01 业务痛点
1.1 多云日志统一分析
在混合云或出海业务中,一个常见的架构模式是:将海外边缘的安全与访问能力交由 Cloudflare 来承担(如 WAF/CDN/Access),其产生的详细日志通过 Logpush 统一落入 AWS S3,用作低成本归档和合规留存。与此同时,企业总部的核心业务与可观测体系可能已在阿里云上运行多年,例如应用的业务日志、网关日志都已进入阿里云 日志服务,告警与值班体系也围绕阿里云生态建设。
这就导致了一个核心矛盾:同一次用户请求、攻击行为或发布变更所产生的“证据链”,被割裂地存储在了 AWS 和阿里云两个平台上。当需要进行根因分析、安全事件调查或运营复盘时,你很难在一个统一的控制台里完成关联检索和闭环处置。
对于平台工程团队而言,真正的痛点不在于“日志存在哪里”,而是“分析和运营动作在哪里完成闭环”:
- 分析分散:日志躺在 S3 里,但排查故障、分析攻击或运营统计却需要在多套系统中来回切换,比如 Cloudflare 控制台、Athena/Glue/EMR、CloudWatch、独立的 BI 工具以及自建的告警系统。
- 口径难统一:同一个关键指标,比如源站 5xx 错误率、接口延迟 P99、WAF 拦截比例,在不同的系统里各有各的算法,变更难以审计,口径无法沉淀和复用,迁移成本高昂。
- 响应链路长:发现异常后,往往需要“先查日志 -> 再手工汇总 -> 然后发通知 -> 最后派单或执行回滚”,人为拉长了平均故障检测时间(MTTD)和平均故障恢复时间(MTTR)。

1.2 降本与简化运维
把 S3 作为海量日志的存储层,成本确实很低。但要把这些数据真正“用起来”——实现查询分析、可视化图表和告警联动,通常还需要额外搭建查询引擎、ETL流水线、指标与告警组件。整个链路变长,配置和故障排查需要跨越多个系统,运维的复杂度会指数级上升。
如果选择 AWS 原生的路径,比如将数据直接接入 CloudWatch:用 CloudWatch Logs 采集存储,用 Logs Insights 做查询,用 Dashboards 和 Alarms 做可视化和告警,虽然实现了闭环,但整体成本通常非常高昂。
02 SLS 解决方案
SLS 提供了一个替代方案,其核心思路是:将分布在 AWS S3 的归档日志,通过高效、可靠的方式实时导入 SLS,在 SLS 统一平台上完成数据的加工、分析、可视化与告警闭环,从而实现跨云环境的统一可观测性。
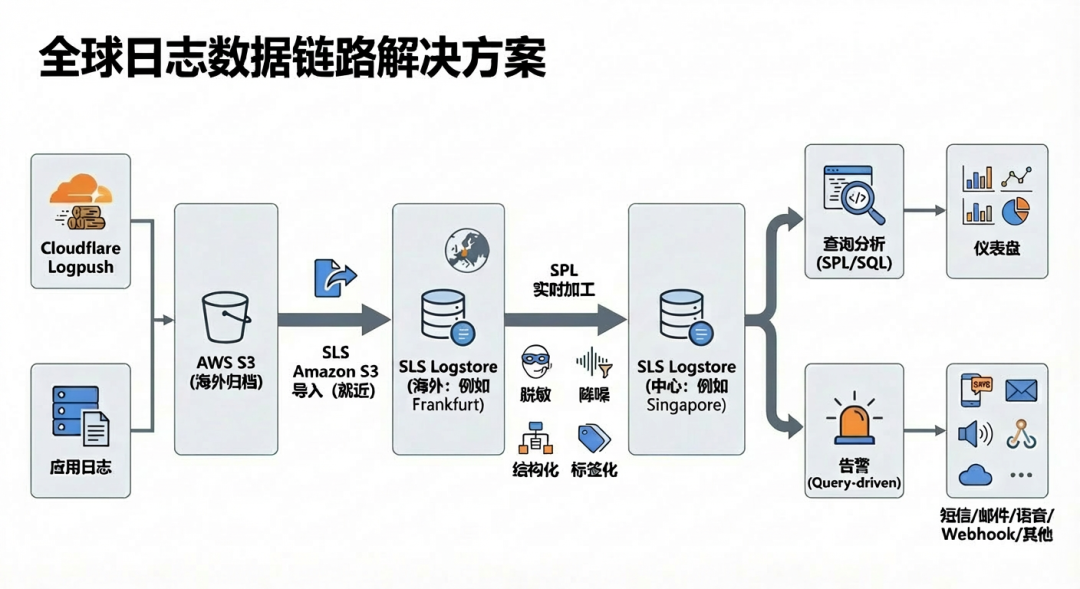
接下来,我们将详细拆解这套方案中的关键环节:数据导入、实时加工、查询分析、可视化仪表盘以及智能告警。
2.1 从 S3 将数据导入 SLS
在很多人的印象里,数据导入无非就是“读取-传输-写入”三板斧。但当你面对真实的业务场景时,会发现挑战远非如此简单:
- 每分钟产生上千个日志文件。
- 攻防演练或业务活动时,流量可能从日常的 1GB/分钟瞬间暴涨到 10GB/分钟。
- 数据格式五花八门,gzip、snappy 压缩与 JSON、CSV 等格式混杂。
这绝不是一个简单的“复制粘贴”任务。我们先梳理导入过程中的核心挑战,再介绍对应的解决思路。
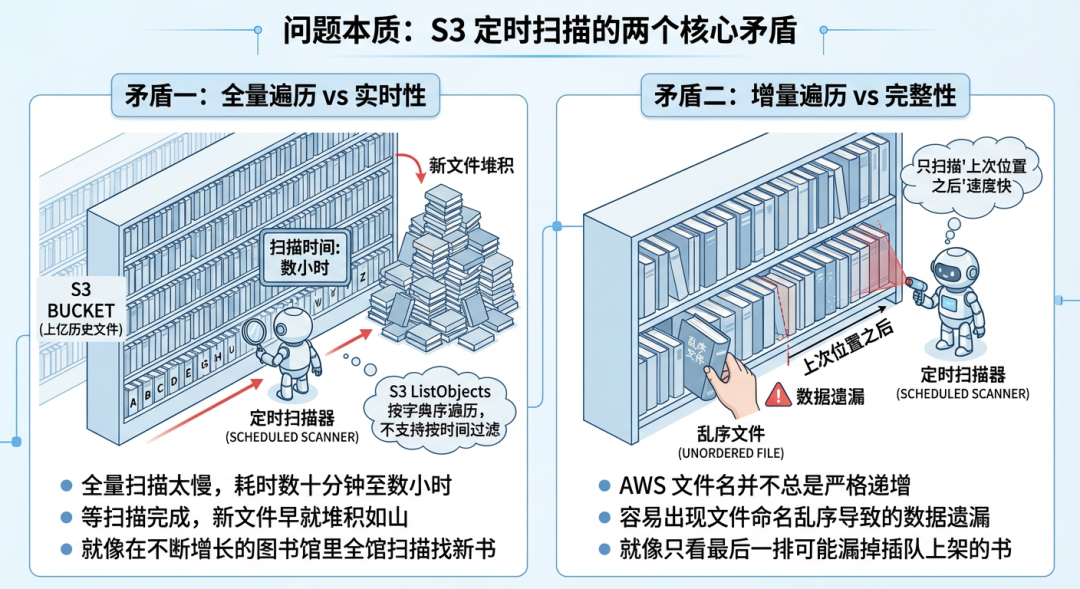
挑战一:海量小文件的“实时发现”难题
S3 的 ListObjects API 只支持按字典序(lexicographic order)全量遍历,不支持“按时间过滤”。当一个 Bucket 或目录下历史文件量巨大(如上亿)时,全量扫描一轮可能需要数小时。但若为了追求实时性只做增量扫描(即只扫描上次扫描点之后的新文件),又可能因为 AWS S3 文件命名并不严格按时间递增而出现乱序,导致遗漏部分文件。
