模型看过手册,不代表会按手册办事
想象一个很常见的企业场景:你把几万字公司合规手册丢给模型,让它判断某笔供应商付款能不能走简化审批。它能复述章节,也能引用制度名,可到了真正判断时,可能漏掉“跨境付款另走流程”“关联方交易必须升级审批”这种细条件。仪器操作手册也类似,模型能背出安全注意事项,却在排障时跳过校准前置步骤。开源仓库规则同样如此,它看完 CONTRIBUTING,仍可能忘记测试矩阵、提交信息格式或版本兼容要求。
这篇 Ctx2Skill 抓住的就是这个断点:长上下文让模型“看见”陌生规则,但看见不等于学会,更不等于把规则沉淀成可复用技能。我觉得这个问题比单纯扩窗口更接近真实工作。窗口越来越大后,瓶颈不再只是能不能装下材料,而是模型能不能把材料变成一套稳定的做事方法。
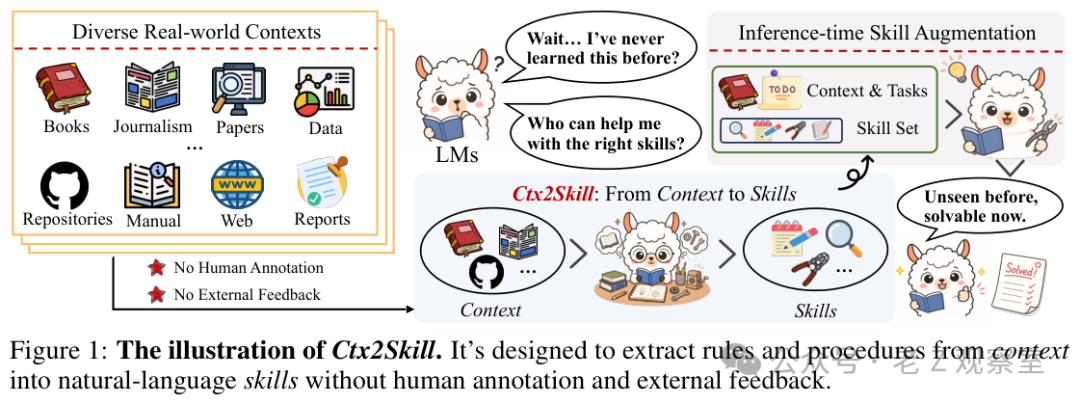
论文选的 CL-bench 也不是普通阅读理解。它有 500 个 contexts、1899 个 tasks、31607 条 rubrics,平均上下文 10.4K token,最长 65K,而且 51.1% 是多轮顺序任务。也就是说,模型不只要找到信息,还要按规则组合、按流程执行、在例外之间做选择。四类任务覆盖领域知识推理、规则系统应用、流程任务执行、经验发现与模拟,很多题更像“拿着一本陌生手册去上岗”,而不是“在文档里找一句话”。
这也是为什么无技能的 GPT-5.1 整体解题率只有 21.1%,GPT-4.1 只有 11.1%。这个数字挺扎心:长上下文时代,真正能“照章办事”的比例仍然不高。我的判断是,模型在长文档上最容易给人一种错觉:它读得很顺,答得也像懂了,但只要任务要求跨章节执行,它就会暴露“规则没有内化”的问题。
换句话说,这篇论文讨论的不是记忆容量,而是 Transformer 架构下的任务迁移。模型需要把散落在文档里的条件、例外、顺序、优先级整理成行动指南。很多真实任务失败,并不是因为模型完全没找到那句话,而是因为它不知道那句话什么时候压过另一条规则。我认为这正是长上下文应用里最容易被低估的难点。
如果只靠“把原文放进提示词”,每次任务都像临场开卷考试;如果能抽成技能,模型至少带着一份提前整理好的考点清单上场。这两种状态差别很大,也决定了它能不能从一次回答变成连续工作的助手,而这正是实用价值所在,尤其适合团队工作场景。
它让模型自己出题、自己判错、自己改技能
Ctx2Skill 的思路不是让模型多读几遍,而是把“读文档”改造成一场自博弈。Challenger 负责基于上下文生成任务和评分 rubrics,Reasoner 带着当前技能去答题,Judge 按 rubrics 给通过或不通过。然后系统把不同结果送去不同方向:Reasoner 做错的题,说明它缺某些上下文技能;Reasoner 轻松做对的题,说明 Challenger 出题太浅。
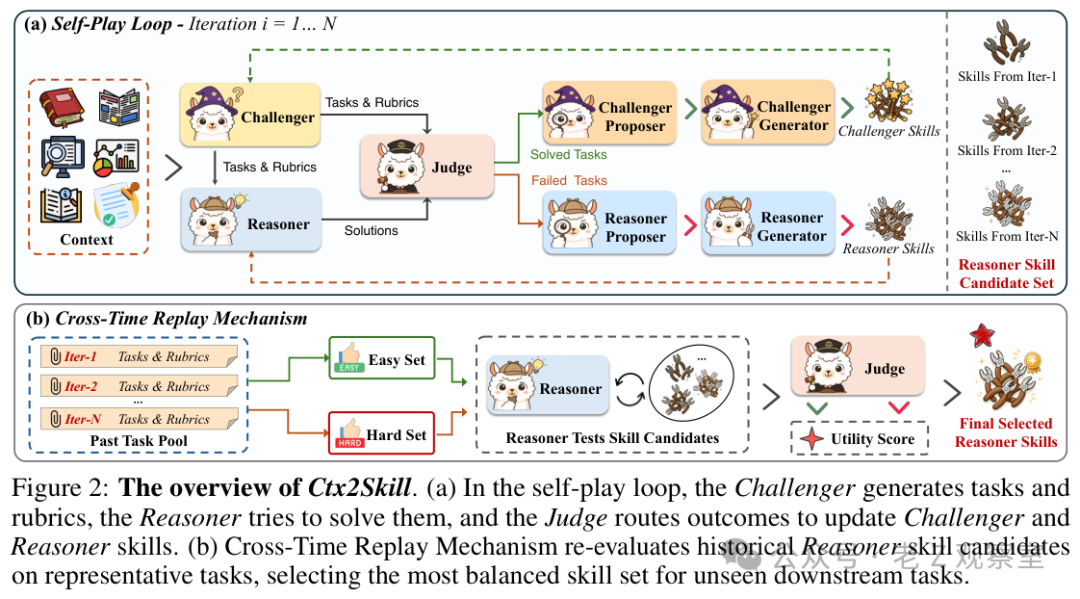
