如何把一个100字符的长URL缩短成6位短码?本文拆解短链接系统的底层逻辑:从 Base62 算法 到 分布式 ID 生成器 ,从 302 重定向策略 到 布隆过滤器防穿透 。带你掌握支撑千亿级跳转的架构方案。
前两天有同学复盘了他在大厂的面试经历,被问到一个经典的系统设计题:
“我们要设计一个像 t.cn 或 dwz.cn 这样的短链接系统,每天要处理亿级的新增和跳转,你怎么设计?”
这位同学不假思索地回答:“很简单啊!把长链接拿去做个 MD5,取前 6 位当短码,存到数据库里。查询的时候根据短码查出长链接,直接跳转不就完事了?”
面试官随即推了推眼镜,连续抛出了三个灵魂拷问:
- “MD5 必然会有哈希碰撞,100 亿数据量下两个不同长链生成了同一个短码,你让用户跳哪去?”
- “为了性能你肯定要加缓存,但如果有人恶意攻击,不停访问不存在的短码,你的数据库瞬间就会被打挂,怎么防?”
- “HTTP 状态码你选 301 还是 302?如果选错了,你的运营数据统计(点击量、来源)全得报废,你知道为什么吗?”
三个问题下来,当场思路就断了。其实,这道题的核心是考察候选人对于 “高并发系统的唯一性保证与全链路优化” 的理解。接下来,我们从几个关键维度来拆解一个成熟的短链接系统应该如何设计。
一、 核心博弈:HTTP 301 还是 302?
这是面试官考察你对业务理解的第一关,看似简单,却直接影响核心商业模式。
- 301 (Permanent Redirect):永久重定向。浏览器会缓存跳转关系,下次用户访问该短链接时,会直接跳转到目标长链接,不再经过你的短链接服务器。
- 优点:极大地节省了服务器资源,降低了后端压力。
- 致命缺点:你拿不到后续的任何点击数据了! 对于一个短链接服务而言,其核心商业价值之一就是统计和分析每一次点击(如点击量、设备类型、地域分布)。一旦使用 301,浏览器缓存生效后,你的后台统计将彻底失效。
- 302 (Temporary Redirect):临时重定向。每次用户访问短链接,请求都会先到达你的服务器,再由服务器响应跳转指令。
- 优点:可以完美地记录和统计每一次点击,为运营分析提供完整的数据支撑。

结论很明确:除非服务器资源极度紧张、濒临崩溃需要“保命”,否则必须选择 302。数据才是短链接系统的灵魂和商业价值的体现。想深入探讨更多高并发场景下的设计模式,可以参考 云栈社区 的相关讨论。
二、 算法之争:如何生成那唯一的6位短码?
这是技术实现的核心。在100亿的数据量下,如何保证短码不重复?
首先,我们通常使用 Base62 编码(字符集包括 a-z, A-Z, 0-9,共62个字符)。6位短码的理论总容量是 62^6 ≈ 568 亿;如果是7位,则达到惊人的3.5万亿。因此,仅应对100亿数据,6位短码长度已经足够。
1. 哈希算法方案(存在碰撞风险)
比如使用 MD5、SHA-1 或 MurmurHash 等算法对长链接进行计算,然后截取部分结果作为短码。
- 痛点:只要是哈希函数,就一定存在碰撞的可能。虽然在概率上极低,但在100亿这个庞大的基数下,碰撞几乎是必然事件。
- 补救措施:发现碰撞后,常见做法是在原长链接后拼接一个随机字符串(如时间戳)重新进行哈希。但这意味着需要额外的数据库查询去判断是否碰撞,严重损害了写入性能。
2. 自增序列法(主流工业级方案)
放弃碰撞风险的哈希,改为为每一个长链接分配一个绝对唯一的递增ID,再将这个ID转换为Base62编码。
- 第一个长链接分配 ID=1,第二个 ID=2,以此类推。
- 将得到的唯一ID进行Base62编码。例如,ID
100,000,000 经过编码后可能得到 6LAze 这样的短码。
- 优点:从源头上保证了绝对唯一性,不存在碰撞。
- 挑战:如何在海量并发请求下,高效、全局唯一地生成这个自增ID?这本身就是一个经典的 分布式系统 问题。

三、 架构实现:如何支撑千亿级数据的高并发访问?