后果:新文件发现不及时(数据延迟高),或者极端情况下数据永久丢失(完整性风险)。
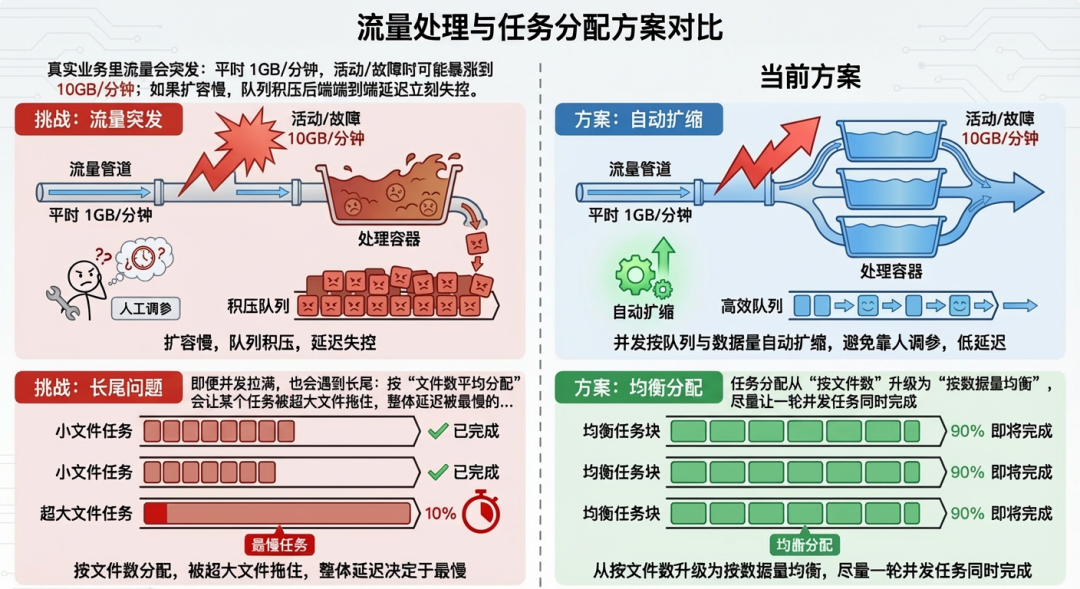
挑战二:吞吐要跟上流量峰值,且不能依赖“人工调参”
- 流量突发:真实业务流量并非平稳,平时 1GB/分钟,活动或故障时可能暴涨10倍。如果处理能力扩容慢,队列会迅速积压,端到端的处理延迟立刻失控。
- 长尾拖累:即便并发拉满,如果任务分配策略是简单地“按文件数平均分配”,一个超大文件就足以拖慢整个批次的任务完成速度,整体延迟由最慢的那个任务决定。
挑战三:数据格式是“混合大礼包”
同一个 Bucket 里可能混着 JSON 行、CSV、纯文本,甚至同样是 JSON,结构也可能是“逐行 JSON”、“JSON 数组”或是“CloudTrail 等特定服务格式”;压缩方式又可能是 .gz、.snappy、.lz4、.zstd 等。如果试图在传输链路中自动探测数据格式,会引入采样误判风险和额外的 I/O 开销,反而拖慢整体效率。
挑战四:正确性必须可交付、可追溯
导入链路天然存在各种异常:网络抖动、消费超时、任务重启、S3事件与扫描任务同时命中同一对象等,都可能导致数据被重复拉取。而比重复更隐蔽、更严重的是数据丢失:事件通知漏发、权限变更、扫描点位漂移、解析异常等都可能让某段时间的数据悄然出现缺口。
针对上述挑战的解决方案设计:
- 设计点一:文件发现“双机制”,兼顾实时与完整
- SQS 事件驱动:配置 S3 事件通知 → SQS → 导入任务实时消费。适合对延迟敏感、且文件名不规则的场景。
- 双模式遍历:增量扫描追赶最新点位 + 周期性全量扫描兜底。防止因事件丢失或乱序导致的数据遗漏。
| 对比维度 |
双模式遍历 |
SQS 事件驱动 |
| 新文件发现实时性 |
分钟级 |
秒级 |
| 配置复杂度 |
简单,无需额外配置 |
需配置 S3 事件通知和 SQS |
| 可靠性 |
高(全量兜底) |
依赖 SQS 可靠性 |
| 成本 |
仅 S3 API 调用费用 |
额外 SQS 费用 |
| 适用场景 |
标准日志导入 |
高实时性、文件名不规则 |
- 设计点二:弹性扩缩 + 按数据量均衡分配,扛峰值、治长尾
- 处理并发度根据待处理队列深度和预估数据量自动弹性扩缩,避免依赖人工经验调参。
- 任务分配从简单的“按文件数”升级为“按数据量均衡分配”,尽量让一轮并发任务能同时完成,避免被超大文件拖累。
2.2 一站式数据分析
数据导入只是第一步,完整的可观测性闭环还需要数据治理、交互式查询、可视化展示与智能告警。SLS 将这些能力整合在一个统一平台内,以下介绍各环节的核心。
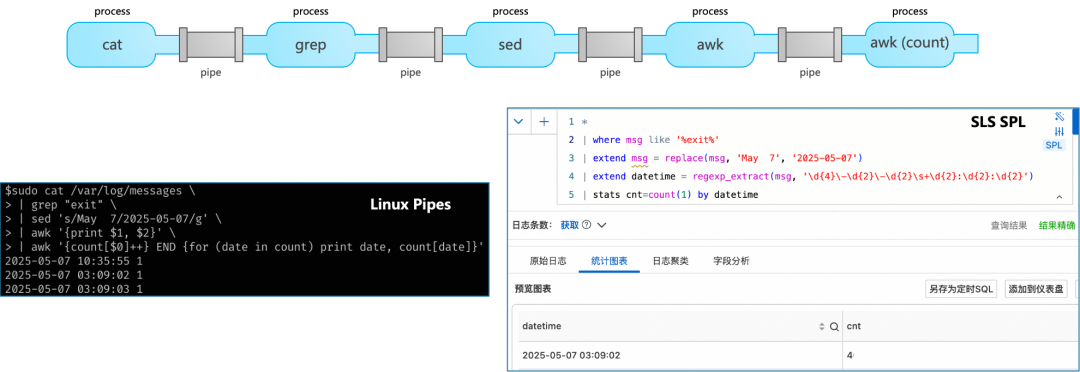
数据加工:全托管流式 ETL
SLS 数据加工基于托管的实时消费任务,使用功能强大的 SPL(SLS Processing Language)语法对日志进行流式处理。其优势在于全托管免运维、弹性伸缩、处理结果秒级可见,并且支持按行调试与代码智能提示。
SLS 的实时消费引擎以高性能 SPL 引擎为核心,采用列式计算、SIMD 加速等技术,并由 C++ 语言实现。基于此引擎,SLS 设计了更细粒度的弹性伸缩机制,不仅能按实例(如 K8s Pod)伸缩,更能按数据块(DataBlock,MB 级别)粒度快速弹性,以应对流量的剧烈波动。
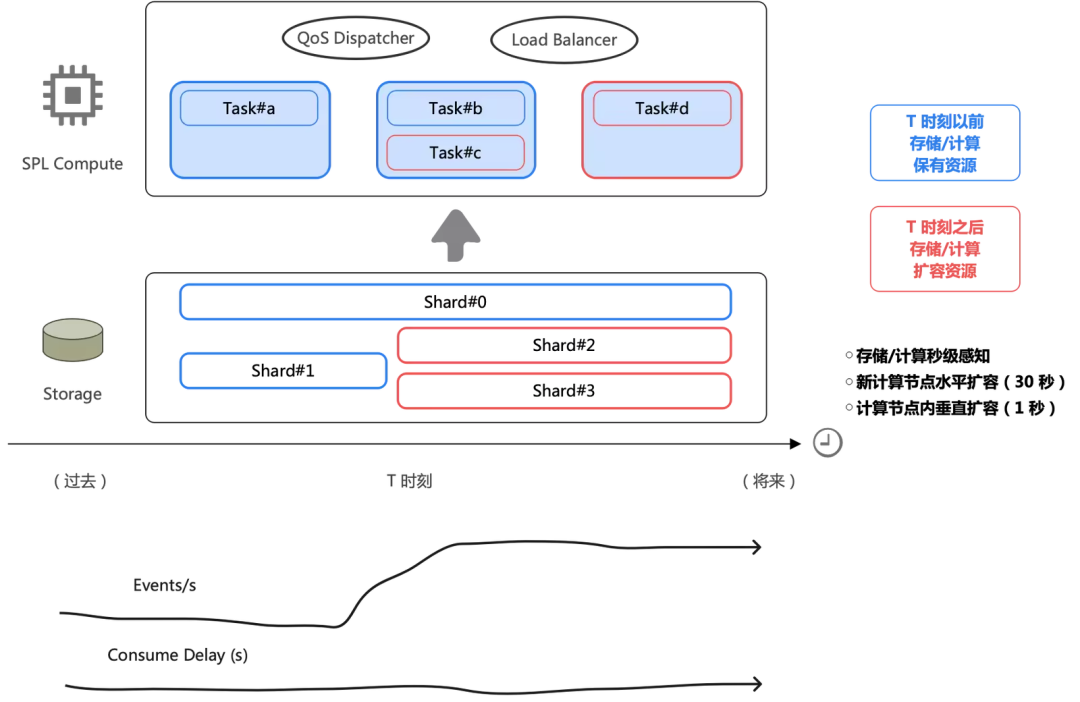
