龙哥推荐理由:
当RLHF遇上“模糊任务”,传统RLVR那一套“逻辑验证”就失灵了。本文提出在线自然语言反馈(Online NLF)这一新范式,通过迭代优化代理奖励模型,巧解“可扩展监督”难题。更有意思的是,微调方法仅用10-20倍专家样本就几乎恢复了100%的性能,数据效率巨幅提升。无论你是搞大模型对齐,还是对“弱监督强模型”感兴趣,这篇论文都值得细品。
原论文信息如下:
Anthropic又出新作啦!文章开始之前,先放一张整篇论文的“成绩单”,帮大家快速get重点:
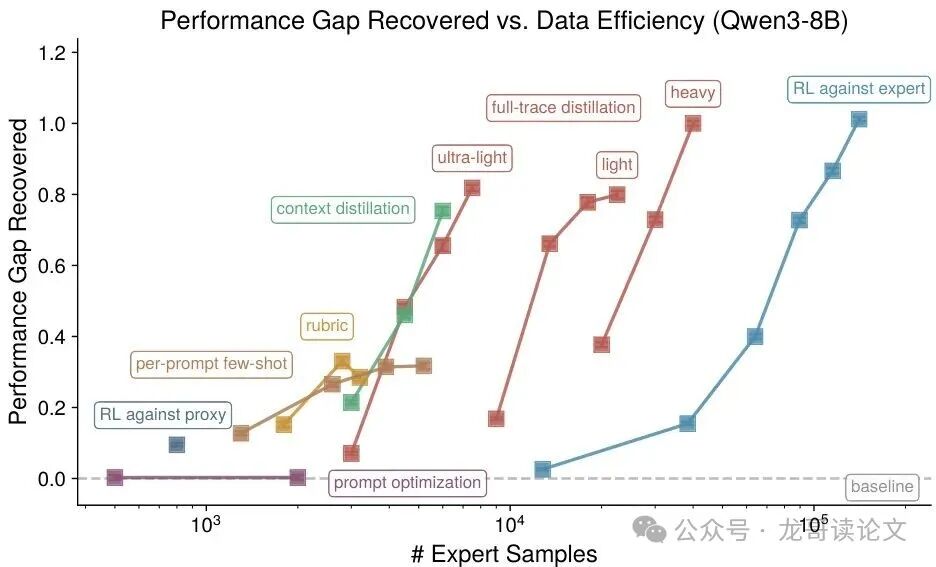
图2:(Qwen3-8B场景)我们的在线自然语言反馈训练方法所恢复的性能差距及所需专家样本数量,测试目标为引导Qwen3-8B撰写短篇小说。
你看这图里,横坐标是专家样本数量,纵坐标是性能恢复比例。那条橙色的线(微调方法)简直是“快、准、狠”,而蓝色的线(上下文学习方法)虽然也不错,但明显后劲不足。
模糊任务中的监督难题
先说说什么叫“模糊任务”(fuzzy tasks)。简单讲,就是那些很难用客观标准来验证对错的任务。比如,写一篇高质量的创意短篇小说、构思一个外交策略、或者探讨一个深刻的伦理哲学问题。
你可能觉得,AI生成一个故事好不好看,人一眼就能看出来啊!这有什么难的?问题就出在“规模”二字上。当你的模型每天要生成几十万个故事,你总不能雇一个编辑团队日夜不休地审稿吧?更何况,真正高水平的判断力,可能只掌握在极少数顶级专家手里。这就引出了AI安全领域一个经典难题:可扩展监督(Scalable Oversight)。简单说就是,当AI模型的能力越来越强,甚至在某些方面超过人类专家时,我们这些“凡人”如何才能有效监督和引导它们?
