来源:中国金融电脑 作者:青藤云安全 林崇攀 刘凯
数字经济浪潮下,金融行业的数字化转型已进入深水区。线上化、智能化业务的蓬勃发展带来了新的增长点,但技术的快速迭代也让金融机构面临着前所未有的网络攻击态势。攻击手段日趋隐蔽、复杂和定向,使得传统依赖静态规则的网络安全防护体系,在海量告警处置与高级威胁研判方面显得力不从心。
近年来,以 大模型 为核心的 人工智能 技术为网络安全防护模式的升级开辟了新路径。将 AI 智能体引入网络安全场景,已成为金融机构提升主动防护效能的关键抓手。
然而,网络安全 AI 应用要在金融业真实业务环境中实现规模化落地,并非易事。它面临着算力适配、数据处理、研判可信度等一系列现实挑战。为此,青藤云安全推出了网络安全 AI 智能体——青藤“无相 AI”,并在金融、电信等行业的头部客户环境中完成了测试与落地探索。本文基于“无相 AI”在 6 家金融机构的实测数据与经验,系统梳理了落地过程中的核心挑战,并分享针对性的解决策略与实践成效。
一、金融行业网安AI智能体落地的核心挑战
1. 公共算力平台及通用大模型的兼容适配挑战
通用大模型的进化速度远超安全垂直领域模型,因此行业客户更倾向于使用公共算力平台和通用大模型。这就要求 AI 智能体必须首先解决与这些外部平台的兼容对接问题,主要挑战集中在两方面:
一是 算力平台 token 用量限制的挑战。当前,大多数平台设有“单位时间 tokens 用量限制”,默认时间尺度通常是每分钟。在网络安全场景下,大模型的 token 调用需求在时间分布上极不均衡。如果平台采用过小的时间尺度进行限制,很容易因为瞬时超限而导致关键的研判任务失败。
二是 大模型安全围栏的限制挑战。为满足合规要求,算力平台通常设有安全围栏等机制来防止模型滥用。然而,在开发 网络安全 专用智能体时,若安全围栏策略设置不当,可能会误拦截包含真实攻防样本或行为数据的合法研判请求,从而导致任务失败。
2. 海量告警处理与有效告警研判之间的矛盾
金融机构部署的网络安全设备众多,产生的流量侧告警规模极其庞大。高效处理海量告警并进行精准研判,是 AI 智能体落地的核心场景,也是矛盾最集中的环节。
矛盾一:流量侧海量告警与有限算力的矛盾。 相比于基于静态规则的快速匹配,大模型研判需要更多的“思考”和响应时间。稀缺的算力资源限制了 AI 的并发研判效率。当巨量告警持续涌入时,研判队列会被迅速占满,导致告警积压,永远处理不完。
矛盾二:告警数量多与有效信息少的矛盾。 虽然流量数据格式标准,易于分析,但单条流量告警所提供的信息往往十分有限。如果大模型仅基于这些单薄的告警数据进行研判,准确率会大幅降低,并产生海量误报,让真正的攻击信号淹没在噪声中,最终导致整个 AI 研判系统“失信”。
二、网络安全AI智能体落地的具体问题解析与解决实践
针对上述核心挑战,青藤基于“无相 AI”在多家金融机构的实践,对具体问题进行了深入解析,并探索出一套有效的落地方案。