典型场景能力:
- 合规前置:在海外侧即可完成 IP 到地理信息的转换与敏感数据脱敏,跨境传输时只保留合规字段,轻松满足 GDPR 等数据出境监管要求。
- 数据过滤:实时剔除调试日志、心跳日志等无效数据,直接减少下游的索引与存储开销。
- 结构化抽取:从原始日志中解析、提取出业务指标,或展开复杂的嵌套 JSON,避免在查询时重复计算,提升分析效率。
- 字段投影:只投递真正需要分析的“黄金字段”到中心存储,可将跨境传输的流量成本与中心索引的存储成本降低 50%–80%。
- 字段富化:支持日志流与维表(如用户信息表)进行实时关联查询(JOIN),为日志动态添加更多维度信息,赋能深度数据分析。
- 数据流转:支持将日志数据灵活地转发、汇总到不同的目标 Logstore,也可按字段内容进行条件分发,构建复杂的数据流水线。
查询分析:高性能引擎,秒级响应
SLS 提供高性能的查询引擎,支持两种模式:索引模式(对百亿级数据实现秒级响应)和扫描模式(用于轻量级的即席分析)。查询直接作用于索引,无需预先建立数据集或忍受刷新延迟。针对超大规模数据分析场景,SLS 还提供 SQL 独享版,包含 SQL 增强(更高并发)和 SQL 完全精确(避免采样误差)两种模式,满足不同精度与性能要求。

核心能力:
- 近百种分析函数:内置统计、聚合、字符串、时间、地理空间等丰富函数,开箱即用。
- 跨库联合查询:通过 StoreView 功能,支持跨 Project、跨 Logstore 的数据关联查询,打破数据孤岛。
- SQL 独享版:为大数据量、高精度分析场景提供专属计算资源,确保结果完全精确,避免采样带来的误差。
- 定时 SQL:支持定时执行 SQL 查询,用于每日报表自动生成、关键指标预计算等场景,提升运营效率。
可视化:丰富图表,开箱即用
SLS 仪表盘是将查询分析结果进行图形化展示的强大工具。它通常由多个统计图表组成,能够直观地汇总和呈现关键性能指标、安全态势与业务数据分析结果。
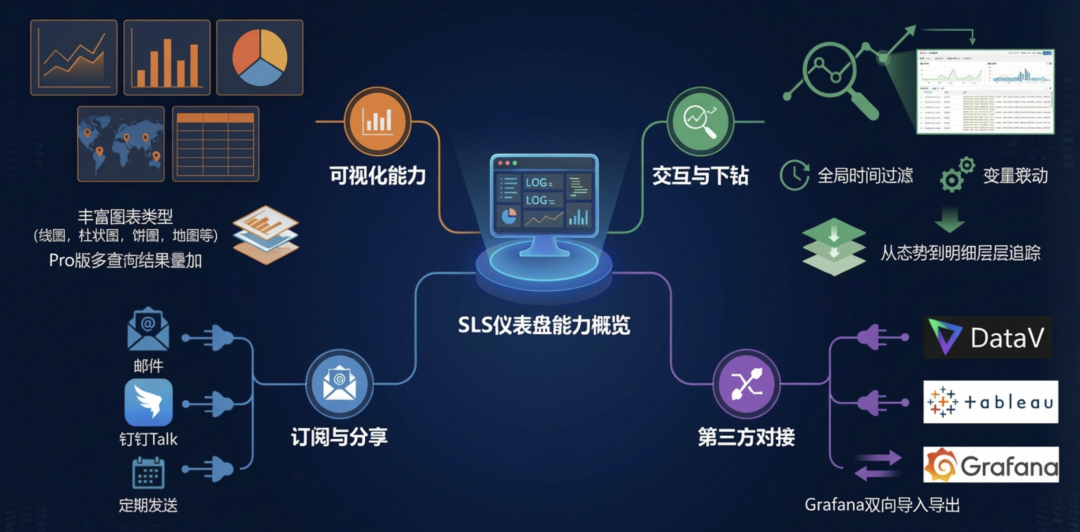
核心能力:
- 丰富图表类型:支持表格、折线图、柱状图、饼图、地理地图等多种统计图表,Pro 版本还支持多查询结果在同一图表中叠加展示。
- 交互与下钻:支持全局时间范围过滤、图表间变量联动、以及从汇总图表下钻到明细日志,实现从宏观态势到微观根因的层层追踪。
- 订阅与分享:支持将仪表盘定期渲染为图片,通过邮件或钉钉等工作群自动发送;也支持将仪表盘控制台内嵌到第三方业务系统中。
- 第三方对接:可与阿里云 DataV、开源 Grafana、Tableau 等主流可视化工具无缝对接,并支持与 Grafana 仪表盘的双向导入导出。
告警:一站式智能运维平台
SLS 告警是一个集告警监控、降噪、事务管理、通知分派于一体的智能运维平台。在接入日志或指标数据后,几分钟内即可完成监控规则、通知渠道和告警策略的配置。
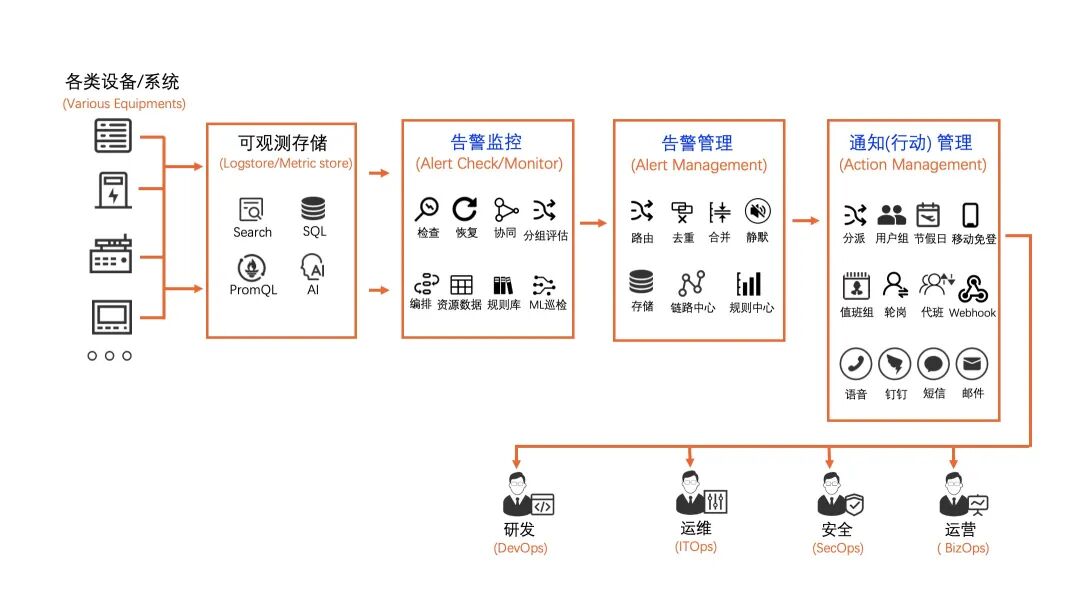
功能优势:
- 低成本免运维:以 SaaS 形态提供,除短信/语音等运营商通道外,告警监控、事务管理等核心功能不额外收费。
- 智能降噪与分派:内置分组、去重、抑制、升级等降噪策略,有效避免告警风暴;支持按规则将告警自动分派给不同的值班团队或人员。
- 通知渠道丰富:原生集成钉钉、企业微信、飞书、Slack、短信、语音电话、Webhook 等多种通知方式。
2.3 运维简化:一体化替代多产品组合
2.3.1 AWS 多产品组合方案
为了在 AWS 上实现从 S3 日志到分析告警的完整闭环,通常需要组合多个服务,其典型架构可能如下所示。
