在上篇文章《林林总总的定时器实现原理》中,我们回顾了定时器的发展历程。今天,让我们聚焦于企业级调度领域那个功能强大且可靠的“瑞士军刀”——Quartz。
Quartz是一个开源的任务调度框架,如今由Apache基金会管理。它以配置灵活、功能全面和高可靠性著称,是众多Java应用中实现复杂定时任务的首选方案。那么,Quartz究竟是如何设计的?它的集群机制如何保证高可用?本文将带你深入其核心源码,一探究竟。
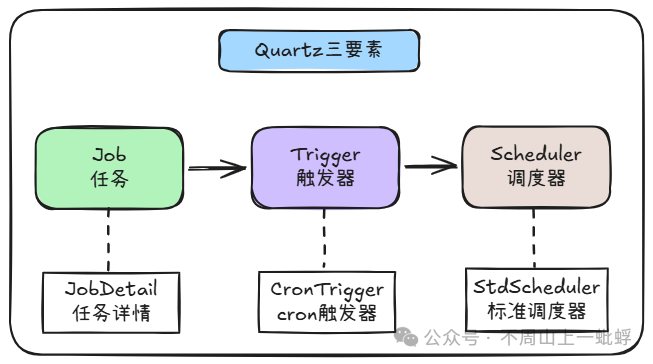
一、Quartz核心概念:三要素模型
在深入代码之前,理解其核心模型至关重要。Quartz的运作围绕三个核心要素展开:
- Job(任务):定义需要执行的具体业务逻辑,开发者通过实现
Job 接口中的 execute 方法来编写。
- Trigger(触发器):定义任务执行的调度规则,例如Cron表达式、固定时间间隔等。
- Scheduler(调度器):作为总指挥,负责协调Job和Trigger,在适当的时间触发任务执行。
Job 与 JobDetail 的分离
你可能注意到,在API中除了Job,还有一个 JobDetail。为什么要做这样的分离?
// Job 接口:定义无状态的执行逻辑
public interface Job {
void execute(JobExecutionContext context) throws JobExecutionException;
}
// JobDetail:承载Job的元数据信息(如名称、分组、附带参数)
public interface JobDetail extends Serializable {
String getKey();
String getName();
String getGroup();
JobDataMap getJobDataMap();
// ...
}
这种设计的关键在于:
- JobDetail 承载元数据:包含了Job的标识(名称、组)以及执行时所需的上下文数据(
JobDataMap)。
- Job 实例无状态:每次执行时,Quartz会创建一个新的Job实例,这使得Job实现本身是无状态的,便于管理和复用。
- 松耦合:同一个Job类可以被多个不同的JobDetail定义和触发。
二、Quartz整体架构概览
了解了核心概念后,我们来看看Quartz是如何将这些组件组织起来的。
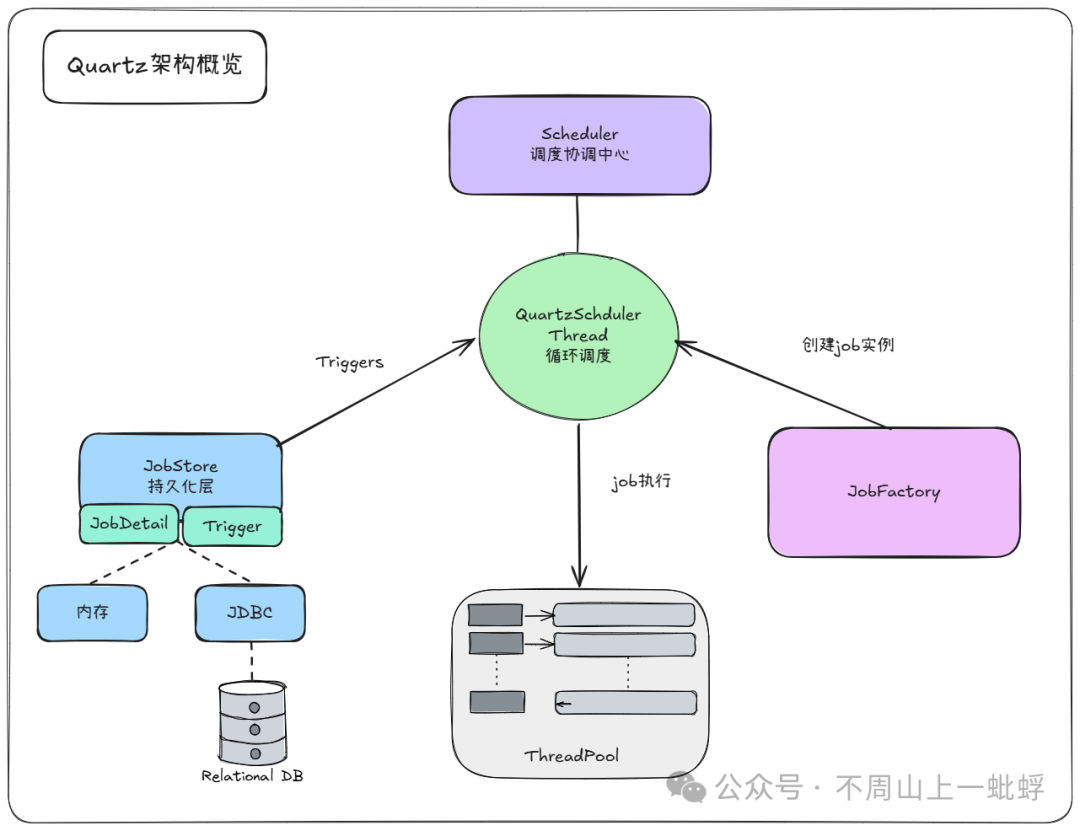
上图清晰地展示了Quartz的核心架构。中心是调度器线程(QuartzSchedulerThread),它驱动整个调度循环。围绕它的几个关键组件职责如下:
