在本文中,我们将编写代码并可视化一个先进的基于智能体的交易系统,其中分析师、研究员、交易员、风险经理和投资组合经理协同工作,执行智能交易。
一个深度思考的交易系统包含多个部门,每个部门由若干子智能体组成,它们通过逻辑流程做出明智决策。例如,分析师团队从各种来源收集数据,研究员团队对这些数据进行辩论和分析以形成策略,执行团队则与投资组合管理及其他辅助子智能体协同工作,对交易进行优化和审批。
在系统底层,有许多复杂的流程在运行,一个典型的流程是这样的……
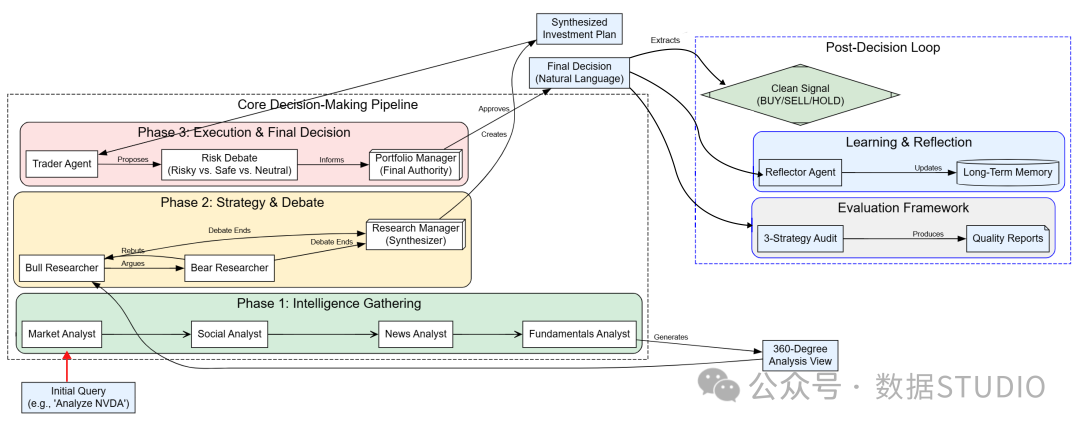
- 首先,一个由专业分析师智能体组成的团队收集360度全方位市场情报,从技术数据、新闻,到社交媒体情绪和公司基本面,无所不包。
- 然后,多头和空头智能体进行对抗性辩论,对研究结果进行压力测试,由研究主管将其整合成一个平衡的投资策略。
- 接着,交易员智能体将该策略转化为具体、可执行的提案,并立即接受多角度风控团队(激进型、保守型、中性型)的审查。
- 最终决策由投资组合经理智能体做出,它权衡交易员的计划与风险辩论的结果,给出最终批准。
- 批准后,系统从经理的自然语言决策中提取出清晰、机器可读的信号(买入、卖出或持有),用于执行和审计。
- 最后,整个过程形成一个反馈闭环。智能体反思交易结果,生成新的经验教训,并存入长期记忆,以持续提升未来表现。
环境搭建、LLM 与 LangSmith 追踪
首先,我们需要妥善保管 API 密钥,并使用 LangSmith 设置追踪。追踪非常重要,因为它能让我们一步步观察多智能体系统内部发生的事情。这大大简化了调试问题、理解智能体工作方式的过程。如果要打造一个可靠的生产级系统,追踪不是可选项,而是必备项。
# 首先,确保已安装所需库
# !pip install -U langchain langgraph langchain_openai tavily-python yfinance finnhub-python stockstats beautifulsoup4 chromadb rich
import os
from getpass import getpass
# 定义一个辅助函数,安全地设置环境变量
def _set_env(var: str):
# 如果环境变量尚未设置,则提示用户输入
if not os.environ.get(var):
os.environ[var] = getpass(f"请输入你的 {var}: ")
# 设置我们将使用的服务的 API 密钥
_set_env("OPENAI_API_KEY")
_set_env("FINNHUB_API_KEY")
_set_env("TAVILY_API_KEY")
_set_env("LANGSMITH_API_KEY")
# 启用 LangSmith 追踪,实现智能体系统的完全可观测性
os.environ["LANGSMITH_TRACING"] = "true"
# 为 LangSmith 定义项目名称,用于组织追踪记录
os.environ["LANGSMITH_PROJECT"] = "Deep-Trading-System"
我们正在设置 OpenAI、Finnhub 和 Tavily 的 API 密钥。
- OpenAI 用于运行我们的大语言模型(你也可以使用 Together AI 等开源大模型提供商的免费额度进行测试)。
- Finnhub[1] 用于获取实时股市数据(免费套餐的 API 调用次数有限)。
- Tavily[2] 用于网页搜索和新闻获取(提供免费套餐)。
- LangSmith 用于追踪和可观测性(免费套餐可让你轻松追踪和调试智能体)。
LANGSMITH_PROJECT 变量尤为重要,它能确保本次运行的所有追踪记录在 LangSmith 仪表板中归为一组,便于隔离和分析本次具体执行。
为了让系统模块化,我们将使用一个中心配置字典。这相当于我们的控制面板,让我们能够轻松尝试不同的模型或参数,而无需修改核心智能体逻辑。
from pprint import pprint
# 定义本次笔记本运行的中心配置
config = {
"results_dir": "./results",
# LLM 设置,指定不同认知任务使用哪些模型
"llm_provider": "openai",
"deep_think_llm": "gpt-4o", # 用于复杂推理和最终决策的强大模型
"quick_think_llm": "gpt-4o-mini", # 用于数据处理和初步分析的快速、低成本模型
"backend_url": "https://api.openai.com/v1",
# 辩论与讨论设置,控制协作智能体的流程
"max_debate_rounds": 2, # 多空辩论将进行 2 轮
"max_risk_discuss_rounds": 1, # 风控团队进行 1 轮辩论
"max_recur_limit": 100, # 智能体循环的安全限制
# 工具设置,控制数据获取行为
"online_tools": True, # 使用实时 API;设为 False 则使用缓存数据,实现更快、更低成本的运行
"data_cache_dir": "./data_cache", # 缓存在线数据的目录
}
# 如果缓存目录不存在,则创建它
os.makedirs(config["data_cache_dir"], exist_ok=True)
print("配置字典已创建:")
pprint(config)
这些参数在后面会更有意义,但这里我们先解释几个关键参数。选择两种不同的模型(deep_think_llm 和 quick_think_llm)是一种深思熟虑的架构决策,旨在优化成本和性能。
- deep_think_llm (
gpt-4o) → 处理复杂推理和最终决策。
- quick_think_llm (
gpt-4o-mini) → 用于常规任务,速度更快、成本更低。
- max_debate_rounds → 控制多空智能体辩论的轮数。
- max_risk_discuss_rounds → 控制风控团队辩论的轮数。
- online_tools / data_cache_dir → 让我们在实时 API 调用和缓存数据之间切换。
定义好配置后,我们现在可以初始化将作为智能体认知引擎的大语言模型了。
from langchain_openai import ChatOpenAI
# 初始化用于高难度推理任务的强大模型
deep_thinking_llm = ChatOpenAI(
model=config["deep_think_llm"],
base_url=config["backend_url"],
temperature=0.1
)
# 初始化用于常规数据处理的快速、高性价比模型
quick_thinking_llm = ChatOpenAI(
model=config["quick_think_llm"],
base_url=config["backend_url"],
temperature=0.1
)
现在我们实例化了两个大语言模型。注意 temperature 参数被设为 0.1。
对于金融分析,我们希望得到确定性的、基于事实的回复,而不是高度创造性的内容。
较低的温度会促使模型坚持最可能、基于事实的输出。
设计共享记忆
AgentState 是共享记忆——我们整个多智能体系统的中枢神经系统。
在 LangGraph 中,状态是一个中心对象,在所有节点之间传递。每个智能体完成其任务时,都会读取并写入这个状态。
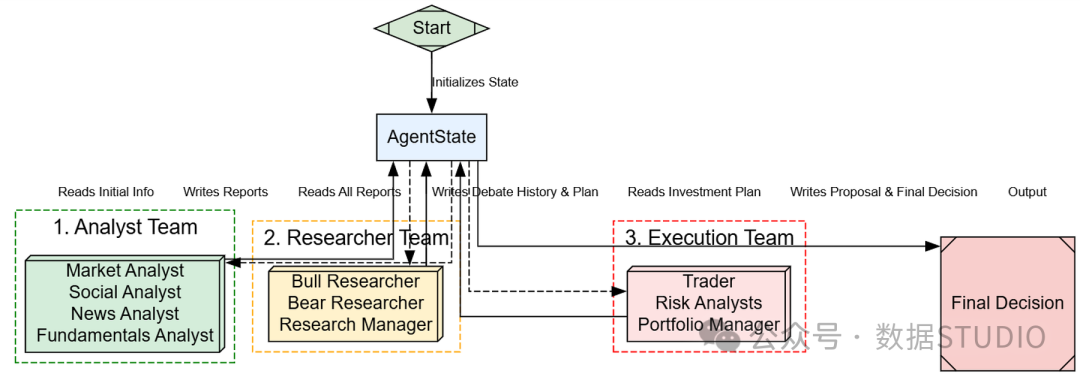
智能体状态的作用
我们将使用 Python 的 TypedDict 定义这个全局记忆的数据结构。这为我们提供了一个强类型、可预测的结构,对于管理复杂性非常重要。我们先从定义两个辩论团队的子状态开始。
from typing import Annotated, Sequence, List
from typing_extensions import TypedDict
from langgraph.graph import MessagesState
# 研究员团队辩论的状态,作为专用草稿板
class InvestDebateState(TypedDict):
bull_history: str # 存储多头智能体提出的论点
bear_history: str # 存储空头智能体提出的论点
history: str # 辩论的完整记录
current_response: str # 最近提出的论点
judge_decision: str # 主管的最终决策
count: int # 用于跟踪辩论轮数的计数器
# 风控团队辩论的状态
class RiskDebateState(TypedDict):
risky_history: str # 激进型风险承担者的历史记录
safe_history: str # 保守型智能体的历史记录
neutral_history: str # 平衡型智能体的历史记录
history: str # 风险讨论的完整记录
latest_speaker: str # 跟踪最后一个发言的智能体
current_risky_response: str
current_safe_response: str
