在分布式KV存储系统中,有一个看似简单却至关重要的问题:当海量数据涌入集群时,系统如何决定每一条数据该存储在哪台服务器上? 答案藏在一个看似简单却极具智慧的技术里—— DHT(Distributed Hash Table,分布式哈希表) 。
数据打散这件事,为什么不能“随便分”?
最简单的想法是:给我N台服务器,我把每个Key的哈希值对N取模,结果是多少就存到哪台机器上。这就是经典的 “哈希取余法”——hash(key) % N 。
在节点数量固定的情况下,这种方法确实简单有效。然而分布式系统的常态恰恰是“变”—— 节点可能宕机 、 集群需要扩容 、 机器需要下电维护 。每当N发生变化,取模结果就会全局洗牌。
假设从10台扩容到11台,约90%的数据都需要重新迁移。 在缓存场景中,这意味着大量缓存同时失效,命中率降低,请求如洪水般涌向数据库,极可能引发 缓存雪崩 ,甚至导致整个服务瘫痪。
那么,有没有一种方法,让节点变化时只影响“局部的”数据?
一致性哈希环:把“取模”换成“找邻居”
1997年,麻省理工学院提出的 一致性哈希(Consistent Hashing) 给出了优雅的答案。它不依赖“节点数量N”,而是构建了一个 虚拟的哈希环 ——通常是一个0到2³²-1的整数空间,首尾相连形成一个闭环。
具体操作分三步:
- 节点上环 :将每台存储节点通过哈希函数(如MurmurHash)计算出一个哈希值,映射到环上的某个位置。
- 数据上环 :同样用这个哈希函数计算每个Key的哈希值,也映射到环上。
- 顺时针找邻居:从Key的位置出发,沿环顺时针方向走,碰到的第一个节点就是它应该存储的目标节点。
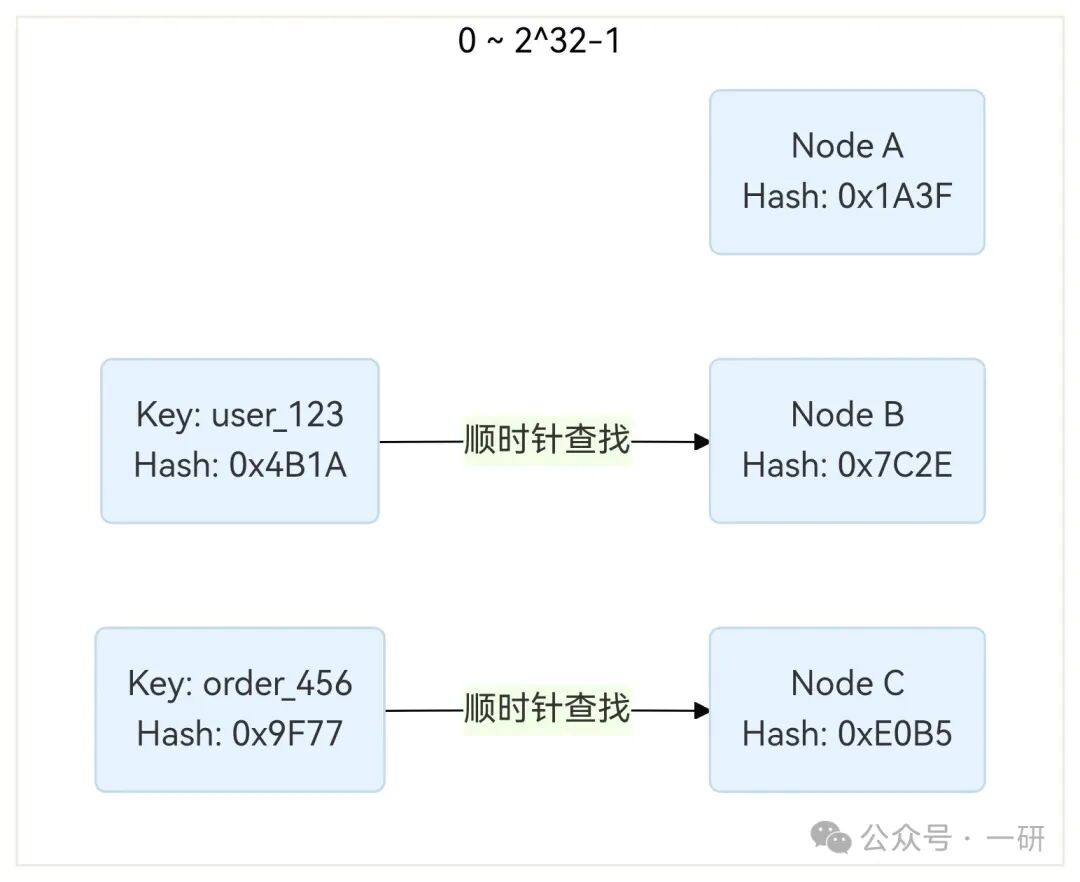
这样一来,当集群中增加一台新节点时,它只需要从环上的“前驱节点”那里接管属于它区间的那一小部分数据,而环上其他节点的数据映射关系完全不受影响。同样,节点下线时,也只需将其负责的数据段交给顺时针方向的下一个节点即可。
以10节点扩容到11节点为例,一致性哈希的数据迁移比例约为1/11≈9%,而传统取模法高达90%——迁移量降低了一个数量级。
数据倾斜?虚拟节点来救场
理想很丰满,现实却很骨感。一致性哈希在节点数量较少时容易出现一个棘手的问题—— 数据倾斜 。
想象环上只有两个节点,A和B。由于哈希函数的随机性,两个节点的位置可能非常靠近,导致一个节点只负责一小段弧,而另一个节点负责了近乎整个环。结果就是一个节点忙得不可开交,另一个却几乎“躺平”。
解决这个问题的关键创新是虚拟节点(Virtual Nodes)。 核心思想很简单:不让一个物理节点只占环上的一个位置,而是给它分配多个“分身”——每个分身就是一个虚拟节点,均匀散落在哈希环的各个位置。
举个例子:系统中有3台物理服务器,给每台分配150个虚拟节点,整个哈希环上就有450个虚拟节点散落其中。 当Key被映射到环上时,先找到负责它的虚拟节点,再通过虚拟节点到物理节点的映射关系,最终确定物理服务器。
vnodeid[hash(key) % vnodeid],vnode -> node
这样一来,物理节点的负载不再是“一锤子买卖”,而是众多虚拟节点负载的叠加。
研究表明,虚拟节点数量设置在100-300时,负载偏差可控制在5%以内。亚马逊Dynamo的经典设计中就充分运用了这一思想,将虚拟节点作为核心分区机制。
从哈希环到DHT:不止是“找到节点”
一致性哈希解决了“数据放在哪”的问题,但DHT要做的事情更多—— 在没有中心协调的情况下,让任意节点都能找到任意数据 。
DHT是一种去中心化的分布式存储方法,本质上是在覆盖网络之上维护了一张分布式的“大哈希表”。 它的特点包括去中心化、伸缩性、容错性和自组织性,允许节点动态加入或退出,而整个系统依然能稳定运行。
