开源世界正经历着一场关于信任与效率的静默变革。
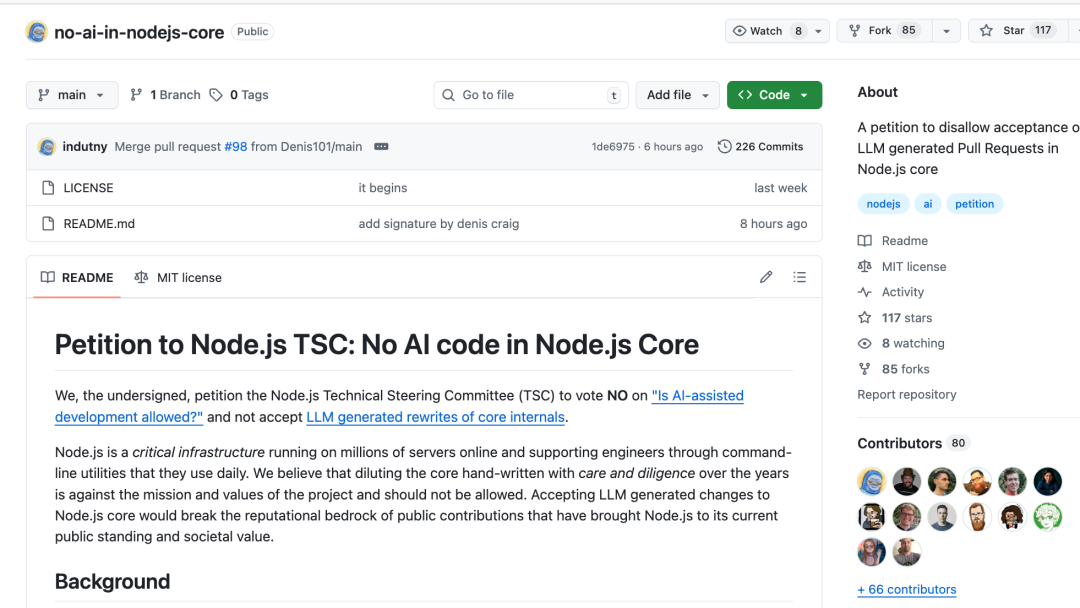
上周,一份要求 Node.js 核心项目禁止接受 AI 生成代码的请愿书在开发者社区引发广泛关注。发起者是 Fedor Indutny,他不仅是 Node.js 技术指导委员会前成员,更是 Node.js TLS 模块的主要作者。这份请愿书获得了包括 Kyle Simpson、Andrew Kelley 在内的 80 多位核心贡献者的联名支持。
然而,这场争论远非简单的“技术工具站队”,它触及了一个根本性问题:在 AI 席卷而来的时代,构建在人与人协作与信任之上的开源社区运作模式,是否还能稳固如初?
事件的源头:一个由 AI 辅助的庞大 PR
事件的中心人物是 Matteo Collina,他是 Node.js 核心团队的资深成员,也是 Fastify 框架和 Pino 日志库的创建者。
今年1月,他提交了一个为 Node.js 添加虚拟文件系统(VFS)功能的 Pull Request (PR)。这个功能本身备受期待,但其规模和实现方式引发了波澜:该 PR 包含了近 19000 行代码。更重要的是,Matteo 在 PR 描述中坦诚地写道,他“使用了大量 Claude Code token 来完成这个工作”。

这段描述如同一颗投入平静湖面的石子。两个月后,Fedor Indutny 在 GitHub 上创建了一个名为 no-ai-in-nodejs-core 的仓库,用以收集签名。请愿书的标题直截了当:“Petition to Node.js TSC: No AI code in Node.js Core”。
反对者的核心担忧:不止于代码本身
如果仅看标题,可能误解这是一场对新技术无理由的抵制。但深入阅读请愿书内容,你会发现反对者的忧虑是多层次且深刻的。
- 巨大的审查负担:无论是人还是 AI 写的,一次性向代码审查流程提交 19000 行代码都极不合理。有人估算,按照正常的审查节奏,这足以消耗一位 Reviewer 数月时间。实际上,该 PR 开放了两个多月,经历了 128 次审查和 108 条评论,至今仍未合并。
