在将大模型推向超大规模 Coding Agent 场景的过程中,推理基础设施面临的考验远比预期中残酷。自智谱 GLM Coding Plan 上线以来,Coding Agent 的日均调用量已达数亿次。这种高并发、长上下文的复杂任务,像一个巨大的压力测试场,将一些在普通聊天场景下完全不会暴露的底层问题,一一逼了出来。这也标志着大模型竞争的焦点,正从“谁的模型更强”转向“谁的基础设施更能扛”。
以下是智谱团队首次系统披露的 GLM-5 系列模型在超大规模 Coding Agent 调用场景下的底层推理技术突破,包括关键 Bug 的定位与修复、性能优化创新,以及一个意料之外的监控机制发现。目前,相关实践经验已通过 Pull Request 贡献给 SGLang 开源社区,以期帮助更多模型在 Agent 场景下实现更优的推理吞吐与系统稳定性。
完整技术博客链接: https://z.ai/blog/scaling-pain
1. Scaling Pain:超大规模 Coding Agent 推理实践
对 Scaling Law 的信仰不仅驱动着模型在参数与数据规模上突破,也同样不断逼近 Infra 工程的极限。这个过程伴随着不可避免的阵痛,我们称之为 “Scaling Pain”。
当大模型应用从简单对话,全面转向更复杂、更长程的 Coding Agent 任务时,推理基础设施迎来了前所未有的压力。部分用户在使用 GLM-5 系列执行复杂编程任务时,曾遭遇乱码、复读以及偶现生僻字等异常。这些问题在标准推理环境下并不存在,它们只在高并发、长上下文的 Coding Agent 场景下才被触发,且极难稳定复现。
经过数周的推演、排查与压测,我们最终定位并修复了几个相互独立的底层竞态 Bug,并对系统瓶颈进行了针对性优化,显著提升了推理系统的稳定性与效率。我们希望将这段探索中收获的经验与教训,与社区分享,共同克服 Coding Agent 推理中的 Scaling Pain。
2. 从线下复现到异常识别
自 3 月起,我们在 GLM-5 的线上监控和用户反馈中观察到三类主要异常:乱码(garbled output)、复读(repetition) 以及 生僻字(rare character)。这些现象表面上类似长上下文场景下常见的“降智”,但由于我们并未上线任何降低模型精度的优化,一个关键问题浮现:异常根源究竟是模型本身,还是推理链路? 如果源于模型,异常应表现为对特定输入的稳定、可重复行为;反之,若与系统压力或运行时状态相关,则更可能指向推理基础设施的状态管理问题。