| 组件 |
职责 |
核心类 |
| Scheduler |
调度核心,对外提供API,内部协调触发 |
StdScheduler, QuartzScheduler |
| ThreadPool |
提供执行Job的工作线程 |
SimpleThreadPool, ThreadPool |
| JobStore |
存储Job和Trigger的定义及状态 |
RAMJobStore, JobStoreSupport |
| JobFactory |
负责实例化Job对象 |
默认使用反射,可自定义 |
三、核心源码流程分析
3.1 调度器(Scheduler)的初始化
一切始于 SchedulerFactory。我们以常用的 StdSchedulerFactory.getDefaultScheduler() 为例,追踪其初始化路径:
getDefaultScheduler()
└─> getScheduler()
└─> initialize() // 加载配置(quartz.properties)
└─> instantiate() // 实例化核心组件
├─> createThreadPool() // 创建线程池
├─> createJobStore() // 创建JobStore(内存或数据库)
├─> createScheduler() // 创建核心调度器实例
└─> initializePlugins() // 初始化插件
关键源码在 instantiate() 方法中:
// StdSchedulerFactory.java (简化)
protected Scheduler instantiate() throws SchedulerException {
// 1. 根据配置创建线程池
ThreadPool threadPool = createThreadPool(config);
// 2. 根据配置创建JobStore
JobStore jobStore = createJobStore(config);
// 3. 创建真正的调度核心 QuartzScheduler
QuartzScheduler sched = instantiate(rsrcs, qs);
// 4. 包装成对用户友好的 StdScheduler 返回
return new StdScheduler(sched);
}
3.2 调度引擎核心:QuartzSchedulerThread
QuartzScheduler 是大脑,而 QuartzSchedulerThread 是其永不停止的心脏。它在一个死循环中工作,核心流程如下:
