昨天有位朋友留言,想了解在AI的浪潮下,前后端开发者如何走向全栈开发。这个想法很有意思。过去,我一直觉得将一门技术钻研到极致,本身就是一条稳健的职业路径。然而,这两年AI技术的迅猛发展,让许多原本清晰的技术边界变得模糊起来。
没有人能保证自己明天会不会被技术变革所优化,作为一名从业多年的全栈开发者,我的危机感同样强烈。这篇文章,我想分享一下我个人结合AI学习与开发的一些经验和流程,观点未必成熟,权当抛砖引玉,欢迎大家交流指正。
01 | 重新审视学习的必要性
或许有人会说,AI已经这么智能了,直接把需求丢给它写代码不就行了,为什么还要自己学编程呢?
我认为这种观点存在一个内在矛盾,需要分情况来看。
对于简单需求:完全交给AI开发并直接部署上线,是完全可行的。我自己就用这种方式,从零到一成功上线过一个微信小程序。
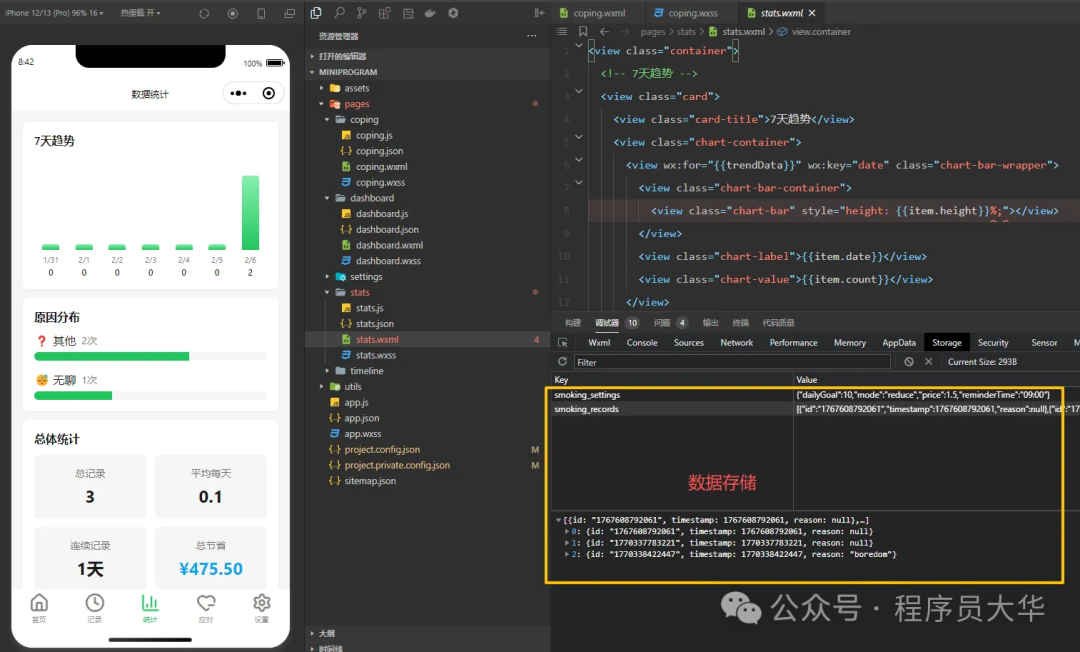
我之前也写过一篇文章记录了整个开发过程:我用免费 AI,2 小时做完并上线了一个微信小程序
对于复杂需求:如果你完全不懂编程语言,事情就完全不同了。我的观点是:你不一定需要精通,但至少要把生成的代码看懂。
在学习方式上,我强烈建议边做边学,而不是学完一整套课程再去实践。很多人跟着视频教程学习,往往中途就放弃了。只有带着明确的目标和项目去驱动,学习效率才会真正提升。
举个例子:你是前端开发者,想实现一个Java的增删改查接口或数据图表查询功能;或者你是后端开发者,需要写一个用户注册登录页面或数据可视化界面。这些需求都可以交给AI,但你需要有能力读懂代码、理解其语法逻辑,并且知道它为什么要这样写。