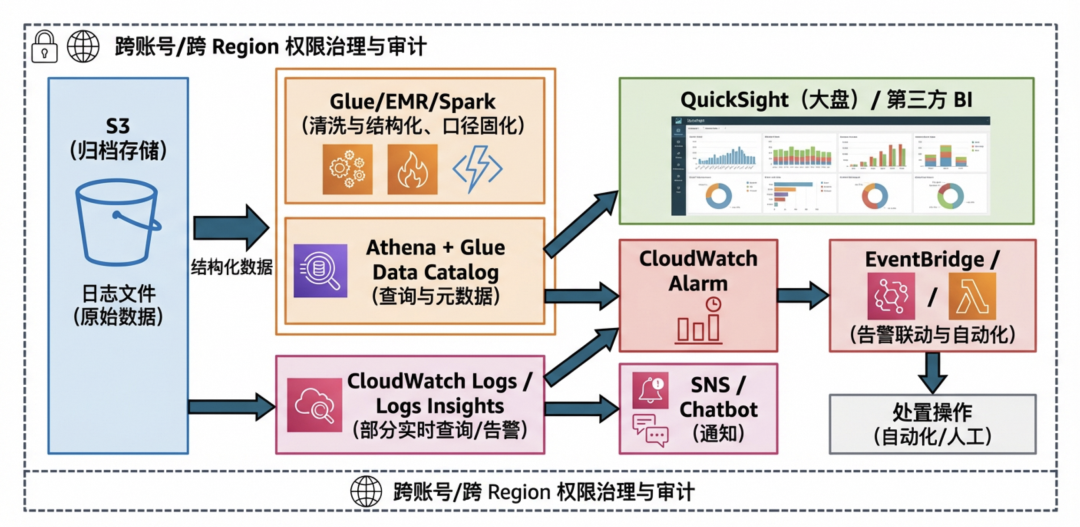
组件多并不一定代表不好,但当你的核心诉求是“统一口径、分钟级闭环、成本可控”时,多组件架构意味着:
- 链路更长:数据需要在不同服务间搬移多次(ETL、落中间表、刷新数据集)。
- 故障面更大:任一环节(如 Glue Job、Athena 查询)出现抖动或失败,都会影响端到端的数据时效性。
- 计费更琐碎:存储(S3)、扫描查询(Athena)、计算(Glue/EMR)、告警(CloudWatch Alarms)、可视化(QuickSight)以及网络传输费用各自计费,成本构成复杂,难以整体优化。
2.3.2 SLS 一体化方案对比
SLS 的方案是将“导入 + 加工 + 存储索引 + 查询分析 + 仪表盘 + 告警/事务”等能力,整合为一个内聚的、可复用的工程模板。用户可以用模板快速交付第一版可观测体系,后续再通过统一的策略界面,持续迭代成本与效果。
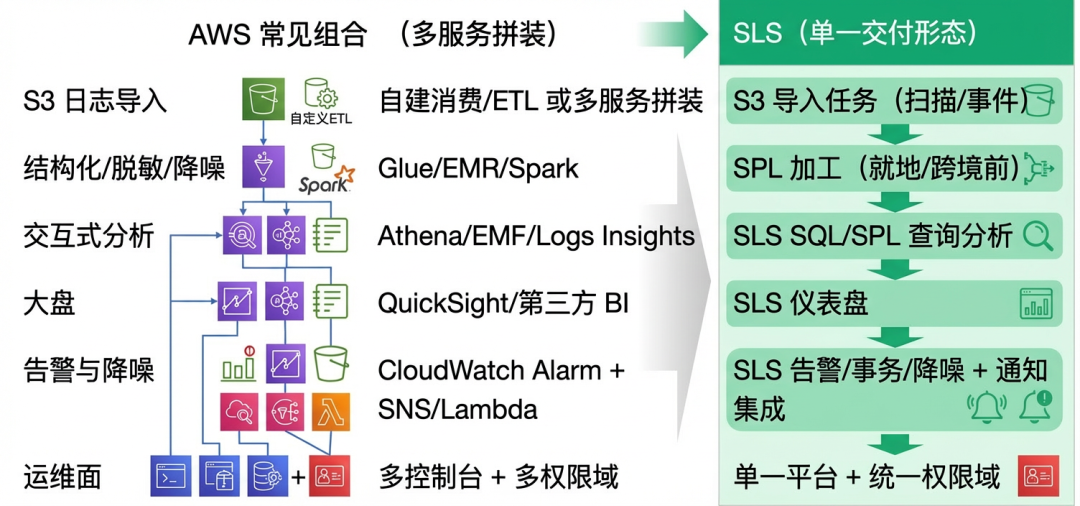
03 出海企业日志分析架构升级案例
背景与解决方案
某大型全球化出海企业,业务覆盖欧洲、亚太、北美等多个区域,使用主流 CDN 与 WAF 服务实现全球加速及 Web 应用防护。为满足海外数据合规与审计要求,企业将安全与访问日志通过服务商提供的 Logpush 功能,持续归档至公有云对象存储(AWS S3)中,用于长期留存。
此前,该企业在 AWS 上采用多组件组合方案来实现海外日志的分析与监控,遇到了典型问题:
- 数据分散:S3 存储桶分布在法兰克福、东京等多个 Region,形成数据孤岛,难以统一管理与分析。
- 查询分析成本高:使用 Athena 按扫描量计费,日常检索与告警查询成本随频次线性增长;CloudWatch Logs Insights 查询能力有限且跨 Region 需分别操作。
- 运维复杂:ETL 依赖 Glue/Lambda 需自行维护;QuickSight 可视化需额外授权且存在数据同步延迟;CloudWatch Alarms 配置分散,缺乏统一的告警降噪能力。
基于阿里云 SLS,该企业构建了统一的可观测分析平台,实现了:
- 统一数据加工:通过 SPL 在海外侧就近完成数据治理(字段裁剪、IP 脱敏、Geo 富化),显著降低跨境传输成本。
- 统一查询分析:在国内中心 Logstore 汇聚处理后的“黄金数据”,提供亿级数据秒级交互式查询体验。
- 统一可视化:一站式仪表盘满足所有可视化需求,无需额外采购和维护 BI 工具。
- 统一告警闭环:基于 SLS 查询分析能力的智能告警,支持降噪、分派与全渠道通知,告警处置效率大幅提升。
3.1 数据链路
数据从 Cloudflare 通过 Logpush 推送到 AWS S3 的海外各 Region(如法兰克福、东京)进行归档。SLS 通过事件驱动或定时扫描的方式,将同地域 S3 的数据导入到对应的 SLS 海外 Region Logstore 中。随后,通过 SPL 加工任务进行实时处理,并将处理后的核心数据汇聚至国内的中心 Region(如新加坡)Logstore,最终支撑统一的查询分析、仪表盘与告警。
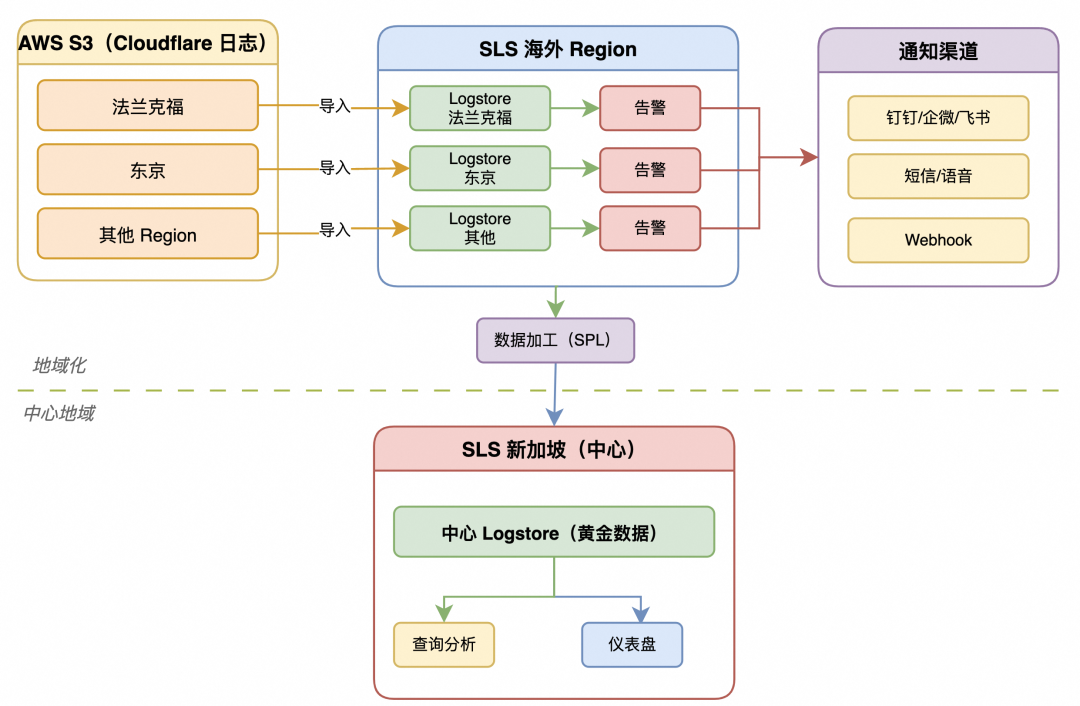
3.1.1 SPL 数据加工示例
假设我们从 S3 导入的是 Cloudflare WAF 原始日志,其结构示例如下:
{
"EdgeStartTimestamp": "2024-12-25T10:30:00Z",