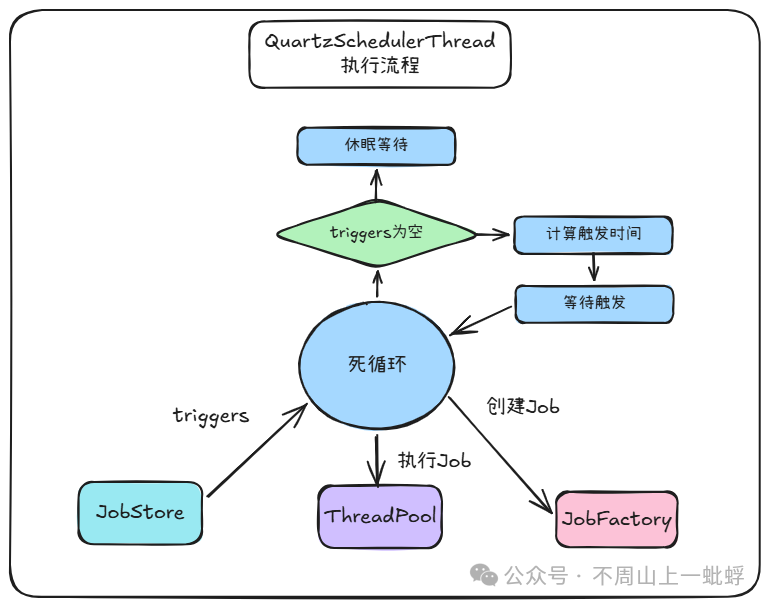
让我们看看这个循环的核心代码逻辑(高度简化):
public class QuartzSchedulerThread extends Thread {
private final QuartzScheduler qs;
public void run() {
while (!halted) {
// 1. 获取在指定时间点前需要触发的触发器
List<OperableTrigger> triggers = qs.jobStore.acquireNextTriggers(
System.currentTimeMillis() + idleWaitTime);
if (triggers.isEmpty()) {
// 没有任务,休眠等待
Thread.sleep(idleWaitTime);
continue;
}
// 2. 计算并等待最临近触发时间的到来
long triggerTime = triggers.get(0).getNextFireTime().getTime();
long delay = triggerTime - System.currentTimeMillis();
if (delay > 0) {
Thread.sleep(delay);
}
// 3. 触发任务:通知监听器、提交到线程池执行
for (OperableTrigger trigger : triggers) {
qs.notifyTriggerListenersFired(trigger);
// 实际执行被封装并提交到线程池
qs.threadPool.runInThread(/* 包装的执行任务 */);
}
}
}
}
四、存储层(JobStore)的设计与实现
JobStore是Quartz的持久化层,决定了任务信息存储在哪里以及如何被检索。
4.1 JobStore的类继承体系
Quartz提供了两种主要的存储方式:内存存储和基于数据库的持久化存储。
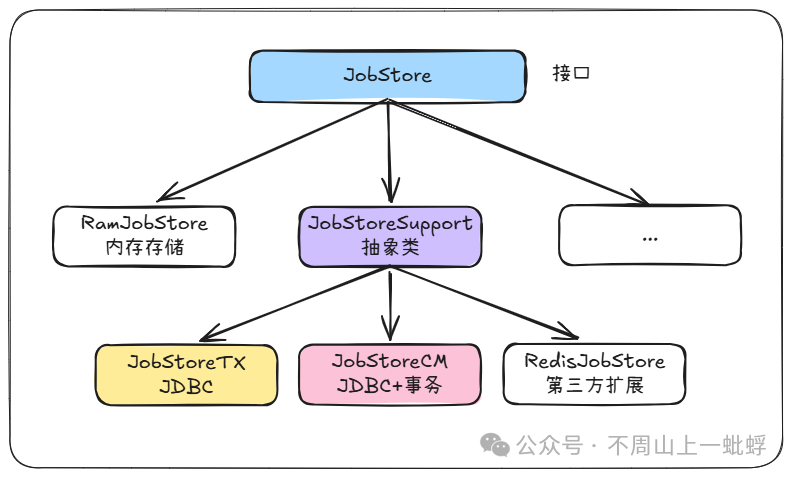
RAMJobStore:将所有Job和Trigger信息保存在内存中,性能极高,但应用重启后任务信息会丢失。JobStoreSupport:所有基于数据库存储实现(如JobStoreTX、JobStoreCMT)的抽象基类。它定义了通过JDBC操作数据库表的核心逻辑。
4.2 RAMJobStore 的内存管理
RAMJobStore 是如何高效管理内存中的触发器,以便快速获取下一个要触发的任务呢?
