真实业务场景下,多轮交互式 Agent RL 从 Demo 走向 Scaling,最棘手的问题莫过于长程任务(Long‑horizon tasks)上端到端解决率的断崖式衰减——单纯堆算力或增加交互步数很难扭转。
本文尝试拆解长序列任务中各类可能的原因,介绍值得参考的思路与论文,并分享一些工程实践上的 trick。考虑到该领域仍在快速演进,这里抛砖引玉,期待后续更多的补充。
01 长程任务的端到端难度
即便先不谈 RL 或训练,普通 Agent 架构在长程问题下的基线性能就已相当脆弱。
以 N 步 ReAct 范式的 Agent 为例:假设单轮正确率 95%,且各轮独立同分布,那么端到端成功率会随步数急剧下滑——N=10 时仅剩 60%,N=50 时更跌至 7%。现实中要更严峻,逐个审视 Agent 架构的假设:
- 独立性并不成立:Agentic RL 中步骤之间存在依赖,错误与幻觉在上下文中累积传播,容易让 Agent 偏离主线或持续积累错误直至崩溃。
- 后续轮次难以维持同等正确率:ReAct 模式本身对 token 消耗巨大。步数越多,有效信息密度越低,早期指令的权重随 token 增长而被稀释,正确率自然难以保持。
- 上下文窗口的实际有效长度:当前基础模型的标称 context window 和真正可用的记忆窗口仍有差距。VLA 或 GUI 场景下的高频视觉输入会加重冗余。
- 输出稳定性的考验:模型输出具有概率性,单步正确不等于稳定输出。若我们说的单步正确率是 pass@1,鲁棒性可能不足,还需要 verifier 来提升单步可靠度——否则 95% 的 pass@1 也不等于稳定。
当然,这只是直观推演。很多复杂任务(如 DeepResearch)本身留有冗余和试错空间,并非每一步都需精确无误,但核心难题并未消失。
02 Agentic RL 的长程痛点
Agentic RL 中,长序列任务不仅要面对 Agent 架构本身的瓶颈,还要叠加 RL 学习机制带来的挑战,可从两方面看:
理论层面:
- 奖励稀疏且延迟:任务越长探索空间越大,outcome reward 很难及时有效地激励。
- 信用分配不平衡:长程行为的权重被均摊或衰减,算法难以实现真正局部的有效 Credit Assignment。
工程层面:
- MoE 激活偏差:长程任务下,MoE 模型训练与推理时激活 gate 的不一致性 Gap 会被放大并累积,导致训练更不稳定。
- Off‑policy 的工程折衷:长尾效应使训练效率下降,长样本更容易被分解、截断、分开推理,导致有效样本稀缺;或因策略版本更新使 Off‑policy 性质增强,最终梯度估计更不准,训练陷入不稳定。
03 优化长程问题是个系统工程
缓解上下文增长:Context Manager
直观的工程思路是利用 Context Manager 简化步骤或压缩序列,本质是对 memory 的各种 trick 再做一次迁移。
经典策略:
- 压缩 CoT:长/短/空 CoT 混合训练,或引入类似 KIMI 的过度思考惩罚。
- 滑窗机制:仅保留最近几轮的 Obs & Results。
- 记忆剪枝:摒弃纯粹的 Append‑only,引入 Working Memory 与 Episodic Memory,每隔 K 步生成 State Summary 来替换原始对话历史。
- 文件外挂:类似 Manus 的做法,将较长输出 Offload 到 Notebook 或文件,建模为工具调用而不占用 Prompt Token(AgentMem, FoldGRPO 等)。
但要注意,所有修改会话历史的操作本质上都改变了序列的概率分布,可能导致训练梯度不准,引入新问题。
训练效率、稳定性与样本稀缺
之前在 AgentRL:工业级 Agentic RL 训练对比选型指南 中分析过同步与异步模式的折衷,两种模式都会导致长样本相对稀缺:
- 同步模式:若设置较高轮次上限,Long‑horizon trajectory 会严重拖慢整体 Rollout 速度;若设置较低,最有价值的长轨迹又会被截断。除非通过精细调度(短任务打包、长轨迹预测优先),否则长样本在 Batch 中极其稀少。
- 异步模式:训推分离引发严重的 Off‑policy 问题。Long trajectory 被旧版本 Policy 采样的概率远高于 Short trajectory,极易导致训练不收敛;即使加入 staleness 控制,同样会造成长样本稀缺。
解决思路的核心还是长样本的推理提效(具体做法参见前述博客,不再重复),以便在权衡后仍能放大最大交互次数上限,获取更长的 trajectory。
此外,在长程任务中,Off‑policy 性质、训推框架差异等细节都会被进一步放大。RL 训练效果与稳定性的关键,往往隐藏在 Rollout 与 Train 的细微不一致中——无论是 MoE 还是 long trajectory 训练,都可追溯到训推引擎在参数、配置、FP16/BF16、tokenizer、MoE 专家激活等细节差异(更具体的可参考 https://fengyao.notion.site/off-policy-rl )。相应的解决思路就是逐一对齐训推差异:在 MoE 上参考 R3(Rollout Routing Replay)记录回放、GSPO 等方法,降低概率分布层面的影响。
长程奖励稀疏与延迟
解决奖励稀疏的工程手段无非是各种形式的 Reward Engineering,今年各场景下想必已完成一轮遍历。核心思路包括:
