在构建大规模系统时,数据分片是绕不开的话题。不管是分布式缓存还是分布式数据库,只要数据量超过单机容量,就必须将数据拆分到多台机器上存储。这个拆分过程的核心,就是一套高效的路由算法:给定一个键(Key),我们能快速、准确地算出它应该存储在哪个节点。
哈希表是完成这项任务的理想工具,因为它能将数据相对均匀地分散开来。然而,不同的哈希策略在系统节点数量动态变化时的表现,可谓天差地别。今天,我们就来深入剖析一下一致性哈希算法,看看它是如何优雅地解决节点扩缩容带来的大规模数据迁移问题。
从问题开始:普通哈希取模的痛点
最简单直接的数据分片方案就是哈希取模。假设我们有3台缓存服务器,编号0、1、2。路由规则很简单:hash(key) % 3,结果是几,数据就存到几号服务器。
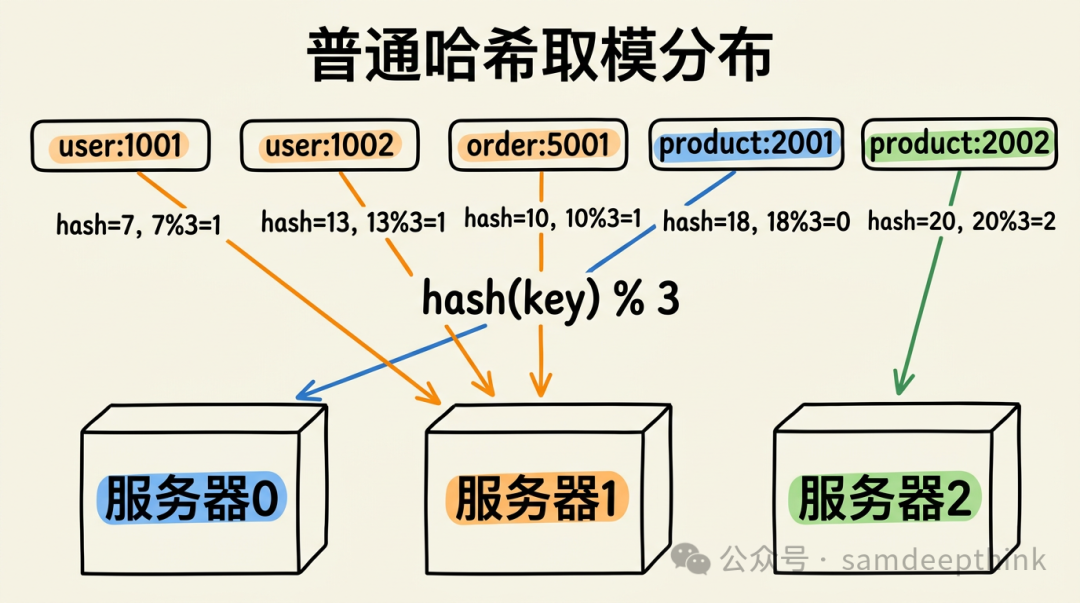
我们来模拟几个数据:
hash("user:1001") 结果为7,7 % 3 = 1,存入1号服务器hash("user:1002") 结果为13,13 % 3 = 1,也存入1号服务器hash("order:5001") 结果为10,10 % 3 = 1,存入1号服务器hash("product:2001") 结果为18,18 % 3 = 0,存入0号服务器hash("product:2002") 结果为20,20 % 3 = 2,存入2号服务器
哈希函数本身的均匀性保证了在节点数量固定时,数据能比较均匀地分散到各台服务器上。读写请求都能准确定位,一切正常。
那么,问题出在哪?