1. 适应网络安全场景的token用量限制策略
(1)场景问题解析
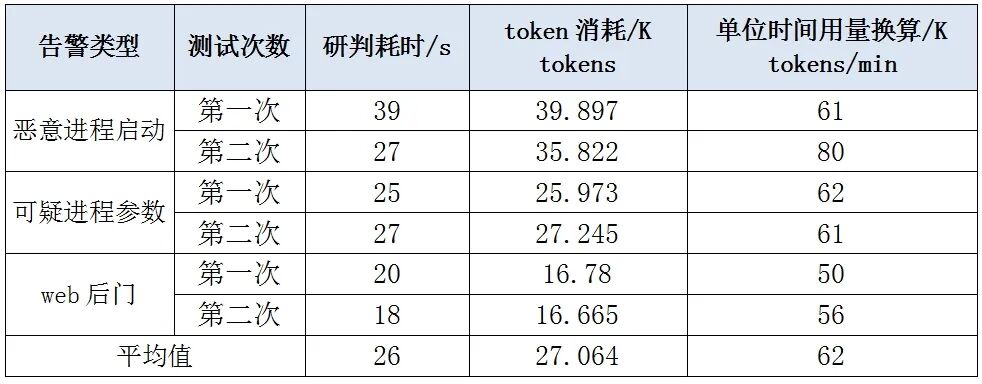
算力平台默认以分钟为单位的 token 限制策略(通常为几十 K tokens/min)并不适用于网络安全场景。一方面,智能体能力越强,处理复杂任务消耗的 token 就越多;另一方面,网络安全告警具有脉冲式的不均衡特性。在需要并发研判大量告警时,短时间尺度的限制极易导致任务失败。下表展示了实测中的告警研判 token 消耗情况:
表1 告警研判token用量观测数据
(2)落地实践
金融机构在落地 AI 智能体时,首先应在申请算力资源时明确要求适配网络安全场景的 token 限制策略。
- 时间尺度选择:鉴于告警数据的时间不均衡性,应尽可能选择长时间尺度的限制策略,至少应支持以“日”为单位。
- 用量估算方法:具体的 token 限额需根据“每日需研判告警量 × 单次研判 token 用量”来估算。参考上表数据,单次研判的 token 用量均值约为 27K tokens。
2. 兼顾效率与合规的大模型安全围栏策略
(1)场景问题解析
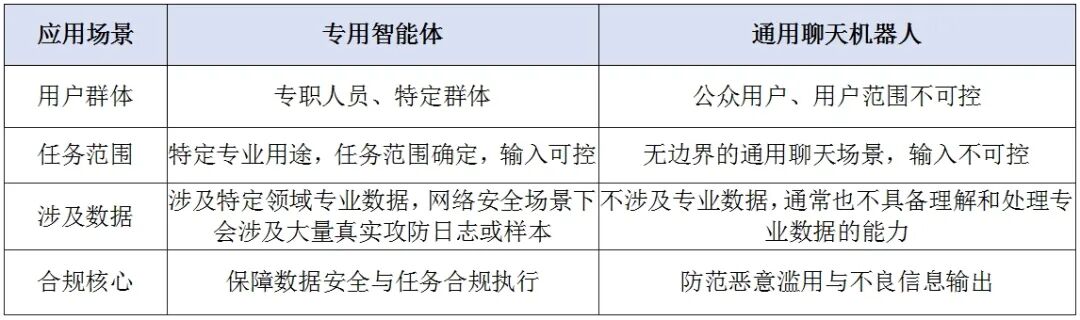
部分平台默认开启的全局安全围栏,会因安全研判任务输入中包含真实入侵样本或行为数据而进行拦截。但这并非恶意请求,相同的任务在公共模型上验证均可正常响应。核心问题在于,安全围栏未能有效区分专用智能体场景与通用聊天机器人场景。
这两种场景在用户群体、任务范围、数据涉及面及合规核心上存在本质区别,不应采用“一刀切”的策略。
表2 专用智能体与通用聊天机器人对比
(2)落地实践
应用落地需在效率与合规间找到平衡点。
- 按场景区分策略:算力平台应为不同应用场景的 API-key 设置差异化的安全围栏策略。对于专用智能体场景,应采取更宽松的策略。
- 场景化围栏定制:由于专用智能体的输入 Prompt 和数据范围相对固定,可让安全模型在“仅告警不拦截”模式下运行一段时间,学习该智能体可能触发的围栏类型。经审核后,即可针对该智能体取消相关误拦截策略,实现精细化的场景定制。
3. AI辅助的数据源头降噪机制
(1)场景问题解析
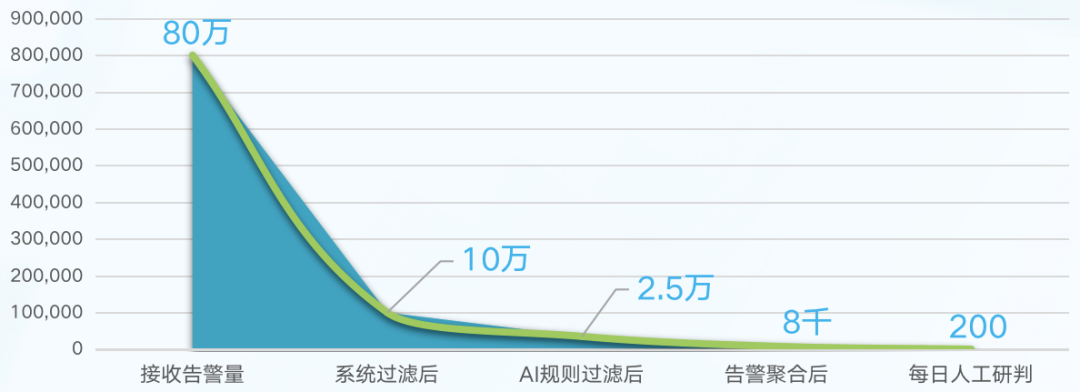
以 32 套 NDR(网络检测与响应)设备为例,其日均告警量可超过 80 万条。而测试算力每分钟仅能支持约 40 条告警的并发研判。告警的持续堆积会使研判任务越来越滞后。这既有大模型自身响应较慢的原因,也暴露出在算力稀缺前提下,告警数据质量本身存在问题。
(2)落地实践
算力的稀缺性凸显了高价值数据的重要性。在告警进入研判队列前,通过构建三级降噪体系,可以过滤掉绝大部分低价值噪声数据。
