软件开发本质上是一个清晰的流水线过程:从需求分析到技术设计,再到编码实现、测试验证,最后验收交付。每个环节都有明确的输入、输出和职责边界。
如今,随着LLM能力的显著提升,一个自然的想法便浮现出来:能不能将这条流水线上的每个角色都替换成 AI Agent,直接用自然语言的需求描述来驱动整个开发过程呢?
这不仅仅是一个新奇的想法。对我而言,它有几个非常实际的价值点:
- 验证需求的可行性:快速通过AI生成PRD和技术方案,从而暴露需求中模糊不清的地方。
- 加速原型开发:对于内部工具、脚本服务或API原型,走一遍自动化流水线比自己从头写要快得多。
- 深入理解Multi-Agent架构:只有真正把一个多Agent系统跑起来,才能切实地理解它的瓶颈和设计边界。
于是,我启动了这个项目:目标是构建一个可以通过自然语言驱动、包含PM(产品经理)、架构师、开发、测试、QA(验收官)五个Agent角色的协作流水线。每个阶段的产物(PRD、技术架构、代码文件、测试报告、验收结论)都要求实时可观测、持久化存储,并且验收不通过时能自动打回进行迭代。
核心思路:制品驱动的 Agent 协作
在动手之前,我思考了两种Multi-Agent的协作模式:
- 模式一:对话式(Chat-based)
Agent之间互相发送消息,上下游通过聊天记录传递上下文。这种方式实现简单,但上下文膨胀极快,在长对话中信号与噪音的比例会严重下降。
- 模式二:制品驱动(Artifact-driven)
每个Agent读取上一阶段的结构化输出(如Markdown文件),生成自己的输出,并写入持久化存储。下游Agent只关心“制品”,不关心冗长的“对话历史”。
我最终选择了制品驱动模式。原因很简单:这与真实世界团队的协作方式完全一致。
现实中的产品经理写完PRD就交给架构师,架构师出完技术方案就交给开发。他们之间传递的不是聊天记录,而是文档。AI Agent的协作也应该遵循同样的逻辑。
这种模式带来了几个显著的工程优势:
- 每个Agent的Prompt只需包含“当前制品”,Token消耗可控。
- 制品天然支持版本化(v1, v2, v3…),便于迭代追踪。
- 各个Agent之间高度解耦,可以独立进行测试。
技术架构
整体架构
项目的整体架构如下图所示,它是一个典型的分层式设计:
用户浏览器 (Next.js)
│
│ HTTP REST
▼
FastAPI 后端
│
├── PostgreSQL (流水线状态 + 制品元数据)
├── MinIO (制品文件存储,S3 兼容)
└── Temporal.io (工作流引擎)
│
▼
Worker 进程
│
┌─────────┼─────────┐
│ │ │
PM Agent 架构师 开发 Agent
(LLM) Agent (LLM)
│
测试 Agent
│
QA 验收 Agent
各个组件职责
| 组件 |
职责 |
| FastAPI |
提供REST API、管理依赖注入、集成数据库/MinIO/Temporal客户端 |
| Temporal.io |
负责工作流编排、活动重试、状态持久化与故障恢复 |
| Worker 进程 |
执行Temporal的Activity(每个Agent的调用都是一个Activity) |
| MinIO |
以 {pipeline_id}/{agent_type}/v{n}.md 的路径存储每个阶段的制品文件 |
| PostgreSQL |
存储Pipeline表、AgentState表、Artifact表等元数据 |
| Next.js 前端 |
提供流水线管理界面、实时状态展示和制品查看功能 |
技术选型的关键决策:为什么用 Temporal.io?
最初,我考虑过直接用Python的asyncio任务链来串联各个Agent。但这带来了一个根本性问题:无法优雅地应对LLM调用可能出现的长时间等待和随机失败。
Temporal.io 为我解决了以下核心问题:
- Activity级别的重试:当LLM调用超时或触发频率限制时,Temporal可以自动重试,无需我手动编写复杂的重试逻辑。
- 工作流状态持久化:即使Worker进程崩溃重启,工作流也能从上次中断的地方继续执行,不会丢失进度。
- 强大的可观测性:通过Temporal Web UI,我可以清晰地看到每个Activity的执行历史、重试记录、输入和输出,极大方便了调试。
- Workflow的确定性要求:Temporal基于事件重放的机制要求Workflow代码必须是确定性的,这倒逼我将所有非确定性的LLM调用都封装到Activity里,使得整体架构更加清晰和规范。在设计和实现这类分布式系统时,一个可靠的工作流引擎至关重要。
Agent 工作流程详解
流水线执行序列
整个流水线被定义为一个Temporal Workflow,其执行序列如下:
create_pipeline (API)
│
▼
[Temporal Workflow: PipelineWorkflow]
│
├─ 1. PM Agent Activity
│ 输入: 用户需求文本
│ 输出: PRD.md → MinIO + DB
│
├─ 2. 架构师 Agent Activity
│ 输入: PRD.md 内容
│ 输出: architecture.md → MinIO + DB
│
├─ 3. 开发 Agent Activity
│ 输入: PRD.md + architecture.md
│ 输出: 各代码文件 → MinIO + DB(每个文件一条 Artifact 记录)
│
├─ 4. 测试 Agent Activity
│ 输入: 代码文件列表 + PRD.md
│ 输出: test_report.md → MinIO + DB
│
├─ 5. QA 验收 Activity
│ 输入: PRD.md + test_report.md
│ 输出: qa_verdict.md → MinIO + DB
│ │
│ ┌────┴────┐
│ 通过 不通过
│ │ │
│ COMPLETED iteration_count < max?