排查初期,我们将用户反馈的 bad cases 在本地回放,并对同一批请求重复推理数百次,但始终未能复现。这初步排除了模型本身的问题。为进一步模拟线上环境,我们在对日志脱敏处理后,尽可能保留原始并发与请求时序,在本地进行全量回放。起初仍未出现异常,直到我们调整 PD 分离比例并持续提高系统负载,模拟高峰期的 Prefill 堆积与 Decode 侧 KV Cache 压力,才在约每万次请求中稳定复现 3-5 次。这种“与请求内容无关,与系统压力强相关”的特征,将矛头指向了高负载下的推理状态管理。
同时,线下复现率低于线上反馈率,说明现有检测手段可能漏检,或仍有部分触发场景未被覆盖。如何可靠地识别异常输出,成了新挑战。在三类异常中,复读相对容易检测,而乱码与生僻字颇为棘手。我们尝试过正则表达式、字符集匹配等启发式方法,也试过基于模型判别,但前者漏判误伤严重,后者无法满足大规模消融实验的效率要求。这使得异常检测本身,成了整个定位流程的瓶颈。
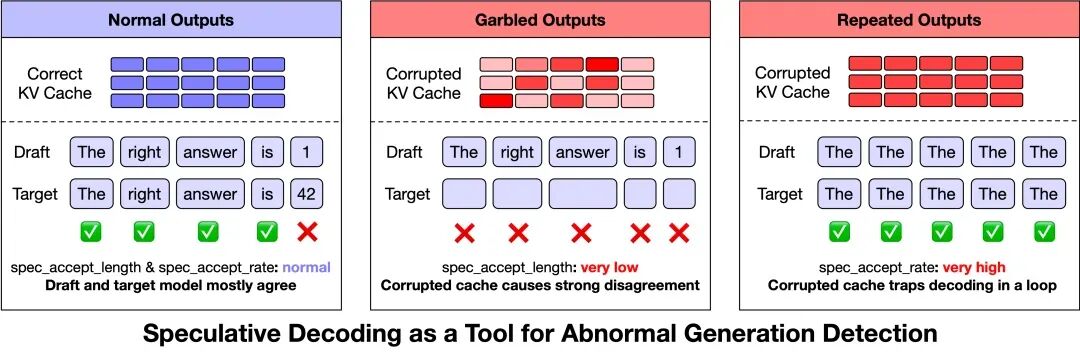
图 1:投机采样指标可以作为异常检测的重要参考
在反复分析日志后,我们找到了一个意想不到的切入点:投机采样(Speculative Decoding)指标可以作为异常检测的重要参考。 投机采样本是一项性能优化技术,让草稿模型先生成候选 token,再由目标模型校验,从而在不改变最终输出分布的前提下提升 decode 效率。如图 1 所示,我们观察到两个指标——spec_accept_length(目标模型连续接受的 draft token 前缀长度)和 spec_accept_rate(draft token 被接受的比例)——在异常发生时呈现出稳定的模式:
- 乱码和生僻字:通常伴随极低的
spec_accept_length,表明草稿模型生成的候选几乎全被目标模型拒绝,这意味着目标模型所看到的 KV Cache 状态与草稿模型预期之间存在显著偏差。
- 复读:通常伴随偏高的
spec_accept_rate,表明损坏的 KV Cache 可能使注意力模式退化,将生成过程推入高置信度的重复循环。
基于此,我们实现了一套在线异常监控策略:当 spec_accept_length 持续低于 1.4 且生成长度已超过 128 token,或 spec_accept_rate 超过 0.96 时,系统会主动中止当前生成,并将请求交由负载均衡器重试。该策略让投机采样从一个单纯的性能优化技术,拓展成了输出质量的实时监控信号,成为后续消融实验中的关键工具。
3. BugFix #1:PD 分离架构下的 KV Cache 竞态
在确定异常输出与并发压力直接相关后,我们深入分析了请求生命周期与 PD 分离架构的执行时序,发现根源在于 请求生命周期与 KV Cache 回收复用流程之间的不一致,由此引发 KV Cache 复用冲突。
