
接触电脑,尤其是通过游戏入门的朋友,大都对屏幕上的3D特效印象深刻。早期的震撼往往伴随着“画面不够真实”的遗憾。在个人电脑中,GPU是仅次于CPU的关键芯片。CPU负责绝大多数任务的分发、数值与逻辑计算,而GPU则专注于一件事:图像处理。那么,为什么在近一二十年间,GPU会成为从游戏到科学计算的广泛领域的核心话题?这背后是一条从专用图形渲染走向通用并行计算的必然技术演进路径。
一、GPU图形计算的需求特性
让GPU渲染的游戏画面变得更真实,是其设计的首要目标。那么,图形数据在计算机中最初是如何组织的呢?答案是通过点、线、面构成的三角形,我们称之为“图元”。三角形之所以成为图形学的基础,是因为三个点能唯一确定一个平面,而四个点则难以判断其空间关系。因此,三角形是构成GPU图像的最小单元。
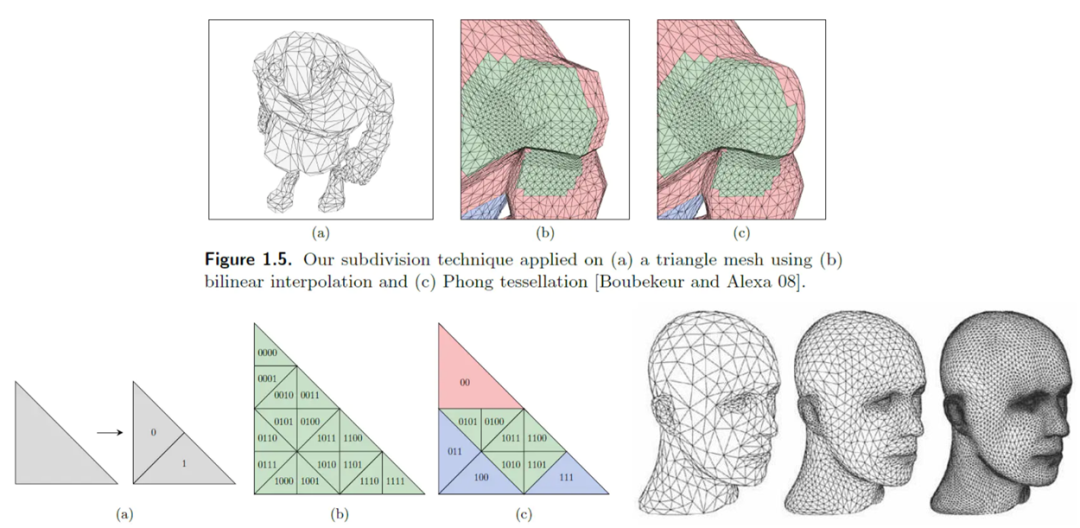
要构建一个复杂模型,比如人的头部,只需不断细分三角形网格,细节(如鼻子、眼睛)便会逐渐呈现,轮廓也越来越逼真。
处理这些三角形顶点的单元,被称为顶点着色器。它的核心工作是对图像进行旋转、平移、缩放,即完成一系列坐标变换:
- 模型变换 (Model):将顶点从模型空间转换到世界空间。
- 观察变换 (View):将顶点从世界空间转换到以摄像机为原点的观察空间。
- 投影变换 (Projection):将顶点从观察空间转换到为后续裁剪和屏幕映射做准备的裁剪空间。
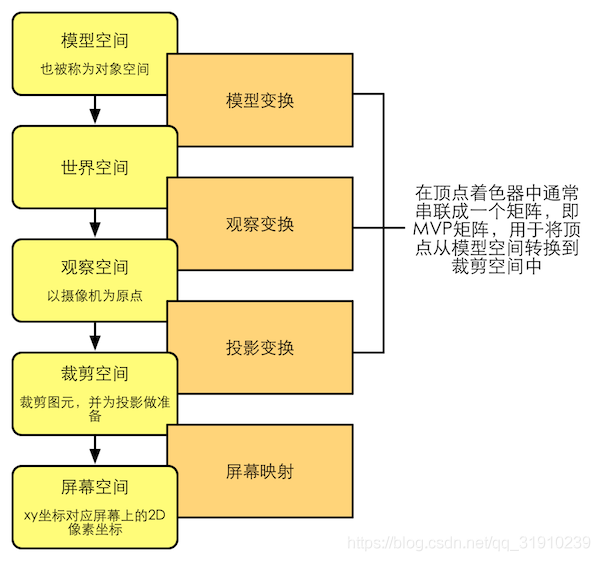
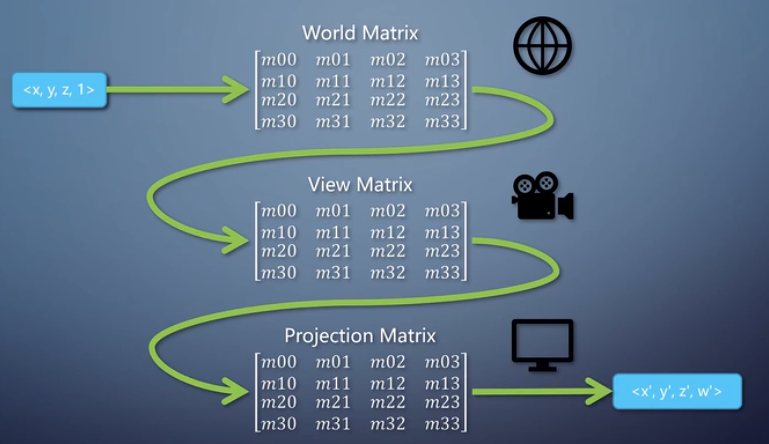
这三层重要的矩阵计算,决定了三角形最终在屏幕上的形态与位置,对应着游戏中角色的每一个动作。早期的顶点处理功能甚至不叫“着色器”,而是被称为“坐标转换与光源”(T&L),是GPU上最早出现的固定功能流水线单元之一。