│ │ │
│ 是 否
│ │ │
│ 回到 PM FAILED
│ (新迭代开始)
└─
有趣的是,这个项目本身在很大程度上也是用AI工具开发的,这提供了一个很有意思的“元”视角。
oh-my-claudecode(OMC) 是Claude Code的一个多Agent编排插件。在开发本项目的过程中,我大量使用了它的几种模式:
Autopilot 模式
/oh-my-claudecode:autopilot
为 pipeline 删除功能添加后端 API,包括:
- DELETE /api/pipelines/{id} 端点,仅允许 failed/completed 状态
- 删除对应 MinIO 所有制品文件
- 删除数据库记录(注意 FK 约束顺序)
Autopilot模式会自动走完“需求分析 → 技术规划 → 并行实现 → QA验证”的完整循环,几乎不需要我逐步指导。
Ralph 模式(自驱循环)
对于需要多轮修复的任务(比如LLM输出的后处理),Ralph模式会持续执行直到满足设定的验收标准:
/oh-my-claudecode:ralph
修复 developer_agent.py 中文件内容被 markdown 代码围栏污染的问题,
验收标准:生成的 .py 文件不含 ``` 字符
Deep-interview → Ralplan → Autopilot 三段式流水线
对于更复杂的功能需求,我总结出最高效的协作路径:
/deep-interview:通过苏格拉底式提问澄清需求,输出低歧义度的规格说明。/ralplan:由Planner、Architect、Critic三个Agent达成共识,输出详细的实现计划。/autopilot:检测到已有的ralplan计划后,直接跳过规划阶段,从执行阶段开始。
通过用AI开发AI系统,我的最大体会是:AI工具能极大地加速“已知模式”的实现(如CRUD、API、标准组件),但在“未知领域”的探索和关键决策上(例如,如何设计Prompt来防止Agent过度工程化),仍然需要人的深度参与。AI是生产力的放大器,而非决策者。
全流程演示与效果展示
-
规划与生成:安装oh-my-claudecode插件,在Autopilot模式下,向它描述你想要构建的多Agent协作工作流。

-
运行本地项目:Autopilot运行完成后,会生成一个完整的本地项目。
执行 make up && make migrate 命令来启动项目。

-
访问与使用:打开浏览器访问 http://localhost:3000。
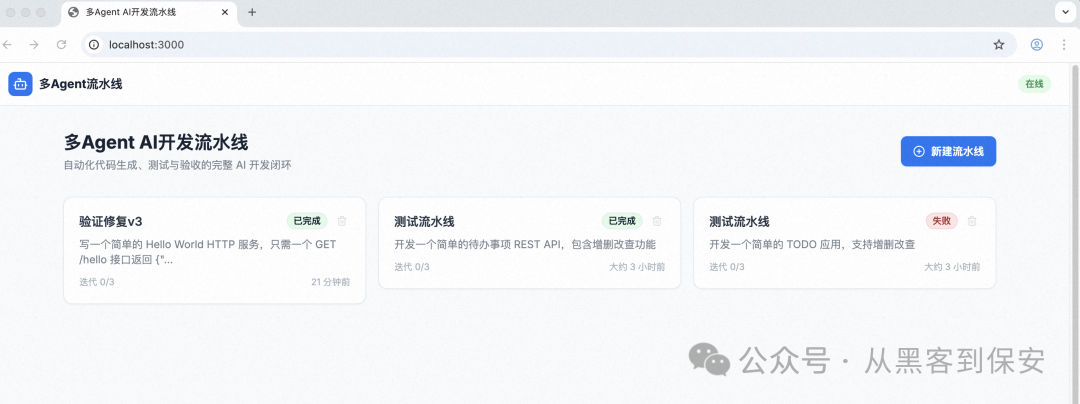
-
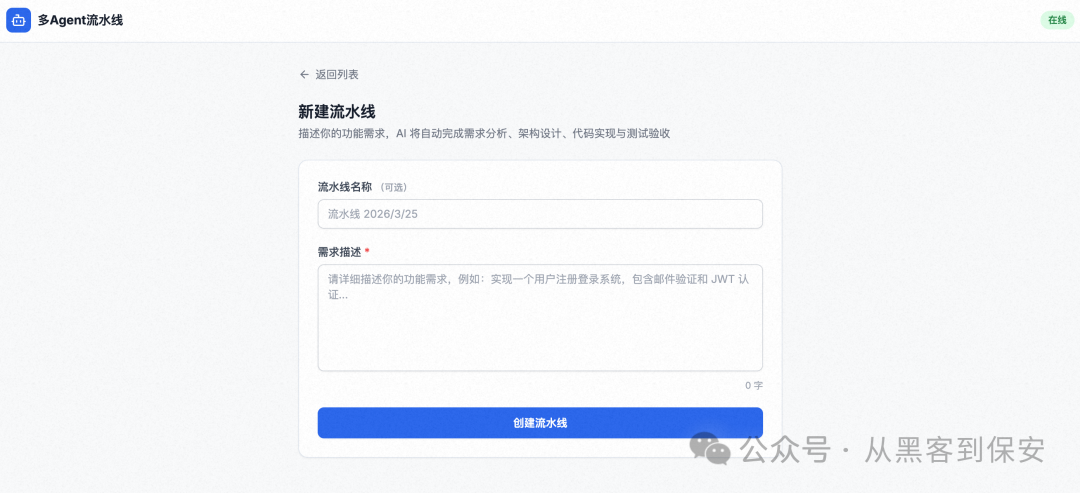