"RayID": "abc123def456",
"ClientIP": "203.0.113.50",
"OriginIP": "10.0.0.100",
"ClientRequestURI": "/api/v1/users?id=123",
"ClientRequestMethod": "POST",
"ClientRequestReferer": null,
"SecurityAction": "block",
"SecurityRuleID": "rule_001",
"SecuritySources": "[{\"source\":\"waf\",\"action\":\"block\"}]",
"OriginResponseStatus": 200,
"OriginResponseTime": 150,
"ResponseHeaders": "{\"x-cache\":\"MISS\"}"
}
我们可以在海外侧的 SLS Logstore 中配置如下 SPL 加工脚本,完成数据治理后再传输到中心,既满足合规又提升效率:
-- 核心追踪与时间标准化
* | extend __time__ = cast(to_unixtime(date_parse(EdgeStartTimestamp, '%Y-%m-%dT%H:%i:%SZ')) as bigint)
| extend RequestId = RayID
| extend RequestPath = url_extract_path(ClientRequestURI)
-- IP -> Geo(在海外侧完成,避免跨境传输原始IP)
| extend
GeoCountry = ip_to_country(ClientIP),
GeoRegion = ip_to_province(ClientIP),
GeoCity = ip_to_city(ClientIP)
-- IP 脱敏:生成匿名指纹(可选),不跨境携带原始 IP
| extend ClientFingerprint = to_base64(sha256(to_utf8(ClientIP)))
-- 安全元数据解析与标签化
| expand-values -keep SecuritySources
| parse-json -prefix='Security' SecuritySources
| extend IsHighRisk = if(ClientRequestMethod = 'POST' and (ClientRequestReferer is null or SecurityAction = 'block'), 1, 0)
-- 最终降噪与字段投影:移除敏感和冗余字段
| project-away ClientIP, OriginIP, ResponseHeaders, RayID
加工后的数据示例如下,已包含地理信息、风险标签,并移除了敏感字段:
{
"RequestPath": "/api/v1/users",
"__time__": "1735122600",
"RequestId": "abc123def456",
"ClientFingerprint": "O1zTaFfLyH1ZqEHS03UiLSNMzwMX+4ZW7OsIVsDGgEg=",
"OriginResponseTime": "150",
"GeoCity": "理查森",
"ClientRequestURI": "/api/v1/users?id=123",
"IsHighRisk": "1",
"EdgeStartTimestamp": "2024-12-25T10:30:00Z",