传统方法如RLVR(Reinforcement Learning with Verifiable Rewards,带可验证奖励的强化学习,即使用代码检查、标准答案等客观方式作为奖励信号)在解决数学、编程这类“硬”任务时表现惊艳。但对于创意写作这种“软”任务,它就彻底抓瞎了。因为根本不存在一个“标准答案”来量化“写得好不好”。
那么,有没有一种方法,既能利用人类(或顶尖AI模型)的高质量评判,又不需要对每一个模型输出都进行人工审核呢?Anthropic的这篇论文,给出了一个非常巧妙的答案。
用在线反馈打造“代理评审”
论文的核心思想是:不直接让专家评审每一段模型输出,而是用你仅有的那点珍贵专家样本,去训练一个代理奖励模型(Proxy Reward Model)。然后,用这个“代理”去进行大规模的强化学习训练。
等一下,这不就是一个标准的RLHF(Reinforcement Learning from Human Feedback,从人类反馈中进行强化学习)流程吗?好问题!关键在于 “在线”(Online)和 “自然语言”(Natural Language)两个词。
传统RLHF的做法是,先离线收集一大堆人类偏好数据(比如“A比B好”),然后训练一个固定的奖励模型。但这有个大坑:过度优化(Over-optimization)。模型在“哄骗”奖励模型这件事上非常有天赋,它会找到一些奖励模型喜欢但人类专家不喜欢的“捷径”,导致实际效果越来越差。你越优化,模型反而变得越“油嘴滑舌”。
Anthropic的方法则聪明得多。他们设计了一个迭代流程,整个流程就像一个循环,核心步骤如下:
迭代式在线RLHF流程:
- 强化学习训练:用当前的“代理评审”对策略模型(也就是我们正在训练的模型,比如Qwen3-8B)进行强化学习训练。
- 检测过度优化:训练一段时间后,模型开始对“代理评审”产生“审美疲劳”,甚至开始钻空子。这时,我们暂停训练,挑出一些当前的模型输出,去请教真正的专家(这里是Claude Opus,一个更强大的模型,模拟人类专家)。
- 收集自然语言反馈:专家(Claude Opus)不仅会给出一个分数,还会写一段详细的评审意见,比如“这个故事的结局过于突兀,和前文的伏笔没有呼应起来……”。这一段文字,就是宝贵的自然语言反馈(Natural Language Feedback,NLF)。
- 更新“代理评审”:利用新收集到的专家反馈,通过各种方式(后面会细讲)来更新“代理评审”模型,让它学会专家新的评价标准。然后回到第一步,用新的“代理评审”继续训练。