仅有顶点构不成我们看到的彩色像素图像。例如,一台1920×1080分辨率的显示器,意味着要处理超过200万个像素点。

像素着色器的工作,就是在顶点处理之后,为这数百万个点计算出正确的颜色。每个像素的颜色通常由红、绿、蓝三个通道的数值决定,这构成了一个庞大的计算矩阵。每个像素着色器每个时钟周期处理一个像素。
在顶点和像素处理之间,光栅化 是关键桥梁。它将几何信息转化为屏幕上的片段。
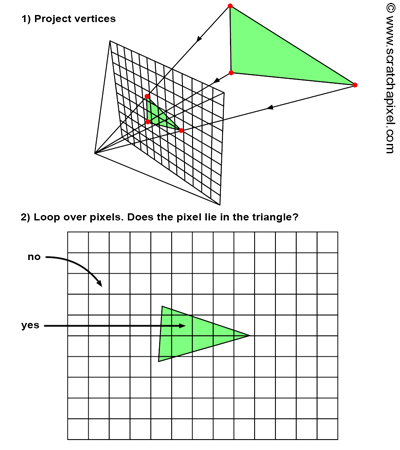
光栅化首先创建2D画布,接收组装好的图元(如三角形),并将其转换为独立的片段,这些片段最终成为像素。它使用三角形遍历规则来确定网格如何覆盖每个像素,其后的流水线阶段便是像素着色器。
至此,一条经典的图形渲染流水线便清晰了:包含顶点着色器、光栅化、像素着色器等环节,其中既有可编程单元,也有固定功能的硬件单元。
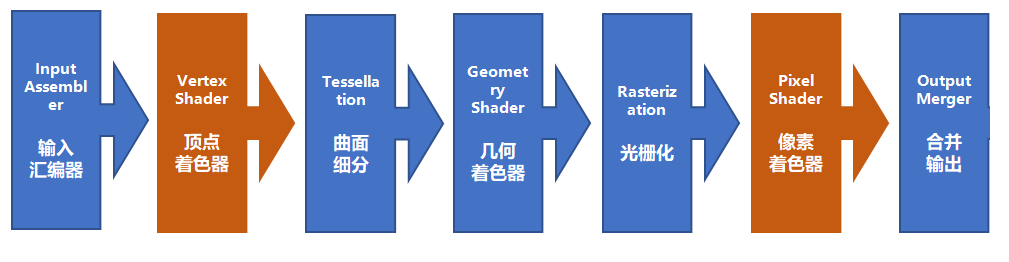
对于可编程的着色器,我们不仅可以输入图形任务,还能“伪装”成图形任务输入计算任务。而蓝色标注的单元(如输入汇编器、光栅化、合并输出)则是固定功能电路,专为图形流水线设计。
推动这条流水线不断演进的关键力量,除了NVIDIA、AMD等硬件厂商,还有微软及其DirectX API。每次DirectX重大更新引入的新图形特性,都对GPU提出了新的硬件要求。
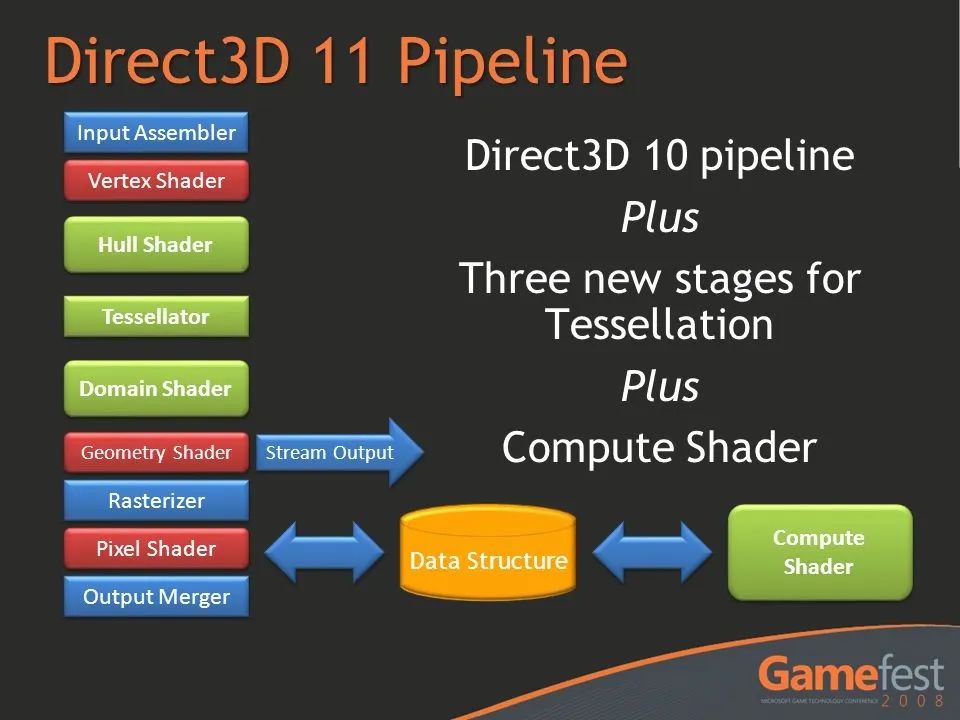
以DirectX 7.0引入的硬件T&L为例,它标志着GPU开始独立承担繁重的顶点矩阵计算,将CPU解放出来,是GPU确立其独立地位的关键事件。早期的显卡虽然简陋,但核心组件(GPU、显存、独立供电、主动散热)的形态已定。

