
Key Knowledge RAG (K²RAG): An Enhanced RAG method for improved LLM question-answering capabilities
摘要
让大型语言模型(LLMs)获取更广泛知识通常需要微调,但这个过程消耗巨大。尽管已有FLAN、LoRA等技术试图降低资源消耗,但随着模型越来越庞大,问题依然存在。因此,业界需要寻找LLM知识扩展的新路径。
检索增强生成(RAG)是一种替代方案,它将信息存储在外部数据库中,检索相关内容来辅助生成答案。然而,朴素的RAG实现在处理复杂查询和大规模数据时,面临可扩展性和准确性的挑战。
本文提出的关键知识增强式问答(K²RAG)框架,正是为了应对这些挑战。它借鉴了分治思想,综合运用了密集与稀疏向量搜索、知识图谱以及文本摘要技术。框架还包含数据预处理步骤以缩短训练时间。
在MultiHop-RAG数据集上的评估显示,K²RAG在答案准确性上优于常见的朴素RAG实现,其平均答案相似度达到0.57,且能回答更多与标准答案高度相似的问题(Q3四分位数高达0.82)。得益于语料库摘要步骤,训练时间平均缩短了93%。同时,K²RAG的执行速度比传统的基于知识图谱的RAG实现快40%,并且VRAM需求减少了三分之二。这表明K²RAG能够帮助企业构建更轻量、健壮的内部知识问答系统,辅助复杂决策。
核心速览
研究背景
- 研究问题
如何解决大规模语言模型(LLMs)因微调而导致的巨额资源消耗问题,并设计一种高效的知识扩展方法。
- 研究难点
- 在不修改基础LLM的前提下进行知识扩展。
- 提高信息检索的准确性与效率。
- 在保证回答质量的同时,最大限度减少计算资源和时间成本。
- 相关工作
现有方法如FLAN、LoRA和QLoRA主要聚焦于优化微调过程。而RAG系统作为微调的替代方案被提出,但在处理复杂、多跳查询时仍存在局限性。
研究方法