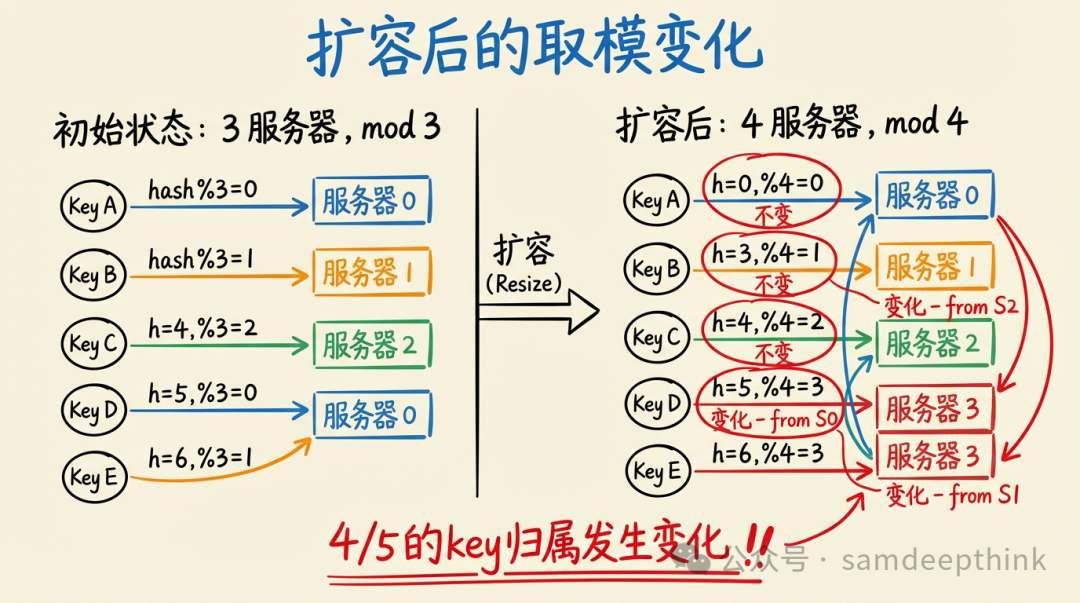
问题出在服务器数量发生变化的时候。假设业务增长,我们需要扩容,增加一台服务器,集群从3台变为4台。此时,取模的除数从3变成了4,绝大部分Key的计算结果都会改变。
还是上面那几个Key:
hash("user:1001") = 7,7 % 4 = 3,从1号服务器迁移到3号hash("user:1002") = 13,13 % 4 = 1,仍留在1号服务器(未变)hash("order:5001") = 10,10 % 4 = 2,从1号迁移到2号hash("product:2001") = 18,18 % 4 = 2,从0号迁移到2号hash("product:2002") = 20,20 % 4 = 0,从2号迁移到0号
看到了吗?5个Key中,有4个的归属服务器都发生了改变,迁移比例高达80%。
在分布式缓存场景下,这种大规模的数据重新分布意味着灾难。大量缓存瞬间失效,请求无法命中缓存,会像洪水一样直接穿透到后端数据库。如果数据库的承载能力不足,极有可能被直接打垮,这就是典型的缓存雪崩。我们需要一种更“智能”的哈希策略来应对节点数量的动态变化,于是,一致性哈希算法应运而生。
一致性哈希的核心思想:哈希环
一致性哈希的核心思路非常巧妙:它将整个哈希值空间想象成一个首尾相连的环形,通常取值范围是 0 ~ 2^32-1(一个32位的无符号整数空间)。
服务器节点和数据Key都通过同一个哈希函数映射到这个环上。确定数据归属的规则是:从数据Key在环上的位置出发,沿顺时针方向行走,遇到的第一个服务器节点,就是它的归宿。
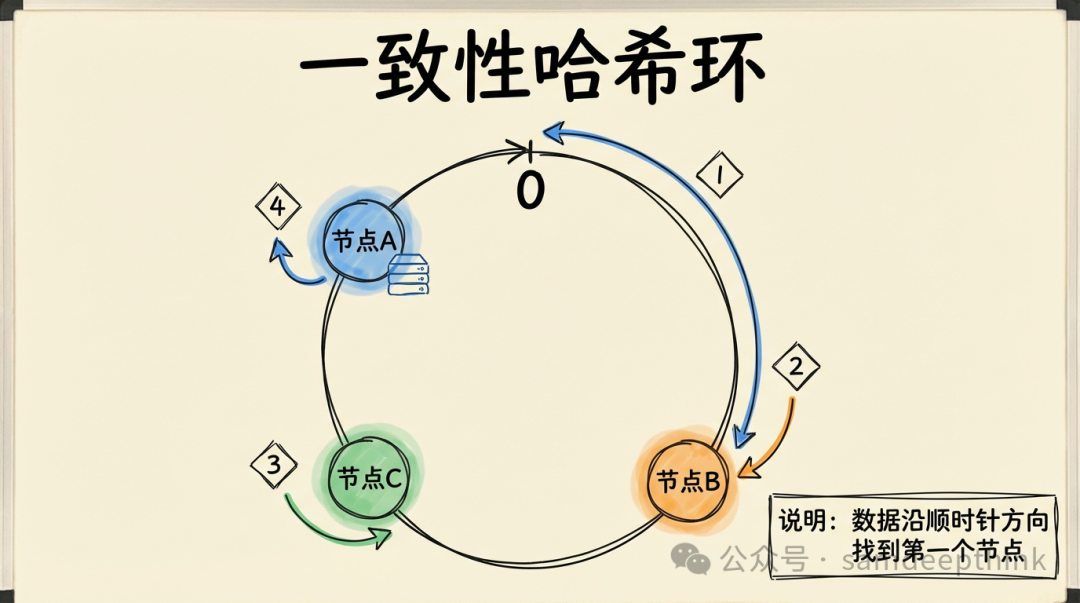
假设3台服务器A、B、C经过哈希运算后,落在环上的不同位置。一个数据Key经过哈希计算落在A和B之间,那么它顺时针找到的第一个节点就是B,因此这个Key就存储在服务器B上。
这套规则在节点固定时,同样能达到均匀分布数据的效果。其真正的威力,体现在节点数量变化时。