这里最聪明的一点,是失败和容易都被利用了。失败任务会更新 Reasoner 的技能,让它补上遗漏的规则、流程或例外;容易任务会更新 Challenger 的技能,让它下一轮更会考深层规则。Proposer 负责诊断问题,Generator 再把诊断写成自然语言技能。整个过程不改模型参数,只改一份 Markdown 风格的技能文本。
我对这个设计的反应是:它像给长文档自动生成一本“错题本加操作备忘录”。单次 prompting 让模型直接写技能,容易写成漂亮但空泛的摘要;Ctx2Skill 逼技能经受任务检验,错在哪里就补哪里。比如在合规手册场景里,第一次技能可能只写“付款需审批”;被 Challenger 考到跨境付款后,Reasoner 才会补上“跨境付款、关联方交易、金额阈值会改变审批链”。这类补丁比普通摘要更接近可执行经验。
更关键的是,它不需要人工给每份长文档写技能,也不需要代码测试那样的外部执行反馈。Challenger、Reasoner、Judge 组成一个内部压力系统,把原本没有反馈的问题,转成了可以循环暴露漏洞的问题。我觉得这比“自动总结文档”向前走了一步:总结追求覆盖信息,技能追求下次做题少犯错。
这也解释了为什么论文把技能写成自然语言,而不是隐藏在某个不可见状态里。自然语言技能可以被人读、被人删改、被另一个模型复用。对团队协作来说,这一点很重要:如果一个运维 agent 反复从事故手册里学到“升级前要确认回滚包、灰度比例和监控阈值”,工程师至少能检查这条经验是否靠谱,而不是只能相信模型说自己已经懂了。
当然,这里也有一个现实问题:Judge 仍是模型 Judge。CL-bench 的协议里,交叉验证和人工一致性超过 90%,这个设计可以接受,但如果放到企业高风险场景,我不会把它当成完全可靠的裁判。我的看法是,它适合做技能发现和候选生成,最终关键流程仍然需要抽检,至少要让人能审阅技能文本,知道系统到底把哪些规则写进去了。
自博弈越久,可能越卷越偏
这篇论文最值得看的不是“多 agent”这个标签,而是它承认自博弈会失控。Challenger 如果不断进化,可能越来越爱出极端题、边角题、病态题;Reasoner 为了应付这些题,也会把技能写得越来越专门。表面上双方都在变强,实际却可能离真实任务越来越远。
这个风险在很多自动化 agent 系统里都会出现。系统内部有了一个会制造压力的角色,就容易把优化方向带到奇怪角落:题变难了,答案变长了,技能越来越厚,但泛化未必更好。我的个人判断是,Ctx2Skill 真正有工程味的地方,就在于它没有迷信“迭代越多越强”。
所以 Ctx2Skill 加了 Cross-Time Replay。它不默认最后一轮技能最好,而是把不同迭代产生的 Reasoner 技能都拿出来,在一批代表性历史任务上重测,挑最均衡的一版。这个机制像是在问:这份技能不只会打最新对手,还能不能处理早期简单题和中期困难题?