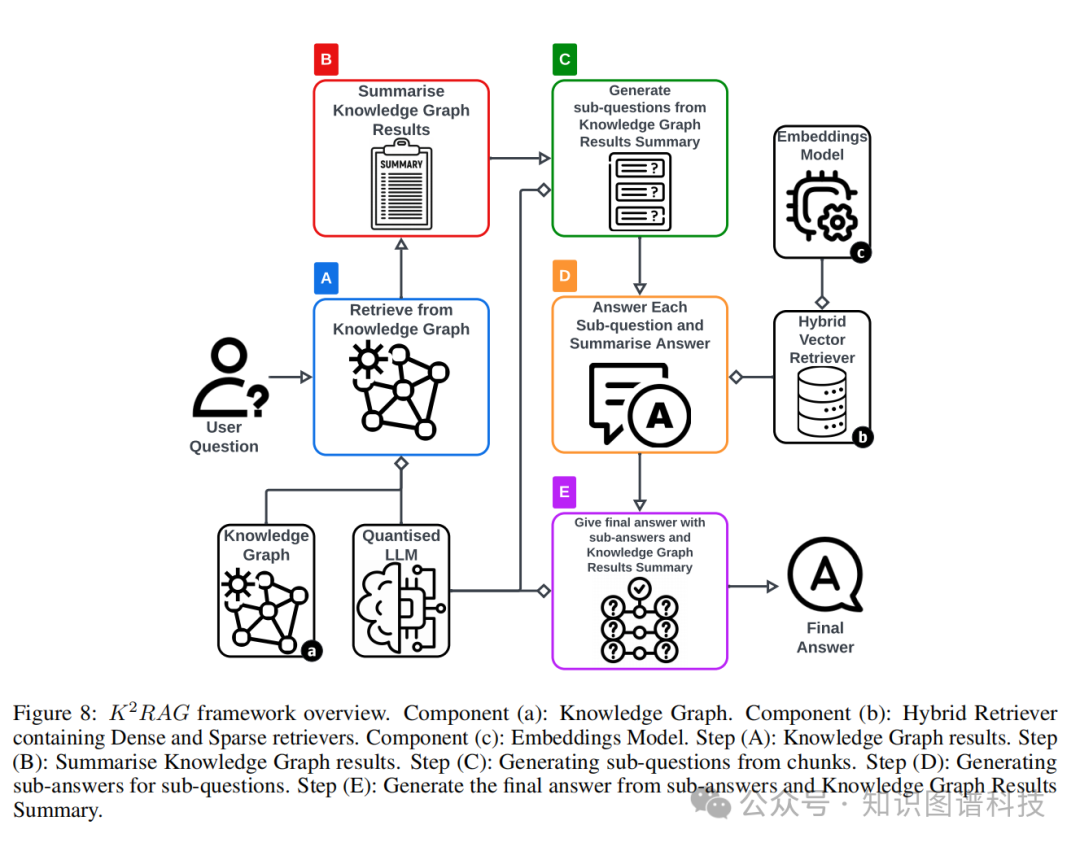
论文提出的KeyKnowledgeRAG(K²RAG)框架,旨在攻克LLM知识扩展中的可扩展性与答案准确性瓶颈。其核心技术组件包括:
-
知识图谱
K²RAG利用知识图谱来组织和链接语料库中的主题概念。与传统简单的文本分块不同,知识图谱将内容结构化为互连的节点,实现更具上下文感知能力的检索,尤其擅长处理复杂或表述模糊的查询。
-
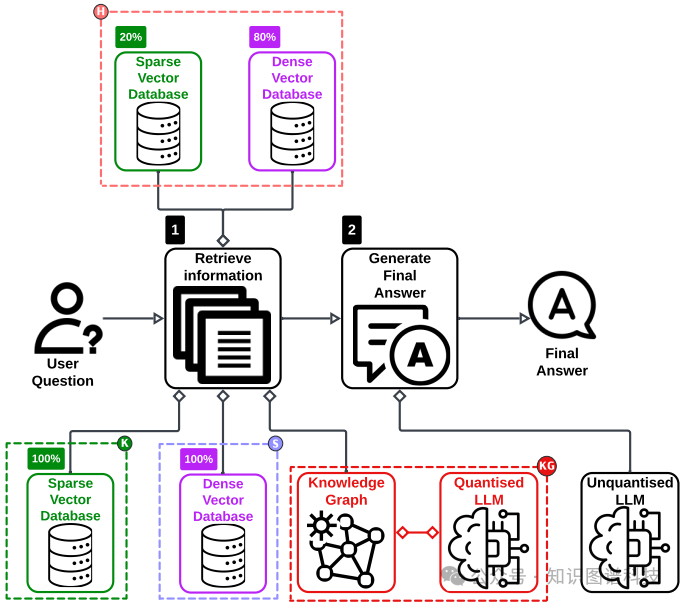
混合检索器
为了减少检索到“语义相似但内容不相关”文档块的概率,K²RAG集成了一个混合检索器。该方法受前人研究启发,以80%(稠密向量)和20%(稀疏向量)的优化比例进行加权检索,兼顾语义与关键词匹配。
-
多阶段摘要
K²RAG在流程的多个阶段引入摘要,以应对“大海捞针”问题。在索引阶段,文档在存入向量库和知识图谱前先被摘要。在查询时,检索到的内容也会被再次摘要,从而精炼提供给LLM的上下文,避免信息过载。
-
轻量级模型
为了提高资源效率,K²RAG采用了基于Longformer的文本摘要器以及量化后的LLMs。这使得整个流水线能够在较低的VRAM占用下高效运行,且不牺牲输出质量。
实验设计
- 数据集选择
为全面评估框架,实验选用了MultiHop-RAG数据集。该数据集包含一个用于训练的语料库(609篇涵盖娱乐、健康等多主题文章)和一个包含2555个问答对的测试集。
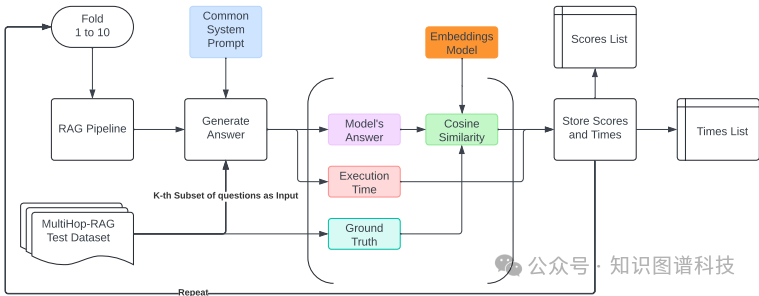
- 评估过程
采用K折评估法(K=10)。对于每个测试问题,记录管道生成的答案及其执行时间。答案准确性通过计算模型输出与标准答案之间的余弦相似度来评估。
结果与分析
-
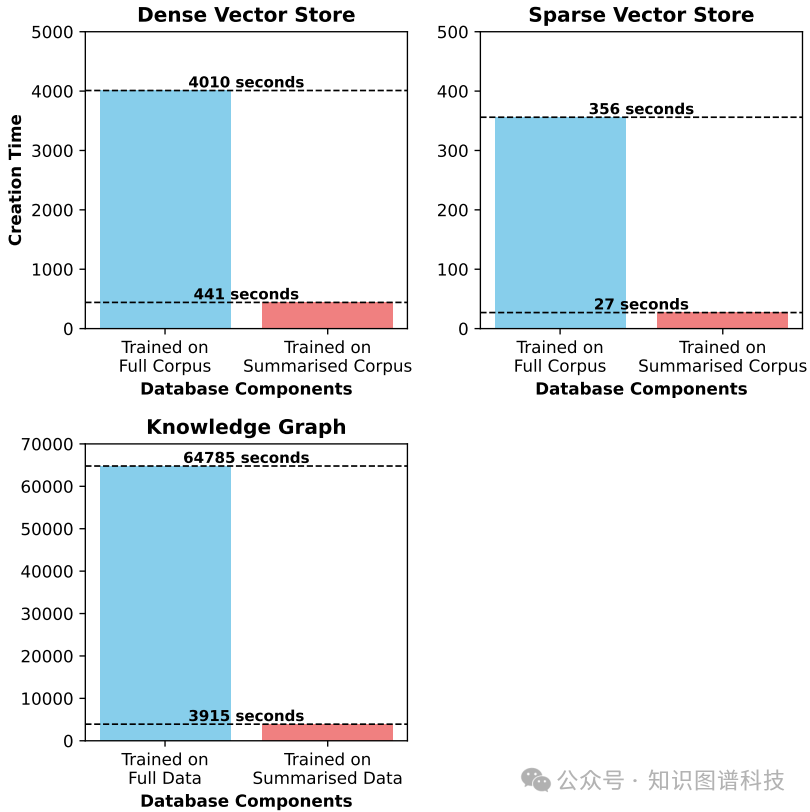
训练时间