current_neutral_response: str
judge_decision: str # 投资组合经理的最终决策
count: int # 风险讨论轮数计数器
InvestDebateState 和 RiskDebateState 作为专用草稿板。我们设计这种模式是为了保持状态的组织性,防止不同辩论相互干扰。history 字段将存储完整的对话记录,为后续智能体提供上下文,而 count 参数对于我们的图条件逻辑至关重要,它用于判断辩论何时结束。
现在,我们定义整合这些子状态的主 AgentState。
# 将在整个图中传递的主状态
# 它继承自 MessagesState,包含一个 'messages' 字段用于存储聊天历史
class AgentState(MessagesState):
company_of_interest: str # 我们正在分析的股票代码
trade_date: str # 分析的日期
sender: str # 跟踪最后修改状态的智能体
# 每个分析师将填充各自的报告字段
market_report: str
sentiment_report: str
news_report: str
fundamentals_report: str
# 辩论的嵌套状态
investment_debate_state: InvestDebateState
investment_plan: str # 研究主管制定的计划
trader_investment_plan: str # 交易员制定的可执行计划
risk_debate_state: RiskDebateState
final_trade_decision: str # 投资组合经理的最终决策
主 AgentState 现在是我们完整的数据模式。注意它包含了每个分析师的输出字段(如 market_report),并嵌套了我们刚刚定义的辩论状态。这种结构化方法使我们能够跟踪从原始数据到 final_trade_decision 的整个信息流。
构建智能体工具集与实时数据
智能体的能力取决于其工具。因此,我们需要一个 Toolkit,在其中定义智能体可以用来与外界交互的所有函数。这能让它们的推理建立在真实、最新的数据之上。
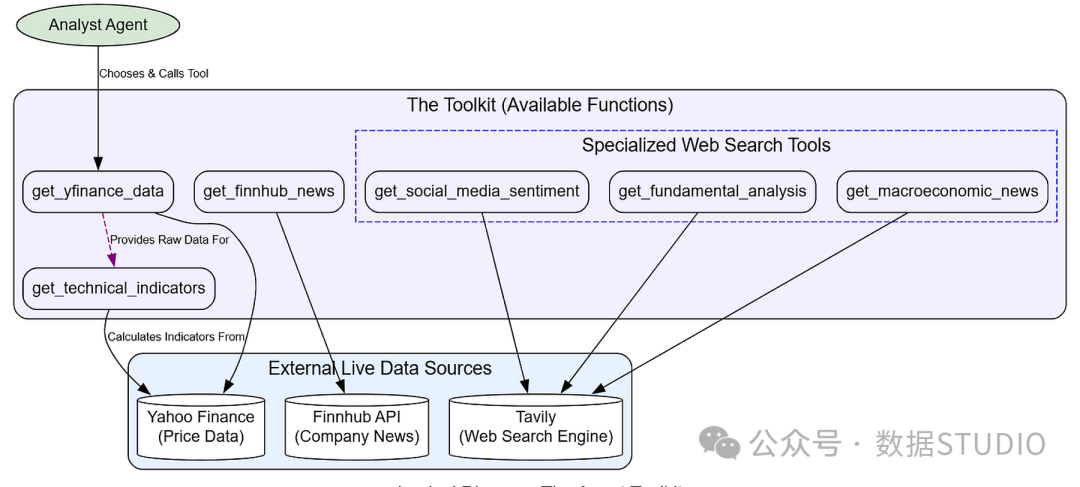
实时数据摄取
每个函数都使用 LangChain 的 @tool 装饰器,配合 Annotated 类型提示,提供了一个模式,供大语言模型理解该工具的用途和输入参数。我们先从一个获取原始历史价格数据的工具开始。
import yfinance as yf
from langchain_core.tools import tool
@tool
def get_yfinance_data(
symbol: Annotated[str, "公司股票代码"],
start_date: Annotated[str, "开始日期,格式为 yyyy-mm-dd"],
end_date: Annotated[str, "结束日期,格式为 yyyy-mm-dd"],
) -> str:
"""从 Yahoo Finance 获取指定股票代码的股价数据。"""
try:
ticker = yf.Ticker(symbol.upper())
data = ticker.history(start=start_date, end=end_date)
if data.empty:
return f"在 {start_date} 至 {end_date} 期间未找到符号 '{symbol}' 的数据"
return data.to_csv()
except Exception as e:
return f"获取 Yahoo Finance 数据时出错: {e}"
在这个函数中,Annotated 类型提示不仅对开发者有用,还为 LLM 提供了每个参数用途的描述(例如,symbol 应该是 "股票代码")。
我们以 .to_csv() 字符串的形式返回数据,这是一种 LLM 非常擅长解析的简单格式。接下来,我们需要一个工具,从原始数据中推导出常见的技术指标。
from stockstats import wrap as stockstats_wrap
@tool
def get_technical_indicators(
symbol: Annotated[str, "公司股票代码"],
start_date: Annotated[str, "开始日期,格式为 yyyy-mm-dd"],
end_date: Annotated[str, "结束日期,格式为 yyyy-mm-dd"],
) -> str:
"""使用 stockstats 库获取股票的关键技术指标。"""
try:
df = yf.download(symbol, start=start_date, end=end_date, progress=False)
if df.empty:
return "没有数据可计算指标。"
stock_df = stockstats_wrap(df)
indicators = stock_df[['macd', 'rsi_14', 'boll', 'boll_ub', 'boll_lb', 'close_50_sma', 'close_200_sma']]
return indicators.tail().to_csv()
except Exception as e:
return f"计算 stockstats 指标时出错: {e}"
这里我们使用 stockstats 库,因为它简单易用。我们选择了一组特定的常见指标(MACD、RSI 等),并只返回数据的 tail()。这是一个重要的实践考量,可以保持传递给 LLM 的上下文简洁相关,避免不必要的 token 消耗和成本。
接下来,使用 Finnhub API 获取公司特定新闻。
import finnhub
@tool
def get_finnhub_news(ticker: str, start_date: str, end_date: str) -> str:
"""从 Finnhub 获取指定日期范围内的公司新闻。"""
try:
finnhub_client = finnhub.Client(api_key=os.environ["FINNHUB_API_KEY"])
news_list = finnhub_client.company_news(ticker, _from=start_date, to=end_date)
news_items = []
for news in news_list[:5]: # 限制为 5 条结果
news_items.append(f"标题: {news['headline']}\n摘要: {news['summary']}")
return "\n\n".join(news_items) if news_items else "未找到 Finnhub 新闻。"
except Exception as e:
return f"获取 Finnhub 新闻时出错: {e}"
上述工具提供了结构化数据。对于市场情绪等难以量化的因素,我们需要一个通用的网络搜索工具。我们将使用 Tavily,并一次性初始化它以提高效率。
from langchain_community.tools.tavily_search import TavilySearchResults
# 一次性初始化 Tavily 搜索工具。我们可以为多个专用工具重用此实例。
tavily_tool = TavilySearchResults(max_results=3)
现在我们创建三个专用搜索工具。这是一个关键的设计选择。虽然它们都使用同一个 Tavily 引擎,但向 LLM 提供像 get_social_media_sentiment 这样的专用工具,而不是一个通用的 search_web,能简化其决策过程。当工具的用途明确且狭窄时,LLM 更容易选择正确的工具。
@tool
def get_social_media_sentiment(ticker: str, trade_date: str) -> str:
"""执行实时网络搜索,获取有关某只股票的社交媒体情绪。"""
query = f"关于 {ticker} 股票在 {trade_date} 前后的社交媒体情绪和讨论"
return tavily_tool.invoke({"query": query})
@tool
def get_fundamental_analysis(ticker: str, trade_date: str) -> str:
"""执行实时网络搜索,获取某只股票近期基本面分析。"""
query = f"关于 {ticker} 股票在 {trade_date} 前后发布的基本面分析和关键财务指标"
return tavily_tool.invoke({"query": query})
@tool
def get_macroeconomic_news(trade_date: str) -> str:
"""执行实时网络搜索,获取与股市相关的宏观经济新闻。"""
query = f"在 {trade_date} 影响股市的宏观经济新闻和市场趋势"
