在嵌入式系统开发中,数据结构的选择至关重要,它直接决定了系统的实时性、内存占用和代码稳定性,绝不能随意选用。以往,我们可能习惯使用简单的链表或数组来管理有序数据,但普通链表的查询效率低下(O(n)),而数组的插入删除又涉及大量数据搬移。要在此基础上实现高性能,挑战不小。
诸如红黑树、AVL树这类平衡二叉树性能虽好,但其逻辑复杂,理解起来就有门槛,代码量也大。若自行实现,调试和维护都是难题。在资源受限、追求代码精简的嵌入式场景中,引入它们有时显得“杀鸡用牛刀”。
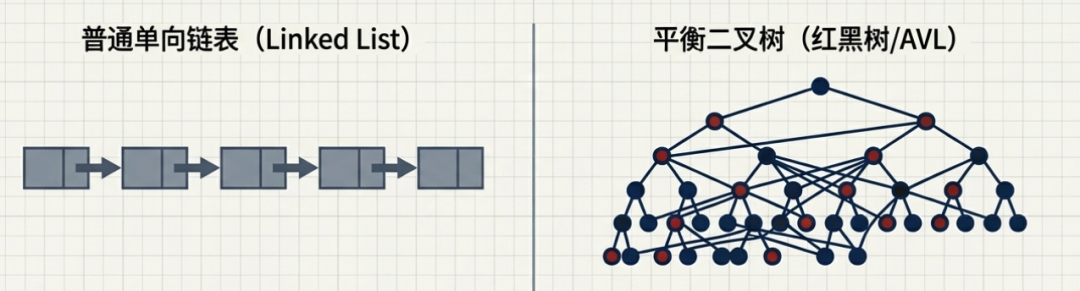
那么,有没有一种更平衡的选择呢?今天的主角——跳表(Skip List)——就是一种介于链表和平衡树之间的轻量化有序数据结构。它的核心是 链表+多级索引 的设计,以可控的额外空间为代价,换取了接近二分查找的高效操作。这种“空间换时间”的极简思路,使得它非常契合嵌入式系统的需求,其思想与MMU中的多级页表有异曲同工之妙。
1 单链表的瓶颈
在嵌入式开发中,普通链表因其无需连续内存、节点可动态增删、实现简单而备受青睐。然而,它的核心缺陷在于 查找效率极低:由于节点离散存储,查找时必须从头节点开始逐个遍历。这意味着查找、插入、删除操作的平均时间复杂度均为 O(n)。
当应用需要管理的有序数据量增长时(例如管理多个定时器或多个任务队列),这种线性遍历会变得非常耗时。这不仅可能导致关键代码执行延迟,还会挤占宝贵的CPU时间,最终影响整个系统的实时响应能力。
2 跳表:带多级索引的高效链表
跳表由 William Pugh 于 1989 年提出。其核心设计是在原始有序链表之上,建立多级稀疏索引层。通过索引,可以快速跳过大量无效节点,实现类似二分查找的检索效率。
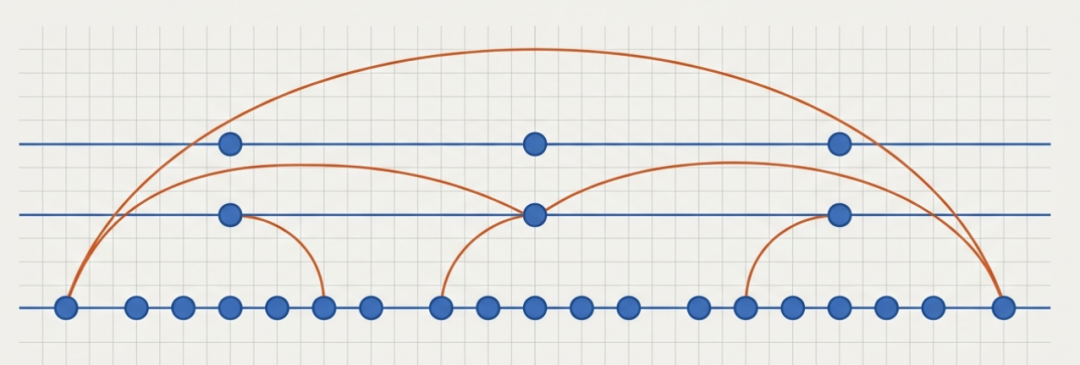
跳表的结构主要分为两层:
- 原始数据层:最底层的完整有序链表,存储所有实际数据,与普通单链表无异。
- 多级索引层:在原始链表的基础上,逐层抽取出部分节点作为“快车道”。上层索引是下层索引的子集,层数越高,节点越稀疏。
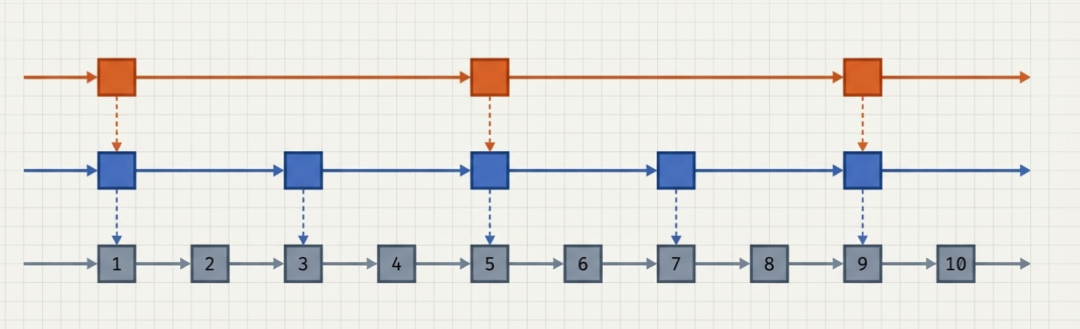
举个例子:假设原始链表从小到大存储了数字1到10。第一级索引可能抽取节点1, 3, 5, 7, 9;第二级索引可能进一步抽取节点1, 5, 9。当我们要查找数字8时,流程如下:
- 从顶层(第二级)索引开始,发现8大于5但小于9,于是快速定位到节点5。
- 下降到第一级索引,从节点5向后找到节点9,确定目标在5和9之间。
- 最后下降到原始数据层,从节点5开始,经过6、7,最终找到节点8。
整个过程跳过了许多不必要的比较,无需像遍历单链表那样逐个访问节点1到7。
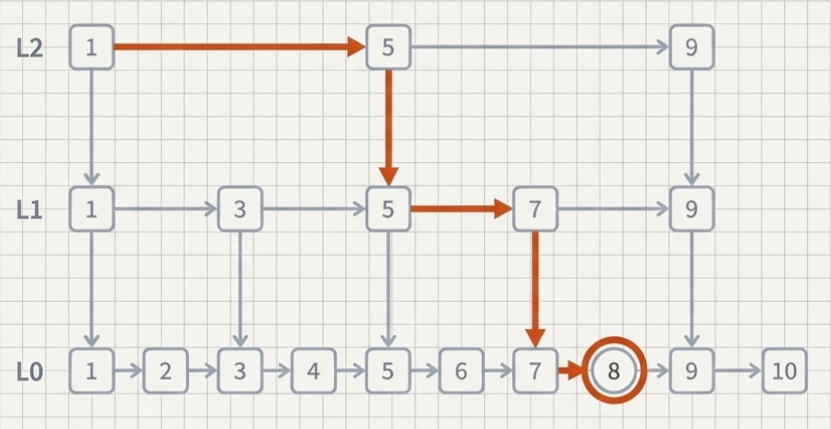
3 跳表核心操作与复杂度分析
跳表的主要操作——查找、插入、删除——都遵循“从高层索引向下逐层缩小范围,最终在底层定位”的步骤。它无需像红黑树或AVL树那样进行复杂的旋转或重新平衡操作,实现逻辑简洁明了。
