说在前面
这篇文章不讲虚的。最近在生产环境里折腾大模型推理优化,投机解码(Speculative Decoding)是我认为最优雅、最实用的加速方案之一。它不改变模型,不损失精度,就能把生成速度提2~5倍。下面把我这段时间的理解和实践思考,用大白话整理出来。
一、先说说痛点:为什么生成一个 Token 这么慢?
用过 GPT-4、Claude 或者自己部署过开源模型的同学都知道,大模型 生成文字是一个字一个字“蹦”出来的。这不是因为算力不够,而是自回归解码的串行诅咒——生成第 N 个 Token 时,必须等第 N-1 个 Token 算完。
KV-Cache 确实减少了重复计算,但计算的先后顺序改不了。每生成一个 Token,就要完整跑一次前向传播。千亿参数模型的单次前向延迟,在实时对话、代码补全、流式翻译这些场景里,用户体验就是“卡”。
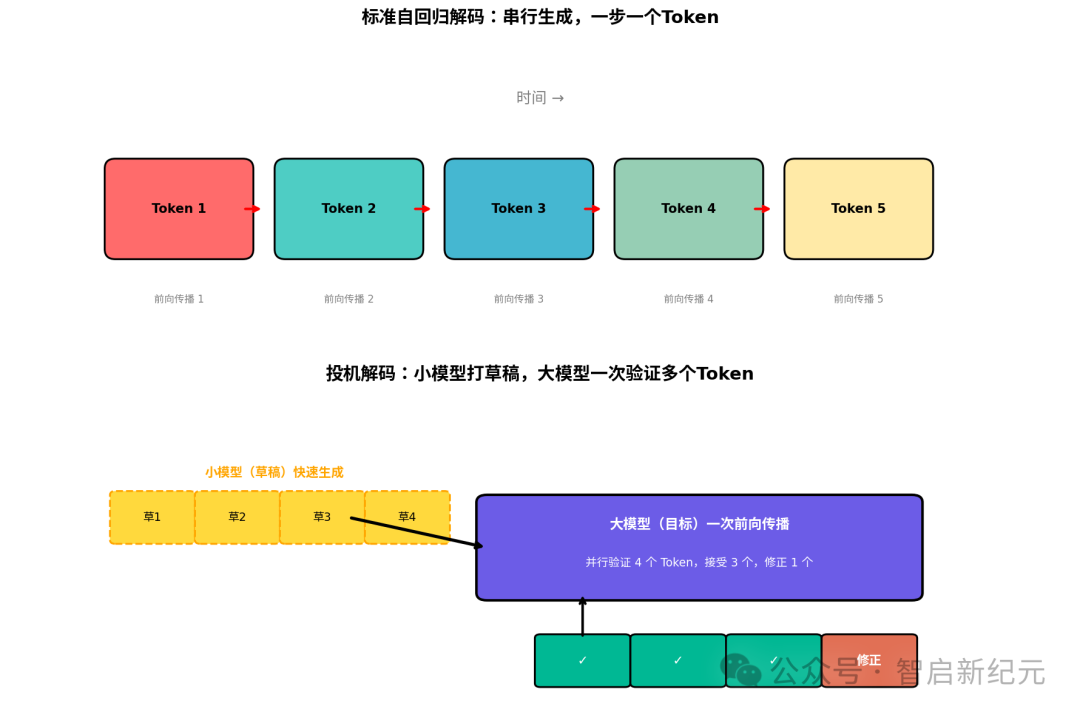
上图:标准解码像单线程排队,投机解码像小模型先“预演”,大模型一次性“批阅”
二、核心思想:先猜后验,无损加速
投机解码的思路特别像编辑部的工作流程:
- 速记员(小模型/草稿模型):看着上下文,快速写出接下来 K 个 Token 的草稿
- 资深编辑(大模型/目标模型):一次性审阅这 K 个 Token,决定哪些保留、哪些推翻重写
如果速记员够靠谱,大部分草稿被直接采纳,大模型一次前向传播就等于生成了多个 Token,速度自然上去了。
最关键的一点是:这个过程是数学上严格无损的。 不是近似,不是蒸馏,最终输出的概率分布和让大模型自己慢慢生成完全一致。
三、怎么保证“无损”?拒绝采样的巧妙设计
这是投机解码的灵魂,也是很多人第一次看论文时容易卡壳的地方。
假设小模型给某个 Token 打了草稿,它的置信度是 p(x),大模型看到这个 Token 后的真实置信度是 q(x)。算法规则很简单:
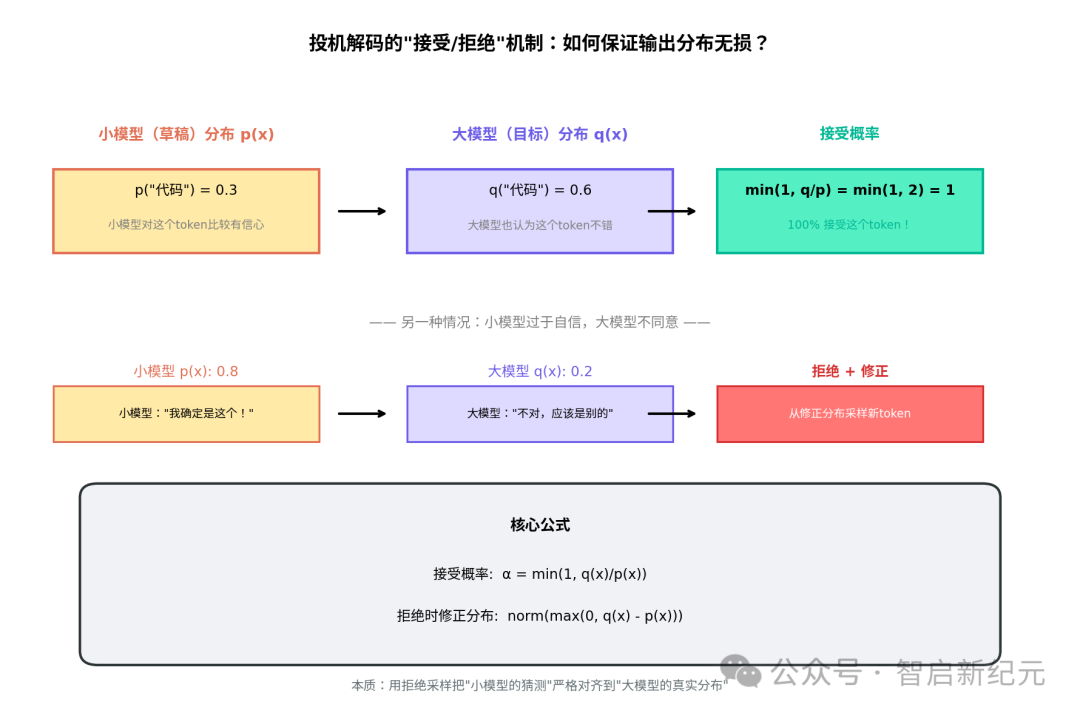
接受概率 = min(1, q(x)/p(x))
- 如果小模型和大模型意见一致(q ≥ p),直接接受
- 如果小模型过于自信但大模型不认同(q < p),按概率拒绝
- 一旦拒绝,从大模型的“修正分布”重新采样,丢弃后续所有草稿
这本质上是一场拒绝采样(Rejection Sampling)。小模型是“提议分布”,大模型是“目标分布”。通过精心设计的接受规则和修正分布,能把小模型的猜测严格对齐到大模型的真实输出上。
直观理解:小模型如果在这个位置“心里没底”(p 很低),但大模型觉得还行(q 较高),接受概率就高;反之,小模型瞎猜但大模型不同意,大概率会被打回重写。
四、能快多少?取决于草稿有多“像”大模型
理论上,每次大模型前向传播的期望生成 Token 数大约是:
E = (1 - α^(K+1)) / (1 - α)
其中 α 是平均接受率,K 是草稿长度。α 越接近 1(小模型越像大模型),加速效果越明显。
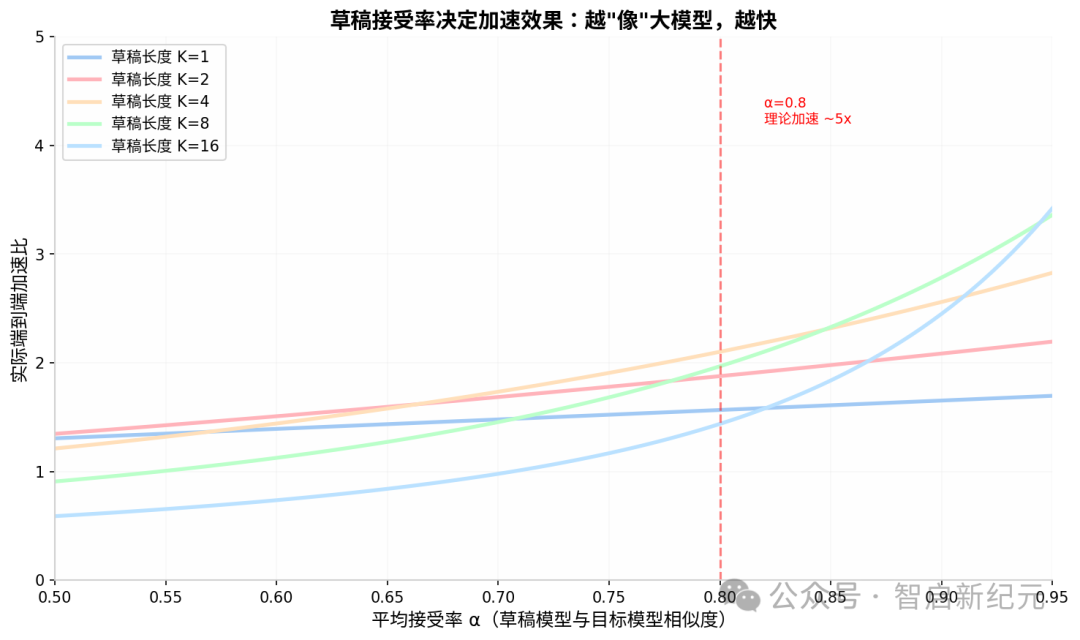
上图:草稿接受率是决定加速效果的核心变量。α=0.8 时理论加速可达 5 倍,实际扣除草稿开销后通常在 2~3 倍
从图里能看出来几个规律:
- 草稿不是越长越好。K 太大但接受率不高,大量计算浪费在验证错误草稿上
- 小模型质量是天花板。草稿模型和目标模型的分布差异(总变分距离)直接决定 α
- 不同任务差异很大。代码生成、数学推理这种确定性高的任务,α 通常很高;创意写作、开放对话则偏低
五、草稿模型从哪来?四条技术路线
生产环境落地时,最大的问题是:上哪找一个既像大模型、又比大模型快很多的小模型? 学术界和工业界演化了四条路线:
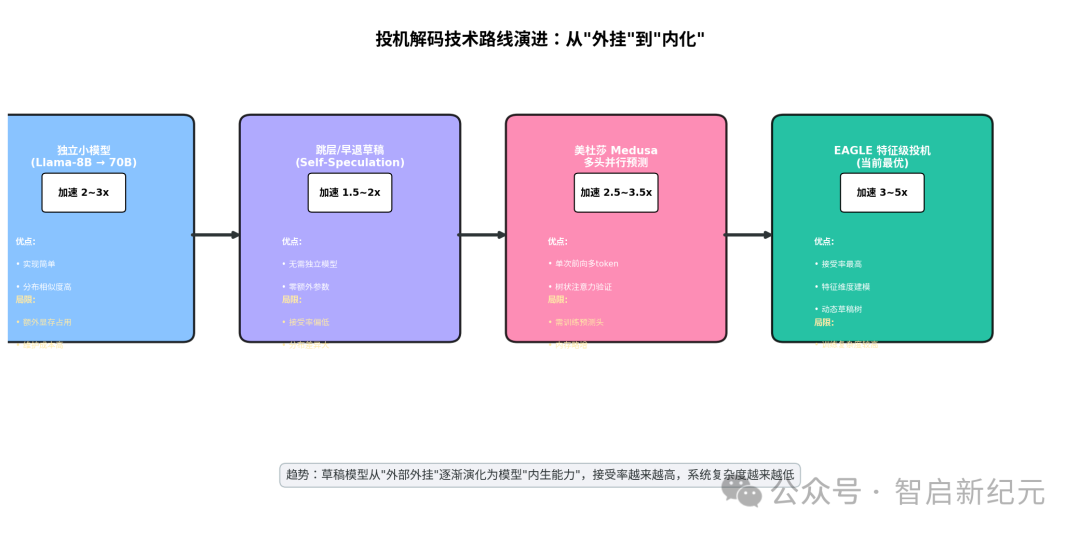
路线 1:独立小模型(如 Llama-8B → 70B)