return tavily_tool.invoke({"query": query})
最后,我们将所有这些函数聚合到一个 Toolkit 类中,以便清晰、有序地访问。
# Toolkit 类将所有已定义的工具聚合到一个方便的对象中
class Toolkit:
def __init__(self, config):
self.config = config
self.get_yfinance_data = get_yfinance_data
self.get_technical_indicators = get_technical_indicators
self.get_finnhub_news = get_finnhub_news
self.get_social_media_sentiment = get_social_media_sentiment
self.get_fundamental_analysis = get_fundamental_analysis
self.get_macroeconomic_news = get_macroeconomic_news
# 实例化 Toolkit,使所有工具都可通过此对象访问
toolkit = Toolkit(config)
print("Toolkit 类已定义并使用实时数据工具实例化。")
至此,我们智能体行动的基础已搭建完毕。我们拥有一套全面的工具,使系统能够收集任何金融资产的丰富、多维度信息。
实现持续学习的长期记忆
为了让我们的智能体能够随着时间推移不断改进,它们需要长期记忆。要实现真正的学习,智能体必须能够反思过去的决策,并在未来遇到类似情况时回忆起这些经验教训。
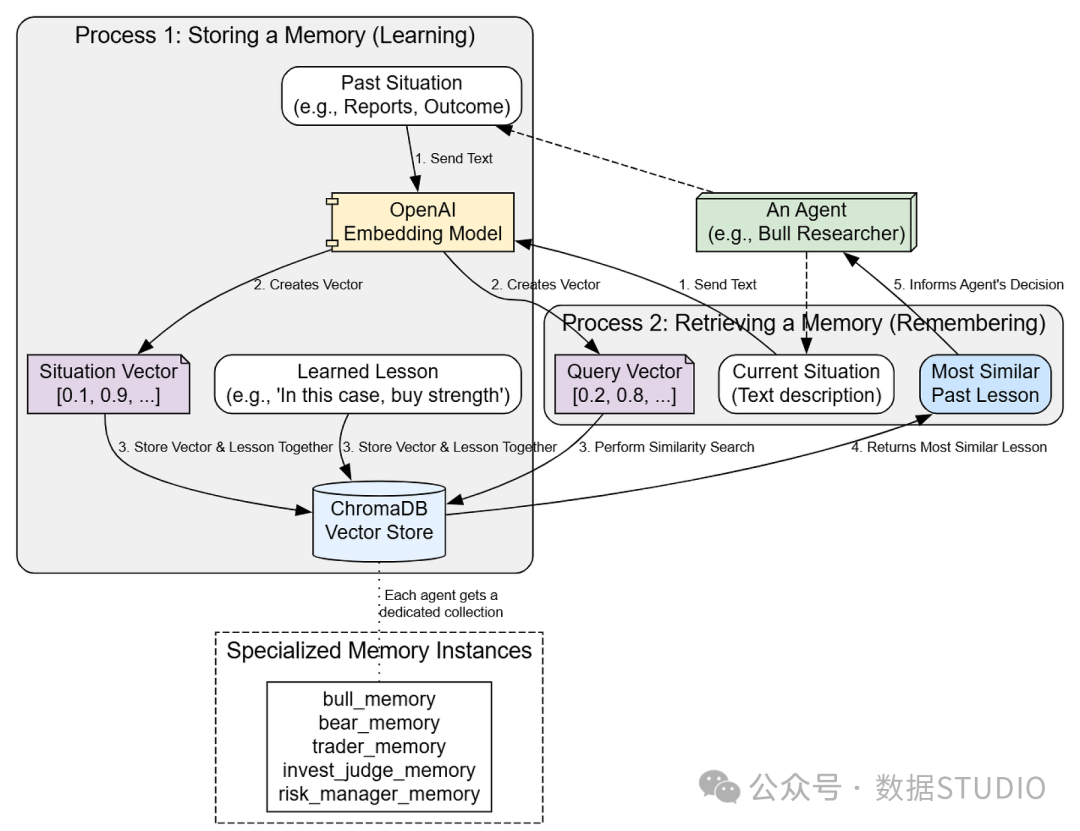
长期记忆流程
FinancialSituationMemory 类是这个学习循环的核心。它使用一个 ChromaDB 向量存储来保存过去情景的文本摘要以及从中汲取的经验教训。
import chromadb
from openai import OpenAI
# FinancialSituationMemory 类提供长期记忆功能,
# 用于存储和检索金融情景及对应的建议。
class FinancialSituationMemory:
def __init__(self, name, config):
# 使用 OpenAI 的小型嵌入模型对文本进行向量化
self.embedding_model = "text-embedding-3-small"
# 初始化 OpenAI 客户端(指向配置的后端地址)
self.client = OpenAI(base_url=config["backend_url"])
# 创建一个 ChromaDB 客户端(允许重置,便于测试)
self.chroma_client = chromadb.Client(chromadb.config.Settings(allow_reset=True))
# 创建一个集合(类似数据表)用于存储情景和建议
self.situation_collection = self.chroma_client.create_collection(name=name)
def get_embedding(self, text):
# 为给定的文本生成嵌入向量
response = self.client.embeddings.create(model=self.embedding_model, input=text)
return response.data[0].embedding
def add_situations(self, situations_and_advice):
# 将新的情景和推荐建议添加到记忆中
if not situations_and_advice:
return
# 通过偏移量确保 ID 唯一(防止后续添加新数据时冲突)
offset = self.situation_collection.count()
ids = [str(offset + i) for i, _ in enumerate(situations_and_advice)]
# 分离情景和对应的建议
situations = [s for s, r in situations_and_advice]
recommendations = [r for s, r in situations_and_advice]
# 为所有情景生成嵌入向量
embeddings = [self.get_embedding(s) for s in situations]
# 将所有内容存入 Chroma 向量数据库
self.situation_collection.add(
documents=situations,
metadatas=[{"recommendation": rec} for rec in recommendations],
embeddings=embeddings,
ids=ids,
)
def get_memories(self, current_situation, n_matches=1):
# 针对给定的查询,检索最相似的过去情景
if self.situation_collection.count() == 0:
return []
# 对当前情景进行嵌入
query_embedding = self.get_embedding(current_situation)
# 在集合中查询相似的嵌入向量
results = self.situation_collection.query(
query_embeddings=[query_embedding],
n_results=min(n_matches, self.situation_collection.count()),
include=["metadatas"], # 只返回建议部分
)
# 从匹配结果中提取推荐建议
return [{'recommendation': meta['recommendation']} for meta in results['metadatas'][0]]
我们来拆解一下关键方法。
__init__ 方法为每个智能体创建一个独立的 ChromaDB collection,为它们提供各自的私有记忆空间。add_situations 方法是学习发生的地方:它接收一个情景(上下文)和一个经验教训,生成情景的向量嵌入,并将两者存入数据库。metadatas 参数用于存储实际的经验教训文本,而 documents 则存储情景上下文。- 最后,
get_memories 是检索步骤。它接收 current_situation,生成 query_embedding,然后执行相似性搜索,找出最相关的历史经验。
现在,我们将为每个需要学习的智能体创建一个专属的记忆实例。
# 为每个需要学习的智能体创建专属的记忆实例
bull_memory = FinancialSituationMemory("bull_memory", config)
bear_memory = FinancialSituationMemory("bear_memory", config)
trader_memory = FinancialSituationMemory("trader_memory", config)
invest_judge_memory = FinancialSituationMemory("invest_judge_memory", config)
risk_manager_memory = FinancialSituationMemory("risk_manager_memory", config)
现在我们已经创建了五个独立的记忆实例。这种专业化非常重要,因为多头智能体学到的经验(例如“在强劲上升趋势中,估值担忧不那么重要”)可能并不适用于更为保守的“安全型风险分析师”。
通过为它们分配独立的记忆,我们确保检索到的经验与其角色高度相关。
至此,我们的环境、状态、工具和记忆都已定义完毕,系统的基础层已经完成。现在可以开始构建智能体本身了。
部署分析师团队,获取360度市场情报
基础就绪后,是时候引入第一个智能体团队——分析师团队了。这个团队是我们公司的情报收集部门。
成功的交易决策不能脱离背景孤立做出,它需要从多个角度对资产形成整体理解。
因此,我们将创建四名专业分析师,每人负责一个独特的领域。
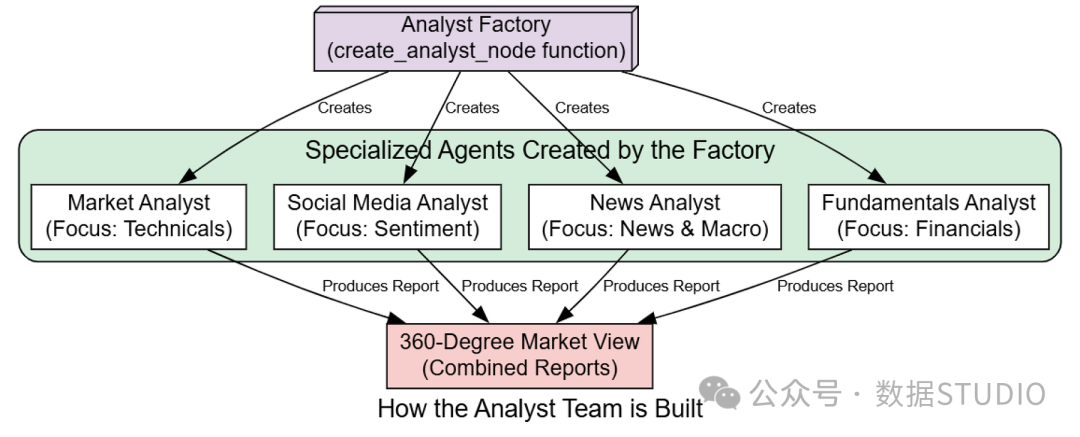
分析师工厂
它们的共同目标是生成全面、360度的股票及市场环境视图,为下一阶段的策略分析填充 AgentState 所需的原始情报。
为了避免重复代码,我们将首先构建一个“工厂”函数。这是一种强大的软件工程模式,允许我们基于通用模板创建每个独特的分析师节点。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 此函数是一个工厂,用于为特定类型的分析师创建 LangGraph 节点
def create_analyst_node(llm, toolkit, system_message, tools, output_field):
"""
创建分析师智能体的节点。
参数:
llm: 智能体将使用的大语言模型实例。
toolkit: 智能体可用的工具集。
