面对分散在不同业务、不同技术栈的监控数据,如何快速搭建一个统一的视图?宏地科技作为一家覆盖商用车车联网、智慧商砼等多个领域的公司,就遇到了这个典型问题。他们需要在6天内,将7个独立业务平台的监控数据整合起来。本文将分享他们基于夜莺(Nightingale)和VictoriaMetrics构建跨平台监控中台的实战经验与避坑指南。
核心挑战:在“行驶的赛车”上换零件
项目初期,宏地科技的监控环境堪称一个“监控烟囱”的典型案例:
- 平台杂:涵盖智慧商砼、校车平台、车联网、充电桩等7个独立业务系统。
- 组件多:技术栈横跨传统的Oracle/MySQL数据库,到现代的IoTDB、RabbitMQ消息队列以及Kubernetes(K8s)容器平台。
- 数据源多样:监控指标散落在自建的VictoriaMetrics集群、独立的Prometheus实例以及K8s集群内生的Prometheus中。
- 时间紧迫:留给团队从环境搭建到实现7大平台全覆盖的时间,仅有6天。
架构设计:混合动力,统一入口
面对复杂的现状,团队没有选择耗时费力的“数据大搬家”,而是采用了多源聚合的策略,让数据待在原地,通过逻辑进行统一:
- VictoriaMetrics (VM):作为主时序数据库,专门处理智慧商砼和车联网业务产生的高频IoT数据,充分利用其MetricsQL在查询性能上的增强优势。
- K8s内生Prometheus:通过夜莺监控直接接入K8s集群内部的Service地址,避免了从外部跨网络抓取数据的额外开销和复杂度。
- 原有独立Prometheus:保留旧有运维系统的采样点,通过夜莺进行逻辑上的平移和统一纳管。
- 最终效果:数据不动,逻辑动。夜莺扮演“指挥中心”的角色,实现了跨所有平台监控指标的一键查询与溯源。
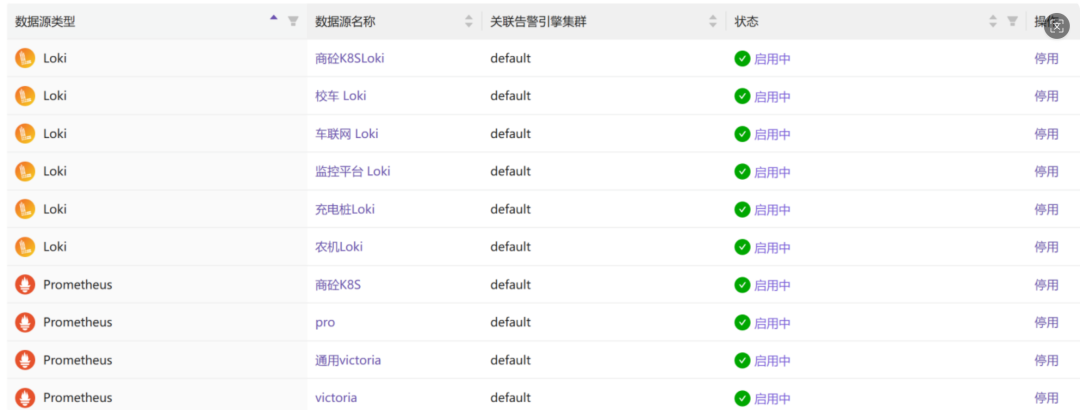