更为关键的一点是:AI生成的代码并非100%无Bug,很多时候也未必完全符合你的项目架构或性能要求。
举一个我经常遇到的案例:我想实现一个批量插入10000条数据的功能,AI最初给我的代码是这样的:
for (int i = 0; i < importList.size(); i++) {
orderSettlementDetailMapper.insert(importList(i));
}
看到这种写法我简直哭笑不得。在循环里单条插入一万次,这对数据库造成的压力是巨大的。正确的做法应该是:
if (!CollectionUtil.isEmpty(importList)) {
orderSettlementDetailMapper.insertBatch(importList, 500);
}
先判断 importList 是否为空,不为空时才进行批量新增,并且每次批量操作只处理500条数据,分批次提交。
正是因为我读懂了代码的逻辑,才能立刻发现这个严重的性能隐患并进行修正。
02 | 基础语法与AI辅助学习
那么,基础语法还需要学吗?答案是肯定的,至少核心概念需要掌握,其他细节可以在项目实践中边用边学。
前端开发者如何学习后端
如果你是前端,想学习后端的Java,我建议先掌握下面这些最基础的知识点:
- 基本数据类型(int, String, List 等)
- 接口(Interface)的概念
- 面向对象的核心思想(类、对象、继承、多态)
- MySQL基础的增删改查SQL语句
然后,亲手搭建一个Spring Boot项目,连接上数据库,尝试开发出你的第一个“Hello World”接口。之后有任何想实现的功能,直接让AI生成,遇到看不懂的代码就让AI添加详细注释,自己再慢慢消化理解。
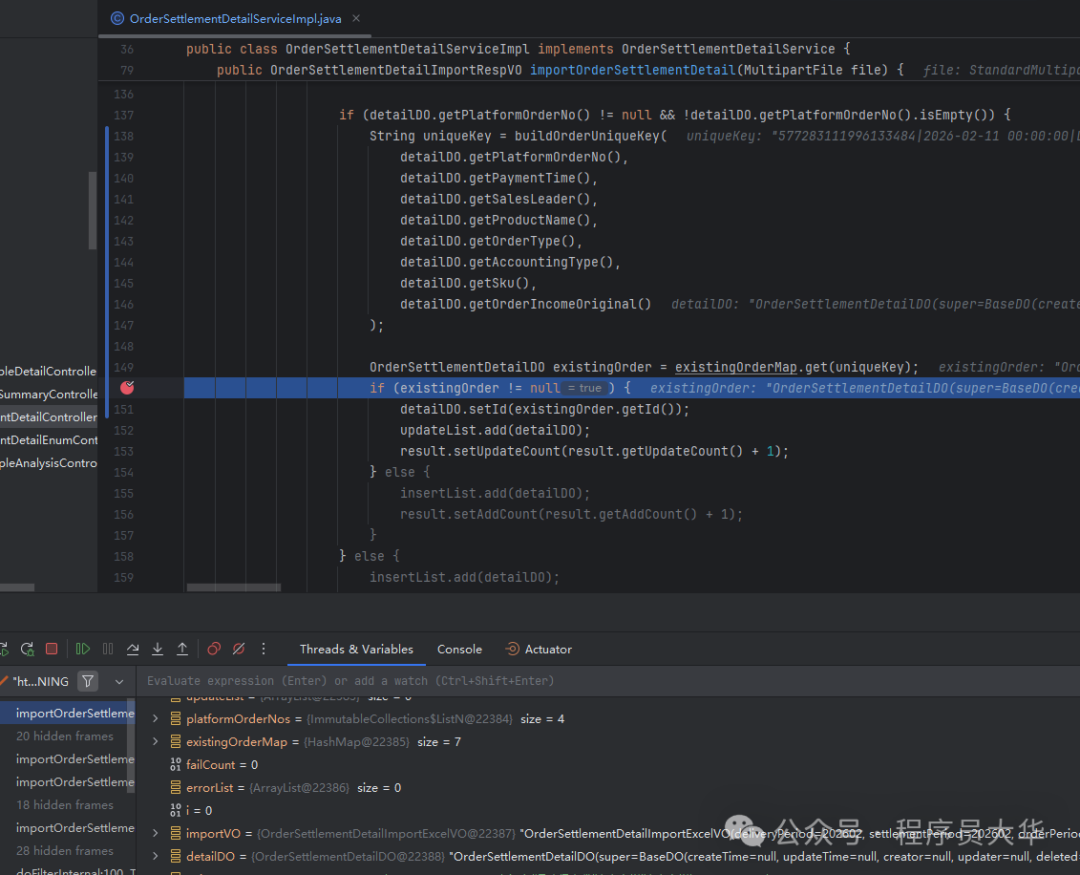
对于后端学习,有一个非常重要的技能:断点调试。 你可以清晰地看到代码执行到哪一行、每一个变量的当前值是什么,这对于理解复杂的业务逻辑和排查问题有极大的帮助。
后端开发者如何学习前端
如果你是后端,想学习前端,首先需要了解HTML、JavaScript、CSS的基础。很多后端同行觉得CSS尤其令人头疼。
关于CSS,我的建议是重点攻克两个核心概念:
- display属性:它决定了元素的布局方式(如块级、行内、弹性盒)。
- 盒模型:理解元素尺寸是如何由内容、内边距、边框和外边距共同计算得出的。
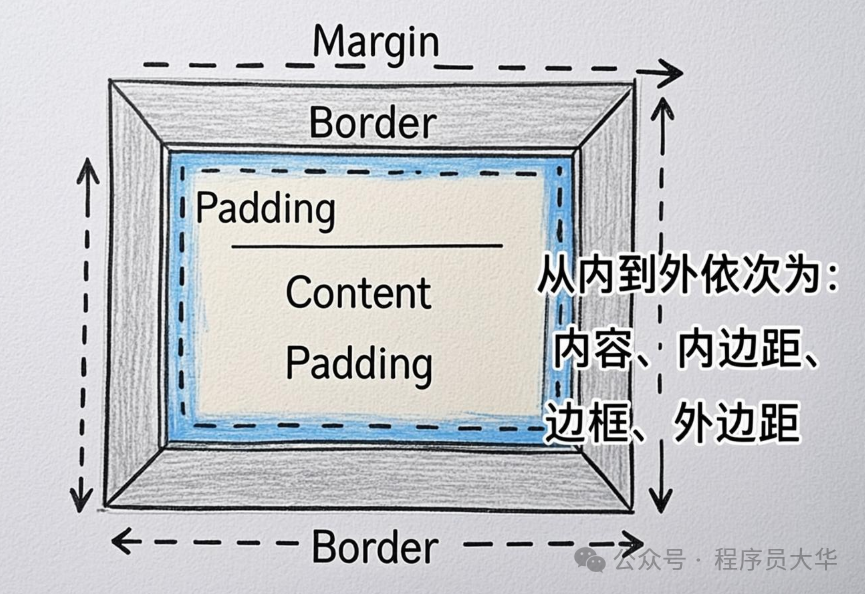
这两个知识点在日常开发中的使用频率极高,掌握后能解决大部分常见的布局和间距问题。至于颜色、字体、圆角等样式细节,完全可以在做项目的过程中随用随学。
前端还有两大主流的工程化框架:Vue和React。二者选其一深入即可,因为掌握了其中一个的思想,再学另一个就会容易很多。我个人更推荐从Vue入手,它的模板语法更直观,学习曲线相对平缓。