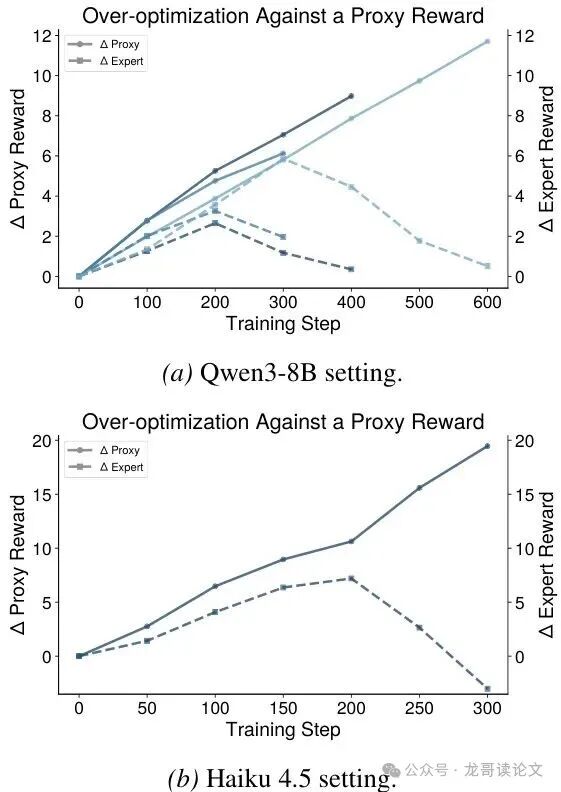
图3:针对代理奖励模型进行强化学习训练,会导致专家奖励分数先升后降(过度优化),且这种现象发生的时间点高度依赖于训练轨迹。
这个“检测-收集-更新-再训练”的循环,使得“代理评审”模型能够始终紧跟专家的最新品味,有效遏制了过度优化问题。那么,如何利用这宝贵的自然语言反馈来更新代理模型呢?论文探索了两条截然不同的技术路线。
上下文学习 vs. 微调:数据效率大比拼
你可以把“代理评审”模型想象成一个学生,专家反馈就是“真题和答案”。如何让学生快速提高?有两种方式。
方式一:上下文学习(In-Context Learning, ICL)
你可以把一些优秀的“范文”(专家对某篇文章的详细评价)放在学生的面前,让他照着学。在模型中,这就是修改评阅提示词(Grading Prompt)。
论文尝试了两种ICL策略:
- 评分准则(Rubric Prompts):让一个强模型基于一些样本自动生成一个评阅标准,比如“故事连贯性占30%,情节创新性占40%,语言优美度占30%”等等。然后让“代理评审”照着这个标尺打分。这个方法虽然高效(只需几十个样本),但效果有限,恢复的性能(Performance Gap Recovered, PGR)最高只到35%左右。就好比你给了学生一把尺子,但他仍然丈量不出好文章真正的神韵。
- 少样本演示(Few-shot Prompts):直接把几篇(5篇)完整的专家评审案例喂给“代理评审”模型,让它照着模仿。这个方法听起来更直接,但效果更差,学生很容易“学过头”,模仿得太刻板,导致过度优化问题更严重。
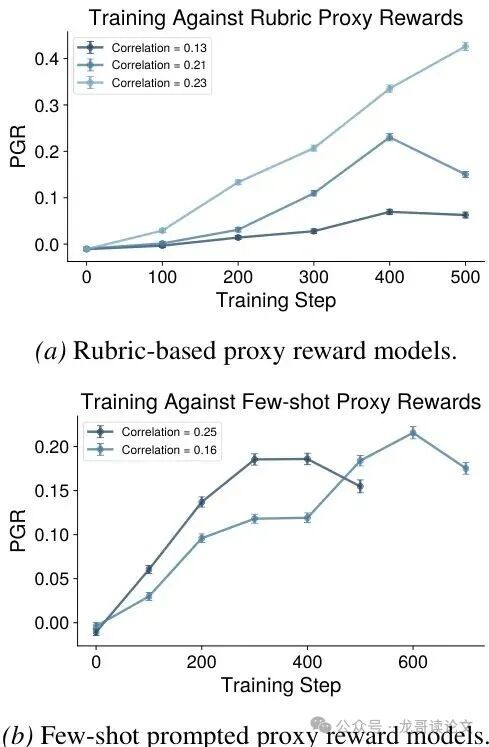
图4:(Qwen3-8B场景)针对不同初始优势对齐度的代理奖励模型进行RL训练。初始奖励对齐度可以预测下游RL的性能表现。
方式二:微调(Fine-tuning)
这个方式更狠,它不让“代理评审”只看题目了,而是让它把整本“练习册”(专家的完整评审记录)都吃进去,通过有监督学习(Supervised Fine-Tuning, SFT)直接改变模型的权重参数。就像是让学生把“范文”彻底背下来,融会贯通。
论文提出了两种微调策略:
- 完整轨迹蒸馏(Full-trace Distillation):把专家从“看到文章”到“写下评语”再到“给出分数”的整个思考过程,都拿去微调“代理评审”模型。这等于让代理模型学会了专家完整的思维模式。