创建流水线:在Web界面中创建一个新的流水线,并详细描述你的功能需求。
-
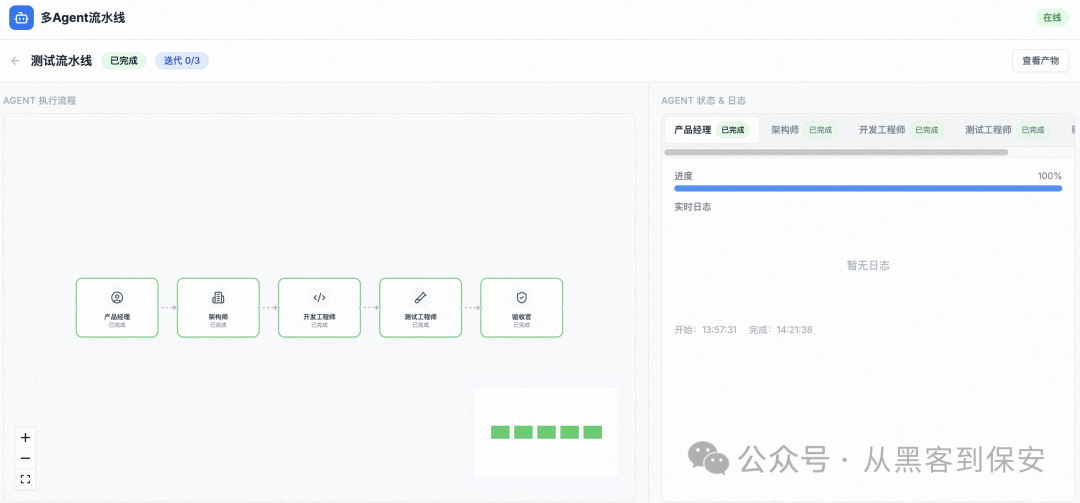
观察执行:创建后,系统会自动开始执行。你可以在详情页观察每个Agent的实时状态和进度。
-
查看产物:执行完成后,可以查看每个Agent生成的详细产物,例如产品经理输出的PRD和架构师输出的技术文档。

应用场景发散
这个基于制品驱动和工作流引擎的架构并不局限于代码生成,稍加修改就能适配许多其他场景:
- 内容创作流水线:选题策划 → 大纲撰写 → 正文撰写 → 编辑校对 → SEO优化 → 发布审核。技术文章、营销文案都可套用此流程。
- 数据分析流水线:需求理解 → 数据探索 → 分析方案 → Python脚本生成 → 结论撰写 → 可视化。用户用自然语言描述分析目标,链路自动完成。
- 安全审计流水线:代码扫描 → 漏洞分类 → 风险评估 → 修复建议 → 审计报告。每个Agent专注于安全的一个维度,提升准确性。
- 法律/合规文档审查:文档解析 → 条款提取 → 风险识别 → 合规对比 → 修改建议 → 审查报告。适用于合同审查、隐私政策检查等。
- 产品需求到测试用例:PRD解析 → 功能点提取 → 测试场景设计 → 测试用例生成 → 边界条件补充 → 测试计划。帮助QA团队快速生成结构化测试用例。
- 多语言本地化流水线:原文解析 → 直译(多语言并行)→ 本地化润色(各语言独立)→ 术语一致性检查 → 回译验证 → 格式化输出。
- 招聘筛选流水线:JD解析 → 简历解析 → 岗位匹配 → 技能评估 → 背景核实提示 → 面试问题生成。标准化评估维度,减少人工初筛时间。
- 智能运维变更流水线:变更申请解析 → 影响分析 → 风险评估 → 变更方案生成 → 回滚方案 → 审批摘要。将变更申请拆解为结构化风险评估。
当前局限与演进方向
坦率地说,目前的系统还有很多不完善的地方。
-
LLM 输出质量不稳定
当前最突出的问题是LLM输出的可预测性。相同的Prompt,不同调用的结果可能差异很大,例如文件路径混入描述文字、代码包含多余Markdown格式、生成空文件等。
改进方向:引入结构化输出(用JSON Schema约束)替代纯文本,并用Pydantic模型验证LLM响应。
-
Agent 之间缺乏真正的“对话”
目前每个Agent只能单向读取上游制品,没有澄清机制。如果PRD存在歧义,开发Agent只能猜测,无法向PM Agent提问。
改进方向:在Activity内部增加“澄清循环”——当Agent检测到输入不清晰时,生成一批澄清问题,等待上游Agent(或人工)答复后再继续。
-
开发 Agent 生成的代码无法执行验证