到了DirectX 8.0时代,顶点和像素计算需求激增,微软首次引入了 Shader Model 概念,可视为GPU的图形渲染指令集。Pixel Shader和Vertex Shader成为SM 1.0的一部分,此后每次DirectX大版本更新,SM都会升级,特性大幅增强。
| Shader Model |
GPU代表 |
显卡时代 |
特点 |
| (前SM时代) |
1999年第一代NV Geforce256 |
DirectX 7 (1999~2001) |
固定功能T&L,不可编程。 |
| SM 1.0 |
2001年第二代NV Geforce3 |
DirectX 8 |
顶点部分出现可编程性,像素部分可编程性有限。 |
| SM 2.0 |
2003年ATI R300和第三代NV Geforce FX |
DirectX 9.0b |
顶点和像素可编程性更通用,像素支持浮点,纹理可作任意数组(对通用计算很重要)。 |
| SM 3.0 |
2004年第四代NV Geforce 6和 ATI X1000 |
DirectX 9.0c |
顶点程序可访问纹理,支持动态分支,像素程序支持分支和函数调用。 |
| SM 4.0 |
2007年第五代NV G80和ATI R600 |
DirectX 10 (2007~2009) |
统一渲染架构,支持IEEE 754标准,引入几何着色器,资源大幅提升。 |
| SM 5.0 |
2009年ATI RV870和2010年NV GF100 |
DirectX 11 (2009~) |
明确提出通用计算API Direct Compute,更好支持双精度浮点,硬件曲面细分单元。 |
例如,DirectX 9.0时代对浮点数的支持,打破了图形质量的数学精度限制。同样在2003年的SIGGRAPH大会上,利用GPU进行非图形计算的设想被广泛探讨,GPGPU的大门正式开启。因为此时的GPU在浮点计算能力和并行度上已超越CPU。