节点变化时的一致性表现
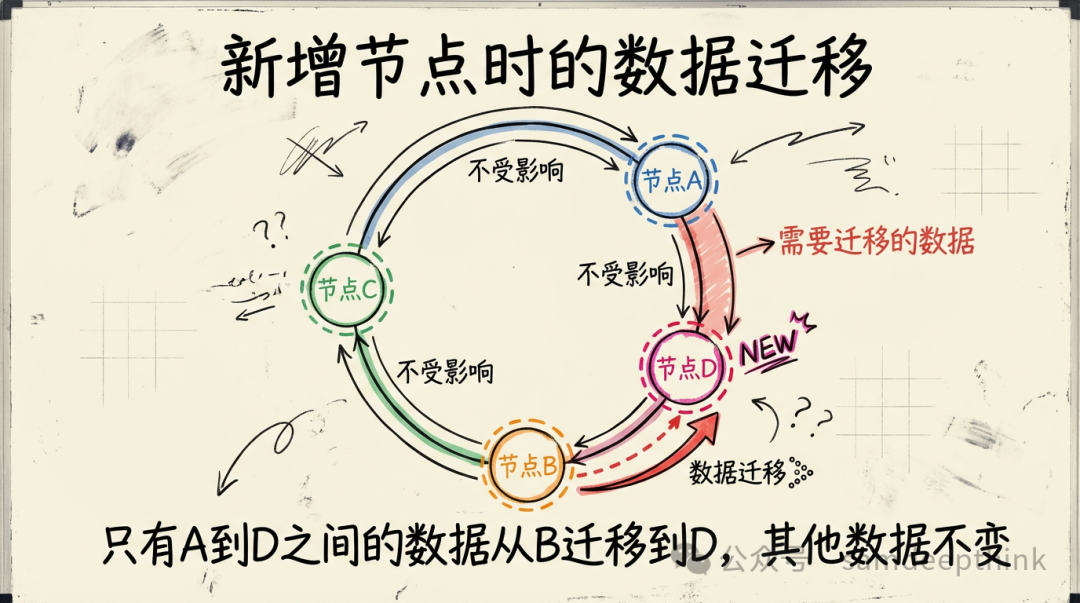
1. 新增一个节点
在环上A和B之间插入一个新节点D。D加入后,只有原本落在A和D之间这一小段弧上的数据需要重新路由,它们将从原来的归属节点B迁移到新节点D。环上其他位置的数据完全不受影响。
2. 移除一个节点
假设节点B宕机了。B负责的那段数据(从前一个节点A到B之间的部分)会顺延到B的下一个顺时针邻居C。同样,只有原本由B负责的数据需要迁移到C,A和C各自的数据范围不受影响。
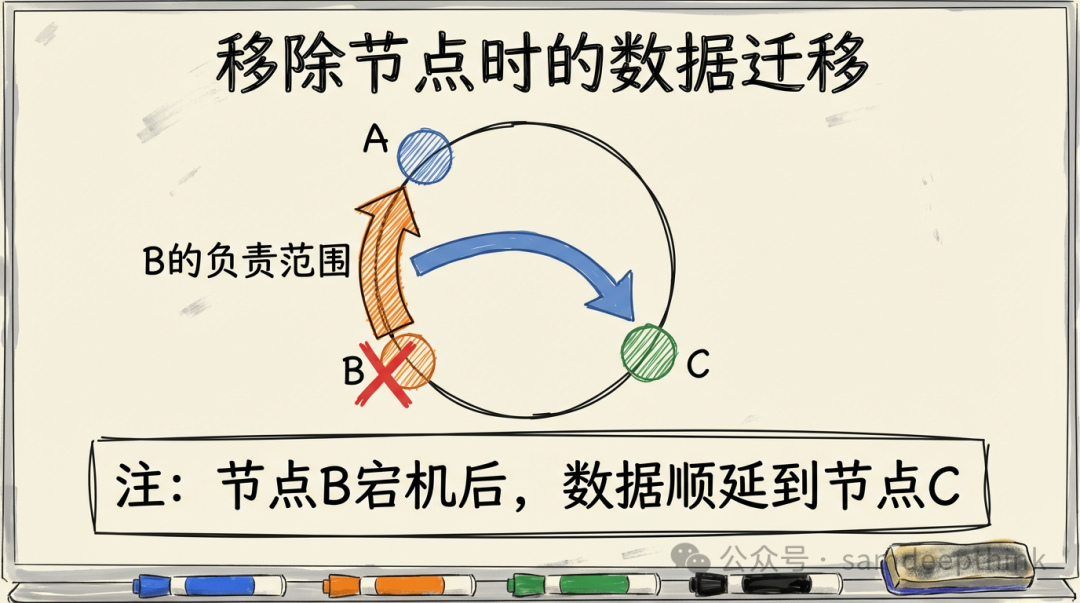
这就是一致性哈希的核心价值:当节点增加或减少时,仅需迁移相邻一小段的数据,而非全部或绝大多数数据。
从数学期望来看,在一个拥有N个节点的集群中增加或减少一个节点,平均只有大约 1/N 的数据需要重新映射。例如,3台变4台,只有约25%的数据需要迁移;对于一个100台节点的集群,加一台机器只影响约1%的数据。这极大地降低了系统扩缩容和节点故障带来的数据迁移开销与缓存失效风险。
数据倾斜问题与虚拟节点方案
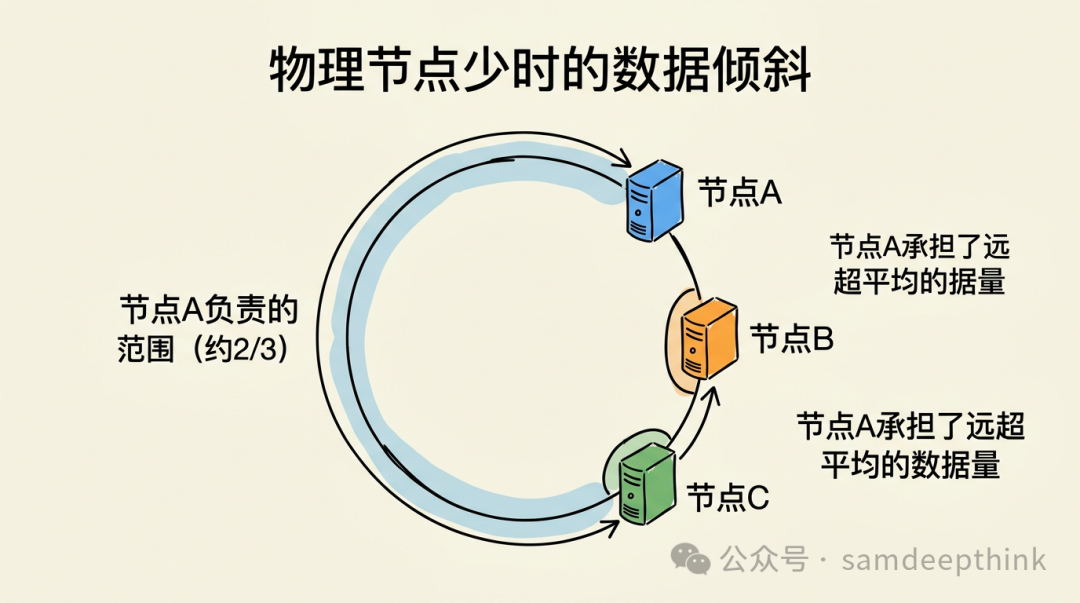
一致性哈希并非完美,一个明显的问题是:当物理节点数量较少时,节点在环上的分布很可能不均匀。极端情况下,如果几个节点扎堆落在环的某一小段,那么另一大半环的所有数据都会被路由到同一个节点上,导致该节点负载过重,即数据倾斜。
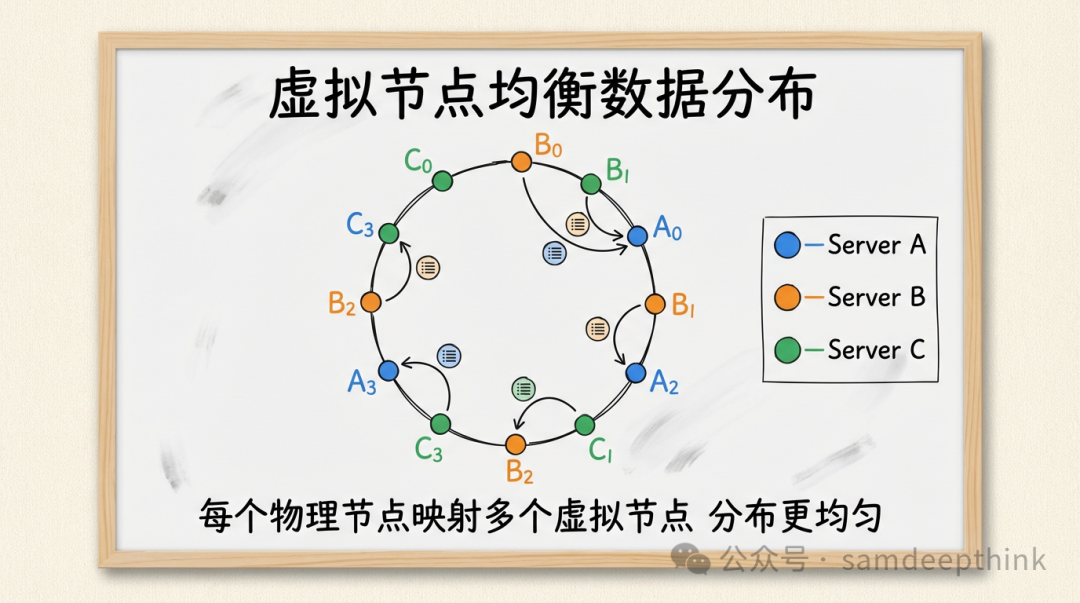
解决方案是引入 虚拟节点。不再让一个物理节点只对应环上的一个点,而是让它映射为多个虚拟节点。例如,物理节点A可以在环上创建150个虚拟节点:A-0, A-1, ..., A-149。每个虚拟节点通过 hash("A-0")、hash("A-1") 等方式计算其位置。
这些虚拟节点会相对均匀地分散在整个哈希环上。数据先映射到虚拟节点,再通过虚拟节点与实际物理节点的映射关系找到最终归宿。这样,即使物理节点很少,通过足够多的虚拟节点,也能让数据分布变得均匀。