最直白的方案。同系列小尺寸模型共享词表和分词器,分布天然比较接近。实现简单,效果稳定。缺点是额外占显存,小模型自己的串行生成也有开销。适合目标模型很大的场景。
路线 2:跳层/早退草稿(Self-Speculation)
让大模型自己给自己打草稿——从中间某层提前退出生成候选,再用完整模型验证。零额外参数,但简单早退的分布和最终输出差异较大,接受率一般,实际加速有限。
路线 3:美杜莎 Medusa(多头并行预测)
不再让小模型自回归生成草稿,而是在大模型最后一层加装多个轻量预测头。第 k 个头直接预测“第 k 个未来 Token”。这些头和模型主干一起单次前向传播,同时产出多个候选。
配合树状注意力(Tree Attention) 机制,多个候选 Token 组成树形结构,大模型一次并行验证所有路径。完全消除了草稿模型的自回归开销,加速效果很可观。
路线 4:EAGLE 特征级投机(当前最优)
EAGLE 不只用最后一层隐藏状态,而是把目标模型中间层的特征向量喂给极轻量的自回归头来生成草稿。它在特征维度做了不确定性建模,草稿质量和接受率大幅领先。
EAGLE-2 进一步引入动态草稿树,根据实时接受率调整策略,经常能做到 3~5 倍无损加速。这揭示了一个深层事实:大模型的中间表征已经包含了丰富的“未来信息”,只需极小的计算成本就能解码出来。
六、生产环境落地的几个硬核挑战
算法漂亮,但真要塞进推理框架,还有不少坑:
1. 显存争用
独立草稿模型意味着多一份权重。在大模型本身快占满 GPU 的情况下,这往往是不可接受的。Medusa、EAGLE 这种“内化”方案优势明显。
2. 批量推理的序列长度管理
一个 batch 里不同请求的草稿接受长度不一样,验证后序列长度参差不齐。怎么高效管理 KV-Cache、怎么回滚被拒绝的草稿 Token、怎么拼接接受的 Token,是推理框架(vLLM、SGLang 等)实现的重难点。
3. 草稿长度的动态调节