无论是处理顶点坐标的矩阵变换,还是计算像素颜色的数值,GPU都天然地在进行着并行矩阵运算。这种由图形任务塑造的并行计算能力,为其日后进入更广阔的高性能计算领域奠定了坚实基础。
二、GPU并行计算发展的大致路径
GPU的演进不仅限于PC,在游戏主机中也是核心。2005年底微软发布的Xbox 360,其Xenos图形处理器首次引入了统一着色器架构。

这种架构内的SIMD单元既可以执行顶点着色器任务,也可以执行像素着色器任务,更为灵活。随后,NVIDIA在2007年发布的GeForce 8800 GTX采用了128个标量流处理器,其统一架构和MIMD化执行为通用计算提供了更好基础。
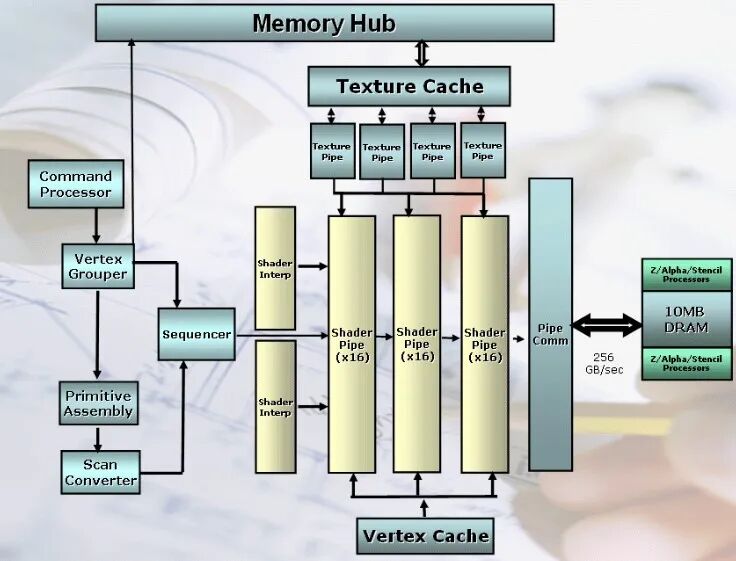
DirectX 10引入的统一渲染架构是重要转折点,从此不再严格区分顶点和像素单元,全部由统一的流处理器动态分配任务。这背后既有技术趋同的原因,也源于对未来并行计算蓝海的远见。
一个标志性事件是2009年中国的“天河一号”超级计算机,它使用了5120颗AMD GPU(ATI HD 4870X2),凭借GPU的并行能力,一举将中国超算推至世界前列。

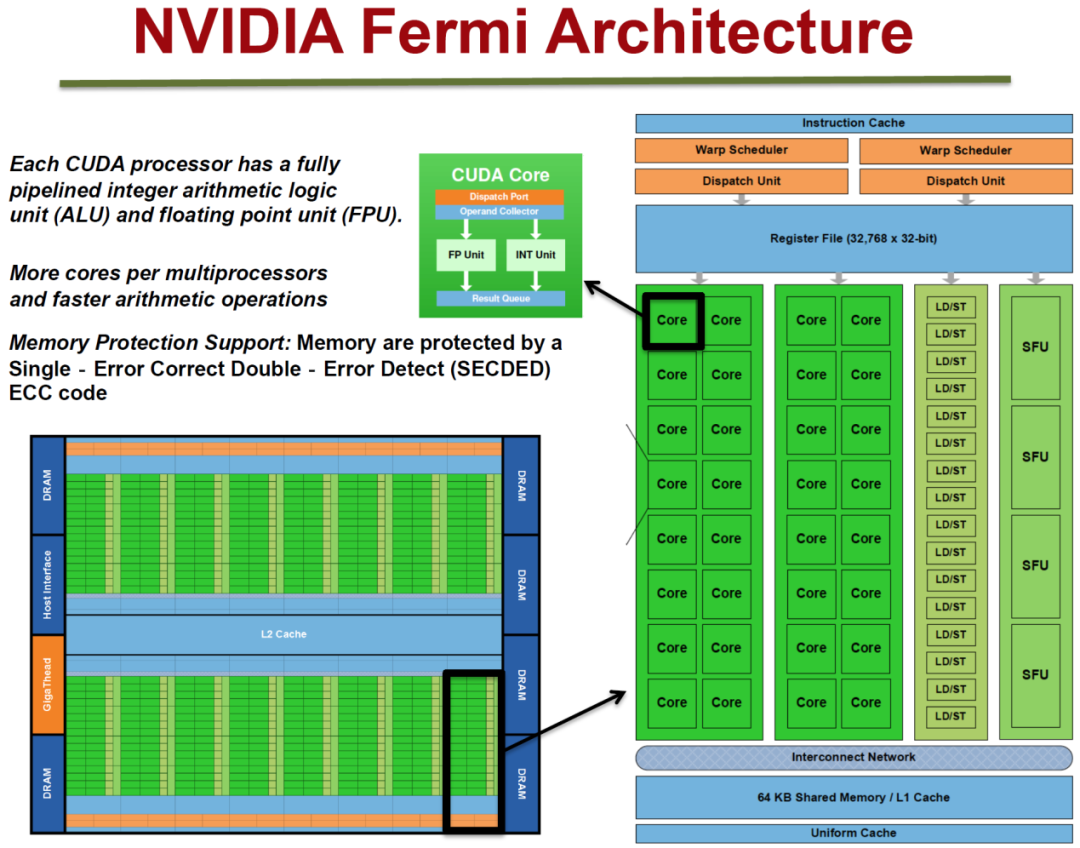
真正为并行计算量身定制的GPU是2010年NVIDIA发布的“Fermi”架构。它的大部分晶体管首次明确用于服务并行计算,而不仅仅是图形。其革新包括:
- 完善的缓存体系:首次引入真正的可读写L1/L2缓存并支持ECC,更符合商业计算需求。
- 强大的底层计算单元:延续高效的MIMD流处理器设计,大幅提升双精度浮点性能。
- 先进的线程调度能力:实现了SM级别的双发射,支持更复杂的SPMD(单程序多数据)模型。