public class RAMJobStore implements JobStore {
// 使用TreeMap,使触发器按键(触发时间)自然排序
private final TreeMap<TriggerWrapper, TriggerWrapper> timeTriggers;
// 通过Key快速查找Job和Trigger
private final Map<JobKey, JobWrapper> jobsByKey;
private final Map<TriggerKey, TriggerWrapper> triggersByKey;
@Override
public List<OperableTrigger> acquireNextTriggers(long noLaterThan) {
synchronized (lock) { // 使用重量级锁保证线程安全
List<TriggerWrapper> wrappers = new ArrayList<>();
// 遍历有序的timeTriggers,找到所有触发时间 <= noLaterThan 的触发器
for (TriggerWrapper tw : timeTriggers) {
if (tw.trigger.getNextFireTime() != null
&& tw.trigger.getNextFireTime().getTime() <= noLaterThan) {
wrappers.add(tw);
} else {
break; // TreeMap已排序,后续的触发时间都更大
}
}
// 从待触发队列中移除这些已被“获取”的触发器
timeTriggers.removeAll(wrappers);
return wrappers.stream().map(tw -> tw.trigger).collect(Collectors.toList());
}
}
}
设计要点:
- 排序检索:使用
TreeMap 按触发时间排序,获取下一批任务的效率为 O(logN + k)。
- 双重索引:
jobsByKey 和 triggersByKey 用于按Key快速查找,timeTriggers 用于按时间调度。
- 并发控制:使用
synchronized 关键字保证线程安全,这在任务量大时可能成为性能瓶颈。
4.3 基于数据库的持久化(JobStoreSupport)
对于需要持久化和集群支持的场景,需要使用数据库存储。Quartz提供了一套完整的数据库表结构。
核心表结构示例:
-- 任务详情表
CREATE TABLE QRTZ_JOB_DETAILS (
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL, -- 存储Job实现类的全限定名
JOB_DATA BLOB, -- 存储序列化的JobDataMap
PRIMARY KEY (SCHED_NAME, JOB_NAME, JOB_GROUP)
);
-- 触发器表
CREATE TABLE QRTZ_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
NEXT_FIRE_TIME BIGINT(13), -- 下次触发时间戳
PREV_FIRE_TIME BIGINT(13), -- 上次触发时间戳
TRIGGER_STATE VARCHAR(16) NOT NULL, -- 状态:WAITING, ACQUIRED, EXECUTING等
PRIMARY KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP)
);
-- Cron触发器扩展表
CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL, -- Cron表达式
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP)
);
JobStoreSupport 的核心操作就是围绕这些表进行的。例如,获取下一个触发器的流程就涉及查询和状态更新:
public abstract class JobStoreSupport implements JobStore {