通过对语料库进行摘要,稀疏向量库、稠密向量库和知识图谱的创建时间分别减少了89%、97%和94%。其中,知识图谱的创建时间从18小时大幅缩减至仅1小时。
-
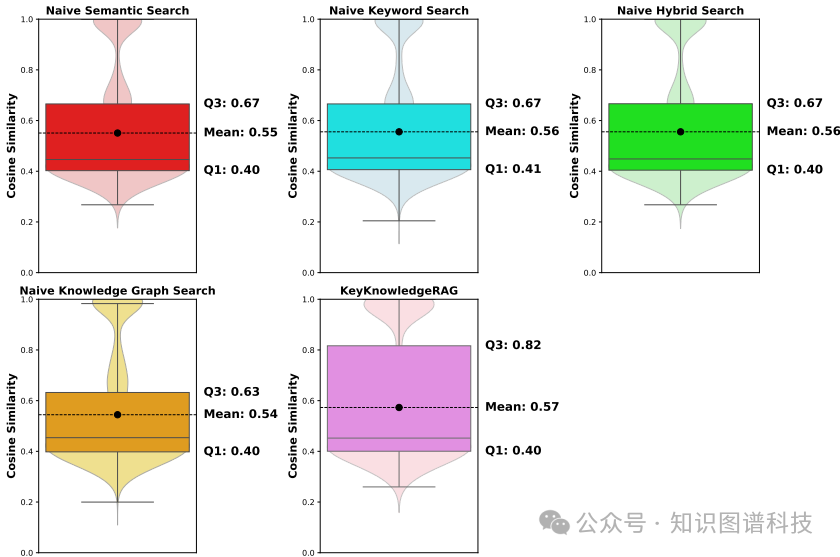
回答准确性
K²RAG的平均相似度得分为0.57,高于其他朴素方法。更值得注意的是,其Q3四分位数(0.82)显著更高,这表明K²RAG能对更多问题给出与标准答案高度相似的优质回答。
-
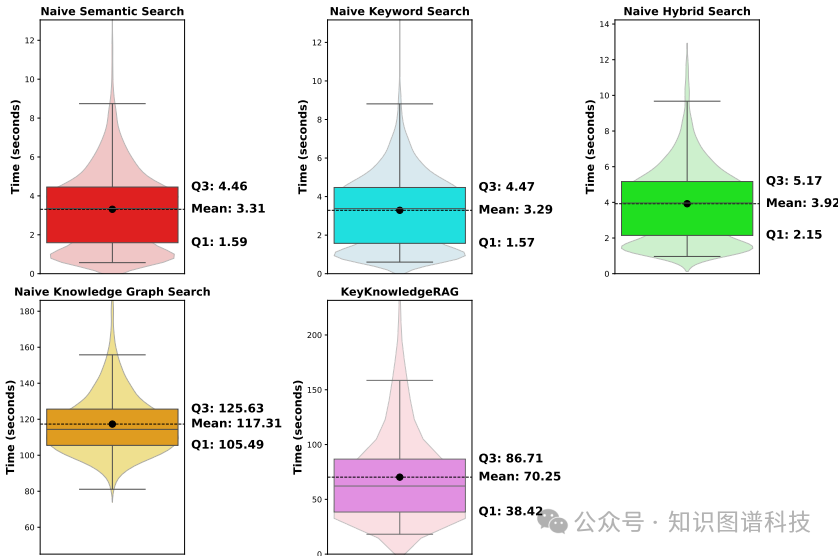
执行时间
K²RAG的平均执行时间为70.25秒,虽慢于纯向量搜索方法,但比朴素的知识图谱搜索(117.31秒)快了约40%。考虑到其更复杂的处理步骤,这个速度表现是成功的。
-
内存占用
K²RAG的VRAM消耗仅为5GB,是所对比的其他检索管道的三分之一,资源效率提升显著。
总体结论
K²RAG框架通过引入语料摘要、混合检索和知识图谱,有效解决了传统RAG方法的几个关键限制。实验表明,它在保持高答案质量的同时,大幅降低了训练时间与资源消耗,并在执行速度上优于传统的知识图谱搜索方案。尽管平均相似度提升幅度有限,但其在高质量答案产出(高Q3值)方面表现突出。未来工作可在更广泛的数据集上测试,并进一步优化知识图谱检索技术。
论文评价
优点与创新
- 时间效率:通过摘要语料库,平均减少93%的训练时间。
- 资源效率:VRAM占用仅为对比管道的三分之一,部署成本更低。
- 答案质量:取得了最高的平均相似度(0.57)和Q3四分位数(0.82)。
- 执行速度:在引入更多处理步骤的情况下,仍比朴素知识图谱搜索快40%。
- 技术整合:巧妙融合知识图谱、混合检索与摘要,提升了系统的综合能力。
不足与反思
- 性能局限:0.57的平均相似度表明,其对大多数问题的普适性提升仍有空间。
- 检索精度:对宽泛的知识图谱搜索的依赖可能影响精度,未来可采用更聚焦的检索策略。