system_message: 定义智能体角色和目标的特定指令。
tools: 从 toolkit 中选出的、允许该智能体使用的工具列表。
output_field: 该智能体最终报告将存入 AgentState 的键名。
"""
# 定义分析师智能体的提示模板
prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个乐于助人的 AI 助手,与其他助手协作。"
"使用提供的工具逐步回答问题。"
"如果无法完全回答也没关系;其他拥有不同工具的助手"
"会在你停下的地方继续帮助。尽你所能推进工作。"
"你可以使用以下工具: {tool_names}。\n{system_message}"
"供你参考,当前日期是 {current_date}。我们关注的股票是 {ticker}"),
# MessagesPlaceholder 允许我们传入对话历史
MessagesPlaceholder(variable_name="messages"),
])
# 为当前分析师部分填充具体的系统消息和工具名称
prompt = prompt.partial(system_message=system_message)
prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))
# 将指定的工具绑定到 LLM,告诉 LLM 它可以调用哪些函数
chain = prompt | llm.bind_tools(tools)
# 这是实际在图节点中执行的函数
def analyst_node(state):
# 使用当前状态中的数据填充提示模板的最后部分
prompt_with_data = prompt.partial(current_date=state["trade_date"], ticker=state["company_of_interest"])
# 使用当前状态中的消息调用链
result = prompt_with_data.invoke(state["messages"])
report = ""
# 如果 LLM 没有调用工具,说明它已经生成了最终报告
if not result.tool_calls:
report = result.content
# 返回 LLM 的响应以及最终报告,用于更新状态
return {"messages": [result], output_field: report}
return analyst_node
让我们来拆解这个工厂函数。create_analyst_node 是一个高阶函数,它返回另一个函数(analyst_node),后者将作为我们在 LangGraph 工作流中的实际节点。
system_message 参数至关重要;在这里我们注入每个分析师的独特“个性”和目标。tools 参数强制执行分工——市场分析师不能访问社交媒体工具,反之亦然。llm.bind_tools(tools) 调用是使智能体能够使用工具的关键。它为 LLM 提供了可用工具的架构信息,让它能够决定调用哪个工具。
有了工厂函数,我们就可以创建第一个专家:市场分析师。它的工作完全是量化的,专注于价格行为和技术指标。我们只给它配备完成这项任务所需的工具。
# 市场分析师:专注于技术指标和价格行为
market_analyst_system_message = "你是一名专门分析金融市场的交易助手。你的职责是选择最相关的技术指标来分析股票的价格行为、动量和波动性。你必须使用工具获取历史数据,然后生成一份包含你发现以及汇总表格的报告。"
market_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
market_analyst_system_message,
[toolkit.get_yfinance_data, toolkit.get_technical_indicators],
"market_report"
)
在这段代码中,我们定义了 market_analyst_system_message,为智能体赋予清晰的角色和目标。然后调用工厂,传入 quick_thinking_llm、toolkit、这条消息以及具体的工具列表 get_yfinance_data 和 get_technical_indicators。最后,我们指定其输出应保存到 AgentState 的 market_report 字段。
接下来是社交媒体分析师。它的角色是捕捉围绕某只股票的定性、通常难以预测的公众情绪。
# 社交媒体分析师:衡量公众情绪
social_analyst_system_message = "你是一名社交媒体分析师。你的工作是分析过去一周内与某家公司相关的社交媒体帖子和公众情绪。使用你的工具找到相关讨论,并撰写一份全面的报告,详细说明你的分析、见解以及对交易者的影响,包括一个汇总表格。"
social_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
social_analyst_system_message,
[toolkit.get_social_media_sentiment],
"sentiment_report"
)
这里我们定义了负责情绪分析的分析师。注意它的工具列表非常狭窄,只包含 get_social_media_sentiment。
这种专业化是多智能体设计的一个关键原则,确保每个智能体聚焦于自己的核心能力。
第三位专家是新闻分析师,负责提供公司特定和宏观经济的背景信息。
# 新闻分析师:覆盖公司特定新闻和宏观经济新闻
news_analyst_system_message = "你是一名新闻研究员,分析过去一周内的最新新闻和趋势。撰写一份关于当前世界状态、与交易和宏观经济相关的全面报告。使用你的工具进行全面分析,并提供详细的分析,包括一个汇总表格。"
news_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
news_analyst_system_message,
[toolkit.get_finnhub_news, toolkit.get_macroeconomic_news],
"news_report"
)
新闻分析师被赋予了两个工具。这是经过深思熟虑的选择:get_finnhub_news 提供微观层面、公司特定的信息,而 get_macroeconomic_news 提供宏观层面的背景。一份全面的新闻分析需要同时具备这两个视角。
最后,我们的基本面分析师将研究公司的财务健康状况。
# 基本面分析师:深入挖掘公司财务健康状况
fundamentals_analyst_system_message = "你是一名研究员,分析公司的基本面信息。撰写一份关于公司财务状况、内部人情绪和交易的全面报告,以全面了解其基本面健康状况,包括一个汇总表格。"
fundamentals_analyst_node = create_analyst_node(
quick_thinking_llm,
toolkit,
fundamentals_analyst_system_message,
[toolkit.get_fundamental_analysis],
"fundamentals_report"
)
理解这些智能体的工作方式很重要。它们使用一种称为 ReAct(推理与行动) 的模式。这不是单次 LLM 调用,而是一个循环:
- 推理: LLM 接收提示,决定是否需要使用工具。
- 行动: 如果需要,它生成一个
tool_call(例如 toolkit.get_yfinance_data(...))。
- 观察: 我们的图执行此工具,结果(数据)被传回 LLM。
- 重复: LLM 现在有了新信息,决定下一步——要么调用另一个工具,要么生成最终报告。
这个循环允许智能体自主完成复杂的多步数据收集任务。为了管理这个循环,我们需要一个辅助函数。
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_core.messages import HumanMessage
import datetime
from rich.console import Console
from rich.markdown import Markdown
# 初始化用于富文本打印的控制台
console = Console()
# 辅助函数,用于运行单个分析师的 ReAct 循环
def run_analyst(analyst_node, initial_state):
state = initial_state
# 从 toolkit 实例中获取所有可用的工具
all_tools_in_toolkit = [getattr(toolkit, name) for name in dir(toolkit) if callable(getattr(toolkit, name)) and not name.startswith("__")]
# ToolNode 是一个特殊的 LangGraph 节点,用于执行工具调用
tool_node = ToolNode(all_tools_in_toolkit)
# ReAct 循环最多执行 5 步推理和工具调用
for _ in range(5):