1. 原因分析:异步 Abort 引发的 KV Cache 复用竞态
为控制尾延迟,我们在推理引擎中引入了基于超时的请求终止机制:当 Prefill 阶段超时,Decode 侧会对请求执行 Abort 并回收其占用的 KV Cache。然而,这个 Abort 信号并未正确传播至 Prefill 侧,且 Decode 侧缺乏判断 KV Cache 是否可以安全复用所需的充分信息。因此,当 Decode 侧将回收的 KV Cache 空间分配给新请求后,先前已发起的 RDMA 写入与正在执行的 Prefill 计算仍在继续,并未被同步取消。
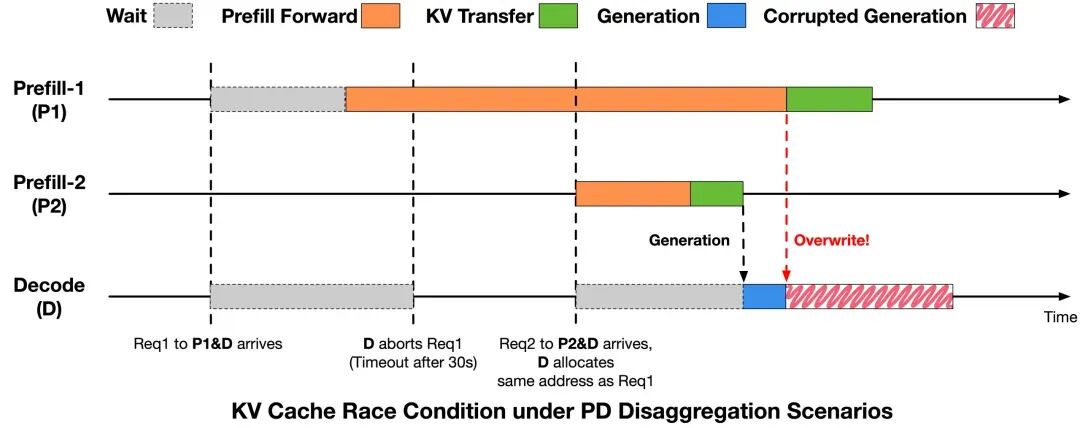
图 2:PD 分离场景下 KV Cache 竞态示意图
图 2 清晰展示了 PD 分离架构下,两个请求在 Prefill 与 Decode 之间引发的竞态过程:
- Req1 被发往 Prefill-1 (P1) 和 Decode (D)。P1 因调度或排队等待,Decode 侧(D)因超时未收到 KV Cache 数据,对 Req1 执行 Abort。
- D 回收 Req1 的 KV Cache 槽位,但未通知 P1。随后,新请求 Req2 到达,被分配到与 Req1 相同的 KV Cache 地址。
- Prefill-2 (P2) 为 Req2 快速完成计算和 KV 传输,D 侧随即进入生成阶段。
- 与此同时,P1 针对 Req1 的 KV Cache 写入仍在继续,其数据直接覆盖了已被 Req2 复用的显存区域。最终,Req2 在 Decode 阶段读到了被污染的数据,导致生成异常。
2. 修复方案:KV Cache 释放的时序一致性保证
为了消除上述竞态,我们引入了更严格的时序约束,在请求终止与 KV Cache 写入完成之间建立显式同步:
- Decode 在触发 Abort 后,向 Prefill 侧发送通知。
- Prefill 仅在确认“相关 RDMA 写入尚未开始”或“所有已提交写入均已完成”后,才返回“可释放”信号。
- Decode 只有在收到该确认信号后,才允许回收并复用对应的 KV Cache 槽位。
此机制确保 KV 写入不会跨越显存复用边界,彻底避免了跨请求的 KV Cache 覆盖。
修复效果: 该修复上线后,异常输出发生率从约万分之十几骤降至万分之三以下。这充分表明,在 PD 分离架构中,必须对跨节点的数据传输与显存复用建立明确的一致性约束。
4. BugFix #2: HiCache 加载时序缺失