实战避坑:那些“细节”里的填坑笔记
真正的挑战往往隐藏在细节里。以下是几个关键的实践经验。
1. 标签降级兼容:解决“识别不了项目”的混乱
- 痛点:不同业务、不同时期部署的Exporter,其指标标签命名极不规范。有的叫
project,有的叫projectA,有的甚至没有任何项目标识标签。
- 对策:在夜莺的告警通知模板中,建立一套“标签提取优先级链条”。
- 逻辑:优先寻找
project标签 -> 如果找不到则寻找projectA标签 -> 再没有则尝试app标签 -> 最后保底显示“通用项目”。
- 价值:确保了无论底层数据源多么混乱,最终发送到钉钉等通知渠道的告警信息,运维人员都能一眼看出是哪个业务线出现了问题。
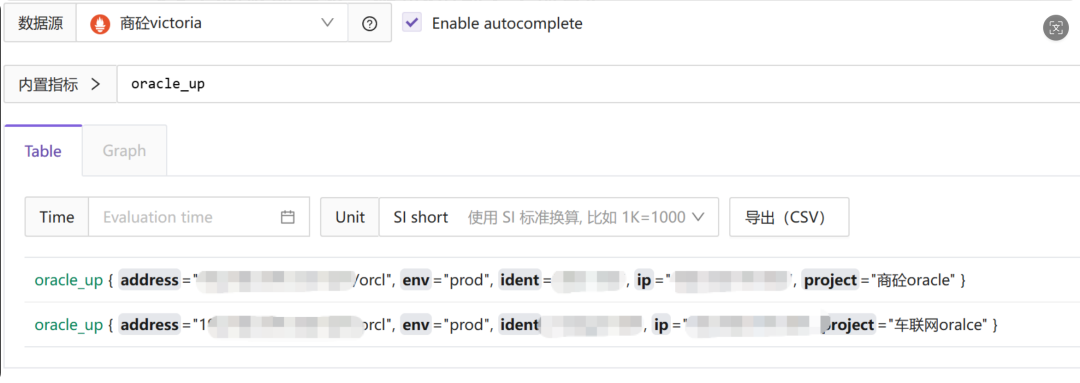
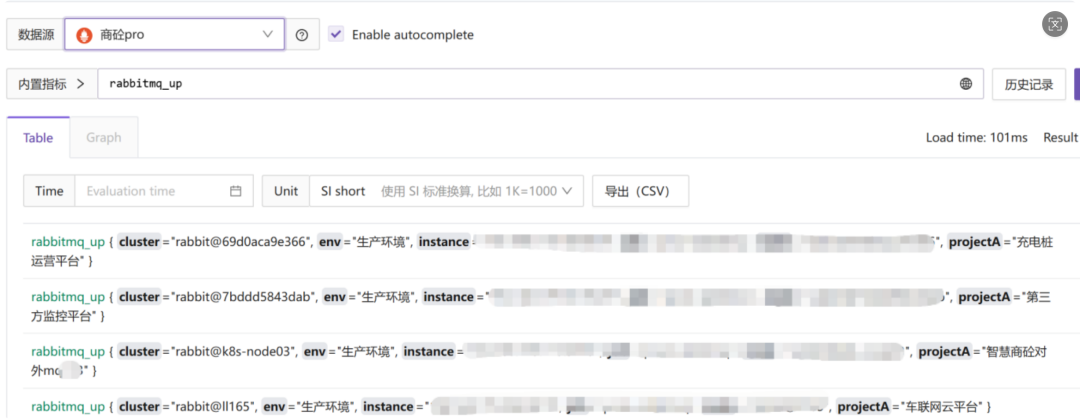
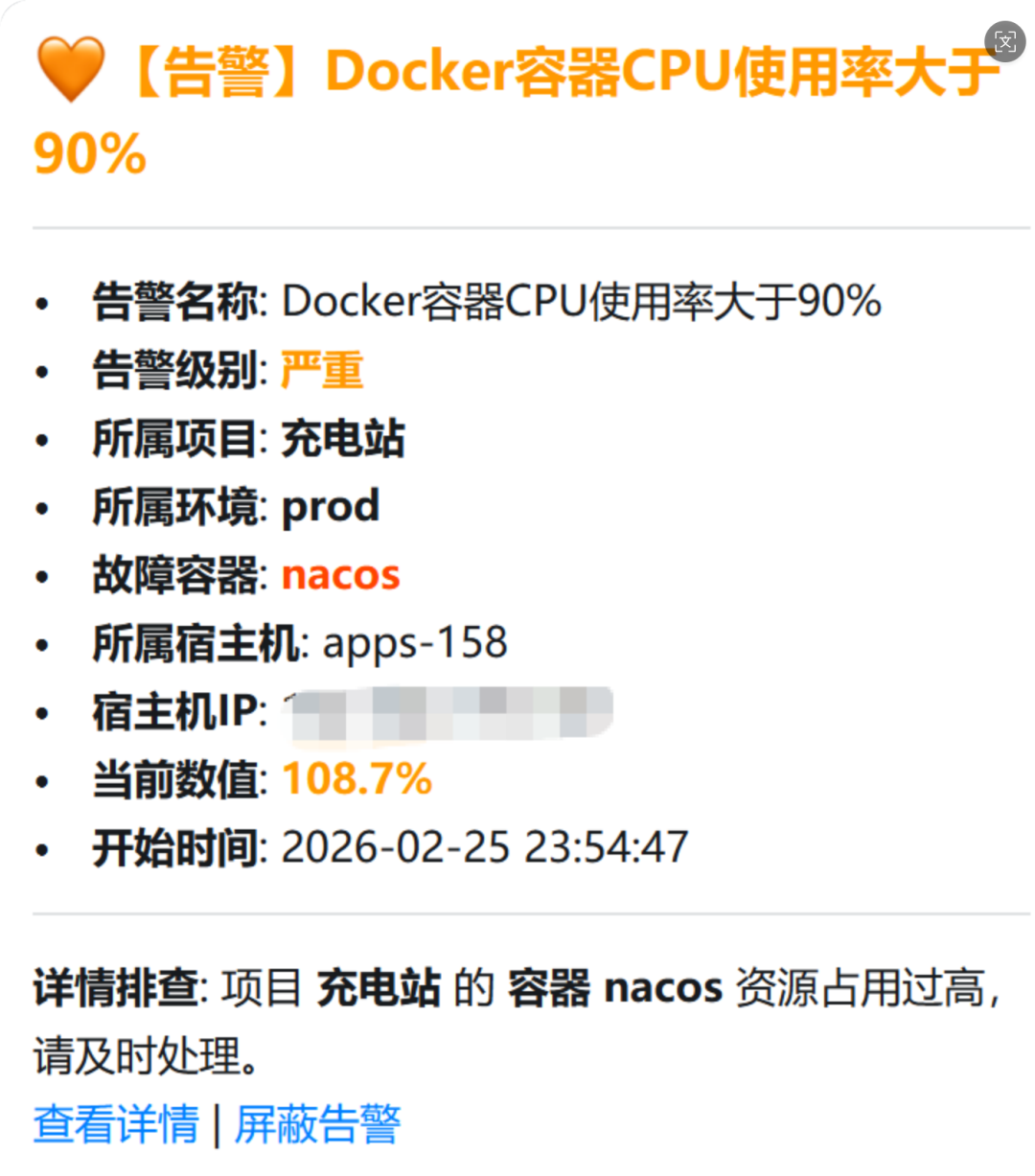
2. 标识优先级重构:解决“故障对象指代不明”
- 痛点:在监控容器CPU使用率时,告警信息如果只上报主机IP(
ident),运维人员无法快速定位是宿主主机上的哪个容器出了问题。
- 对策:在告警规则中,智能定义故障对象标识的提取顺序:容器名 (
container_name) > Pod名 (pod) > 主机名 (ident) > IP地址。
- 效果:告警标题从模糊的 【告警】192.168.xx.xx 异常,变成了清晰的 【告警】rabbitmq 容器异常。这种“一眼定罪”的能力,直接为每次告警处理节省了至少5分钟的二次排查时间。
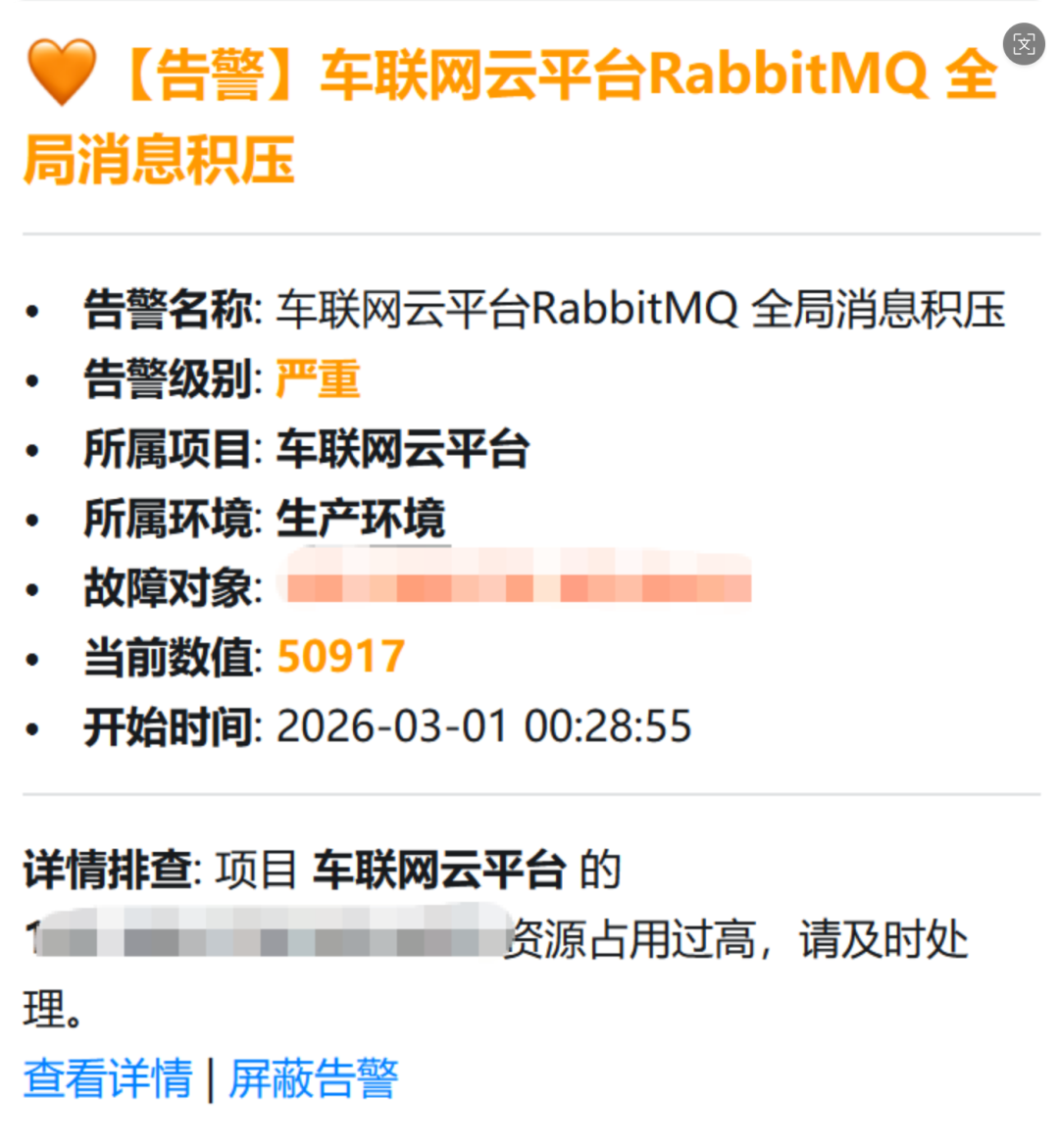
3. 语义化告警:让机器指标“说人话”