典型DHT协议的设计都围绕两个核心问题展开: 数据如何分布 和 如何快速找到数据 。
- Chord协议 ——DHT领域的里程碑之作。它将节点和Key映射到一个环形标识符空间(使用一致性哈希),每个节点维护一张 “Finger Table”(路由表) ,记录环上距离自己指数级增长的若干节点位置。查找一个Key时,Chord采用“二分跳转”的思路,每一步都将距离缩短约一半,从而在O(logN)跳内找到目标节点,其中N为节点总数。
- Kademlia协议 ——BitTorrent和以太坊都在用的经典。它使用160位节点ID和SHA-1哈希,采用 异或(XOR)运算 来计算节点间的“距离”。每个节点维护 k-bucket结构 来管理“距离”自己不同远近的邻居节点。查找时同样逐跳逼近,复杂度为O(logN)。
这两种协议各有千秋: Chord的Finger Table结构简单直观,适合理解DHT路由原理;Kademlia的XOR距离度量对称性好,天然支持并行查询,在实际P2P网络中部署更广泛。
从理论到实践:DHT如何支撑亿级流量
DHT不仅仅停留在学术论文里,它早已是众多大规模生产系统的核心引擎。
- 亚马逊Dynamo ——分布式KV存储的开山之作。Dynamo采用改进的 一致性哈希+虚拟节点方案,将数据均匀分布在去中心化的节点集群上。配合(N, R, W)副本策略、向量时钟版本管理、Gossip成员协议和Hinted Handoff容错机制,Dynamo支撑了亚马逊购物车等核心业务,实现了99.9%的请求响应时间低于300毫秒。这一设计思想直接启发了Cassandra、Riak等后续NoSQL系统。
- 美团Squirrel ——面向万亿级业务的自研内存KV存储。早期美团使用的是“客户端一致性哈希+Memcached集群”的简单架构,但扩容时数据丢失、运维复杂等问题日益凸显。后来演进为自研Squirrel系统,采用 预分片+路由表架构 :将Key空间划分为固定数量的Slot(如16384个),Key先哈希到Slot,再通过路由表定位存储节点。这种设计在 扩缩容时只需调整路由表 ,无需重新计算Key哈希值,实现了真正意义上的平滑扩缩容。
- Apache Pegasus ——另一个值得关注的分布式KV存储。它通过 哈希分片 实现横向扩展,底层使用RocksDB作为存储引擎,并通过PacificA一致性协议保证强一致性。
此外,DHT还广泛用于 P2P网络 (如BitTorrent的无Tracker文件下载)、 IPFS星际文件系统 (内容寻址与节点发现)、 CDN内容分发网络 (边缘节点数据定位)以及 区块链节点发现 等场景。
写在最后
DHT和一致性哈希的核心理念非常朴素:与其依赖中心化调度,不如让数据和节点在数学空间里“自己找到彼此” 。 通过哈希环+顺时针查找,它解决了节点变化时的数据迁移问题;通过虚拟节点,它化解了数据分布不均的困境;通过结构化的路由协议,它实现了对数级的查找效率。
当然,DHT并非银弹。当系统规模变得极其庞大、网络环境跨地域时,传统DHT的距离度量可能不再与物理网络拓扑匹配,导致路由效率下降。
此外,在支持范围查询的场景下,DHT也无法像范围分片那样保持数据的良好局部性。这也催生了众多改进方案——从结合网络拓扑感知的路由优化,到“Power of Two Choices”等智能负载均衡策略,再到基于强化学习的动态分片技术。
理解DHT的设计思路,实际上是在 理解分布式系统的“第一性原理”——如何在去中心化的环境中,用简洁的数学规则达成高效协调。 在云栈社区,我们持续关注这些底层原理如何驱动上层架构的演进。这一思想的价值,远超算法本身,它深刻地影响着每一代分布式系统的架构设计。
 发表于 2026-4-24 17:16:56
|
查看: 153|
回复: 0
发表于 2026-4-24 17:16:56
|
查看: 153|
回复: 0