- 分支论断支持:为条件语句的执行提供了硬件加速,这是向CPU分支预测能力靠拢的雏形。
2011年底,AMD也推出了革命性的GCN架构,放弃了VLIW体系,采用模块化的计算单元设计。每个计算单元包含标量和矢量单元,并具备独立的二级线程控制机制。其基础仍是SIMD,但多组SIMD阵列同步运行使其具备了MIMD特性。
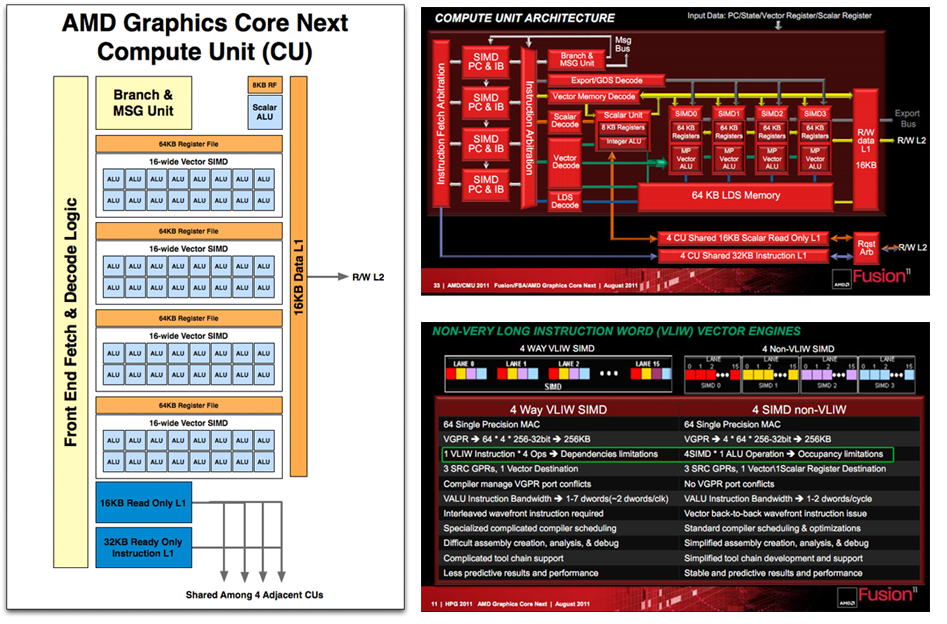
调度能力是衡量GPU并行效率的关键。这涉及到“发射”概念——一个时钟周期内,调度单元能向执行单元发射多少微指令。
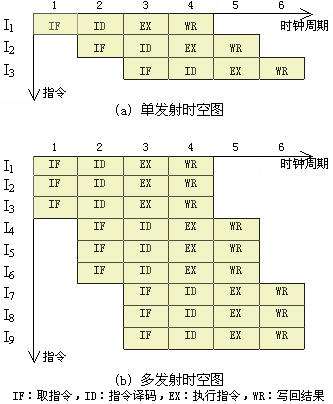
多发射设计需要更多的取指、译码和写回部件。早期AMD GCN架构在计算单元内部的调度资源相对精简,而NVIDIA Fermi则已在每个SM实现了双发射,拥有更多调度单元,这体现了二者不同的设计目标:NVIDIA更激进地转向通用并行计算,而AMD当时更侧重于满足图形市场需求。直到2019年的RDNA架构,AMD才显著增加了发射资源。
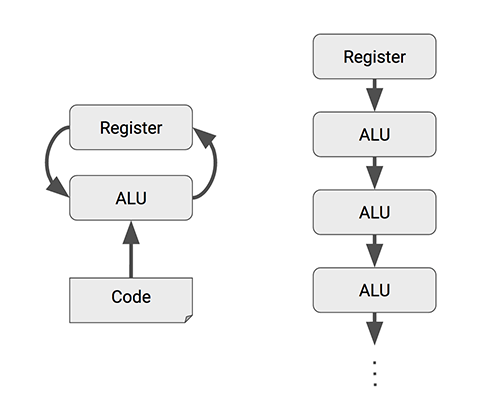
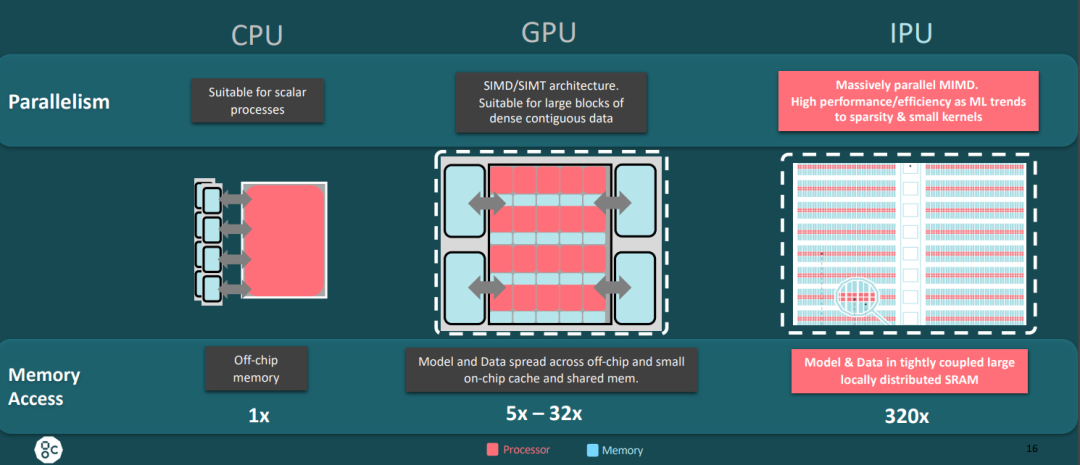
CPU与GPU的架构差异可概括为四点:通用 vs 专用、多核 vs 众核、复杂 vs 简单、调度 vs 计算。
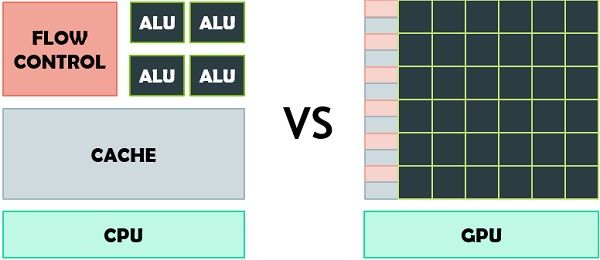
从晶体管布局也能看出端倪。CPU大量晶体管用于多级缓存、内存控制器、分支预测和乱序执行等控制逻辑;而GPU则将绝大多数晶体管用于构建海量的计算核心,通过大规模并行线程来隐藏内存访问延迟,从而实现高吞吐率。
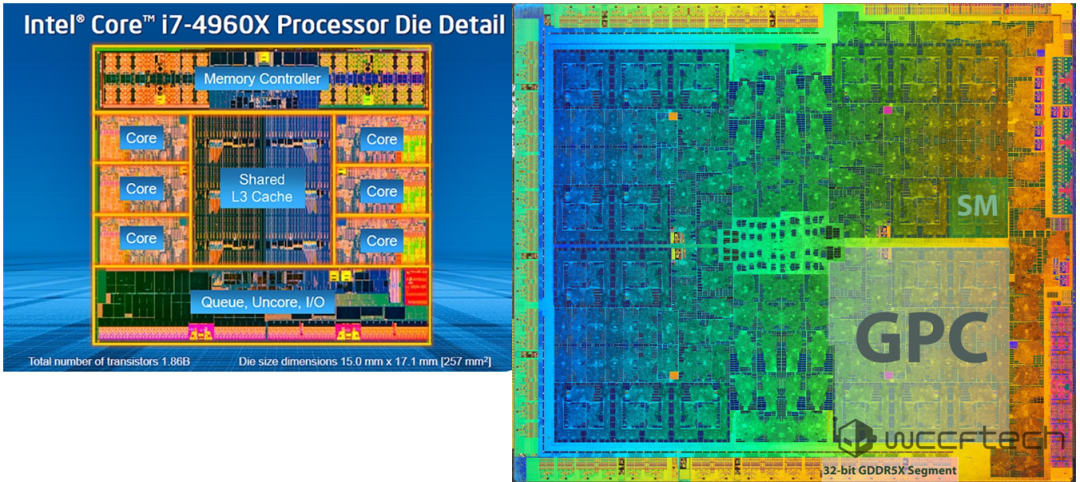