result = analyst_node(state)
# tools_condition 检查 LLM 的最后一条消息是否是工具调用
if tools_condition(result) == "tools":
# 如果是,执行工具并更新状态
state = tool_node.invoke(result)
else:
# 如果不是,说明智能体已完成,跳出循环
state = result
break
return state
run_analyst 函数编排了单个智能体的 ReAct 循环。tools_condition 是 LangGraph 的一个实用函数,用于检查智能体的最后一条消息。如果该消息包含 tool_calls 属性,则返回 "tools",将流程导向 tool_node 执行。否则,智能体已完成工作。
现在,让我们设置初始状态并运行第一个分析师。
TICKER = "NVDA"
# 使用最近日期获取实时数据
TRADE_DATE = (datetime.date.today() - datetime.timedelta(days=2)).strftime('%Y-%m-%d')
# 定义图运行的初始状态
initial_state = AgentState(
messages=[HumanMessage(content=f"分析 {TICKER} 在 {TRADE_DATE} 的交易机会")],
company_of_interest=TICKER,
trade_date=TRADE_DATE,
# 用默认空值初始化辩论状态
investment_debate_state=InvestDebateState({
'history': '', 'current_response': '', 'count': 0, 'bull_history': '', 'bear_history': '', 'judge_decision': ''
}),
risk_debate_state=RiskDebateState({
'history': '', 'latest_speaker': '', 'current_risky_response': '', 'current_safe_response': '', 'current_neutral_response': '', 'count': 0, 'risky_history': '', 'safe_history': '', 'neutral_history': '', 'judge_decision': ''
})
)
# 运行市场分析师
print("运行市场分析师...")
market_analyst_result = run_analyst(market_analyst_node, initial_state)
initial_state['market_report'] = market_analyst_result.get('market_report', '生成报告失败。')
console.print("----- 市场分析师报告 -----")
console.print(Markdown(initial_state['market_report']))
我们现在以英伟达(NVDA)股票为目标。首先需要运行市场分析师来观察市场,得到的结果如下。
# 运行市场分析师...
----- 市场分析师报告 -----
基于对 NVDA 的技术分析,该股票表现出强劲的看涨趋势。价格持续运行在 50 日和 200 日简单移动平均线之上,这两条均线均处于明确的上行趋势中。MACD 线位于信号线上方,确认了正向动量。RSI_14 处于高位但尚未进入超买区域,表明仍有进一步上涨的空间。布林带近期扩张,表明波动性增加,这通常伴随强劲的价格走势。总而言之,所有关键技术指标都指向持续的看涨力量。
| 指标 | 信号 | 洞察 |
|--------------------|------------|--------------------------------------------------------------|
| 移动平均线(50,200) | 看涨 | 确认了强劲、持续的上升趋势。 |
| MACD | 看涨 | 正向动量目前处于主导地位。 |
| RSI(14) | 强劲 | 表明强劲的买盘压力,但尚未耗尽。 |
| 布林带 | 扩张 | 暗示波动性增加,可能出现突破。 |
市场分析师已成功完成任务。通过查看 LangSmith 追踪,我们会看到一个两步过程:
- 首先,它调用了
get_yfinance_data 获取价格,然后利用这些数据调用 get_technical_indicators。
- 最终报告是一个清晰、结构化的摘要,包含表格,这正是其提示所要求的。这份报告现在存储在
initial_state['market_report'] 中。
市场分析师给了我们一个强劲的定量信号。现在,看看公众情绪是否与图表一致。
# 运行社交媒体分析师
print("\n运行社交媒体分析师...")
social_analyst_result = run_analyst(social_analyst_node, initial_state)
initial_state['sentiment_report'] = social_analyst_result.get('sentiment_report', '生成报告失败。')
console.print("----- 社交媒体分析师报告 -----")
console.print(Markdown(initial_state['sentiment_report']))
运行社交媒体分析师...
----- 社交媒体分析师报告 -----
针对 NVDA 的社交媒体情绪总体非常乐观。X(原 Twitter)和 Reddit 等平台上积极讨论量很大,主要围绕该公司在 AI 芯片市场的主导地位以及对强劲财报的预期。关键意见领袖和散户社区积极宣传“买入并持有”策略。有一些关于股票估值过高的零星讨论,但基本被正面共识所淹没。总体情绪对股价形成强力支撑。
| 平台 | 情绪 | 关键主题 |
|----------------|-------------|---------------------------------------------|
| X (Twitter) | 非常乐观 | AI 主导地位、分析师上调评级、产品热潮 |
| Reddit | 非常乐观 | “长期持有”心态、财报预期、网络迷因 |
社交媒体分析师证实了看涨论点。其报告基于实时 Tavily 网络搜索生成,捕捉到了围绕该股票的定性“热度”。这些非结构化数据现在被提炼为结构化报告,并添加到我们的 AgentState 中。
但我们需要通过收集新闻背景来验证这一确认。
# 运行新闻分析师
print("\n运行新闻分析师...")
news_analyst_result = run_analyst(news_analyst_node, initial_state)
initial_state['news_report'] = news_analyst_result.get('news_report', '生成报告失败。')
console.print("----- 新闻分析师报告 -----")
console.print(Markdown(initial_state['news_report']))
运行新闻分析师...
----- 新闻分析师报告 -----
NVDA 的新闻环境是积极的。来自 Finnhub 的公司特定新闻头条突出了新产品发布以及在汽车和企业 AI 领域的合作伙伴关系。更广泛的宏观经济新闻对科技股有利,近期通胀数据符合预期,缓解了对激进央行政策的担忧。过去一周没有关于 NVDA 或半导体行业的重大负面新闻。
| 新闻类别 | 影响 | 摘要 |
|-----------------|-----------|-----------------------------------------------------------------------|
| 公司特定 | 积极 | 新产品发布和战略合作伙伴关系表明持续增长。 |
| 宏观经济 | 中性偏多 | 稳定的通胀和利率前景提供了有利的背景。 |
新闻分析师的报告又增添了一层确认,表明公司特定新闻和宏观经济新闻均提供支持。该智能体正确地使用了分配给它的两个工具来构建这份全面的视图。
最后,我们来检查公司的基本面健康状况。
# 运行基本面分析师
print("\n运行基本面分析师...")
fundamentals_analyst_result = run_analyst(fundamentals_analyst_node, initial_state)
initial_state['fundamentals_report'] = fundamentals_analyst_result.get('fundamentals_report', '生成报告失败。')
console.print("----- 基本面分析师报告 -----")
console.print(Markdown(initial_state['fundamentals_report']))
运行基本面分析师...