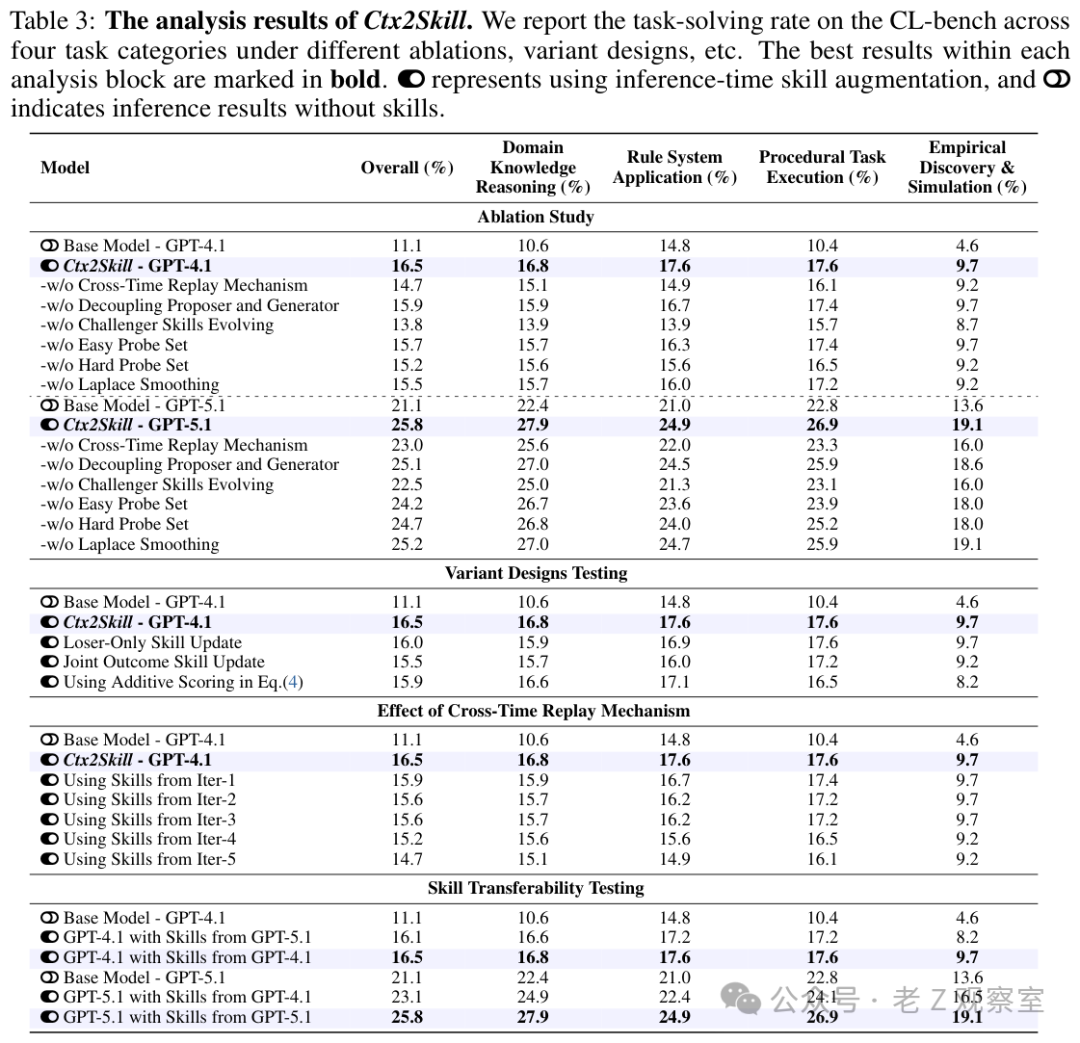
消融结果很能说明问题。GPT-4.1 上,完整 Ctx2Skill 是 16.5%;去掉 Cross-Time Replay 后降到 14.7%;去掉 Challenger skills evolving 降到 13.8%。更有意思的是,固定用 Iter-1 技能是 15.9%,固定用 Iter-5 反而只有 14.7%。这说明后期技能不天然更好,越卷可能越偏。

我很喜欢这个细节,因为它把论文从“让模型互相卷”拉回到了工程理性:系统不只是要制造难题,还要知道什么时候停、回看哪一版更稳。图里不同模型会从不同迭代挑技能,早期迭代被选中很多,但后期也不是完全没价值。我的理解是,有些上下文规则简单,早期技能已经够用;有些上下文结构复杂,多轮对抗还能挖出隐藏规则。统一拿最后一版,反而粗暴。
结果有提升,但别把它神化
主结果显示,Ctx2Skill 在三个 backbone 上都有稳定提升:GPT-4.1 从 11.1% 到 16.5%,GPT-5.1 从 21.1% 到 25.8%,GPT-5.2 从 18.2% 到 21.4%。更抓眼球的是,GPT-4.1 加上 Ctx2Skill 技能后达到 16.5%,超过无技能 Gemini 3 Pro 的 15.8%。这不是说 GPT-4.1 真的全面超过 Gemini,而是说明面向特定上下文的技能层,确实能弥补一部分模型能力差距。

技能质量评估也支持这个判断。用 GPT-4.1 做 judge,Ctx2Skill 生成技能的平均分在三组设置下分别是 89.8、93.6、92.0,优于 Prompting 和 AutoSkill4Doc。跨模型迁移也有看点:GPT-5.1 生成的 skills 给 GPT-4.1 使用,整体还能到 16.1,接近 GPT-4.1 自己生成技能的 16.5。这让我觉得,自然语言技能不只是临时提示词,某些情况下可能成为可迁移、可审计、可维护的上下文资产。