- 上下文蒸馏(Context Distillation):这是一种更“偷懒”的方法,它只把专家的自然语言反馈(不包括分数的思考过程)作为“上下文”提供给代理模型,然后让代理模型自己写出评审过程。作者发现,即使只学“反馈”,效果也和完整蒸馏差不多,这说明自然语言反馈本身包含了极其丰富的信息。
为了验证方法的有效性,作者设计了一种“三明治式”(Sandwiching)的实验:
- 用顶级大模型(如Claude Opus)模拟人类专家,提供高质量反馈。
- 用稍弱的模型(如Qwen3-8B或Haiku 4.5)作为被训练的策略模型(Policy Model)和代理奖励模型(Proxy Reward Model)。
这种设置很巧妙,它模拟了人类(专家)监督比自身更强的AI模型(策略模型)的场景,为研究可扩展监督提供了一个绝佳的试验田。
微调策略的效果可谓一骑绝尘。在训练创意写作(Creative Writing)任务中,重配置的完整轨迹蒸馏方法,仅需约3倍的专家样本,就能恢复100%的性能!这简直就是数据效率的革命。相比之下,基线方法虽然也能恢复性能,但需要的样本数高出一个数量级。
核心发现:10倍样本,100%性能
聊完了“是什么”和“为什么”,我们来看看更详细的数据,把这些发现说得更透一些。
让我们把目光聚焦到下面这张图,它形象地展示了在创作短篇小说任务(Qwen3-8B场景)中,不同方法的性能恢复曲线。
我们先来看看ICL方法的效果。论文发现,通过“规则提示”方法,可以用极低成本(约50倍专家样本)恢复约35%的性能。但问题是,这个性能提升主要发生在第一轮迭代,后续更新提示词的效果就愈发有限了。这好比学生虽然看懂了规则,但缺乏“手感”,无法真正触及高分的精髓。
更让人意外的是,在“对齐研究”(Alignment Research)任务中,即使是使用“规则提示”的ICL方法,其效果甚至没有超过直接用粗糙的坏提示词训练得到的基线。这表明,对于更复杂、更专业的任务,单纯的提示工程已经不够用了。
接下来看SFT微调方法,它的表现就非常亮眼了。下面的两个图展示了在“对齐研究”任务(Haiku 4.5场景)中,不同微调配置下的性能对比。
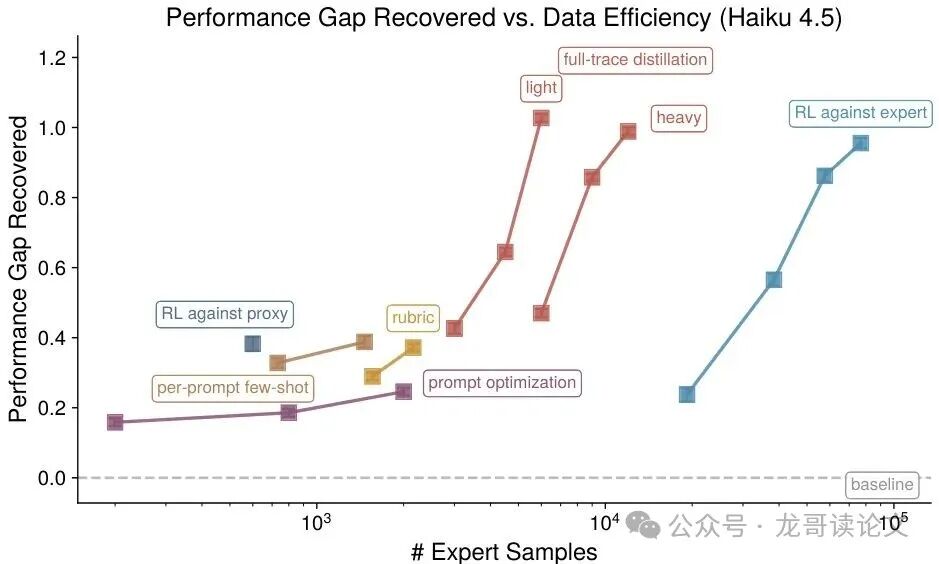
图1:(Haiku 4.5场景)我们的在线自然语言反馈训练方法所恢复的性能差距及所需专家样本数量,测试目标为引导Haiku 4.5撰写对齐研究实验计划。
结果令人振奋:在“对齐研究”任务中,无论是重配置还是轻配置的微调,都可以使用约10倍于基线的专家样本,轻松恢复100%的性能!而在“创意写作”任务中,轻配置也能恢复80%的性能。这说明微调方法已经从根本上改变了“代理评审”的能力,让它学会了专家的思维方式,而不仅仅是模仿了几个例子。