- 泛化能力:需在更多样化的数据集上进行测试,以验证其跨领域的稳定性。
关键问题及回答
问题1:K²RAG框架如何解决“大海捞针”的问题?
K²RAG在索引和查询两个阶段引入了摘要策略。索引前对文档摘要,降低了后续处理的数据量;查询时对检索结果再次摘要,精炼了输入给LLM的上下文。这种多级摘要有效控制了上下文长度,避免了LLM因处理过长文本而性能下降,从而更精准地定位关键信息。
问题2:K²RAG框架在训练时间上有哪些改进?
核心改进源于语料库摘要步骤。该步骤耗时约25分钟,将文档大小平均压缩了89%。由此带来的连锁效应是:稀疏向量库、稠密向量库和知识图谱的创建时间分别减少了89%、97%和94%。知识图谱的创建时间更是从18小时锐减到1小时。整体而言,训练时间平均缩短了93%。
问题3:K²RAG框架在回答准确性和执行时间上有哪些具体表现?
- 回答准确性:平均相似度0.57,为对比方法中最高。其Q3四分位数达到0.82,说明它能对相当一部分问题产出高质量答案,虽然整体平均提升幅度不大,但在高端答案产出上优势明显。
- 执行时间:平均70.25秒,显著快于朴素知识图谱搜索(117.31秒),但慢于单纯的语义、关键词等向量搜索方法。考虑到K²RAG集成了子问题生成、多路检索等复杂步骤,这个速度已是显著的效率优化。
本文是对论文《KEYKNOWLEDGERAG (K²RAG): AN ENHANCED RAG METHOD FOR IMPROVED LLM QUESTION-ANSWERING CAPABILITIES》的解读与总结。想了解更多关于Transformer架构、大模型应用与实践的前沿动态?欢迎访问云栈社区,与更多开发者一起交流学习。 |  发表于 2026-3-26 02:01:50
|
查看: 110|
回复: 0
发表于 2026-3-26 02:01:50
|
查看: 110|
回复: 0