- 痛点:传统的“up”类服务存活指标,服务挂掉时上报的数值是“0.0”。对于非专业人士或紧急情况下的运维,反应不够直观。
- 对策:
- 状态转译:在告警通知模板中,将数值“0”映射为红色的 “离线” ,将“1”映射为绿色的 “在线”。
- 排查逻辑分流:根据触发告警的指标名称(例如,是服务存活的
up指标,还是资源使用的usage指标),自动切换通知底部的故障排查建议文案。不再用笼统的“资源占用过高”去描述一个已经宕机的服务。
核心技术干货:统一的核心指标计算口径
为了确保监控数据的准确性与可比性,项目团队对核心监控指标的计算口径进行了统一和优化。
CPU 利用率(平滑去噪)
round((1 - avg by(instance, projectA) (rate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100, 0.01)
注:这里选择使用rate函数而非irate,并配合5分钟的滑动窗口,有效过滤了类似商砼系统设备瞬间启动时产生的瞬时毛刺,避免了大量误报警。
内存使用率(真实视角)
round((1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100, 0.01)
注:强制使用MemAvailable(系统估算的可用内存)而非简单的(MemTotal - MemUsed)进行计算,排除了Linux系统文件缓存(Cache/Buffer)的干扰,经实践,这一改动降低了30%以上的虚假内存告警。
落地执行时间表
如何在6天内完成如此复杂的整合?以下是他们的实战推进表:
| 阶段 |
任务重点 |
核心产出 |
| D1: 筑基 |
拉起夜莺(n9e)/VictoriaMetrics核心服务,接入商砼核心数据库与消息队列 |
商砼生产链路监控实现闭环 |