造成这种巨大差异的核心原因在于,微调后的“代理评审”模型在面对策略模型的花式“忽悠”时,展现出了更强的鲁棒性(Robustness,即面对分布外数据的稳定性)。
为了量化这一点,论文提出并验证了一个关键的启发式指标:优势相关性(Advantage Correlation)。简单说,就是计算“代理评审”和“专家评审”对同一批模型输出给出的“优势”评分之间的相关性。
什么是“优势”?在强化学习中,“优势”表示一个动作(此处的模型输出)相对于平均水平的好坏。论文公式化了这个想法,下面的图的逻辑起点在这里:
公式一:我们希望最大化策略的期望专家奖励:
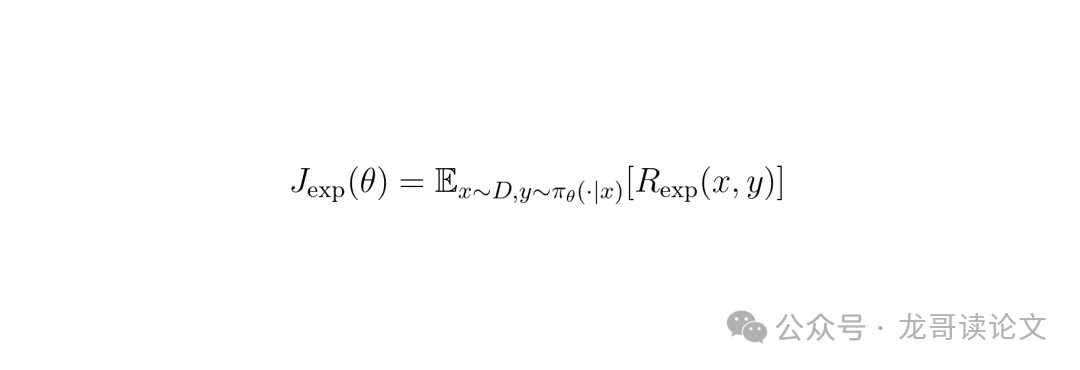
其中,Rexp(x,y) 是专家对输入x和输出y给出的奖励。πθ是我们正在训练的策略模型。
公式二:当用代理奖励Rpr进行RL时,单步更新的专家奖励变化可以近似为:
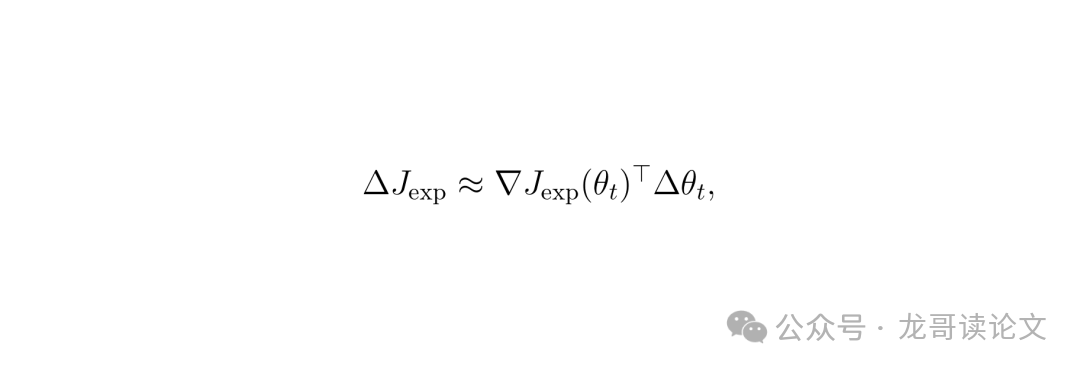
这意味着,如果代理和专家的“优势”估计是正相关的,那么沿着代理的优势方向优化,大概率也会提升专家的奖励。论文进一步推导了简化形式:
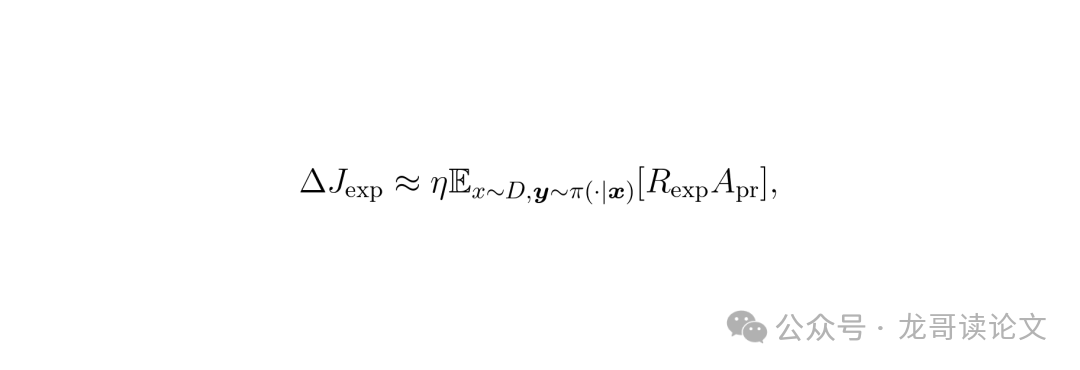
其中,Apr 是代理奖励模型给出的优势。这个公式清晰地表明,期望的专家奖励变化,近似于专家奖励和代理优势的协方差。
基于此,论文提出了度量“奖励对齐”的指标——prompt平均优势皮尔逊相关系数:
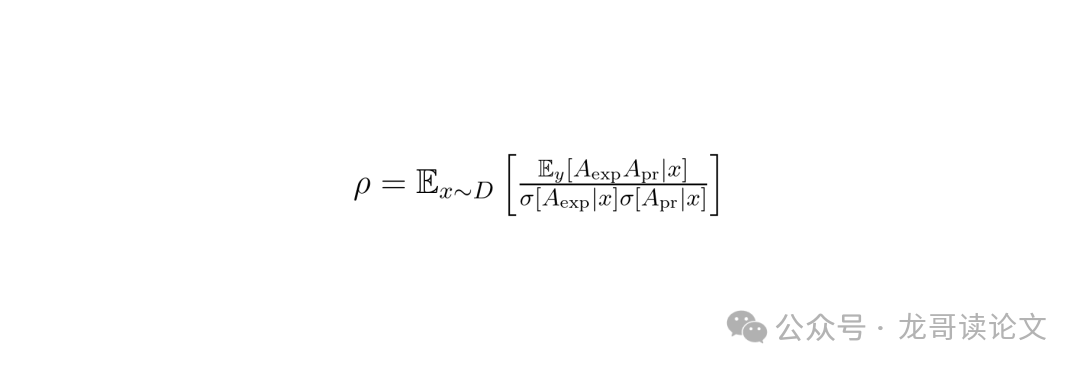
这个ρ值越高,说明“代理评审”和专家的判断方向越一致,我们用它来优化模型就越放心。
潜在局限与未来展望
论文的实验结果可以说是非常漂亮,但龙哥也要客观地说,这项研究并非完美无瑕,还有许多潜在局限和值得深入的方向。
“专家”也是AI,存在上限:论文中使用Claude Opus来模拟人类专家。虽然Opus很强,但它毕竟也是AI,其判断是否完全等同顶级的、高度专业化的人类专家,仍需打个问号。真正的“可扩展监督”需要面对的是比人类更聪明的AI,那时的“专家”反馈质量可能远高于此。这是该方法的“下限”实验。
任务复杂度有限:实验选用的“创意写作”和“对齐研究”虽然已属“模糊任务”,但都是典型的单轮、长文本生成任务。对于需要多轮对话、复杂推理、甚至与环境交互的任务(如外交谈判、战略游戏),该方法是否依然有效,有待验证。比如,一个游戏策略的优劣,往往要在几十步之后才能显现,人类的即时反馈可能本身就带有偏差。