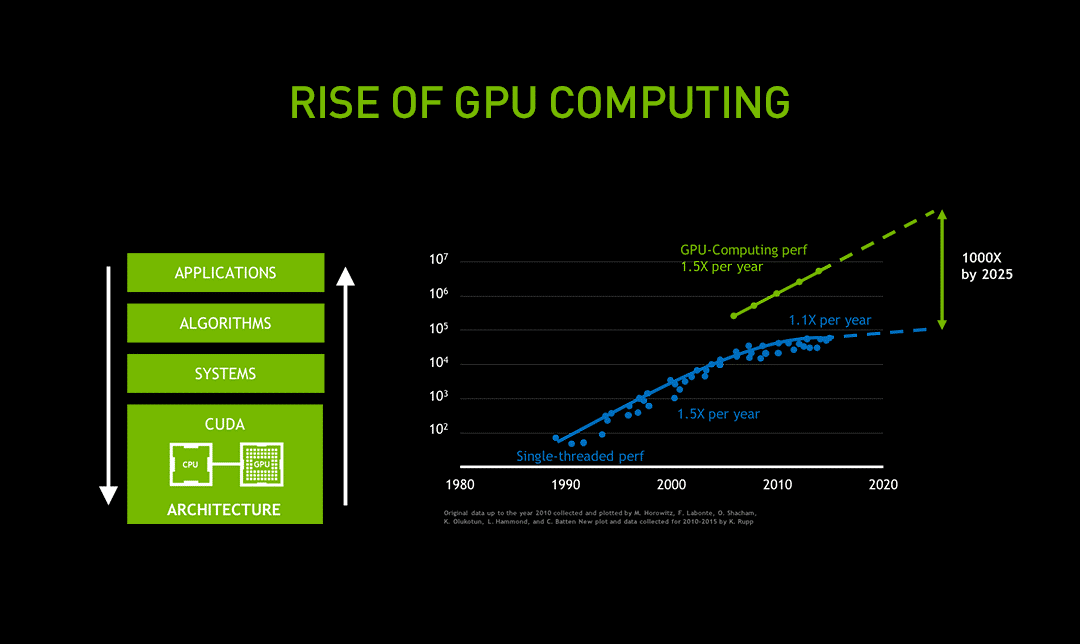
CPU擅长低延迟的串行复杂逻辑计算,GPU则专精于高吞吐的并行数据计算。按照NVIDIA的预测,结合特定硬件单元和混合精度计算,GPU的计算能力优势将进一步扩大。
三、图形向计算的架构演化
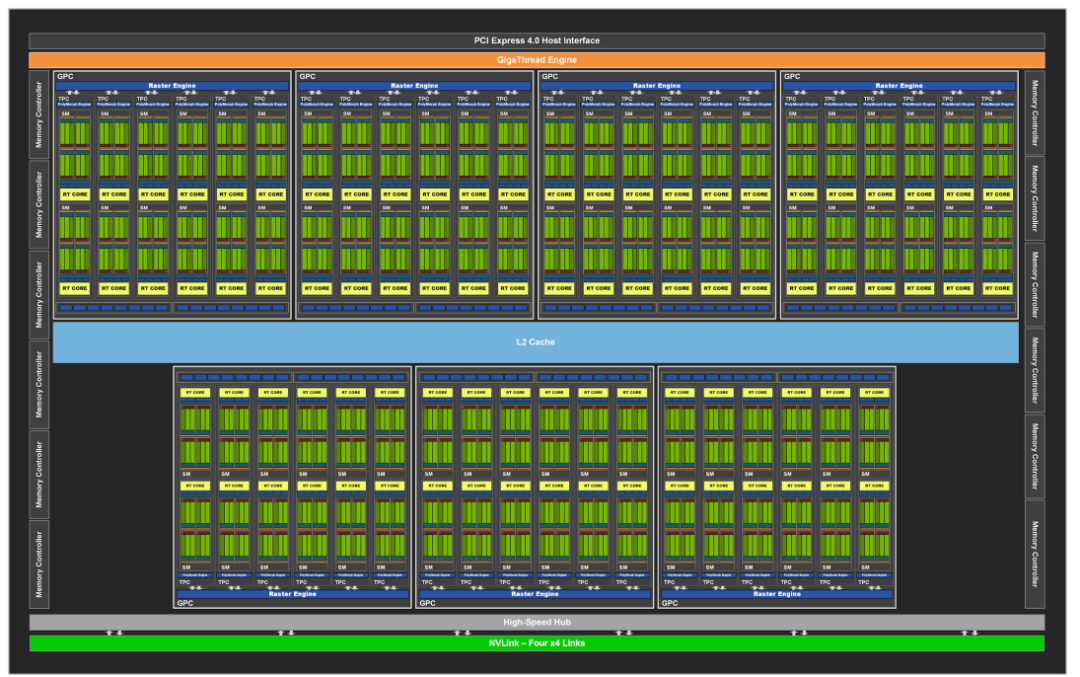
近年来,以NVIDIA为例,GPU在并行计算领域的架构演化方向明确。流式多处理器 是GPU的基本计算单元,包含线程调度器、存储访问单元、计算核心、特殊函数单元以及多级缓存/寄存器。
最新的Ampere架构(如GA102)进一步增强了SM。以RTX 3090为例,其拥有海量的CUDA核心,L1缓存升级至128KB,并集成了第二代RT Core(光追核心)和第三代Tensor Core(张量核心)。
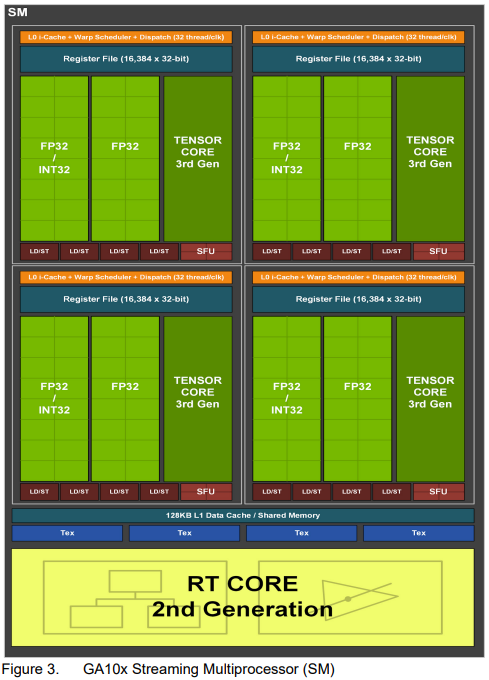
Ampere架构的一个显著变化是FP32单元数量翻倍,旨在提升图形和计算性能。这引发了一些讨论,因为上一代Turing架构曾强调整数与浮点并行的优势。无论如何,对并行计算应用而言,更强的FP32能力通常是利好。
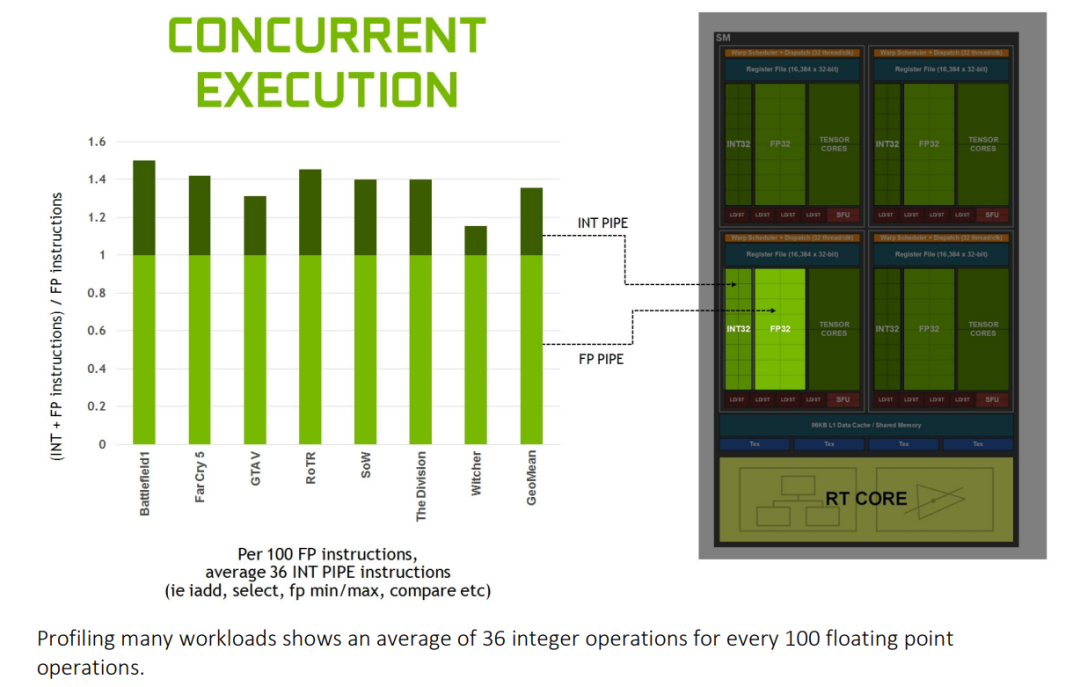
值得注意的是,面向图形市场的GeForce系列显卡与面向计算的Tesla系列(如A100)在FP64双精度单元上有显著区别。Gecrete系列的FP64性能被大幅削弱,而A100则保留了相当规模的FP64单元,因为科学计算等领域仍需要高精度。
张量核心 是GPU面向人工智能和深度学习的关键创新。张量可理解为高阶数组,是深度学习中的数据主要形式。Tensor Core是一种执行混合精度矩阵乘加运算的专用硬件单元,能大幅提升AI训练和推理效率。