虚拟节点还有另一个好处:可以实现加权负载均衡。为性能更强的物理节点分配更多的虚拟节点,它自然就能承载更多的数据和请求。在业界实践中,如Amazon Dynamo等系统,虚拟节点的数量会根据节点性能和负载情况进行动态调优。
另一种思路:Guava的Jump Consistent Hash
Google在2014年提出了一种名为Jump Consistent Hash的新算法,并实现在Guava库的 Hashing.consistentHash() 方法中。它的思路与传统的哈希环完全不同,是一个纯函数式的数学计算方案。
核心代码如下,非常简洁:
public static int consistentHash(long input, int buckets) {
checkArgument(buckets > 0, "buckets must be positive: %s", buckets);
LinearCongruentialGenerator generator = new LinearCongruentialGenerator(input);
int candidate = 0;
int next;
// 从第0个桶开始,不断往后跳跃
while (true) {
next = (int) ((candidate + 1) / generator.nextDouble());
if (next >= 0 && next < buckets) {
candidate = next;
} else {
return candidate;
}
}
}
它依赖一个内部的线性同余随机数生成器来保证确定性:
private static final class LinearCongruentialGenerator {
private long state;
LinearCongruentialGenerator(long seed) {
this.state = seed;
}
double nextDouble() {
state = 2862933555777941757L * state + 1;
return ((double) ((int) (state >>> 33) + 1)) / 0x1.0p31;
}
}
算法原理简述:将输入(Key的哈希值)作为随机数种子,生成一个确定的随机数序列。算法从0号桶开始,通过一个公式计算下一次跳跃的目标桶编号。跳跃过程会持续到目标桶超出有效范围,最后一个有效的桶编号即为结果。
其性能非常出色:时间复杂度 O(ln n),空间复杂度 O(1)。不需要维护任何数据结构,对于100个桶,平均只需约5次循环迭代。
然而,它有一个关键限制:桶编号必须是0到N-1的连续整数,并且只能从末尾进行增删(即桶的数量变化必须是连续的),不支持在集群中间随意移除任意一个节点。因此,它更适用于桶数量只增不减的场景,例如分布式缓存的单纯扩容。
实际应用场景一览
一致性哈希在工业界有着广泛的应用,以下是几个典型例子:
- Memcached客户端分片:Memcached本身不提供集群功能,分片逻辑由客户端库(如spymemcached)实现。这些库大多支持一致性哈希,以在节点变动时最小化缓存失效范围。
- Redis Cluster的哈希槽:Redis Cluster没有直接采用一致性哈希,而是采用了16384个固定哈希槽的方案。每个Key映射到一个槽,槽再分配给具体节点。这本质上解决了和一致性哈希相同的问题,但提供了更细粒度和可控的数据迁移单元。
- Nginx的负载均衡:Nginx的upstream模块支持一致性哈希负载均衡策略。配置
hash $request_uri consistent; 可以让同一个URL的请求始终路由到同一台后端服务器,有效利用服务器本地缓存,并在后端服务器增减时仅影响少量请求。
- Amazon Dynamo:作为分布式键值存储的经典论文,Dynamo系统详细阐述了一致性哈希与虚拟节点在生产环境中的应用,对后来的Cassandra等系统产生了深远影响。
方案速查对比表
| 维度 |
普通哈希取模 |