----- 基本面分析师报告 -----
NVDA 的基本面状况非常强劲,尽管伴随着高估值。网络搜索结果证实,最近的财报持续超出分析师预期,数据中心收入呈爆炸式增长。毛利率和净资产收益率等关键指标处于行业领先水平。虽然市盈率较高,但非常高的远期增长率(PEG 比率更为合理)支撑了这一估值。公司资产负债表稳健,拥有大量现金储备。这是一家基本面扎实、处于强劲增长轨道上的公司。
| 指标 | 状态 | 洞察 |
|-------------------|-------------|----------------------------------------------------------------|
| 营收增长 | 异常强劲 | 数据中心业务因 AI 需求而呈现超高速增长。 |
| 利润率 | 优秀 | 显示出强大的定价能力和运营效率。 |
| 估值(市盈率) | 高 | 市场已经消化了未来显著的增长预期。 |
| 资产负债表 | 强劲 | 充足的现金储备为研发和收购提供了灵活性。 |
基本面分析师的最终报告确认了强劲的增长故事,但也首次引入了警示信号……
“高估值”和“较高的市盈率”。
这是一个关键的矛盾信息。尽管其他一切都看似看涨,但高估值带来了明确的风险。
现在,我们的 initial_state 对象已经满载了对 NVDA 市场定位的丰富、多维度视图。有了这些全面但明显存在矛盾的数据,我们的研究员团队已经准备就绪,将对其含义进行辩论,并形成连贯的策略。
构建多空研究员团队
汇总了四份分析师报告后,我们的 AgentState 已满载原始情报。然而,原始数据可能存在矛盾,需要进一步解读。正如我们所见,基本面分析师引入了一个关键风险——高估值——这与其它压倒性的积极信号形成了矛盾。
这正是研究员团队发挥作用的地方。
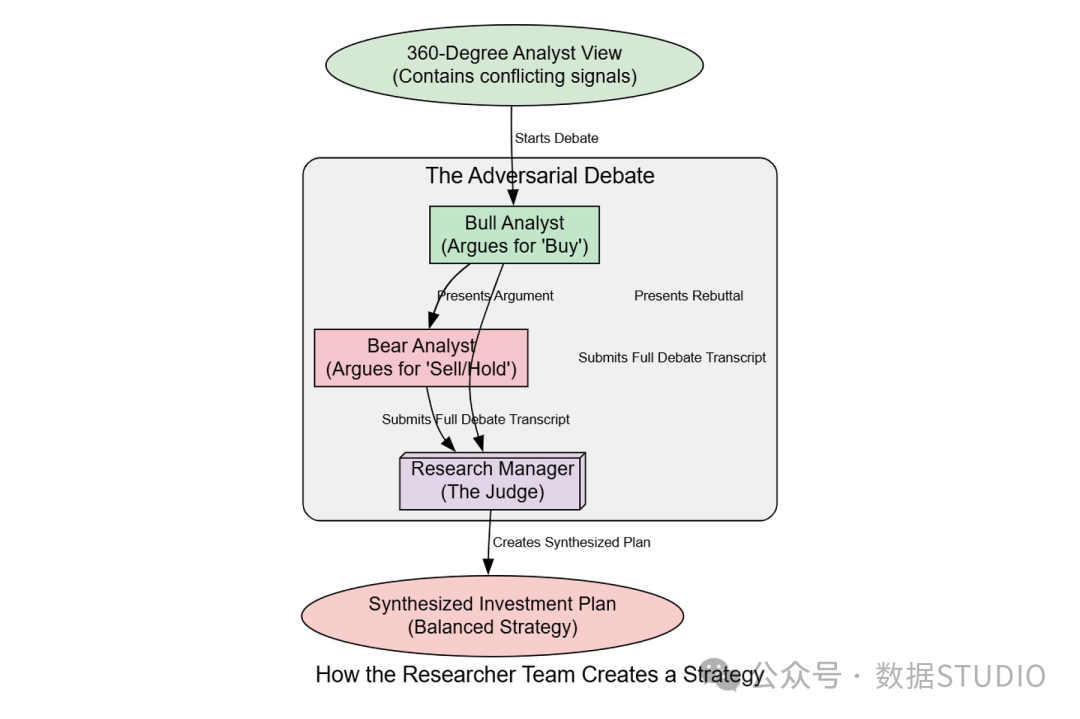
解决冲突
该团队的目标是通过组织两个对立观点——多头和空头——之间的结构化对抗性辩论,来批判性地评估证据。这个过程旨在防止确认偏误,并从正反两方面对投资论点进行压力测试。研究主管随后监督这场辩论,并承担关键任务:将各方论点综合成一个连贯一致的投资计划。
首先,我们需要为这些辩论者定义逻辑。我们将创建一个类似于分析师的工厂函数,来生成研究员节点。
# 此函数是一个工厂,用于为研究员智能体(多头或空头)创建 LangGraph 节点
def create_researcher_node(llm, memory, role_prompt, agent_name):
"""
创建研究员智能体的节点。
参数:
llm: 智能体将使用的大语言模型实例。
memory: 该智能体的长期记忆实例,用于从过往经验中学习。
role_prompt: 定义智能体角色(多头或空头)的具体系统提示。
agent_name: 智能体名称,用于日志记录和论点识别。
"""
def researcher_node(state):
# 首先,将所有分析师报告合并为一个摘要作为上下文
situation_summary = f"""
市场报告: {state['market_report']}
情绪报告: {state['sentiment_report']}
新闻报告: {state['news_report']}
基本面报告: {state['fundamentals_report']}
"""
# 从记忆中检索与过去相似情景相关的经验
past_memories = memory.get_memories(situation_summary)
past_memory_str = "\n".join([mem['recommendation'] for mem in past_memories])
# 构建完整的 LLM 提示
prompt = f"""{role_prompt}
以下是当前的分析状态:
{situation_summary}
对话历史: {state['investment_debate_state']['history']}
对方的最新论点: {state['investment_debate_state']['current_response']}
类似过去情景的反思: {past_memory_str or '未找到过往记忆。'}
基于以上所有信息,请以对话方式阐述你的论点。"""
# 调用 LLM 生成论点
response = llm.invoke(prompt)
argument = f"{agent_name}: {response.content}"
# 用新论点更新辩论状态
debate_state = state['investment_debate_state'].copy()
debate_state['history'] += "\n" + argument
# 更新该智能体(多头或空头)的专属历史记录
if agent_name == 'Bull Analyst':
debate_state['bull_history'] += "\n" + argument
else:
debate_state['bear_history'] += "\n" + argument
debate_state['current_response'] = argument
debate_state['count'] += 1
return {"investment_debate_state": debate_state}
return researcher_node
create_researcher_node 函数是我们辩论逻辑的核心。让我们看看它的关键组成部分:
situation_summary:它将所有四份分析师报告合并成一个文本块。这确保两位辩论者基于同一组事实展开讨论。past_memories:在形成论点之前,智能体会查询其 memory 对象。这是学习的关键步骤;它允许智能体回忆过往交易的教训,为当前立场提供参考。- 提示结构:提示经过精心构建,包含智能体的角色、分析师报告、完整的辩论历史、对手的最新论点以及自身的长期记忆。这种丰富的上下文使得复杂的反驳成为可能。
- 状态更新:函数返回更新后的
investment_debate_state,将新论点追加到 history 中,并更新 count 计数器。
现在,让我们为多头和空头定义具体的角色,并创建它们的节点。
# 多头角色:乐观,聚焦优势和增长
bull_prompt = "你是一名多头分析师。你的目标是论证投资该股票的理由。关注增长潜力、竞争优势以及报告中的积极指标。有效反驳空头的论点。"
# 空头角色:悲观,聚焦风险和弱点
bear_prompt = "你是一名空头分析师。你的目标是论证不投资该股票的理由。关注风险、挑战和负面指标。有效反驳多头的论点。"
# 使用工厂函数创建可调用的节点
bull_researcher_node = create_researcher_node(quick_thinking_llm, bull_memory, bull_prompt, "Bull Analyst")
bear_researcher_node = create_researcher_node(quick_thinking_llm, bear_memory, bear_prompt, "Bear Analyst")
辩论者就绪后,我们需要一位裁判。研究主管智能体将审阅完整的辩论记录,并生成最终综合的投资计划。这是一项高风险的推理任务,因此我们将使用强大的 deep_thinking_llm。
# 此函数创建研究主管节点
def create_research_manager(llm, memory):
def research_manager_node(state):
# 提示指导主管扮演裁判和综合者的角色
prompt = f"""作为研究主管,你的职责是批判性地评估多头和空头分析师之间的辩论,并做出最终决定。
总结关键论点,然后给出明确的建议:买入、卖出或持有。为交易员制定详细的投资计划,包括你的理由和策略行动。
辩论历史:
{state['investment_debate_state']['history']}"""
response = llm.invoke(prompt)
# 输出是最终的投资计划,将传递给交易员
return {"investment_plan": response.content}
return research_manager_node
# 创建可调用的主管节点
research_manager_node = create_research_manager(deep_thinking_llm, invest_judge_memory)
print("研究员和主管智能体的创建函数现已可用。")
现在,让我们模拟辩论。我们将按照配置中指定的 max_debate_rounds 运行循环。每一轮,多头先陈述论点,然后空头进行反驳,每轮结束后状态都会更新。
# 使用分析师部分结束时的状态
current_state = initial_state
# 循环执行配置中定义的辩论轮数
for i in range(config['max_debate_rounds']):
print(f"--- 投资辩论第 {i+1} 轮 ---")