我还注意到一个细节:Prompting 和 AutoSkill4Doc 并不是完全没用,它们也能带来一点提升,但有些子类会下降。这很符合直觉。单次抽取技能时,模型可能把文档压缩错重点,甚至把“看起来重要”的规则放在前面,把真正决定任务成败的例外藏掉。Ctx2Skill 的优势不是文案写得更好,而是它用任务失败逼迫技能回到可执行层面。
如果换到开源仓库场景,这个资产形态很直观:一次自博弈可以沉淀“如何跑测试、哪些目录不能直接改、PR 描述要包含哪些字段、兼容性检查怎么做”。以后不管调用 GPT-4.1 还是 GPT-5.1,都能把这份技能放在前面,让模型少踩同一批坑。对企业内部知识库也是一样,技能层可以比原文档短得多,又比摘要更强调操作。
但我不想把它讲成“长文档问题解决了”。最高的 GPT-5.1 加技能也只有 25.8%,绝对解题率仍然低;多 agent、多轮自博弈会带来成本;Judge 偏差也没有彻底消失。我的局部存疑是:在真实公司手册或复杂工具链里,技能更新会不会把少数误判写进长期技能库?论文给了选择机制,但没有完全消除这个风险。
这篇工作的启发在于,它把长上下文应用从“塞材料”推进到“沉淀技能”。以后让模型处理合规、运维、科研流程、仓库规则时,可能不该只问窗口多大,而要问:它有没有一份经过任务压力测试的技能表?如果没有,模型大概率只是读过;有了,才更接近会做。在 云栈社区 的讨论中,我们常看到开发者分享类似的实践经验:真正落地的 技术文档 理解方案,往往需要将静态知识转化为可执行的操作指南,而不仅仅依赖模型的基础能力。
 发表于 2026-5-8 02:14:15
|
查看: 129|
回复: 0
发表于 2026-5-8 02:14:15
|
查看: 129|
回复: 0
