3 月 25 日,GitHub 官方发布公告,宣布从 2026 年 4 月 24 日起,将调整 GitHub Copilot 用户交互数据的使用规则。新政策将默认使用用户的数据来训练和改进自家的 AI 模型。

哪些用户会受影响?
这次政策更新并非针对所有用户,而是明确区分了版本类型。
受影响的,主要是个人用户使用的 Copilot Free(免费版)、Pro(专业版)和 Pro+(高级专业版)。这类用户在日常编程过程中与 Copilot 的交互数据,包括输入、输出、代码片段、相关上下文,都将成为 GitHub 后续 AI 训练的重要素材。
而 Copilot Business(商业版)和 Copilot Enterprise(企业版)用户,则不会受到此次政策更新的影响。
如果用户不想参与,可以在隐私设置里一键退出。此外 GitHub 还提出了“历史选择保留”原则:倘若用户此前已经关闭了“允许 GitHub 收集数据用于产品改进”的选项,这一设置依然有效,数据不会被用作训练,除非用户主动重新开启。
话虽如此,这一政策一出,再次让开发者社区对 AI 代码助手的数据使用边界展开讨论。
什么数据会被收集?
许多开发者最关心的是:什么数据会被拿去训练 AI?针对这一疑惑,GitHub 在公告中列出了清单,主要包括:
- 用户接受或修改后的 Copilot 输出结果
- 发送给 Copilot 的输入信息,包括展示给模型的代码片段;
- Cursor 附近的代码上下文、注释和文档;
- 文件名、存储库和开发导航模式;
- 与 Copilot 各功能的交互记录,比如聊天互动、建议;
- 用户对建议的反馈(点赞/点踩)。
其明确表示不会使用:
- 来自 Copilot Business、Copilot Enterprise 或企业自有仓库的交互数据;
- 在 Copilot 设置中选择退出模型训练的用户交互数据;
- 处于“静止状态”的 issues、讨论区或私有仓库内容。这里特意使用“静止状态”,因为当你主动使用 Copilot 时,私有仓库中的代码确实会被处理。这部分交互数据是运行服务所必需的,除非您选择退出,否则可能会被用于模型训练。
此外,GitHub 还声称:这一政策使用的数据可能会在 GitHub 关联公司内部共享,这些关联公司包括微软等集团内企业,但不会与第三方 AI 模型提供商或独立服务商共享。
为何需要用户数据?官方:为了让AI更“懂”编程
GitHub 解释,这次调整的目的很直白:通过真实开发者的使用数据,让 Copilot 的模型更“懂编程”,提供更贴近实际的代码建议。
最初,Copilot 训练主要依靠公开可用代码和人工样本。去年开始,GitHub 尝试用微软内部员工的 Copilot 交互数据训练模型,结果显示,代码建议采纳率明显提升。事实证明,真实开发场景中的交互数据能让模型更精准地理解开发者的工作流,不仅提供更实用的补全,还能提前识别潜在漏洞,降低生产环境风险。
换句话说,你每次使用 Copilot、每次点赞或吐槽,都在帮它变得更聪明。
社区反对声强烈:安全隐患与信任危机
不过,从 GitHub 社区近期的讨论来看,这项计划并不算受欢迎。仅从 emoji 投票来看,用户给出了 97 个踩(👎),而仅有 4 个火箭(🚀)。

有开发者犀利地指出了政策中存在的多个安全隐患,特别是在企业环境中:
首先,我所在组织的用户并没有授权将公司源代码的版权许可授予他人,也无权允许将代码向第三方公开。
其次,将选择权设为“个人退出”,意味着只要我的某个员工没有关闭该选项,你们就可能获得我们公司全部源代码的访问权。
再者,新加入的用户或外部协作者如果没有主动退出,可能会在无意中让你们获得对公司源代码的事实性访问权限。
此外,这项政策也使我们无法满足 SOC 2 合规要求,因为我们将无法再明确知道究竟有哪些主体可以访问我们的源代码。
更进一步,你们还可以在未来随时修改政策,以某种方式让自己获得对我们源代码的事实性访问权。
这对信任是一次严重打击。我正在强烈建议公司逐步迁离 GitHub。Copilot 本身并没有特别大的价值,更不值得你们擅自把我们的代码和想法通过大模型“分享”给其他人。