# 多头先发言
bull_result = bull_researcher_node(current_state)
current_state['investment_debate_state'] = bull_result['investment_debate_state']
console.print("\n**多头的论点:**")
# 解析响应,只打印新论点
console.print(Markdown(current_state['investment_debate_state']['current_response'].replace('Bull Analyst: ', '')))
# 然后空头反驳
bear_result = bear_researcher_node(current_state)
current_state['investment_debate_state'] = bear_result['investment_debate_state']
console.print("\n**空头的反驳:**")
console.print(Markdown(current_state['investment_debate_state']['current_response'].replace('Bear Analyst: ', '')))
print("\n")
# 循环结束后,将最终辩论状态存回主 initial_state
initial_state['investment_debate_state'] = current_state['investment_debate_state']
--- 投资辩论第 1 轮 ---
**多头的论点:**
NVDA 的论据坚不可摧。所有维度都呈现出完美的一致性:技术面显示清晰持续的上升趋势,基本面由代际性的 AI 繁荣驱动,社交媒体情绪极为乐观,新闻周期也全是利好。每一份数据都指向同一个结论。这是一个在具有长期增长潜力的领域中全面发力的市场领导者。不买入这只股票,就是无视当今市场最明显的趋势。
**空头的反驳:**
我的对手看到了一个完美的图景,但我看到的是一只定价已充分反映未来、容错空间极小的股票。高市盈率是一个重大隐患。“极度看涨”的情绪是市场狂热的典型信号,往往预示着大幅回调。虽然基本面目前强劲,但半导体行业以周期性著称。任何 AI 支出放缓或竞争加剧的迹象,都可能导致这只股票大幅下跌。明智的策略是等待显著回调后再建仓,而不是在历史高点追涨。
--- 投资辩论第 2 轮 ---
**多头的论点:**
空头关于周期性的论点已经过时。AI 革命不是一个周期;它是全球经济的结构性转变,而 NVDA 正在为其提供必需的硬件。在这种动能的股票上等待“显著回调”,历史上一直是失败的策略。估值高是因为增长是代际性的。我们应该买入强势,而不是等待可能永远不会出现的弱势。
**空头的反驳:**
将 AI 繁荣称为非周期性纯属臆测。所有行业,尤其是科技行业,都会经历繁荣与萧条的周期。即使长期趋势向上,从当前水平面临 30-40% 回撤的风险也非常真实。当前价格已经反映了未来多年的增长。建议“持有”可以让我们规避显著的下行风险,同时等待更有利的风险回报入场点。现在买入是赌博,不是投资。
输出显示我们的辩论运行完美。
- 在第一轮中,多头基于积极数据的一致性,发表了有力的开场陈述。空头立即抓住分析师报告中唯一的负面信号——高估值——进行反击。
- 在第二轮中,辩论者进行了直接的反驳。多头通过重新定义风险(“结构性转变”)来淡化风险,而空头则进一步强调风险,量化了潜在的下行空间(“30-40% 的回撤”)。
这场辩论成功地揭示了投资案例的核心矛盾:强劲的动量 vs. 显著的估值风险。现在,完整的辩论记录已准备好,供研究主管综合成最终计划。
print("运行研究主管...")
# 主管接收包含完整辩论历史的最终状态
manager_result = research_manager_node(initial_state)
# 主管的输出存储在 'investment_plan' 字段中
initial_state['investment_plan'] = manager_result['investment_plan']
console.print("\n----- 研究主管的投资计划 -----")
console.print(Markdown(initial_state['investment_plan']))
----- 研究主管的投资计划 -----
在审阅了热烈的辩论后,多头的核心论点——NVDA 是一个结构性增长市场中的代际领导者——更具说服力。空头提出的关于估值和周期性风险的担忧是有效且重要的,但这些担忧被公司当前卓越的财务表现和市场地位所压倒。
**建议:买入**
**理由:** 卓越的基本面、强劲的技术动量以及利好的新闻和情绪环境共同构成了建立多头仓位的强有力依据。目前,等待回调而错失进一步上涨的风险,似乎大于估值驱动的回调风险。
**策略行动:** 我建议采用分步建仓的方式,以管理空头所强调的风险。在当前价格建立部分仓位。如果股票出现小幅回调至 50 日均线附近,可将其视为加仓机会。应在 200 日均线下方设置明确的止损,以防范重大趋势反转。
我们的研究主管不仅仅是选择一方,而是创造了一个新策略。它支持多头的 “买入” 建议,但通过提出“策略行动”(如分步建仓和明确的止损)明确纳入了空头的担忧。这个细致的计划比任何一位辩论者的个人立场都更加实用和风险可控。
有了研究团队清晰的投资计划,工作流现在转向以执行为导向的智能体。
创建交易员与风控智能体
有了研究主管清晰的投资计划,工作流从策略分析转向以执行为导向的智能体。该计划虽然经过深思熟虑,但仍然是一份高级别文档。它需要被转化为可在市场中执行的具体交易提案。
这就是交易员智能体的工作。一旦交易员制定出提案,它将被传递给风控团队进行最终审查。在这里,具有不同风险偏好的智能体——激进型、保守型和中性型——对该计划进行辩论,确保在动用资金之前,所有角度都已被考虑。
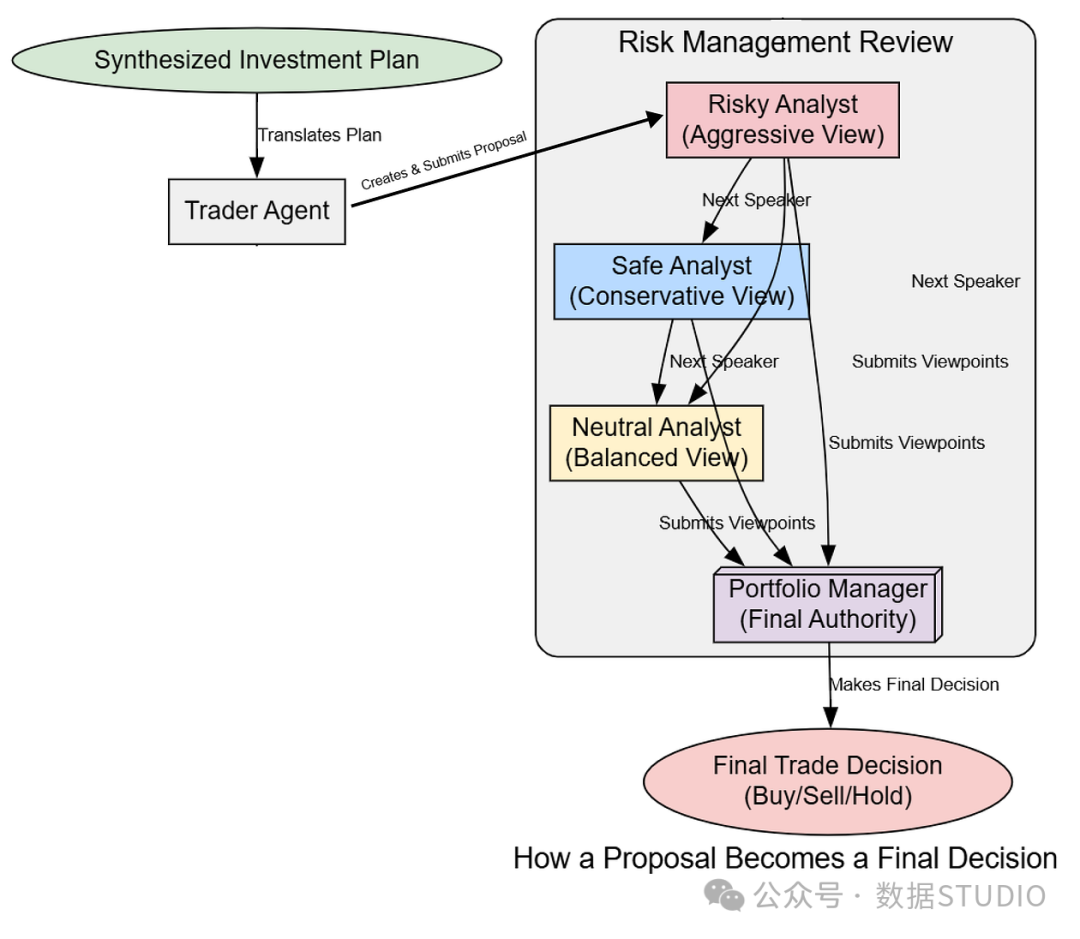
交易与风控
首先,让我们为交易员智能体定义逻辑。其主要角色是将详细的 investment_plan 提炼成简洁、可执行的提案。一个关键要求是其响应必须以特定的、机器可读的标签结尾。
import functools
# 此函数创建交易员智能体节点
def create_trader(llm, memory):
def trader_node(state, name):
# 提示很简单:根据计划创建提案
# 关键指令是强制性的结尾标签
prompt = f"""你是一名交易智能体。根据提供的投资计划,创建一个简洁的交易提案。
你的响应必须以 'FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL**' 结尾。
拟议投资计划: {state['investment_plan']}"""
result = llm.invoke(prompt)
# 输出更新状态,包含交易员的计划和发送者标识
return {"trader_investment_plan": result.content, "sender": name}
return trader_node
这个交易员智能体的设计聚焦于清晰和可执行性。提示中最关键的部分是指令以 FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** 结尾。这不仅是为了人类可读性,更重要的是创建了一个可预测的模式,便于下游流程(如稍后的信号提取器)可靠解析。
接下来,我们将为风控辩论者构建工厂函数。与我们的其他智能体类似,这个函数将为三个风控角色创建节点。这里的逻辑更为复杂,因为每个智能体需要了解对手的最新论点,以便进行恰当的反驳。
# 此函数是创建风控辩论者节点的工厂
def create_risk_debator(llm, role_prompt, agent_name):
def risk_debator_node(state):
# 首先,从状态中获取另外两个辩论者的论点
risk_state = state['risk_debate_state']
opponents_args = []
if agent_name != 'Risky Analyst' and risk_state['current_risky_response']: opponents_args.append(f"激进型: {risk_state['current_risky_response']}")
if agent_name != 'Safe Analyst' and risk_state['current_safe_response']: opponents_args.append(f"保守型: {risk_state['current_safe_response']}")
if agent_name != 'Neutral Analyst' and risk_state['current_neutral_response']: opponents_args.append(f"中性型: {risk_state['current_neutral_response']}")