| D2: 标准化 |
全量部署Categent采集器,下发统一的主机监控模板 |
7大平台主机资源统一画像 |
| D3: 安全攻坚 |
完成校车、车联网平台的视频流与MQTT协议指标接入 |
高并发接入层稳定性监控就绪 |
| D4: 垂直调优 |
接入Oracle数据库存活、IoTDB写入性能、充电桩支付链路等业务指标 |
数据库与核心交易链路深度监控 |
| D5: 闭环告警 |
调试全兼容告警通知模板,配置P0/P1级别分级推送策略 |
“语义化”告警通知全面上线 |
| D6: 驾驶舱 |
构建7大项目健康度总览大屏,完成全链路拨测验证 |
统一运维驾驶舱交付使用 |
写在最后:监控的本质是“清晰的救火指南”
通过这6天的高强度重构,宏地科技团队成功将监控从“一堆令人困惑的数字”转变为了“一封封清晰的救火说明书”。为了巩固成果,团队制定了后续的“红线”要求:
- 新增监控必带标签:任何新项目或新组件接入监控,必须在数据采集侧(Exporter或埋点)带上
env(环境)和projectA(项目)等核心业务标签。
- 持续时长必填:所有告警规则必须设置大于60秒的“持续时长”条件,宁可因观察期而慢报1分钟,也绝不因瞬时抖动而产生上百次误报干扰团队。
- 模板动态更新:随着后续农机平台、充电桩平台的深入监控,需要持续完善告警模板中的标签映射(TagsMap)提取逻辑,保持其适应性。
夜莺(Nightingale)项目开源地址: https://github.com/ccfos/nightingale
欢迎有类似整合需求或对统一监控中台实践感兴趣的开发者,在云栈社区的运维板块进一步交流探讨。
|  发表于 2026-3-28 02:16:31
|
查看: 152|
回复: 0
发表于 2026-3-28 02:16:31
|
查看: 152|
回复: 0