- 系统预设过滤规则:根据实际业务,筛选明确无需研判的情况(如响应码为 403/404 的告警),可过滤掉约 80% 的噪声。
- AI过滤规则:基于数字人研判结果和专家标注的误报,AI 会归纳误报原因并生成过滤规则。新规则生成时也会与已有规则融合、归并,以提高效率。此环节可再过滤约 70% 的明确误报。
- 告警聚合规则:对经过前述过滤的告警,在入队前进行时间窗内的聚合,避免对同一事件的重复研判。
实践表明,经过“系统预设—AI过滤—告警聚合”三级降噪后,日均需人工审核的告警量从最初的 80 万条锐减至约 200 条。
图1 告警数据三级降噪事件成效示意图
4. 端网联动的上下文增强研判模式
(1)场景问题解析
仅依靠原始告警信息进行研判,准确率低且结论不稳定,容易出现两种极端:一是倾向于将一切告警都判为真实攻击,导致误报泛滥;二是在设定严格判定原则后,又因信息不足而频繁研判失败。
(2)落地实践
必须改变“以告警研判告警”的传统模式,构建“以上下文研判告警”的新模式。
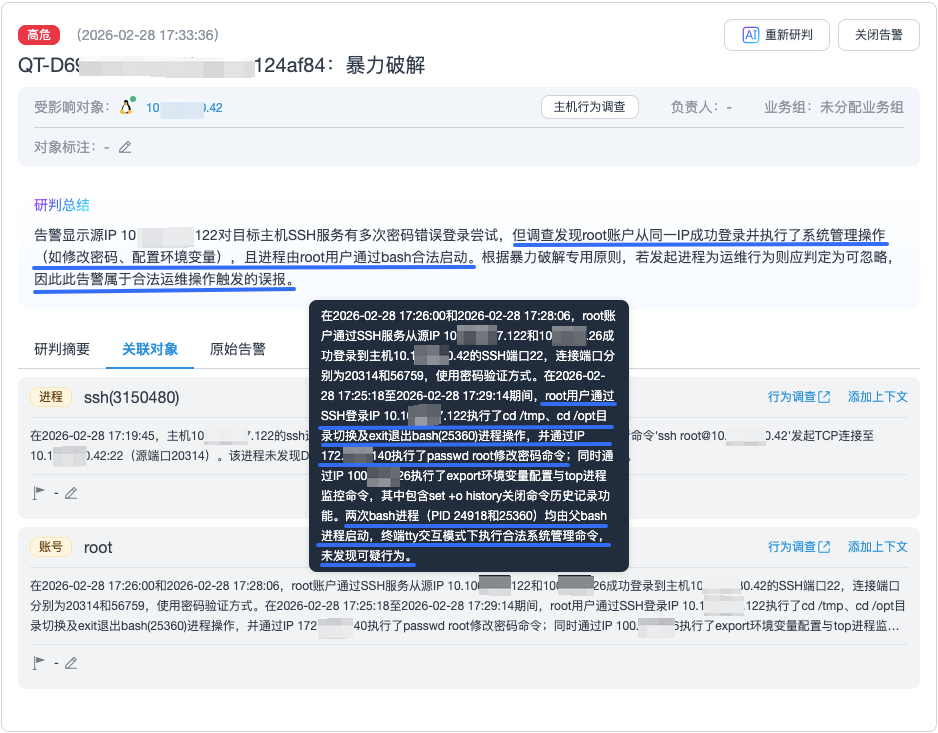
- 构建数据关联机制:将流量侧告警关联到主机上的具体服务、进程等对象,进而调取其告警时间前后的端侧行为数据,补充完整的上下文信息。
- 优化研判逻辑:综合流量告警与端侧的业务上下文进行分析,而非依赖单一告警字段。
案例:某次因管理员忘记密码触发暴力破解告警。若仅关联 NDR 和 HIDS 的告警,大模型易判定为攻击。但青藤“无相 AI”通过关联主机上下文信息(如成功登录后执行了合法的系统管理操作),正确将其研判为运维行为,判定为“可忽略”。
图2 端网联动“以上下文研判告警”实例
三、落地实践成效总结
基于上述解决方案,青藤“无相 AI”成功突破了从实验环境到真实业务场景的落地瓶颈,取得了以下成效:
- 广泛兼容适配:通过场景化的 token 策略与分场景的安全围栏优化,实现了与金融机构主流公共算力平台及通用大模型的稳定对接,为规模化落地奠定了基础。
- 处理效能量级跃升:借助多级联动告警降噪体系,可高效处理日均百万级告警数据,最终日均人工审核量仅约 200 条,告警收敛率超 99%,极大释放了安全运维人员的工作压力。
- 研判可靠性全面提升:通过端网联动的全上下文研判模式,打破了传统局限,使得告警研判的准确率和可解释性大幅提升。实测数据显示,基于全上下文的研判置信度普遍达到 98% 以上,使 AI 研判结果真正变得可信、可用。
特别提示:本文首发于《中国金融电脑》杂志,探讨了 AI 安全智能体在金融行业落地的现实路径与解决方案。对于更多前沿技术落地实践与深度讨论,欢迎关注 云栈社区 的相关技术板块。
 发表于 2026-3-28 01:19:25
|
查看: 126|
回复: 0
发表于 2026-3-28 01:19:25
|
查看: 126|
回复: 0