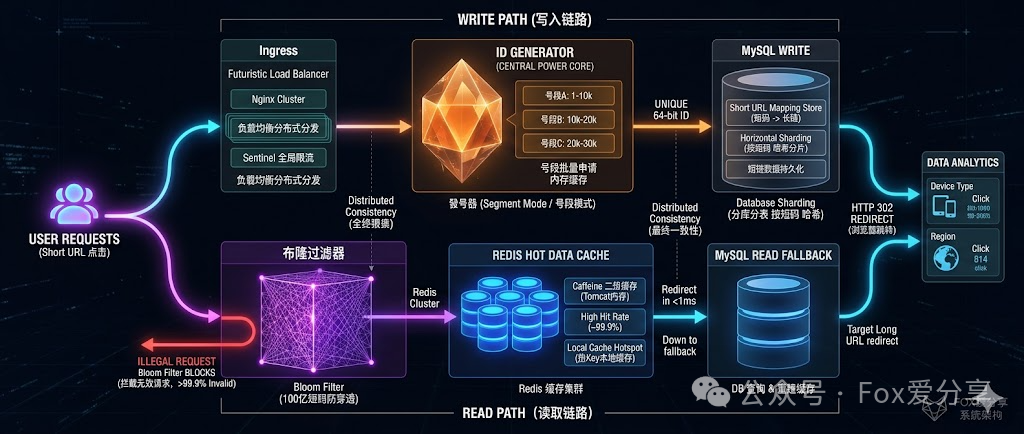
1. 分布式ID生成器(发号器)
单机数据库的自增ID显然无法满足高并发需求。业界普遍采用类似美团 Leaf 或 Twitter Snowflake 的方案:
- 号段模式:服务启动时,或当前号段快用完时,向数据库批量申请一个ID范围(例如:1-10000),并将这段ID缓存在应用内存中。业务请求直接在内存中取号,效率极高。
- 优势:避免了每次生成短码都去访问数据库,可以轻松支撑每秒数万甚至更高的ID生成请求。
2. 读写分离与多级缓存策略
- 写链路:发号器生成唯一ID -> Base62编码为短码 -> 将
短码-长链接映射关系持久化到数据库(如MySQL)-> 同时写入 Redis 缓存。
- 读链路(核心):用户访问短链接时,首先查询Redis缓存。由于短链接一旦生成就几乎不会改变,这个映射关系是静态的,因此缓存命中率可以做到极高(>99.9%),响应速度极快(亚毫秒级)。
- 布隆过滤器:在查询Redis之前,增加一层布隆过滤器进行校验。如果布隆过滤器判断某个短码肯定不存在,则直接拦截此次请求,返回404。这能有效防止缓存穿透,即恶意构造大量不存在短码的请求绕开缓存,直接击穿数据库。
3. 应对热点Key
当某个短链接(例如,某位大V微博中的链接)瞬间被海量用户点击时,该Key会成为 Redis 集群的热点,可能造成单点压力。
- 解决方案:启用本地缓存(如 Caffeine)。在应用服务器(如Tomcat)的内存中,缓存这些极热点的短链接映射。这样,对于热点请求,连访问Redis的网络I/O都省去了,直接从本地内存返回,实现访问速度的极限优化。
四、 面试标准答案思路模板
如果面试中被问到,可以按照以下结构化思路回答,展现系统性思维:
“针对短链接系统设计,我的核心思路是 ‘分布式发号器保证唯一性 + Base62编码压缩 + 多层次缓存保障高性能’ :
- 业务与协议层:采用 HTTP 302 临时重定向,确保每次点击流量都能经过后台服务器,以完成点击量、设备、地域等关键业务数据的精准统计。
- 短码生成层:舍弃存在碰撞风险的哈希算法,采用分布式号段模式生成全局唯一且趋势递增的ID。将此ID进行 Base62 编码,6位短码即可支撑超过560亿的数据量,满足百亿级需求。
- 查询性能层:利用Redis缓存所有
短码-长链接映射。由于映射关系生成后不变,缓存命中率极高,能实现亚毫秒级的查询响应。同时,引入布隆过滤器在缓存层之前拦截非法请求,有效防止缓存穿透,保护后端数据库。
- 容灾与扩展层:针对百亿级数据存储,对数据库进行分库分表(例如按短码哈希值分片)。对于读多写少的特性,可以结合读写分离进一步扩展。同时,系统具备降级策略,当缓存失效时可回查数据库。”
总结
技术面试考察的从来不是你是否知道某个API或算法,而是你对于大规模数据下的唯一性、系统性能、数据一致性以及全链路稳定性的综合掌控能力。
能把一个看似简单的“长链变短链”问题,层层拆解,深入到分布式ID生成、缓存架构设计、协议规范运用等层面,并给出平衡性能、成本与业务的方案,这正是一个高级开发者或架构师需要具备的功底。希望这个拆解能帮助你下次面试时,思路清晰,对答如流。
 发表于 2026-4-6 09:07:49
|
查看: 146|
回复: 0
发表于 2026-4-6 09:07:49
|
查看: 146|
回复: 0