测试Agent目前仅针对代码文本编写测试报告,并未实际执行代码。通过QA验收的代码不一定能正常运行。
改进方向:集成代码执行沙箱(如E2B、Docker exec),让测试Agent真正运行生成的代码,捕获运行时错误并反馈给开发Agent进行迭代。
-
成本控制
一条完整的流水线(5个Agent,每个调用1-3次LLM)大约消耗50k-200k tokens。对于简单任务,成本偏高。
改进方向:1) 按任务复杂度动态选择模型(简单任务用Haiku,复杂任务用Opus);2) 引入缓存机制,对相似需求复用已有的上游制品。
-
人工介入节点缺失
目前流水线是全自动的,但现实中,PRD或技术方案完成后可能需要人工确认。
改进方向:利用Temporal.io支持的Signal机制,在关键节点暂停Workflow等待人工输入,实现“人在环中”(Human-in-the-loop)的协作模式。对于更复杂的系统,你可能需要在 后端 & 架构 层面进行更深入的设计。
总结
通过这个项目的实践,我对Multi-Agent系统形成了几个核心认识:
- 制品驱动优于对话驱动:在工程化场景中,结构化的文档比松散的对话记录更稳定、更易于版本化管理,也更符合人类团队的协作习惯。
- 工作流引擎是基础设施:不要尝试用裸
asyncio来串联Agent。像 Temporal.io 这类引擎已经系统性地解决了重试、幂等、状态持久化等分布式难题,让你能专注于Agent本身的业务逻辑。
- Prompt 工程的本质是边界管理:让AI“做得好”不难,难的是让AI“不做多余的事”。坚持最小化原则,给予与项目规模匹配的技术选型约束,比任何鼓励它“多做一点”的提示都更重要。
- 用AI开发AI系统是可行的加速路径:OMC的Autopilot模式处理了本项目超过60%的编码工作(样板代码、CRUD、前端组件)。剩下的40%是架构决策、调试和Prompt调优——这部分目前仍然高度依赖人的经验和判断。探索这些前沿的人工智能应用模式,正是技术社区的乐趣所在。
- 从小处开始,逐步扩展:不要一开始就追求设计一个完美的系统。先让两个Agent跑通制品流转,验证核心机制,再逐步加入更多角色和能力。系统的复杂性是演化出来的,而非一次性设计出来的。
Multi-Agent协作系统仍处于早期阶段,许多最佳实践尚在探索中。但方向是清晰的:AI不会替代整个团队,但一个懂得如何有效协调多个AI Agent 的开发者,其生产力完全有可能媲美一个小型团队。如果你对这类工程化AI应用感兴趣,欢迎在 云栈社区 交流探讨,共同学习成长。
 发表于 2026-3-26 02:46:14
|
查看: 202|
回复: 0
发表于 2026-3-26 02:46:14
|
查看: 202|
回复: 0