- 引入中间奖励(PRM):利用更强模型(如 GPT‑4)或人工标注数据训练 Reward Model,对 Agent 每一步进行 Verify。
- 场景先验:例如 Tool Use 的 AST 解析奖励、Coding 任务的单元测试奖励、Plan Milestone 奖励。
- 课程学习:类似 NTK 的思路,先通过短序列任务拿到有效奖励,再逐步放开任务复杂度、Context Windows 和 Turns 约束。
长程奖励分配
这一点尤其值得展开。当前 GRPO 在 Episode 级别进行归一化后再反推到每个 Token,在长短不一的 Batch 中存在几个明显问题:
- Token/Turn 稀释:Long trajectory 的每个 Token/Turn 效用被长度稀释,在整 batch 中的权重反而不如 Short trajectory(明显不合理)。
- 关键步骤平均化:关键步骤与大量冗余步骤获得相同的奖励,等于吃大锅饭,无法形成有效激励;步数越多,这种现象越严重。GAE 在长序列下的高方差更会导致训练不收敛。
- 虚假的 PRM:虽然 PRM 奖励过程,但有些实现将其累加成 ORM 再平均分配,意味着并未真正对每个步骤和关键 token 给予区别对待。
主要的改进方向是在 Advantage Normalization 上加入长度感知的调整,例如:
- 奖励再分配:梯度计算时根据 PRM 对最终 ORM 的贡献重新平衡权重,或者仅奖励关键 token。
- 基于部分轨迹分组:若不同轨迹的 PRM 具有可比较性(如奖励的 milestone 重复),更合理的思路可能是按部分轨迹分组与计算,如 GiGPO(这会不会是 DQN state‑based value estimation 的文艺复兴?)。
- 长度自适应 Advantage Normalization:类似 DAPO 对 Token 级别长度正则化的思路,对 Turn 级别长度进行正则;或采用长度自适应 GAE(Length‑adaptive GAE)动态调整 λ。
对于更长的思维链,算法自动使用更大的 λ:
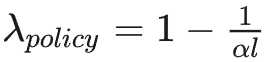
确保早期推理步骤能收到来自最终奖励的反馈信号(VAPO 是基于 PPO 的改进,但思路可以借鉴)。
鲁棒性与自我纠错
Agent 自身也会导致长程任务的鲁棒性较差——任何一次偏离方向的轮次,都可能让任务进度完全丢失或意图理解彻底漂移。使用 vibe coding 时或许深有体会:一旦某轮崩坏,后续越说越离谱,只好另起炉灶(这确实不好解决,所以 TRAE 的工程实践直接建议大家多 commit、多开新对话)。
实践中发现,长程问题的大部分 badcase 可归结为首轮出错。这可能与具体场景有关,也可能具有共性特征:
- 首轮仍处在理解意图/规划阶段,错误的调用或搜索方向往往意味着用户意图不清晰、模型理解偏差、规划失误,更容易引发后续连环错误;
- 受 Attention 顺序影响,靠前或靠后位置的文本通常具有较高权重,首轮与前一轮的错误返回对下一轮影响最大;
- 首轮出错容易导致随后连续几轮陷入推测与试错,轨迹越来越难回到正轨。
一些简单有效的工程技巧包括:错误轨迹剪枝、模拟环境优化、意图复述以缓解意图偏移、纠错负样本合成。
04 有限的游戏与无限的游戏
James Carse 在《有限与无限的游戏》中写道:“有限的游戏,其目的在于赢得胜利;无限的游戏,却旨在让游戏永远进行下去。”
前面讨论的种种长程问题,本质上都将 Agent 任务视作交互次数较长的有限游戏——总有一个最终的 verifiable episode reward,总有一个明确的意图,也总会有结束的时刻。当前 99% 的 Agent 任务确实是有限游戏,我们上述的工程技巧也都是在短任务思维上的迁移与缓解。
但真实世界果真如此吗?在 Minecraft 这样的开放世界中,在与豆包对话或情感陪伴里,在向 AI 寻求哲学思考或创意交互式探索时,在具身智能持续执行的 VLA 任务中,Agent 面对的更像是无限游戏——边界模糊且不断变化,规则随互动演变,没有终点。
这种差异意味着,无限游戏绝非有限游戏的叠加与组合,RL 的设计哲学或许也需要根本性的转变。在无限游戏中,若缺乏全局目标的指引,只把任务看作一系列阶段性目标的加和、分别优化战术层面,很容易“赢得战斗,输掉战争”。例如,把每一次对话当作一个 Episode,目标是让用户当下点赞,长期结果却是 Agent 变得谄媚、无法提供有效信息,最终用户厌烦。
当外部环境无法给出定义清晰、前后一致的反馈信号时,或许需要引入 Intrinsic Reward(内在奖励)——更多依靠自我反思、信息增益等多样化的内部奖励系统来驱动 Agent。无限游戏必须始终保持一定的 Exploration/Entropy 来应对 Env Distribution Shift,今天的最优解明天可能就是死路,目标不是当下的 reward maximization。
这同样是一个有趣且值得深思的方向。真正的 Long‑horizon 不仅仅是 Step 数的增加,更是世界观的维度跃迁——除了如何取胜,还有如何让交互持续产生价值,让这场游戏永远进行下去。
作者:乞力马扎罗雪人
来源:https://zhuanlan.zhihu.com/p/1996314343483130133
 发表于 2026-5-10 03:28:37
|
查看: 140|
回复: 0
发表于 2026-5-10 03:28:37
|
查看: 140|
回复: 0