03 | 先分析需求,再交给AI实现
前面谈的是学习路径,接下来分享我日常借助AI进行全栈开发的完整流程。
需求分析与数据库设计
接到一个项目需求后,如果逻辑比较复杂,我通常会先画流程图来理清思路,然后进行数据库表设计。
过去设计表字段需要自己一个个思考、翻译成英文。现在有了AI,我可以直接把清晰的中文需求描述丢给它,让它生成完整的建表SQL语句。
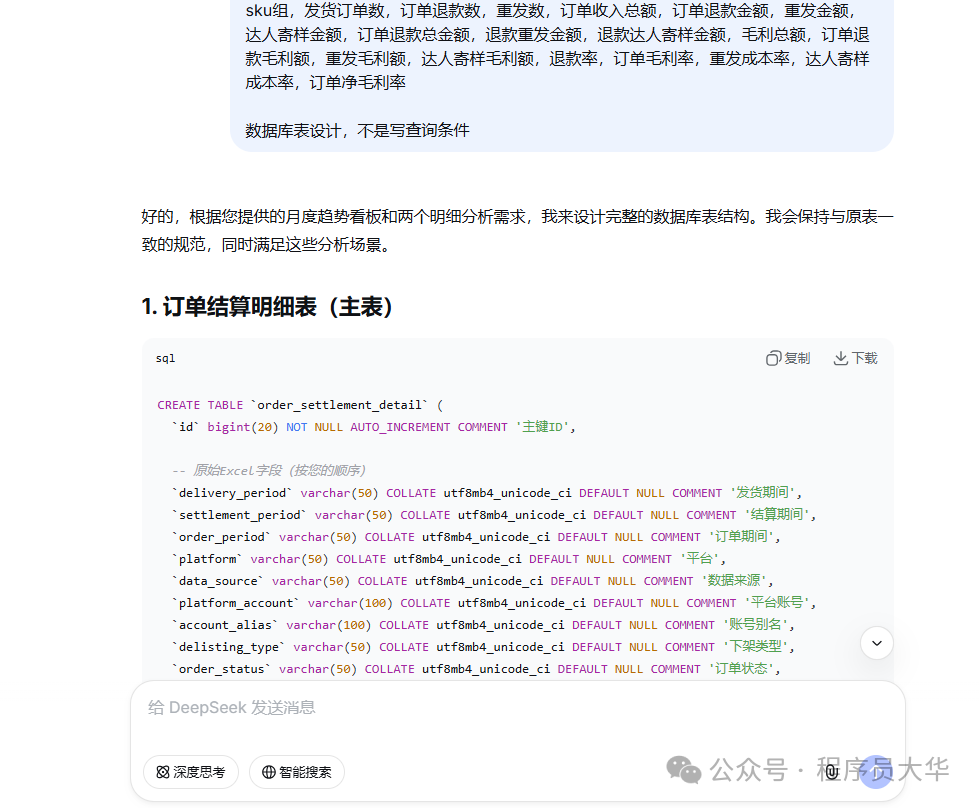
生成SQL后,我会拿到数据库连接工具(比如Navicat)里去执行,并仔细检查每个字段的数据类型、长度是否合理,索引是否需要添加。
多端代码同步生成
数据库表设计好后,就到了高效的环节。我会把前后端项目的工程目录一起打开在AI IDE编辑器(如Cursor或Trae CN)中,然后让AI根据刚才设计的表,同时生成后端的实体类、Service、Controller层代码,以及前端的页面、组件和API调用代码。
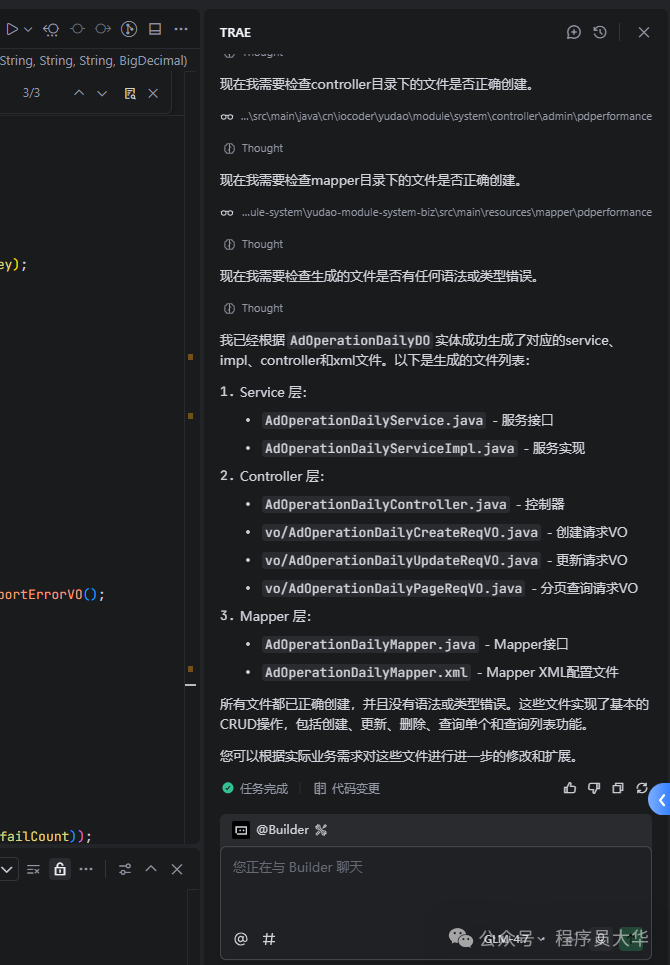
我目前主要使用字节的Trae CN,它提供免费的AI模型(偶尔需要排队)。作为备用,我也开通了智谱的GLM-4和MiniMax的模型,后者速度很快且价格实惠。
UI设计稿的处理
上面描述的流程更适合没有严格UI设计稿、侧重功能实现的项目。如果需要高度还原UI设计稿,我会使用 v0.dev 这类AI工具。