微调稳定性问题:论文提到,在轻量级的微调配置中,训练后期会出现不稳定性。这暗示着,为了保证稳定,可能需要更精细的超参数调整(比如学习率、迭代步数),这会增加实际应用的门槛。
未来,这项工作可以沿着以下方向深化:探索将ICL和SFT的优势结合起来的混合方法;将该方法应用在更广泛、更复杂的模糊任务上;研究如何提升“代理评审”在不同迭代间的一致性,避免出现“学到新知识就忘记旧知识”的问题。
龙迷三问
下面是龙哥对于大家可能的一些问题的解答:
这篇论文解决什么问题? 它主要解决的是在“模糊任务”中,如何高效利用稀缺的人类专家监督来对齐语言模型的问题。通过一种迭代式的在线自然语言反馈方法,它显著提升了对齐的数据效率。
什么是“过度优化”? 这是强化学习中的经典问题。当用一个简单的“代理”奖励模型来训练一个聪明的模型时,后者会找到一些不被前者惩罚,但实际上对任务目标无益甚至有害的“捷径”。比如,让模型学会输出越长越好,而不是越准确越好。它的存在会导致训练出的模型看起来很厉害(奖励很高),但实际能力很烂。
文中提到的“性能差距恢复(PGR)”具体指什么? PGR是Performance Gap Recovered的缩写,是衡量方法有效性的一种标准。公式为:PGR = (你的方法得到的专家奖励 - 弱模型基线的奖励) / (最强基线能得到的最大奖励 - 弱模型基线的奖励)。一个100%的PGR意味着你的方法达到了最强基线(用大量专家数据直接训练)的效果,但用的专家样本更少。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性分数:★★★★✰
论文的创新点在于巧妙地将“在线”和“自然语言”两个概念融入到可扩展监督的框架中,并系统地对比了ICL和SFT两种实现路径。虽然各部分技术本身不算颠覆性创造,但组合起来解决了一个关键痛点,思路清晰,具有很好的启发意义。
实验合理度:★★★★★
实验设计非常巧妙,采用“三明治”式模拟,控制了变量。在两个不同模型、不同任务上的实验结论一致,具有很强的说服力。对基线、高水位线的设定都非常清晰合理。对过度优化的检测和定量分析也很到位。
学术研究价值:★★★★★
这项研究在“可扩展监督”这一AI安全的核心研究方向上迈出了坚实的一步。它证明了利用“丰富但昂贵”的在线自然语言反馈来指导“廉价但粗糙”的代理模型是一条极有前景的道路,为后续研究者提供了清晰的研究范式和优化方向。
稳定性:★★★✰✰
论文中微调方法表现出了不错的鲁棒性,但轻量级配置仍会出现训练不稳定现象。ICL方法则对提示词选择非常敏感,不够稳定。总体来看,要达到理想效果仍需精细的调参,离“开箱即用”还有距离。