热评第一的开发者则直接批评了这种“默认选择退出”的机制:“如果用户代码培训如此明显有益,为什么每家公司都试图将其隐藏在开关、脚注或分级定价背后,而不是自豪地征求用户同意呢?真正做到‘自豪地征求同意’的方式是要求用户选择加入,而不是通知他们该功能将在未来某个日期启用,从而要求他们选择退出。”
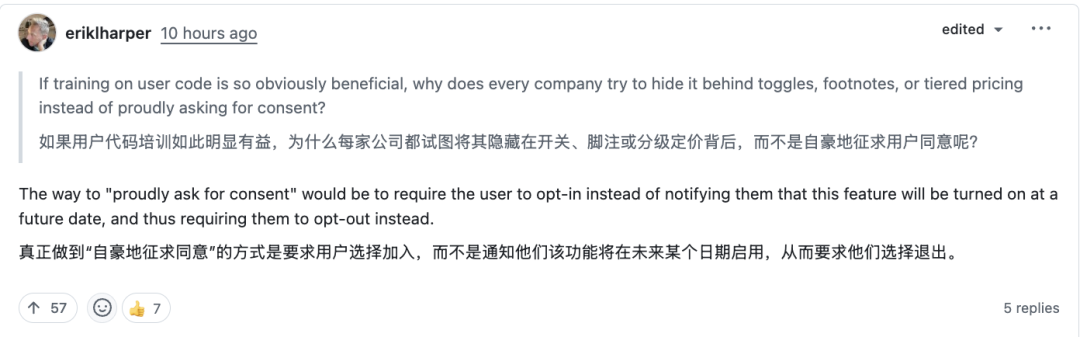
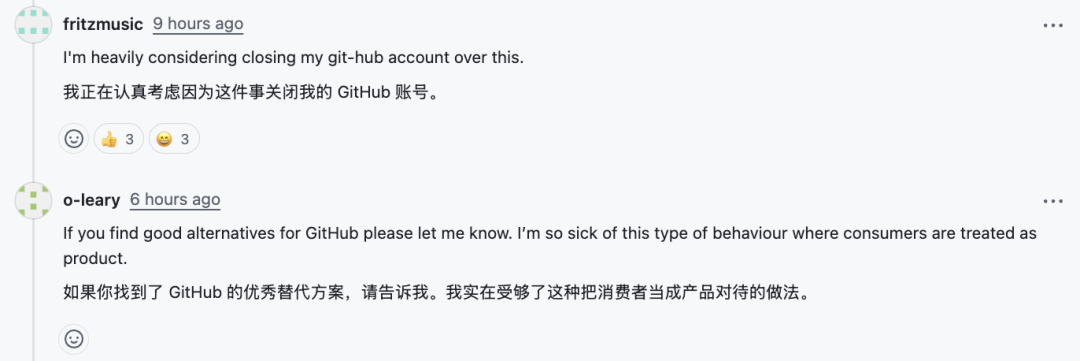
这一事件也引发了部分开发者对平台本身的信任危机,甚至开始寻找替代方案。在开源实战领域,关于代码所有权和开源协议的讨论也再度升温。有人表示:“我正在认真考虑因为这件事关闭我的 GitHub 账号。” 另一位开发者呼应道:“如果你找到了 GitHub 的优秀替代方案,请告诉我。我实在受够了这种把消费者当成产品对待的做法。”
目前,GitHub 尚未公布具体的数据脱敏方式和训练周期,但从 2026 年 4 月 24 日起,普通用户将正式迎来这一规则。这究竟是AI助手进化的必然代价,还是对开发者权利的一次越界?欢迎在云栈社区分享你的看法。
参考链接:
 发表于 2026-3-27 04:03:49
|
查看: 167|
回复: 0
发表于 2026-3-27 04:03:49
|
查看: 167|
回复: 0