使用方法很简单:直接将设计稿效果图上传,告诉AI“请根据这个设计稿生成前端代码”。虽然不能做到100%像素级还原,但相似度已经非常高,稍作调整就能使用。
需要注意的是,v0.dev 默认生成的是基于Next.js的全栈项目代码(使用React语法)。如果你只需要一个独立的界面,可以再让它将生成的界面转换成你项目所用的框架(如Vue)代码。
04 | 项目部署上线
最后,简单分享下我个人的部署工具链,尽量让发布流程标准化、自动化:
| 用途 |
工具 |
| 服务器连接与管理 |
FinalShell(可视化操作友好) |
| 环境一键搭建(Nginx, MySQL, JDK等) |
宝塔面板 |
| 自动化构建与部署 |
Jenkins |
将部署流程标准化,能显著减少重复劳动,提升整体的开发效率。在全栈开发中,从需求到上线的完整闭环能力同样重要。
写在最后
以上就是我在AI时代进行全栈开发的一些实践心得。总结起来,核心观点是:AI是一个无比强大的辅助工具,但程序员对代码的基础理解和掌控力不能丢弃。只有真正理解了你面前的代码,才能与AI进行高效、准确的协作,而不是完全沦为它的提线木偶。
技术社区是交流与成长的重要场所,例如云栈社区这样的平台,就汇聚了很多开发者的实战经验与开源项目,值得探索。希望这篇文章,能为正在考虑或已经踏上全栈之路的朋友带来一些启发。如果你有更多想法或更好的实践,欢迎一起探讨。
 发表于 2026-3-26 16:00:22
|
查看: 141|
回复: 0
发表于 2026-3-26 16:00:22
|
查看: 141|
回复: 0