- 潜在的法律风险:开源贡献者通常需要签署贡献者许可协议,声明代码是其原创或来自合法授权来源。但 AI 生成的代码,其训练数据混合了海量的开源代码,版权归属模糊不清。尽管 OpenJS 基金会的法律顾问认为没有问题,但许多开发者对此并不买账。
- 对协作与学习本质的冲击:开源社区运行着一套隐性的社会契约——我贡献代码,你审查代码,双方在此过程中交流、学习、建立信任。然而,如果代码由 LLM 生成,审查者花费时间指出的问题和给出的建议,实际上没有一个“人”在学习。请愿书中尖锐地指出:LLM 没有学习能力,花在审查 AI 代码上的时间可能是重复的浪费。
- 隐性的经济门槛:使用 Claude Code 这类高级 AI 编程工具需要付费。如果社区普遍接受 AI 生成的大量代码,那么审查者为了验证和复现问题,也可能需要付费使用同等工具。这在无形中为参与开源贡献设立了一道经济门槛,与开源“平等参与”的精神有所背离。
支持 AI 辅助的声音:工具无罪,质量至上
当然,反对禁令的声音同样强烈。
核心论点非常明确:代码质量应该是唯一的评判标准。无论代码是用 Vim、VS Code 还是 AI 生成的,只要它清晰、高效、安全,就应该被接纳。根据使用的工具来区别对待贡献,本身就是一种偏见。
另一个现实的问题是:这项禁令几乎无法有效执行。如果 Matteo 没有主动声明使用了 AI,谁能准确分辨?未来的贡献者只需保持沉默,这条规则便会形同虚设。
Node.js 技术指导委员会成员 James Snell 也在 PR 评论中为 Matteo 辩护。他认为,Matteo 显然在持续投入精力迭代这个功能,是一位值得信赖的长期贡献者,其工作成果不应因使用的工具而被否定。
更大的图景:这不是 Node.js 独有的困境
类似的争议已在多个开源社区浮现。Linux 内核社区去年就有过关于 AI 生成补丁的讨论,QEMU 项目甚至在提交信息中明确表明了立场。Python 和 Rust 社区也相继出现了相关提案。Node.js 事件之所以格外引人注目,是因为争论双方都是社区内极具影响力的核心成员,将矛盾彻底公开化了。
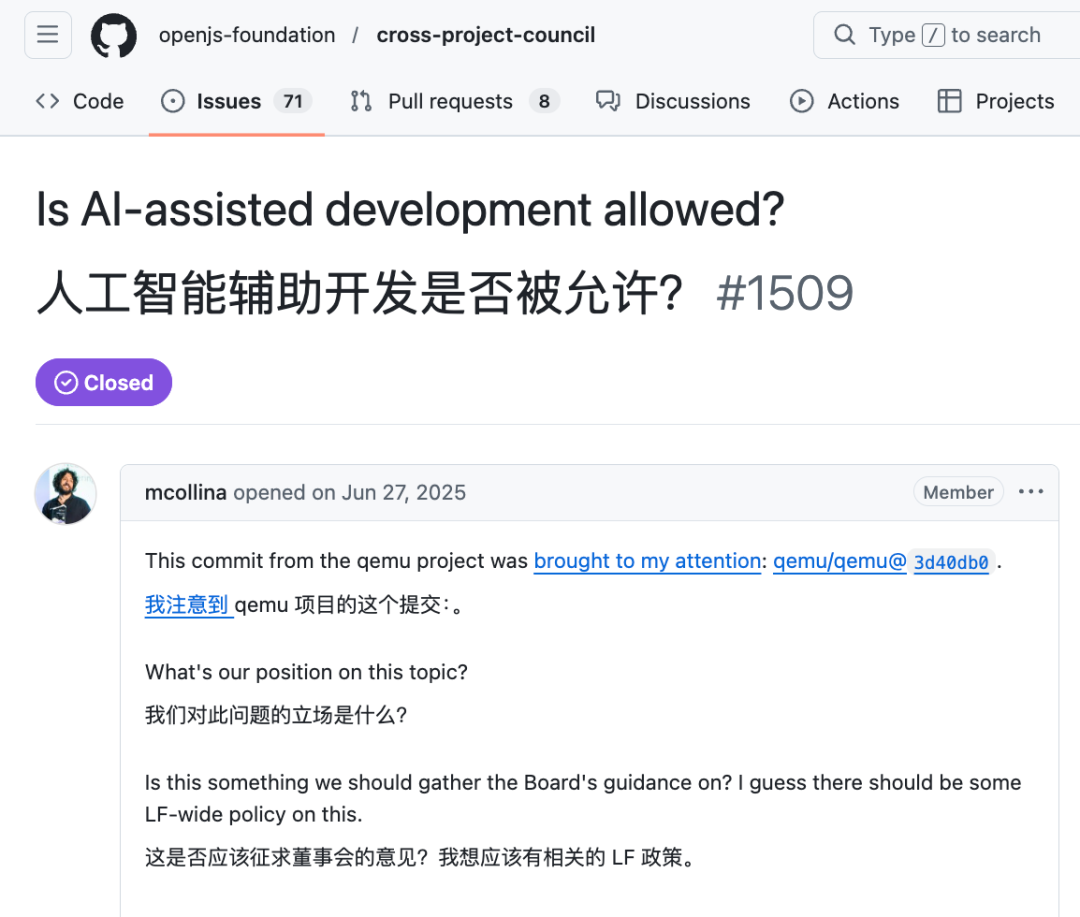
有意思的是,Matteo Collina 本人早在 2025 年 6 月就在 OpenJS 基金会提出了一个议题,标题正是“Is AI-assisted development allowed?(人工智能辅助开发是否被允许?)”。这表明他本人也意识到,社区需要对此形成一个明确的共识。