固定 K 不是最优解。代码生成时接受率高,K 可以大一点;开放对话时接受率低,K 应该缩小。自适应机制根据实时接受率动态调整,才能最大化整体吞吐。
4. 与其他优化的正交叠加
投机解码可以和量化、FlashAttention、流水线并行等几乎所有推理优化叠加使用,互不冲突。这也是它吸引人的地方——不是替换现有优化,而是在现有基础上再捞一层收益。
七、给我的启示:用概率性冗余换确定性并行
投机解码看似是在“走弯路”——明明可以直接生成,非要先猜一遍再验证。但正是这种概率性的冗余计算,换来了确定性的并行收益。
在当前硬件和算法的边界下,这可能是突破串行瓶颈最根本的策略。更长远来看,随着多 Token 预测(Multi-Token Prediction)成为训练目标的一部分,模型本身会具备更强的“自我预见”能力,投机和生成的界限会越来越模糊。
对于我们做工程落地的人来说,这意味着:
- 短期:在现有模型上集成 Medusa 或 EAGLE,快速拿到 2~3 倍加速
- 中期:把投机能力内化到训练流程,让模型天生会“打草稿”
- 长期:推理系统的标准组件里,投机采样会和 KV-Cache、量化一样,成为默认配置
写在最后
大模型推理优化这个领域,每天都在出新东西。但投机解码是我觉得少数几个既在理论上有严格保证,又在工程上切实可行的方案。它不魔改模型,不牺牲精度,用一套优雅的“草稿-校对”机制,把生成效率往上提了一个台阶。
如果你也在做模型部署和推理优化,建议直接去看 vLLM 或 SGLang 里投机采样的实现代码,比论文直观得多。理论是骨架,代码是血肉,跑起来才是真的懂了。
本文技术内容参考自 Google Research、DeepMind 2023 年原始论文及后续 Medusa、EAGLE 系列工作。
 发表于 2026-5-5 20:19:33
|
查看: 167|
回复: 0
发表于 2026-5-5 20:19:33
|
查看: 167|
回复: 0