Coding Agent 场景显著推高了平均输入长度(超 70K tokens),同时伴随着较高的前缀复用率。这使得 HiCache(多级 KV Cache)成为线上服务的关键优化。然而,在 KV Cache 换入与计算重叠执行的过程中,现有实现未能保证数据在使用前已完成加载,可能引发“读取未就绪数据”的风险。
1. 原因分析:流水线同步缺失导致的 read-before-ready
通过对 HiCache 执行时序的分析,我们将问题锁定在 DSA HiCache 的缓存读取路径上。系统会从 CPU 内存异步换入历史前缀缓存,并通过 Load Stream 与 Forward Stream 的重叠执行来提升吞吐。
如图 3(a) 所示,Load Stream 负责加载 KV Cache 与 Indexer Cache,Forward Stream 则依次执行 Indexer 计算与后续的 Sparse Attention。理论上,Indexer 计算必须在对应的 Indexer Cache 加载完成后才能启动。但在原始实现中,这一依赖关系未被显式表达。
具体来说,Indexer 算子在启动时没有对 Load Indexer Cache 的完成设置同步点。因此,Forward Stream 可能在数据加载完成前就开始执行,出现 Read-before-Ready 的访问模式——即在数据尚未就绪时就被读取。这将导致 Index 计算基于不完整或未初始化的数据,进而影响后续 Sparse Attention 的结果,最终反映为输出异常。
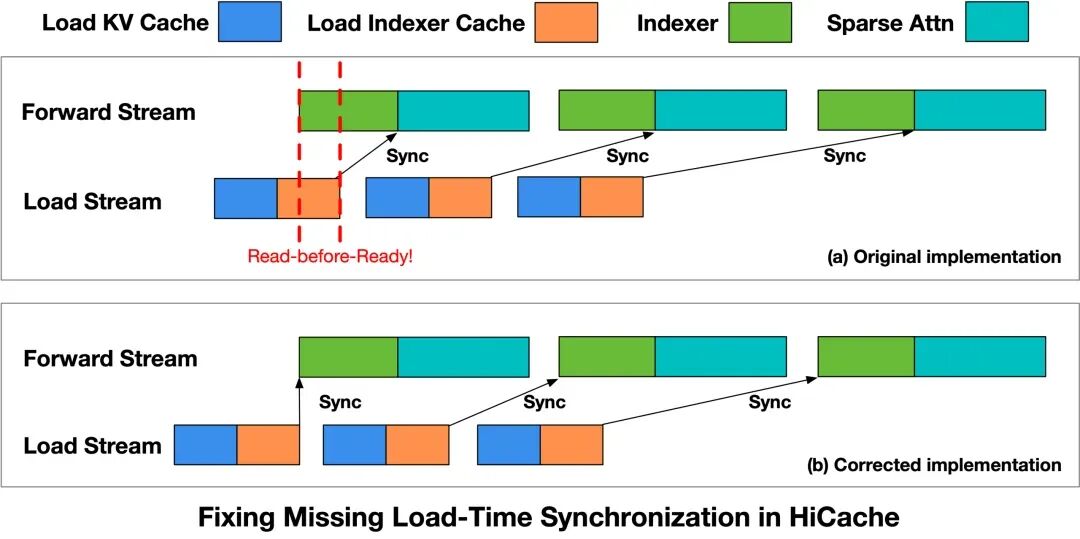
图 3:HiCache 读取流水线时序异常与修复示意图
2. 修复方案:重构算子流水线的原子性
为解决此问题,我们对 HiCache 的读取流水线进行了修改(如图 3(b) 所示),引入显式同步约束:
- 显式同步约束:在 Indexer 算子启动前,引入与 Load Stream 的同步点,确保对应层级的 Indexer Cache 已完成加载。Forward Stream 仅在数据就绪后才启动计算,从根本上杜绝了 read-before-ready 的访问。
该修复上线后,在相同负载下,由执行时序异常引起的问题完全消失,系统行为趋于稳定。此修复已通过 Pull Request #22811 提交至 SGLang 社区。
5. 优化:KV Cache 分层存储 LayerSplit
上述两个竞态问题,共同揭示了一个系统瓶颈:在长上下文的 Coding Agent 服务场景中,Prefill 阶段主导了系统性能。为了控制 TTFT(首 Token 延迟),我们引入了超时 Abort;为了缓解 Prefill 侧的 KV Cache 容量压力,我们引入了 HiCache。在修复了这些状态一致性问题后,我们选择直面瓶颈本身:如何从根本上提升 Prefill 吞吐、降低其显存压力?为此,我们设计并实现了 LayerSplit 方案。
