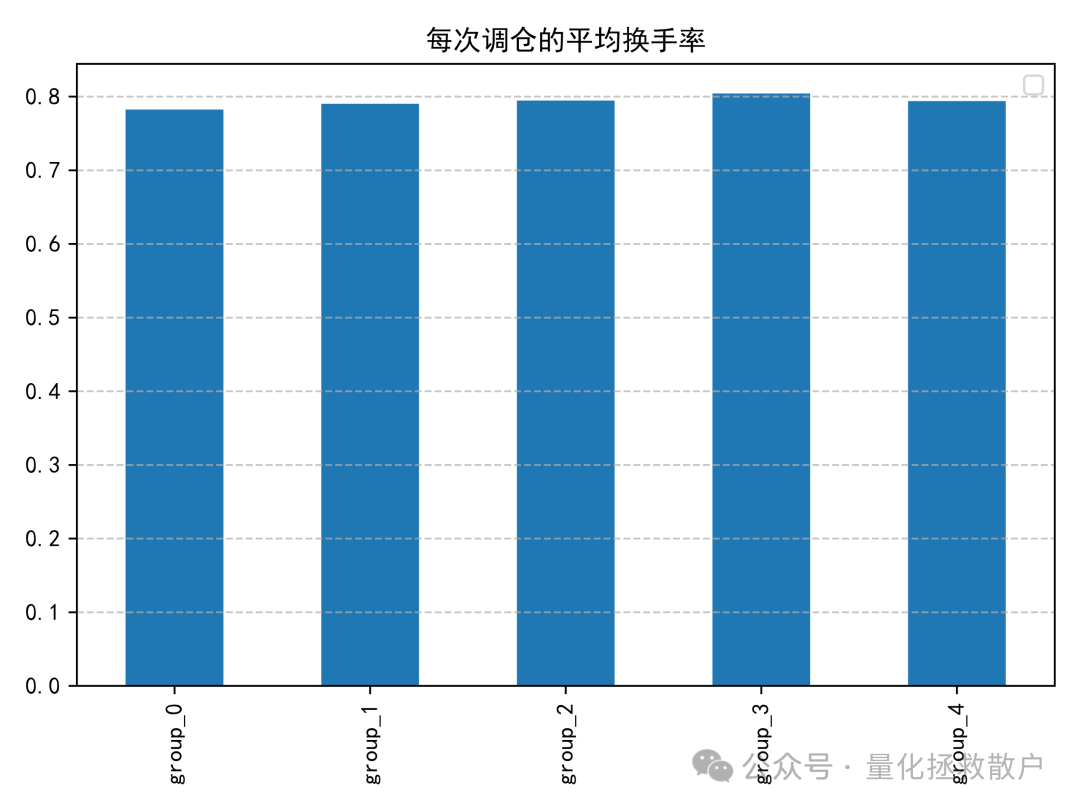
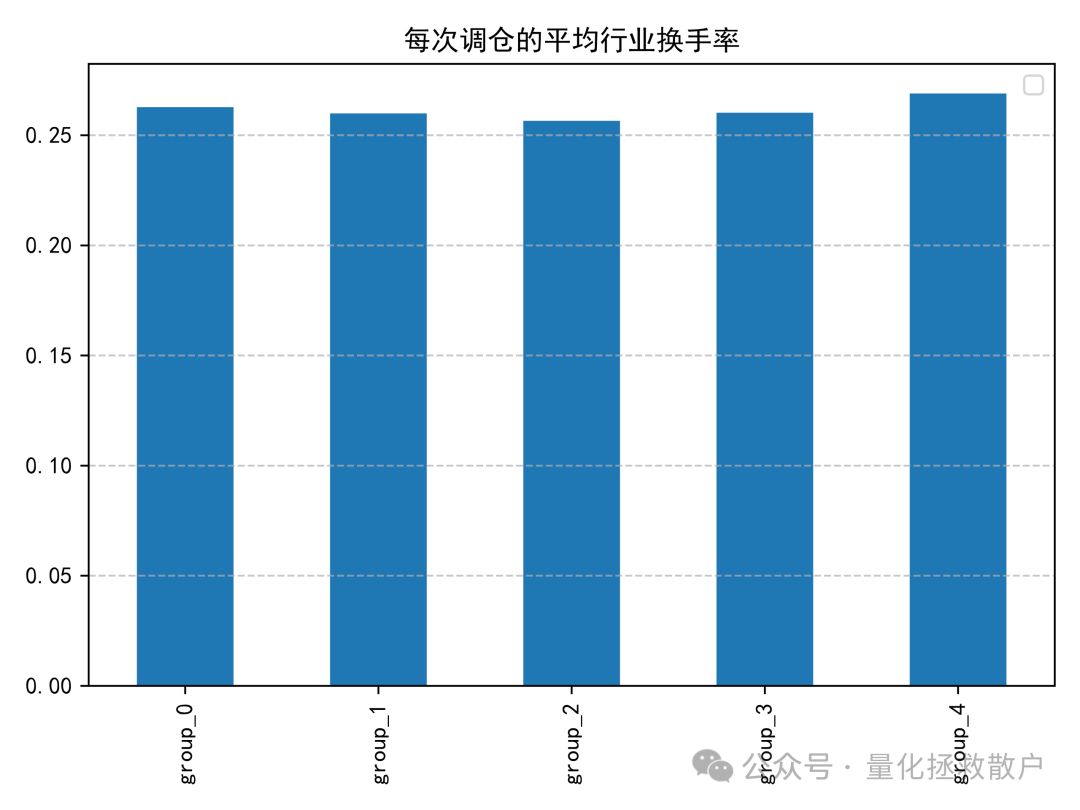
换手率分析显示,该因子在调仓时产生的个股和行业换手率处于可接受范围内,并未异常偏高,这在实际交易中是一个积极的信号。
收益分析
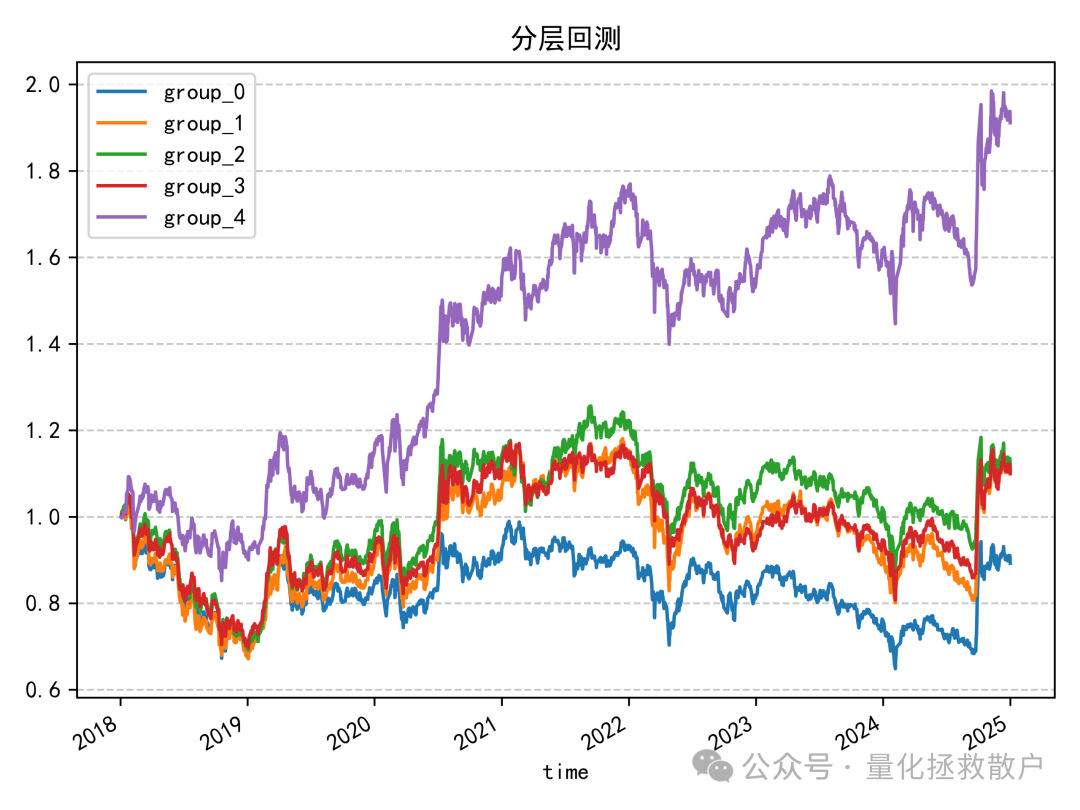
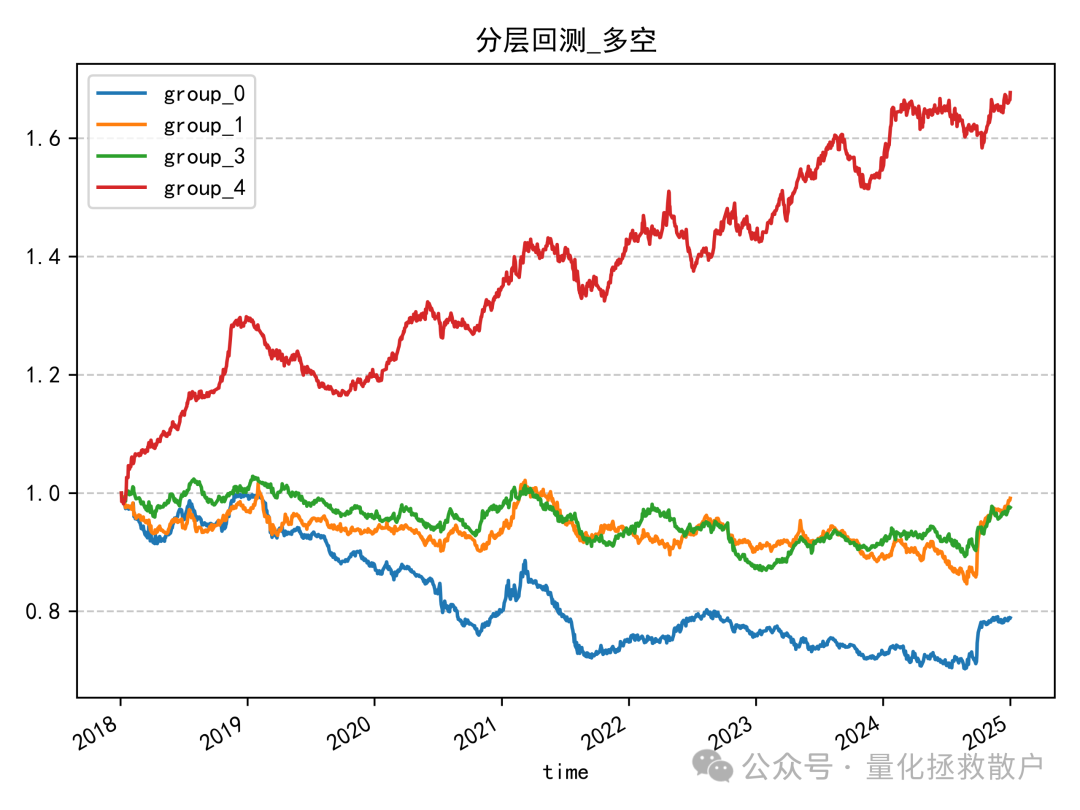
收益分析是本次改造的亮点所在。原始的过度自信因子在分层回测上已有不错的表现,而经过残差收益率优化后,虽然在IC和分层单调性上略有减弱,但其多空收益得到了显著提升。
从“分层回测_多空”图中可以清晰看到,做多最高分组、做空最低分组的组合净值曲线(group_4)在样本后期呈现出强劲的上升趋势,整体夏普比率和收益风险比可能优于原版因子。这正是笔者觉得这个改造版本值得分享的核心价值。
总结
本次对“过度自信因子”的魔改,核心思想是利用残差收益率剥离市场系统性波动,试图捕捉更纯粹的个股特异行为。回测结果表明,这一改动在牺牲部分IC稳定性的同时,换来了多空对冲收益的显著增强。这对于寻求多空策略或市场中性策略的量化投资者而言,提供了一个新的思路和备选因子。当然,任何因子都需经过严格的风险控制和样本外检验,本文的分析仅作为思路探讨和初步回测参考。在云栈社区的技术论坛中,经常有开发者分享类似的因子挖掘与优化实践,持续推动着量化策略研究的进步。
 发表于 2026-3-26 00:55:07
|
查看: 124|
回复: 0
发表于 2026-3-26 00:55:07
|
查看: 124|
回复: 0