更值得注意的是,另一位 Node.js 核心贡献者 Stephen Belanger 在同一个 VFS PR 的评论区也分享了自己的实验性代码,并同样标注了“大量 LLM 辅助”。这说明,在核心贡献者圈层,使用 AI 辅助开发早已不是秘密,只是未曾被摆上台面公开讨论。
对普通开发者的影响:规则将塑造未来的协作方式
你或许认为这只是“神仙打架”,与己无关。但这场讨论的走向,将切实影响每一位开发者。
如果主流开源项目开始限制 AI 生成代码,那么习惯使用 Copilot、Cursor、Claude Code 等工具的开发者,在向开源项目提交贡献时必须格外谨慎。“辅助”与“生成”的边界在哪里?自动补全算不算?这些问题目前都没有标准答案。
反之,如果完全不加限制,海量 AI 生成的代码涌入开源项目,将成倍增加维护者的审查压力。许多维护者本是利用业余时间义务劳动,额外的 AI 代码筛查负担,只会加剧开源维护者“过劳”的困境。
可能的出路:在效率与信任间寻找平衡点
“彻底禁止”或“完全放开”的二元对立思维,或许本身就提出了一个错误的问题。
更现实的路径可能是建立分级的指导规则。例如:
- 明确要求使用 AI 辅助的 PR 必须进行标注。
- 限制单次提交的 AI 生成代码量,使其保持在可审阅的合理范围内。
- 要求提交者必须能够独立解释每一处关键改动的意图和实现逻辑。
这样既能保留 AI 提升开发效率的潜力,也能为审查者提供足够的上下文信息来做出判断。
归根结底,Node.js乃至所有开源社区的核心价值,从来不只是优质的代码本身,更是代码背后人与人之间的协作、学习与信任网络。AI 可以生成代码,但无法替代这层至关重要的社会关系。如何在拥抱效率工具的同时,守护社区长期赖以生存的信任基石,是每个开源社区都必须面对的课题。
Node.js 社区正在被迫回答这份考卷,而他们最终形成的共识,极有可能成为整个开源世界的重要参考范本。这场讨论的余波,无疑将在云栈社区及更多技术圈层中持续回荡。
 发表于 2026-3-26 18:49:50
|
查看: 147|
回复: 0
发表于 2026-3-26 18:49:50
|
查看: 147|
回复: 0