Coding Agent 负载具有上下文长、前缀缓存命中率高的特点。在此场景下,Context Parallel (CP) 成为了 Prefill 节点的主要并行策略。然而,SGLang 的现有实现存在 KV Cache 冗余存储的问题,每个 rank 都存有完整的全层缓存,导致有限的 KV Cache 容量反过来制约了 GPU 计算资源的利用率。
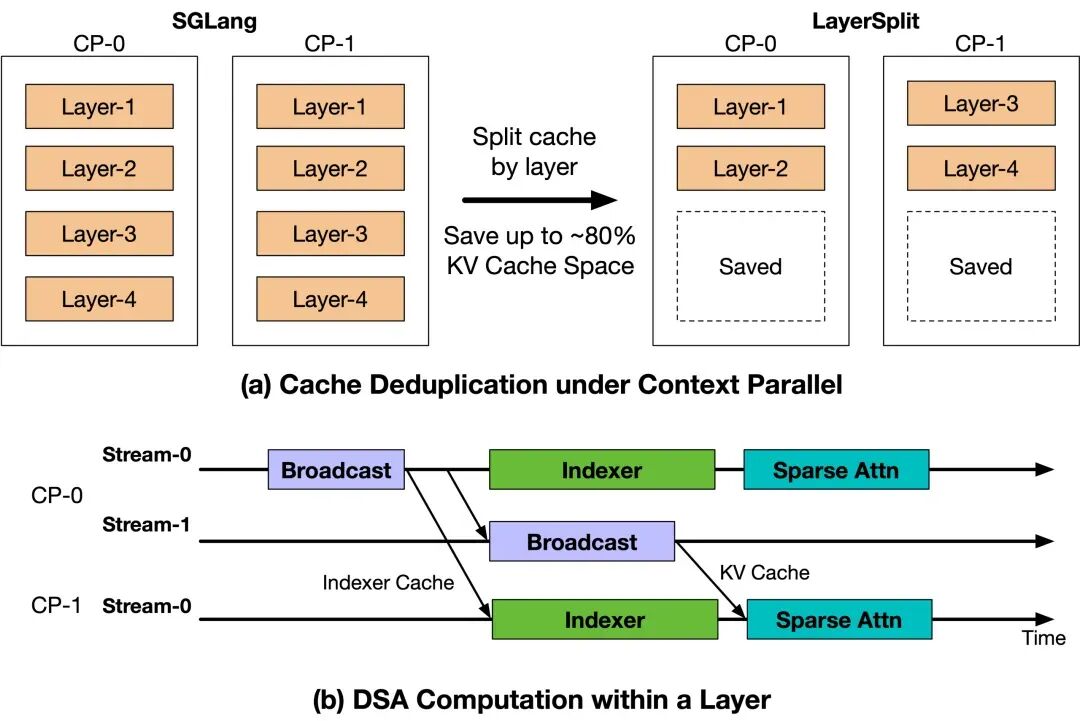
图 4:LayerSplit、KV Cache 分层存储方案
我们设计的 LayerSplit 方案,让每张 GPU 不再保存全部层的 KV Cache,而是仅持有部分层的 Cache(如图 4(a) 所示)。持有某一层 KV Cache 的 rank,会在执行 Attention 计算前,将该层 Cache 广播给其他相关的 rank。为了降低通信开销,我们进一步设计了 KV Cache 广播与 Indexer 计算的重叠机制,使二者在时间上相互掩盖。最终,整个流程仅引入了规模约为 KV Cache 1/8 的 Indexer Cache 广播开销,整体通信成本极低,对性能的影响几乎可以忽略不计。
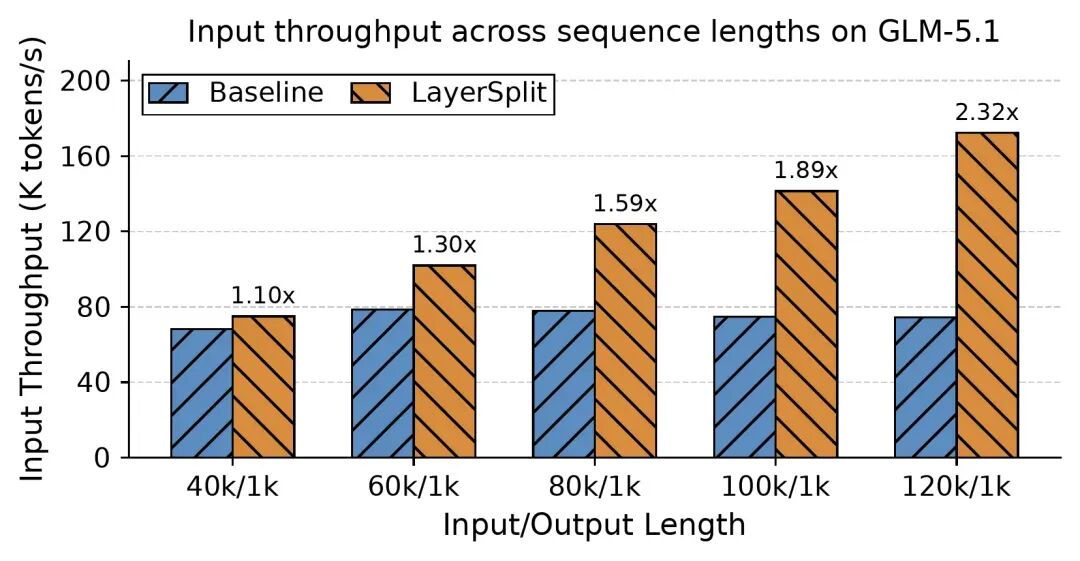
图 5:GLM-5.1 + LayerSplit 在不同长度下的吞吐提升
图 5 展示了在缓存命中率达 90% 的条件下,该优化在请求长度从 40k 到 120k 区间内带来的性能收益。实验数据显示,系统吞吐量提升幅度在 10% 至 132% 之间,且随着上下文长度的增加,收益愈发显著。整体来看,该优化极大地增强了系统在 Coding Agent 场景下的处理能力。
6. 总结
当 AI 应用从对话走进高并发、长上下文的 Coding Agent 场景后,推理基础设施面临的挑战已不止于吞吐、延迟和可用性,维护输出质量变得至关重要。我们分享这些在 Scaling Pain 中摸索出的经验,希望能帮助社区少走一些弯路,共同打磨出足以承载 AGI 未来的坚实推理基座。对 Scaling Law 的每一次极致追求,都离不开同等强度的系统工程作为支撑。
在云栈社区,我们持续关注大模型工程化落地的前沿实践,欢迎一同交流探讨。
 发表于 2026-5-1 17:58:23
|
查看: 116|
回复: 0
发表于 2026-5-1 17:58:23
|
查看: 116|
回复: 0