# 构建包含交易员计划、辩论历史和对手论点的提示
prompt = f"""{role_prompt}
以下是交易员的计划: {state['trader_investment_plan']}
辩论历史: {risk_state['history']}
对手的最新论点:\n{'\n'.join(opponents_args)}
请从你的角度批判或支持该计划。"""
response = llm.invoke(prompt).content
# 用新论点更新风控辩论状态
new_risk_state = risk_state.copy()
new_risk_state['history'] += f"\n{agent_name}: {response}"
new_risk_state['latest_speaker'] = agent_name
# 将响应存储在该智能体的特定字段中
if agent_name == 'Risky Analyst': new_risk_state['current_risky_response'] = response
elif agent_name == 'Safe Analyst': new_risk_state['current_safe_response'] = response
else: new_risk_state['current_neutral_response'] = response
new_risk_state['count'] += 1
return {"risk_debate_state": new_risk_state}
return risk_debator_node
create_risk_debator 中的逻辑是实现真正多方辩论的关键。通过动态构建 opponents_args 列表,我们确保每个智能体直接回应其他参与者,而不是孤立地陈述观点。
状态更新也更加精细,填充了 current_risky_response 等字段,以便其他智能体在下一轮访问。
现在,我们为三个风控智能体定义具体的角色。这种对抗性设置——一个激进、一个保守、一个平衡——旨在从各个角度对交易员的计划进行压力测试。
# 激进型角色:主张追求高回报,即使意味着承担更高风险
risky_prompt = "你是一名激进型风险分析师。你主张高回报机会和大胆策略。"
# 保守型角色:优先考虑资本保值
safe_prompt = "你是一名保守型风险分析师。你优先考虑资本保值和最小化波动性。"
# 中性型角色:提供平衡、客观的视角
neutral_prompt = "你是一名中性风险分析师。你提供平衡的视角,权衡收益和风险。"
定义了智能体逻辑后,我们现在可以为工作流的这一部分实例化所有可调用的节点。
# 创建交易员节点。使用 functools.partial 预填充 'name' 参数
trader_node_func = create_trader(quick_thinking_llm, trader_memory)
trader_node = functools.partial(trader_node_func, name="Trader")
# 使用各自的提示创建三个风控辩论者节点
risky_node = create_risk_debator(quick_thinking_llm, risky_prompt, "Risky Analyst")
safe_node = create_risk_debator(quick_thinking_llm, safe_prompt, "Safe Analyst")
neutral_node = create_risk_debator(quick_thinking_llm, neutral_prompt, "Neutral Analyst")
现在,让我们在上一节生成的 investment_plan 上运行交易员智能体。
print("运行交易员...")
# 将当前状态传递给交易员节点
trader_result = trader_node(initial_state)
# 用交易员的输出更新状态
initial_state['trader_investment_plan'] = trader_result['trader_investment_plan']
console.print("\n----- 交易员的提案 -----")
console.print(Markdown(initial_state['trader_investment_plan']))
运行交易员...
----- 交易员的提案 -----
研究主管分步建仓的计划是审慎的,并得到了全面分析的有力支持。这种方法使我们能够参与明确的上升趋势,同时管理与股票高估值相关的风险。
我将在开盘时执行初始 50% 仓位的建仓。限价单将设置在回调至 50 日均线时,用于增加剩余 50% 的仓位。将在 200 日均线下方设置硬止损,以保护资本免受重大市场反转的影响。
最终交易提案:**买入**
交易员的输出非常出色,表明它已成功将研究主管的策略指导转化为具体的、可执行的计划,并附带了具体参数(50% 仓位、入场/出场点)。关键的是,它还包含了 FINAL TRANSACTION PROPOSAL 标签,使其核心建议明确无误。
这个提案现在将提交给风控团队进行辩论。
print("--- 风险管理辩论第 1 轮 ---")
risk_state = initial_state
# 按照配置中指定的轮数运行辩论(当前为 1 轮)
for _ in range(config['max_risk_discuss_rounds']):
# 激进型分析师先发言
risky_result = risky_node(risk_state)
risk_state['risk_debate_state'] = risky_result['risk_debate_state']
console.print("\n**激进型分析师的观点:**")
console.print(Markdown(risk_state['risk_debate_state']['current_risky_response']))
# 然后保守型分析师发言
safe_result = safe_node(risk_state)
risk_state['risk_debate_state'] = safe_result['risk_debate_state']
console.print("\n**保守型分析师的观点:**")
console.print(Markdown(risk_state['risk_debate_state']['current_safe_response']))
# 最后中性型分析师发言
neutral_result = neutral_node(risk_state)
risk_state['risk_debate_state'] = neutral_result['risk_debate_state']
console.print("\n**中性型分析师的观点:**")
console.print(Markdown(risk_state['risk_debate_state']['current_neutral_response']))
# 用最终的辩论记录更新主状态
initial_state['risk_debate_state'] = risk_state['risk_debate_state']
--- 风险管理辩论第 1 轮 ---
**激进型分析师的观点:**
分步建仓的计划过于保守。所有数据都指向即时且持续的强势。只建立 50% 的仓位,我们是在主动放弃利润。等待可能永远不会出现的回调,其机会成本才是最大的风险。我主张在开盘时建立 100% 的全仓,以最大化我们对这个明显赢家的敞口。
**保守型分析师的观点:**
全仓将是鲁莽的。该股票交易在估值高位,情绪狂热——这是典型的大幅回调前兆。交易员从 50% 仓位开始的计划是一个明智的折中方案,但我会主张设置更紧的止损,也许就在 50 日均线下方,以保护近期收益。在这只波动性较大的股票上,资本保值必须是我们的首要任务。
**中性型分析师的观点:**
交易员的计划非常出色,无需修改。它完美地平衡了激进型分析师对上行参与的渴望与保守型分析师对风险的合理担忧。在高动量股票中,50% 的分步建仓加上明确的止损,正是审慎仓位管理的教科书式范例。它让我们参与行情的同时管理下行风险。我完全认可原计划。
风控辩论的输出清楚地展示了多角色方法的价值。激进型分析师推动更激进的行动(“100% 全仓”),保守型分析师推动更严格的控制(“更紧的止损”),而中性型分析师则验证了交易员的计划是一个平衡良好的折中方案。这场辩论有效地阐明了风险考量的完整光谱。
参考资料
[1] Finnhub: https://finnhub.io/
[2] Tavily: https://www.tavily.com/
本文通过 LangGraph 构建了一个完整的多智能体深度交易系统,涵盖了情报采集、对抗性辩论、风险管理和最终决策的全流程。如果你对 智能体 开发感兴趣,欢迎访问 云栈社区 交流更多实践经验。

 发表于 2026-5-10 02:22:50
|
查看: 105|
回复: 0
发表于 2026-5-10 02:22:50
|
查看: 105|
回复: 0