public List<OperableTrigger> acquireNextTriggers(long noLaterThan) {
Connection conn = getConnection();
try {
// 1. 查询状态为WAITING且下次触发时间<=noLaterThan的触发器
List<TriggerWrapper> triggers = selectNextTriggersToAcquire(conn, noLaterThan);
// 2. 通过UPDATE语句将这些触发器的状态改为ACQUIRED(行锁竞争发生在此处)
updateTriggerStateFromWaitingToAcquired(conn, triggers);
return triggers;
} finally {
releaseConnection(conn);
}
}
}
五、集群高可用设计与实现
Quartz的集群功能旨在解决单点故障问题,其实现原理相对朴素而有效:基于数据库的悲观锁。
5.1 集群架构
多个Quartz调度器实例(节点)共享同一个数据库。它们通过竞争数据库表中的“锁”来确保同一个任务在同一时刻只会被一个节点触发。
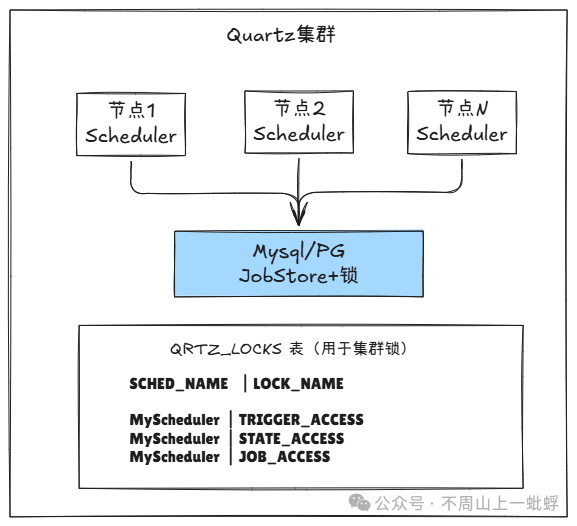
5.2 核心机制:心跳与锁
集群协调主要依赖两张表:
QRTZ_SCHEDULER_STATE:记录每个调度器实例的心跳。
CREATE TABLE QRTZ_SCHEDULER_STATE (
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL, -- 实例标识
LAST_CHECKIN_TIME BIGINT(13) NOT NULL, -- 最后检入时间戳
CHECKIN_INTERVAL BIGINT(13) NOT NULL, -- 检入间隔
PRIMARY KEY (SCHED_NAME, INSTANCE_NAME)
);
QRTZ_LOCKS:用于实现悲观锁的锁表。
CREATE TABLE QRTZ_LOCKS (
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL, -- 锁名,如TRIGGER_ACCESS, STATE_ACCESS
PRIMARY KEY (SCHED_NAME, LOCK_NAME)
);
ClusterManager 是一个后台线程,定期执行以下操作:
public class ClusterManager implements Runnable {
public void run() {
while (!shutdown) {
// 1. 检查集群中是否有实例失效(长时间未更新心跳)
List<SchedulerStateRecord> failedSchedulers = findFailedInstances(conn);
// 2. 恢复失效实例未完成的任务(将其状态从ACQUIRED改回WAITING)
recoverJobs(conn, failedSchedulers);
// 3. 更新本实例的心跳时间
updateSchedulerState(conn);
Thread.sleep(checkinInterval);
}
}
}
锁的获取:
当调度器线程需要获取触发器进行触发时,会尝试获取名为 TRIGGER_ACCESS 的锁。
SELECT * FROM QRTZ_LOCKS
WHERE SCHED_NAME = 'MyScheduler' AND LOCK_NAME = 'TRIGGER_ACCESS'
FOR UPDATE; -- 关键:使用SELECT ... FOR UPDATE获取行级排他锁
这条 SELECT ... FOR UPDATE 语句是集群协调的核心。第一个执行此查询并成功提交事务的节点获得了锁,其他节点则会被数据库阻塞,直到锁被释放。这就实现了跨JVM的互斥访问。
六、任务执行与监听器机制
任务被触发后,会经历一个标准的执行生命周期。Quartz提供了监听器(Listener)接口,允许我们在生命周期的各个阶段插入自定义逻辑。
6.1 监听器接口层次
Quartz提供了三种类型的监听器,覆盖了调度的不同维度。