- 查找操作:从最高层索引开始,向右遍历直到下一个节点的值大于等于目标值,然后向下一层继续此过程,直至底层。平均时间复杂度为 O(log n)。
- 插入/删除操作:首先执行查找以定位精确位置,然后完成节点的增删,并随机决定新节点需要建立到第几层的索引(或删除节点时更新对应索引)。平均时间复杂度同样为 O(log n)。
- 空间复杂度:这是典型的“空间换时间”。索引层数通常是概率性的,在实践中(如Redis的实现),节点层数的期望值是常数,因此整体额外空间复杂度为 O(n),且常数因子很小,远低于哈希表等数据结构的内存开销。在嵌入式场景中,通常3-5层索引就能带来显著的性能提升。
4 跳表在嵌入式中的应用场景
应用场景1:软件定时器管理
在嵌入式系统中,软件定时器模块常用于实现延时、周期任务和超时判断(如串口接收超时)。传统方案常采用有序单链表管理定时器,按超时时间排序。每次系统Tick中断时,都需要遍历链表以找到最早超时的定时器。当定时器数量较多时,遍历开销会显著增加,影响中断响应速度。

跳表优化方案:
将定时器按 超时时间戳 构建为有序跳表。底层链表存储所有定时器节点,上层建立2-3层基于超时时间的索引。这样,在Tick中断中查找最早超时定时器的耗时可以从 O(n) 降至接近 O(log n)。这对于工业控制等拥有大量定时任务的嵌入式设备尤为重要,能有效降低因定时器管理导致的中断阻塞风险。
应用场景2:轻量级RTOS任务调度
在一些轻量级实时操作系统中,任务调度的核心是就绪队列,系统需要快速选出优先级最高的任务来执行。许多RTOS采用“位图+链表”的方式:位图快速定位非空优先级,同一优先级下的任务再用链表管理。这种方式下,同优先级内的任务调度仍需遍历链表。
若采用红黑树来全局管理所有就绪任务,固然能获得稳定的 O(log n) 调度性能,但代码复杂度和体积对于资源紧张的MCU来说负担过重。
跳表优化方案:
用跳表来实现任务就绪队列。所有任务按 优先级 构成有序跳表(优先级数字越小通常优先级越高)。配合多级优先级索引,系统可以快速定位最高优先级任务所在的区间,并在该区间内高效操作。这种方案在保持接近 O(log n) 调度效率的同时,代码实现远比红黑树简单,更易于在MCU上移植和调试,同时天然支持任务优先级的动态调整。
结语
总而言之,跳表凭借其简洁的实现逻辑、可控的内存开销以及接近平衡树的查询性能,在嵌入式系统数据结构选型中提供了一个非常优秀的折中方案。它尤其适用于那些需要高效有序访问,但又对代码复杂度和内存占用敏感的场景,例如定时器管理和任务调度。当你在嵌入式项目中面临链表太慢、平衡树太重的困境时,不妨考虑一下跳表这个“轻量级的多面手”。
在云栈社区,你可以找到更多关于数据结构和嵌入式系统优化的深度讨论与实战分享。
 发表于 2026-3-26 04:39:03
|
查看: 164|
回复: 0
发表于 2026-3-26 04:39:03
|
查看: 164|
回复: 0