"SecurityAction": "block",
"SecurityRuleID": "rule_001",
"Securityaction": "block",
"GeoCountry": "美国",
"GeoRegion": "德克萨斯州",
"OriginResponseStatus": "200",
"Securitysource": "waf",
"ClientRequestMethod": "POST"
}
3.1.2 查询分析示例
基于加工后的“黄金数据”,我们可以轻松进行各种分析。
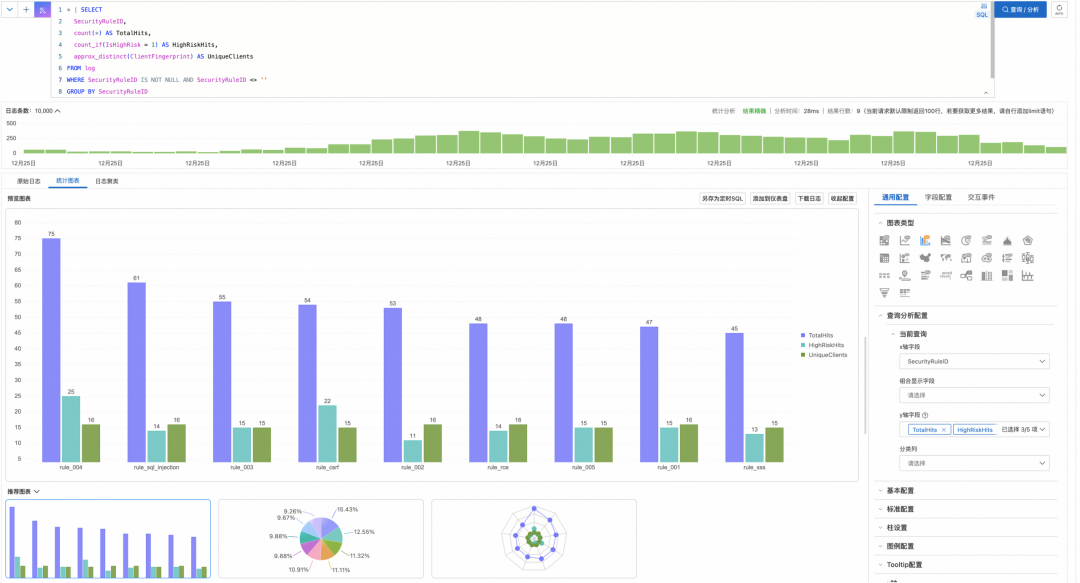
示例 1:WAF 规则命中统计
分析各安全规则的拦截效果、高风险请求占比及独立攻击者数量。
* | SELECT
SecurityRuleID,
count(*) AS TotalHits,
count_if(IsHighRisk = 1) AS HighRiskHits,
approx_distinct(ClientFingerprint) AS UniqueClients
FROM log
WHERE SecurityRuleID IS NOT NULL AND SecurityRuleID <> ''
GROUP BY SecurityRuleID
ORDER BY TotalHits DESC
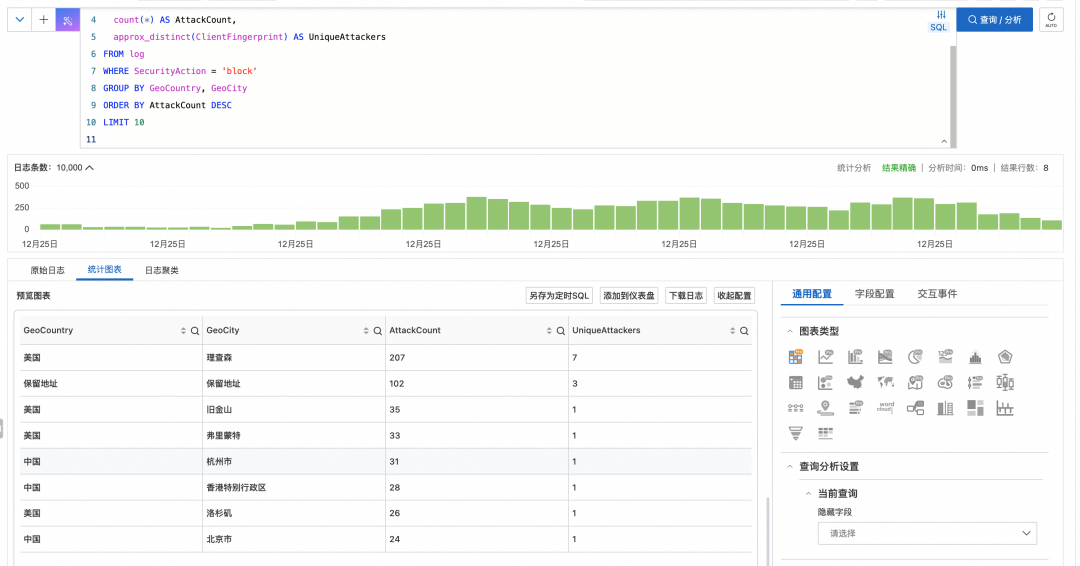
示例 2:攻击源地域 Top 10
快速定位攻击主要来源的国家和城市。
* | SELECT
GeoCountry,
GeoCity,
count(*) AS AttackCount,
approx_distinct(ClientFingerprint) AS UniqueAttackers
FROM log
WHERE SecurityAction = 'block'
GROUP BY GeoCountry, GeoCity
ORDER BY AttackCount DESC
LIMIT 10
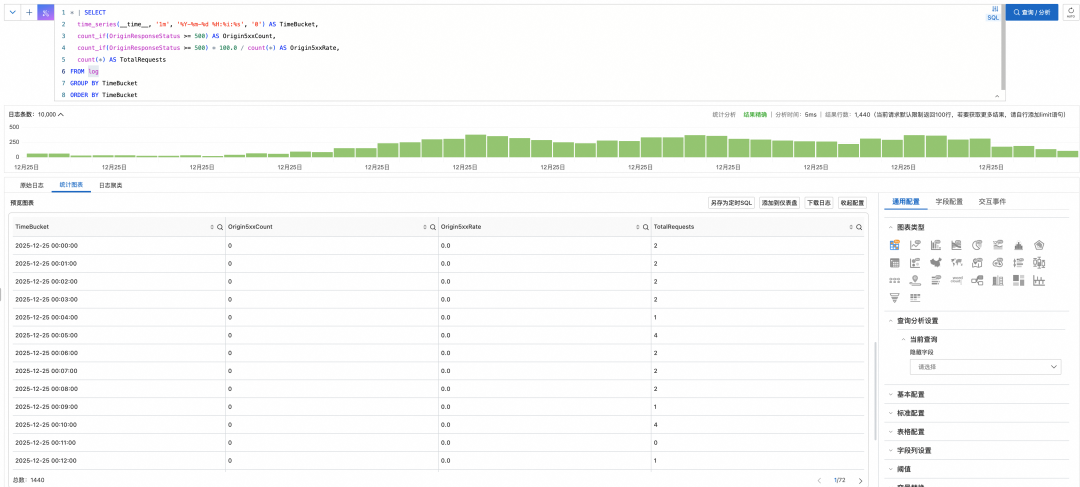
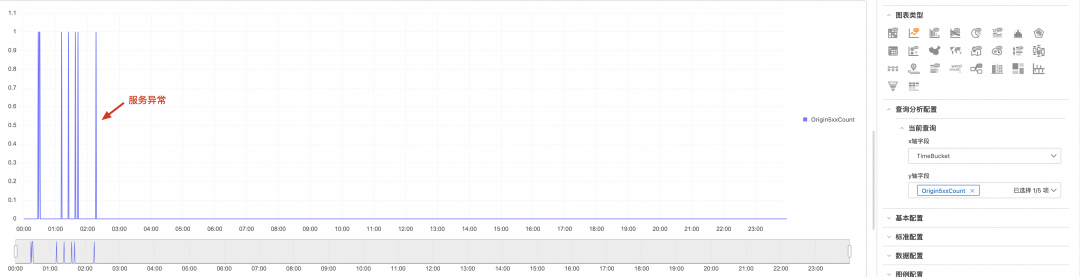
示例 3:源站 5xx 错误率趋势
监控源站健康状态,及时发现后端服务异常。
* | SELECT
time_series(__time__, '1m', '%Y-%m-%d %H:%i:%s', '0') AS TimeBucket,
count_if(OriginResponseStatus >= 500) AS Origin5xxCount,
count_if(OriginResponseStatus >= 500) * 100.0 / count(*) AS Origin5xxRate,
count(*) AS TotalRequests
FROM log
GROUP BY TimeBucket
ORDER BY TimeBucket
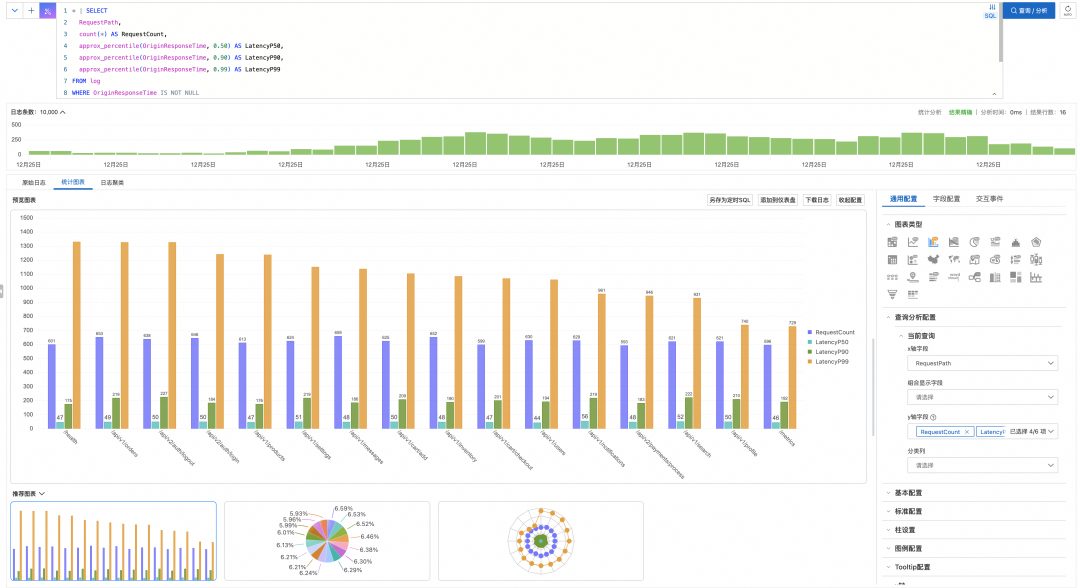
示例 4:API 接口延迟分析
识别慢接口,进行性能优化。
* | SELECT
RequestPath,
count(*) AS RequestCount,
approx_percentile(OriginResponseTime, 0.50) AS LatencyP50,
approx_percentile(OriginResponseTime, 0.90) AS LatencyP90,