哈希环(一致性哈希) |
Jump Consistent Hash |
哈希槽 |
| 节点变化时数据迁移量 |
约 N/(N+1) |
约 1/N |
约 1/N |
按槽粒度迁移,可控 |
| 数据均衡性 |
好 |
物理节点少时差,需虚拟节点 |
好 |
好,可手动调整 |
| 支持任意节点增删 |
是(但代价大) |
是 |
否,只能从末尾增删 |
是 |
| 空间复杂度 |
O(1) |
O(N * V),V为虚拟节点数 |
O(1) |
O(槽数量) |
| 时间复杂度 |
O(1) |
O(log(N * V)) |
O(ln N) |
O(1) |
| 典型应用 |
简单场景 |
Memcached、Dynamo |
Guava库 |
Redis Cluster |
总结与思考
一致性哈希算法解决的,本质上是在节点数量动态变化的分布式环境中,如何将数据路由的扰动范围降至最低这一核心挑战。这不仅是缓存分片的问题,也是所有分布式数据存储系统设计时必须面对的课题。
在实际项目中,我们无需纠结于自己实现哪种一致性哈希。很多时候,成熟的中间件已经为我们做好了选择:使用Redis Cluster,就接受其哈希槽方案;使用Memcached,客户端库已内置一致性哈希;若需在自有系统中实现简单分片,Guava的 Hashing.consistentHash() 提供了极其轻量的选择。
最后,必须清醒地认识到:一致性哈希并非分布式系统的银弹。它仅仅优雅地解决了“路由”这一个环节的问题。数据迁移的具体执行、副本的同步与一致性、节点的故障检测与恢复,这些都需要一整套完善的配套设施。理解一致性哈希的原理,能帮助我们在架构设计时做出更明智的决策,但构建一个健壮的分布式系统,远不止一个算法那么简单。
希望本文能帮助你透彻理解一致性哈希。如果你在实践中有更多心得或疑问,欢迎到云栈社区与更多开发者一起交流探讨。
 发表于 2026-3-26 20:35:29
|
查看: 115|
回复: 0
发表于 2026-3-26 20:35:29
|
查看: 115|
回复: 0