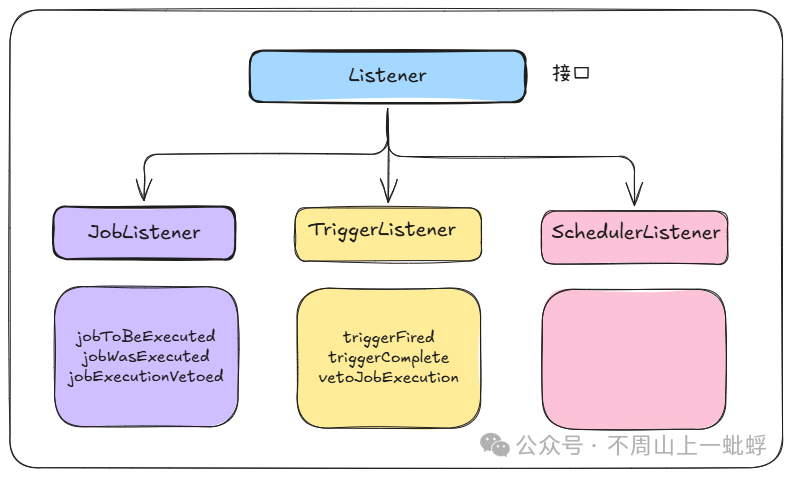
一个简单的 JobListener 示例:
public class MyJobListener implements JobListener {
@Override
public String getName() { return "MyJobListener"; }
@Override
public void jobToBeExecuted(JobExecutionContext context) {
System.out.println("Job即将执行: " + context.getJobDetail().getKey());
}
@Override
public void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException) {
System.out.println("Job执行完成: " + context.getJobDetail().getKey());
if (jobException != null) {
System.out.println("执行异常: " + jobException.getMessage());
}
}
}
// 注册监听器
scheduler.getListenerManager().addJobListener(new MyJobListener());
七、性能优化与配置建议
在实际使用中,合理的配置对Quartz的性能和稳定性至关重要。
常见性能瓶颈与对策:
| 现象 |
可能原因 |
优化建议 |
| 任务触发延迟 |
线程池大小不足,任务排队 |
增加 org.quartz.threadPool.threadCount |
| 数据库连接高负载 |
集群节点多,锁竞争激烈 |
优化 acquireTriggersWithinLock 等参数,或减少非必要节点 |
| 调度器启动/停止慢 |
JobStore中积累了大量历史数据 |
定期清理过期的QRTZ_TRIGGERS等表数据 |
关键配置示例 (quartz.properties):
# 线程池配置
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 15 # 根据业务并发量调整
org.quartz.threadPool.threadPriority = 5
# 使用JDBC存储并启用集群
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.isClustered = true
org.quartz.jobStore.clusterCheckinInterval = 20000 # 集群检入间隔20秒
# 减少不必要的锁竞争(针对数据库存储)
org.quartz.jobStore.acquireTriggersWithinLock = true
八、总结
通过以上对Quartz源码的深度剖析,我们可以清晰地看到其设计精妙之处:
- 清晰的职责分层:API层、核心调度层、存储层分离,便于理解和扩展。
- 灵活的扩展点:从
JobStore、ThreadPool 到各种 Listener,几乎每个核心组件都支持自定义实现。
- 务实的集群方案:基于数据库行锁的实现,虽然在高并发竞争下可能成为瓶颈,但其原理简单、可靠性高,对于大多数中小规模集群场景已足够。
- 丰富的调度能力:尤其是Cron表达式的强大支持,满足了复杂的业务调度需求。
适用场景:
- 需要复杂时间规则(Cron)调度的后台任务。
- 对任务执行可靠性有要求,需要故障恢复的应用程序。
- 中小规模的分布式调度场景。
局限性:
- 调度中心本身非分布式,性能受限于单个数据库的锁竞争。
- 相较于后来出现的XXL-JOB、Elastic-Job等分布式调度中心,在超大规模任务、分片广播、可视化治理等方面存在不足。
理解其源码和设计原理,不仅能帮助我们在使用中更好地排查问题、进行调优,也能为我们自研或选型其他调度系统提供宝贵的设计参考。希望这篇深度解析能为你带来启发。欢迎在云栈社区继续交流更多技术实战细节。
 发表于 2026-3-26 19:21:52
|
查看: 123|
回复: 0
发表于 2026-3-26 19:21:52
|
查看: 123|
回复: 0