approx_percentile(OriginResponseTime, 0.99) AS LatencyP99
FROM log
WHERE OriginResponseTime IS NOT NULL
GROUP BY RequestPath
HAVING count(*) > 100
ORDER BY LatencyP99 DESC
LIMIT 20
3.1.3 告警规则示例
基于上述查询,可以快速配置智能告警。
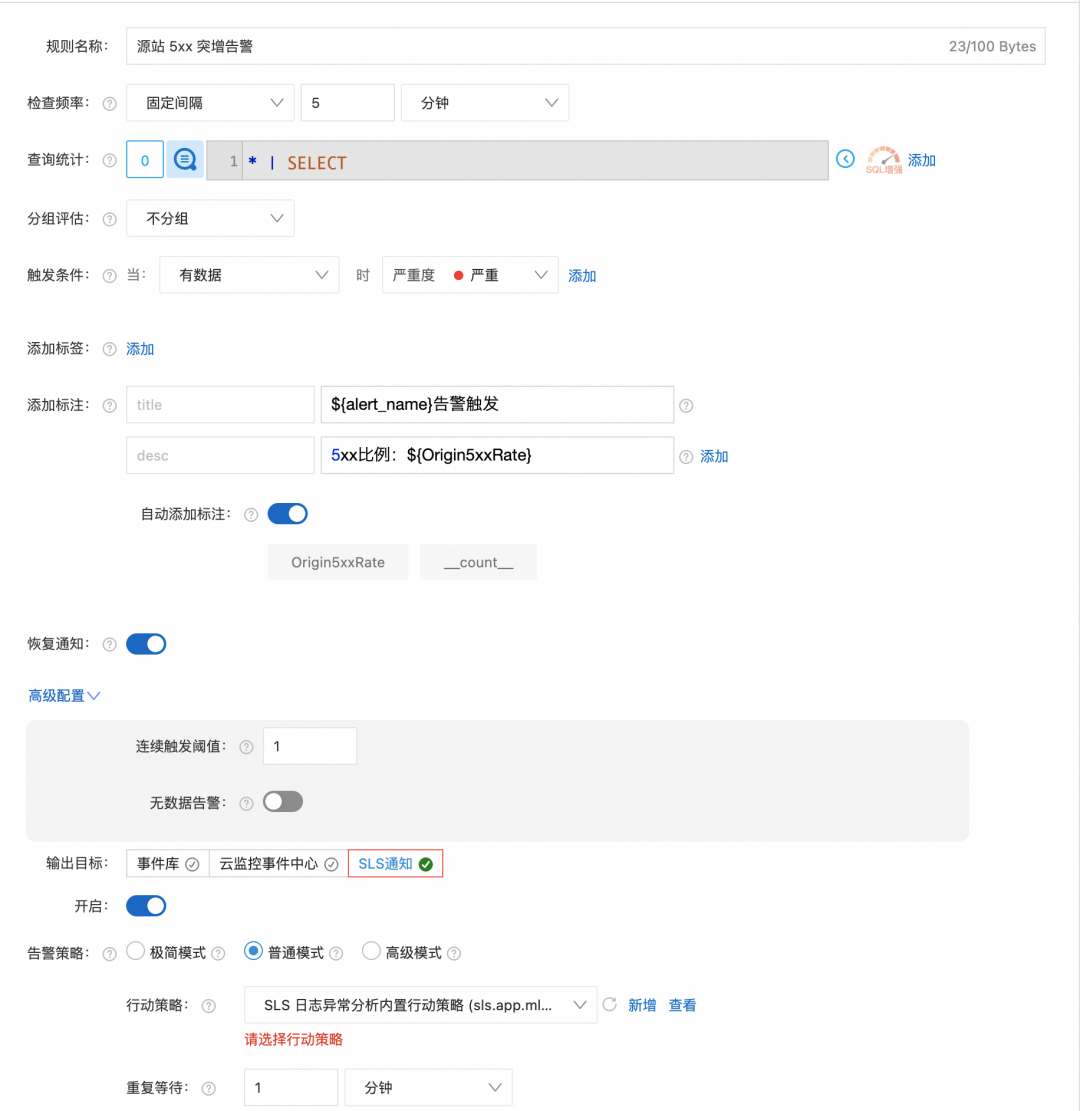
告警 1:源站 5xx 错误率突增
当最近5分钟内源站5xx错误率超过5%时触发,快速发现后端服务异常。
* | SELECT
count_if(OriginResponseStatus >= 500) * 100.0 / count(*) AS Origin5xxRate
FROM log
HAVING Origin5xxRate > 5
告警 2:高风险请求突增
当高风险请求次数超过100或占比超过10%时触发,识别潜在攻击行为。
* | SELECT
count_if(IsHighRisk = 1) AS HighRiskCount,
count_if(IsHighRisk = 1) * 100.0 / count(*) AS HighRiskRate
FROM log
HAVING HighRiskCount > 100 OR HighRiskRate > 10
告警 3:WAF 拦截量突增
当WAF拦截次数超过1000或独立攻击者超过50时触发,感知大规模攻击态势。
* | SELECT
count_if(SecurityAction = 'block') AS BlockCount,
approx_distinct(ClientFingerprint) AS UniqueAttackers
FROM log
HAVING BlockCount > 1000 OR UniqueAttackers > 50
3.2 成本对比分析
我们以一个具体的业务场景为例,进行端到端的 TCO(总拥有成本)对比。对比遵循“能力对齐”原则,覆盖 SLS 方案中提供的完整闭环能力:数据传输(从 S3 导入)、数据加工(SPL)、存储与索引、查询分析、告警、可视化(约100个仪表盘)。为避免片面比较,AWS 侧选择功能最接近的 CloudWatch 一体化方案作为对标(CloudWatch Logs + Logs Insights + Dashboards + Alarms)。
3.2.1 场景与参数设定
- 原始日志量:20 TB/天(写入 SLS 的数据量)。
- 公网拉取流量:从 S3 拉取的是压缩后的日志对象,按典型压缩比 10:1 估算,约为 2 TB/天 (2,048 GB/天)。
- 查询负载:20,000 次查询/天,峰值约 24 QPS;日均扫描数据量约 100 TB。
- 告警负载:20 条告警规则,每 3 分钟执行一次(9,600 次/天),使用 Webhook 通知。
- 可视化:约 100 个动态仪表盘(Dashboard)。
- 数据加工:对所有数据进行过滤、清洗、分发等实时处理。
- 数据存储时间:14 天(热存储)。
3.2.2 单价来源说明
3.2.3 分项费用估算(月度)
1) 数据传输 / 日志摄入
- SLS(写入费用)
20 TB/天 = 20,480 GB/天
月费用 = 20,480 GB/天 × 0.061 USD/GB × 30 天/月
= 37,478.40 USD/月