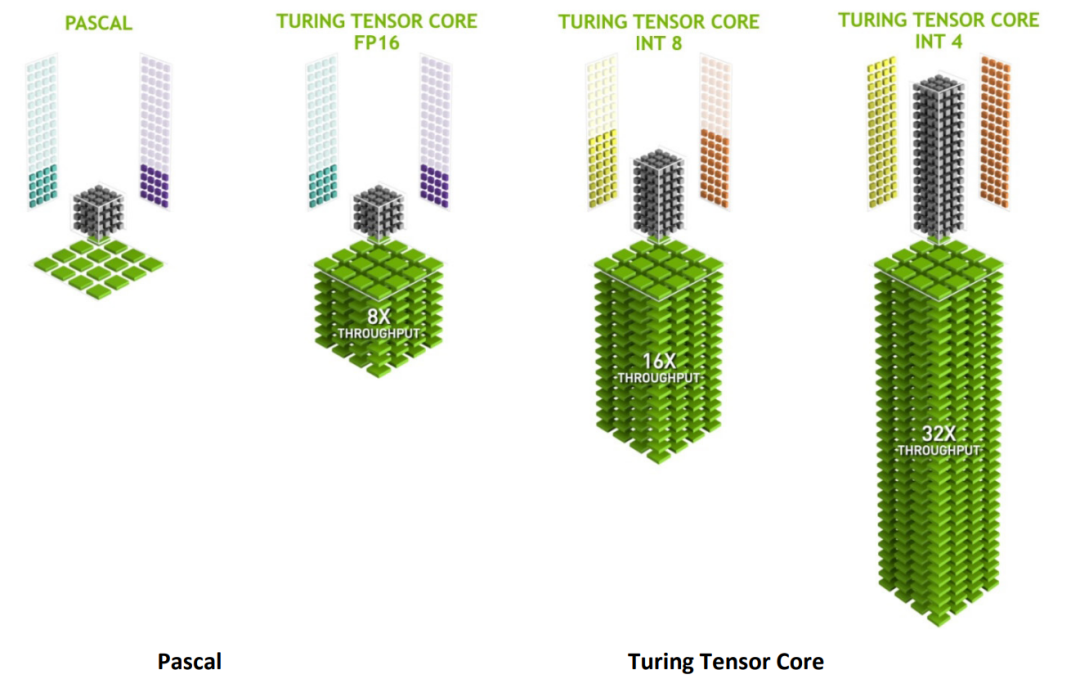
NVIDIA Ampere架构支持丰富的精度格式,包括TF32、FP64、FP16、INT8和INT4。其中,TF32 是一种巧妙的设计,它采用FP32的8位指数范围,但使用与FP16相同的10位尾数精度,在AI负载中实现了性能、范围和精度的平衡。

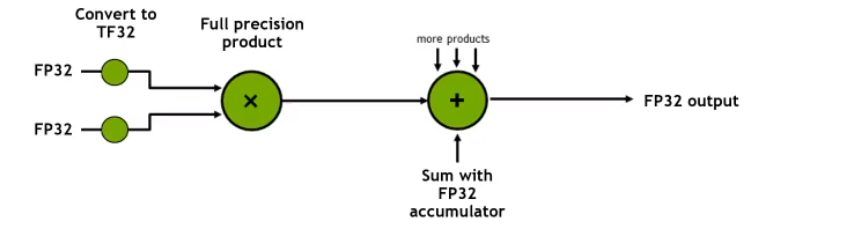
TF32在计算时自动将FP32输入转换为TF32进行乘加运算,最终结果仍以FP32格式累加和输出,用户无需修改代码即可获得性能提升。
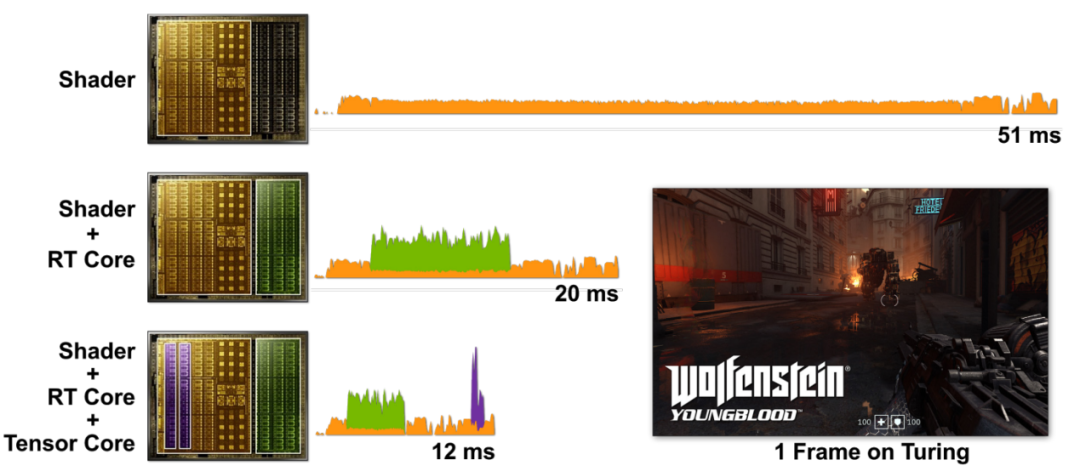
在游戏渲染中,Tensor Core也能发挥作用,例如用于深度学习超级采样或光线追踪降噪,与传统的着色器、光追核心协同工作。
为了应对多GPU高密度部署的需求,NVIDIA开发了 NVLink 和 NVSwitch。NVLink是集成于GPU内部的高速互连总线,而NVSwitch则是一颗独立的交换芯片,用于构建多GPU全互联拓扑,提供远超PCIe的GPU间通信带宽,这对于大规模AI训练和超算至关重要。

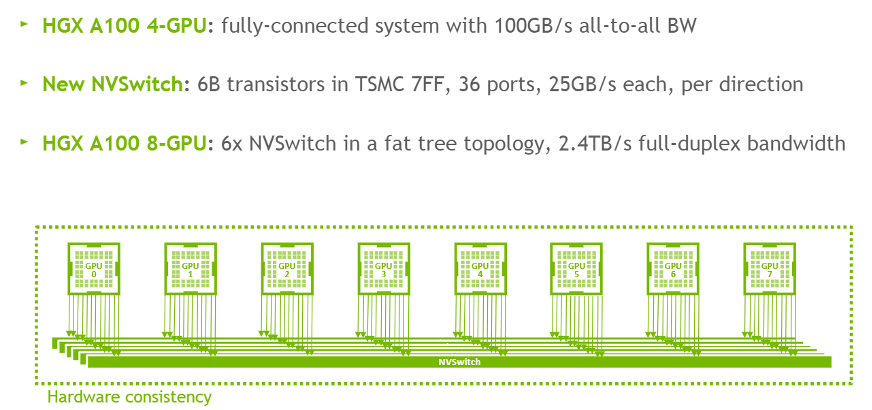
国内如幻方等机构,就利用搭载NVSwitch的DGX系统或自建集群,构建了强大的AI算力平台。

四、谷歌TPU与特殊用途加速器IPU
最后,我们看看专用计算芯片。为应对自身海量深度学习任务的需求,谷歌在2016年推出了张量处理单元。TPU是一种ASIC,专为神经网络中的矩阵乘加运算设计,结构极度简化。
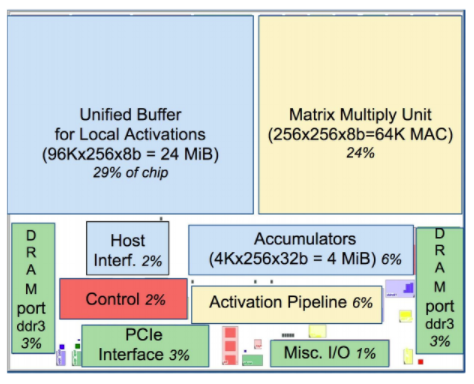