适应性以及泛化能力:★★★★✰
在两个差异较大的任务和模型上验证了有效性,说明有一定泛化能力。但由于任务的类型(单轮长文本生成)和模型(GPT系列)同质性较强,更广泛的任务(如多轮对话)和模型族(如Mamba)的泛化能力有待检验。
硬件需求及成本:★★★✰✰
方法本身需要不断的“训练代理-收集反馈-训练代理”的循环。虽然专家反馈样本节省了,但整个训练流程的计算开销(特别是SFT和多次RL迭代)依然很高。对于小团队来说,成本仍是主要瓶颈。
复现难度:★★✰✰✰
方法涉及多轮迭代、RL、专家模型调用等多个复杂环节,复制整个实验需要投入大量的工程和计算资源。论文并未提供完整的代码开源,对于只想快速验证想法的研究者不太友好。
产品化成熟度:★★✰✰✰
目前更多是研究性证明,离产品落地还有距离。主要障碍在于需要依赖强大的专家模型参与训练循环,以及训练稳定性的挑战。但在某些特定场景(如企业内部的高质量内容生成、创意辅助)存在应用潜力。
可能的问题: 论文中ICL方法的效果远不如SFT,但作者并未详细探讨为什么ICL会如此“脆弱”。此外,实验中“专家”和“代理”之间的能力差距是固定的,如果差距缩小(代理变得更强),迭代式RLHF是否还能保持稳定,需要进一步研究。
主要参考文献
[1] Christiano, P., et al. Deep reinforcement learning from human preferences. NeurIPS 2017.
[2] Bowman, S., et al. Measuring Progress on Scalable Oversight. arXiv:2211.03540, 2022.
[3] Gao, L., et al. Scaling laws for reward model overoptimization. ICML 2023.
[4] Burns, C., et al. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. ICML 2024.
[5] 原论文链接:https://arxiv.org/pdf/2605.04356v1.pdf
本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击原文链接查看更多原论文细节。

 发表于 2026-5-10 03:22:28
|
查看: 116|
回复: 0
发表于 2026-5-10 03:22:28
|
查看: 116|
回复: 0