- AWS CloudWatch(日志摄入费用)
月费用 = 20,480 GB/天 × 0.50 USD/GB × 30 天/月
= 307,200.00 USD/月
- 公网流量费用(计入 SLS 方案 TCO)
公网出站量 = 20,480 GB/天 ÷ 10 (压缩比) = 2,048 GB/天
月度总量 = 2,048 GB/天 × 30 天 = 61,440 GB
(按 AWS 分段计价示例,前 100 GB 免费)
计费量 = 61,440 - 100 = 61,340 GB
估算月费用 ≈ 5,113.00 USD/月
2) 数据加工
- SLS:按写入量计费模式下,数据加工不额外收费。
- AWS:同等能力通常需依赖 Glue/EMR/Lambda,会产生额外计算费用,此处暂不计入以作保守对比。
3) 存储(14天)
- SLS:按写入量计费模式下,提供30天免费存储。存储14天,费用为 0 USD/月。
- AWS CloudWatch Logs
稳态存储量 = 20,480 GB/天 × 14 天 = 286,720 GB
月费用 = 286,720 GB × 0.03 USD/(GB×month)
= 8,601.60 USD/月
4) 查询分析
5) 告警
6) 仪表盘可视化
3.2.4 月度费用汇总
SLS 月度总费用 ≈ 37,478.40 (写入) + 5,113.00 (公网出站) = 42,591.40 USD/月
AWS CloudWatch 月度总费用 = 307,200.00 (摄入)
+ 8,601.60 (存储)
+ 15,360.00 (查询扫描)
+ 2.00 (告警)
+ 300.00 (仪表盘)
= 331,463.60 USD/月
3.2.5 结论
在本案例设定的参数和对比口径下:
月度节省金额 = 331,463.60 - 42,591.40 = 288,872.20 USD/月
成本降低比例 = 1 - (SLS / AWS) = 1 - (42,591.40 / 331,463.60) ≈ 87.15%
核心发现:
- 显著降本:SLS 一体化方案相比 AWS CloudWatch 组合方案,端到端 TCO 降低约 87.15%。
- 隐性价值:SLS 按写入量计费模式包含了30天免费存储(本案仅用14天,相当于额外获得16天免费存储)、免费的数据加工/投递能力、免费的告警功能以及不限数量的仪表盘。而在 AWS 侧,这些均为独立计费项。
- 简化运维:一体化平台极大降低了多服务拼装带来的集成、配置和维护复杂度。
04 总结与展望
本文深入探讨了在混合云及出海场景下,如何利用阿里云 SLS 有效整合 AWS S3 中的日志数据,构建统一、高效、低成本的可观测性体系。通过“统一采集、统一加工、统一分析、统一告警”的一体化方案,企业不仅能打破数据孤岛、提升运维效率,更能实现可观的成本优化。
在实践过程中,跨云、跨境的数据传输网络质量与费用是需要重点考虑的环节。为此,SLS 提供了通过 CloudFront 等加速网络来优化传输体验和成本的选择。同时,SLS 的集成能力也在不断扩展,现已支持从 GCP Cloud Storage、Azure Blob Storage 等主流云存储导入数据,旨在为企业构建真正的 多云统一可观测性 平台提供坚实支撑。
希望这篇来自 云栈社区 的深度实践分享,能为面临类似挑战的架构师和开发者提供有价值的参考。
 发表于 2026-3-28 02:13:58
|
查看: 107|
回复: 0
发表于 2026-3-28 02:13:58
|
查看: 107|
回复: 0