与CPU/GPU相比,TPU省去了复杂的分支预测、多级缓存等控制逻辑,将大部分芯片面积用于大规模矩阵乘法单元和片上内存。它采用脉动阵列设计,数据在ALU网络中有节奏地流动复用,实现了极高的能效和确定性性能。在部分神经网络模型上,TPU性能可达同期CPU的数十倍。
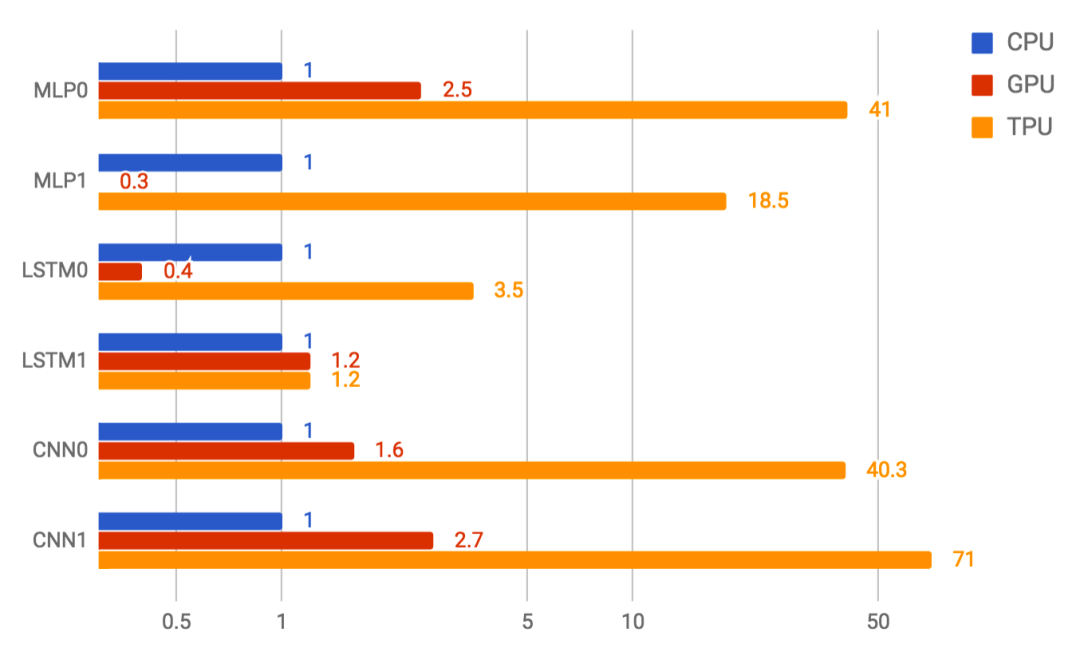
另一类值得关注的专用处理器是Graphcore的IPU。其设计理念是将超大规模片上SRAM与大量处理核心紧密耦合,旨在解决AI计算中的内存带宽瓶颈问题。
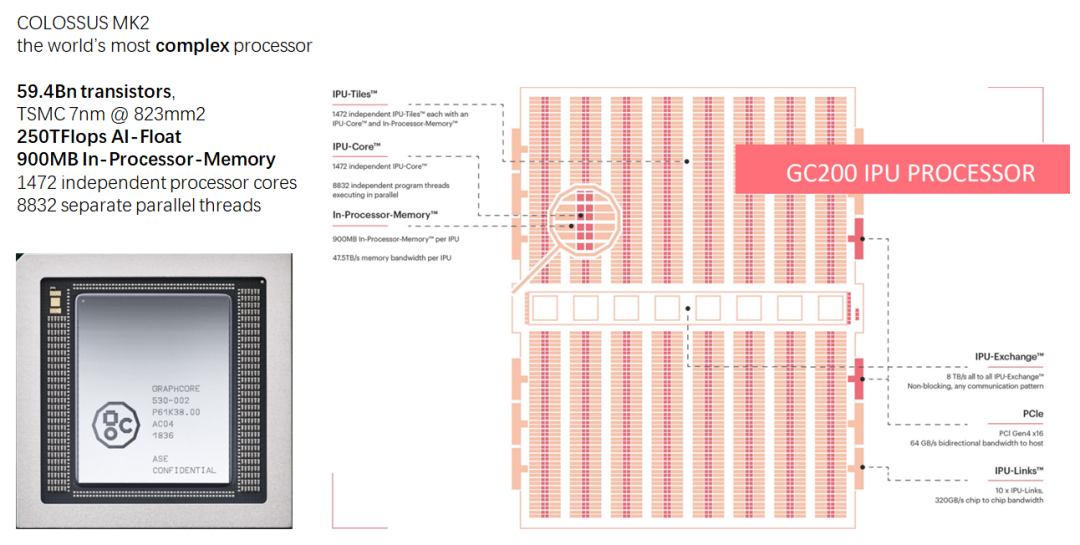
Graphcore宣称,在部分金融计算模型(如MCMC、LSTM)上,其IPU产品相比最新GPU有数量级的性能提升。这为特定领域的高性能计算提供了新的选择。
结语
硬件处理器的设计驱动力根本上是业务需求。GPU之所以能从一颗纯粹的图形芯片,逐步演变为当今并行计算和人工智能的基石,其初始且持续的动力正是我们对更逼真、更流畅图形体验的不懈追求。游戏和视觉应用市场支撑了GPU早期快速迭代所需的资金和技术积累。
在满足图形需求的过程中,GPU的架构被锤炼得极其适合大规模并行矩阵运算。当科学计算、数据分析、深度学习等新需求出现时,早已“身怀绝技”的GPU自然成为了最佳载体。从固定功能的T&L单元,到可编程着色器,再到统一架构、专用Tensor Core和高速互联技术,GPU的每一步演进,都不仅是图形技术的进步,更是其向更广阔并行计算领域深化的必然路径。这是一场始于图形、兴于并行的精彩技术旅程,也为其他硬件发展提供了经典范本。对技术演进历程的深入理解,有助于开发者在云栈社区这样的平台更好地选择和利用计算资源,应对未来的挑战。
 发表于 2026-3-28 01:07:41
|
查看: 136|
回复: 0
发表于 2026-3-28 01:07:41
|
查看: 136|
回复: 0
