
进入2026年4月,国内AI服务市场接连传来涨价消息,一股成本压力正在产业链中弥漫。
4月12日,智谱的Coding Plan(海外版)月付价格几乎翻倍。紧接着第二天,阿里云宣布取消百炼平台基础套餐的续费入口。而早在4月9日,腾讯云已先行一步,将其AI算力服务价格全线上调了5%。
这并非孤立事件,它标志着整个AI产业正经历一次深刻的范式转移:从早期“跑马圈地”的流量竞争,迅速滑向以算力通货紧缩为特征的重资产运营阶段。过去,各大模型厂商为了争夺用户,不惜大打价格战。如今,随着用户调用量的激增,一个清晰的现实摆在面前——按Token计费的模式终于被验证能够跑通盈利闭环,厂商们开始着手收回前期的巨额投入成本。
在汹涌增长的Token需求面前,上游算力供应持续吃紧,涨价压力沿着“芯片-云厂商-模型厂商-应用厂商”的链条层层传导。最终,为这轮成本上涨买单的,往往是广大中小开发者和普通用户。
智能体普及撞开了算力需求的闸门
是什么在短时间内引爆了对算力如此巨大的需求?数据给出了直观答案:我国日均Token调用量在今年三月已突破140万亿。这个数字相比2024年初的1000亿增长了超过1000倍,即便是与2025年底的100万亿相比,在短短三个月内也实现了40%的增长。
最近这波猛涨,主要推力来自于以OpenClaw为代表的AI智能体的广泛普及。这些能够自动执行复杂任务的智能体,每一次运行都意味着海量Token的消耗。许多用户体验后直呼“用不起”,正是因为其背后惊人的算力开销,让个人用户难以承受,最终只能卸载了事。
Token消耗的猛增直接转化为对底层算力硬件,尤其是AI芯片的疯狂抢购。行业分析机构SemiAnalysis的数据显示,英伟达H100 GPU的一年期租赁合同价格已从2025年10月的1.70美元/小时/GPU,飙升至2026年3月的2.35美元,涨幅接近40%。
抢手的不只是GPU。作为AI服务器调度与推理核心的CPU同样供不应求。2026年3月下旬,英特尔与AMD相继通知客户上调服务器处理器价格,两家巨头今年的相关产能已基本售罄。
成本压力向下游传导,应用厂商毛利率堪忧
“芯片-云厂商-模型厂商-应用厂商-企业客户”,这条清晰的产业链,如今也成了成本压力的传导链。处于中游的AI应用厂商处境尤为尴尬。
以全球最大的独立AI代码生成平台Cursor为例,其在2026年2月实现了年化收入突破20亿美元的亮眼成绩。然而风光背后,是2025年至少1.5亿美元的亏损。其收入的绝大部分都被用于向Anthropic和OpenAI等上游模型厂商支付API调用费用,导致毛利率被压缩至令人窒息的水平。
传统SaaS软件公司的毛利率中位数可高达77%,而当前主流AI应用的平均毛利率仅为25%至60%。AI虽然在功能上卷死了传统软件,但在盈利模型上却面临着巨大挑战。
因此,模型厂商涨价成为必然选择,目的是将成本继续向下游转移,收回此前价格战给出的“福利”。这股涨价风并非国内独有。2026年4月初,估值数百亿美元的AI巨头Anthropic突然宣布,切断订阅用户通过OpenClaw等第三方工具接入其Claude API的许可。
官方的解释直白而赤裸:部分重度用户每月仅支付20美元订阅费,却消耗了价值高达5000美元的算力资源。Anthropic表示,一个OpenClaw代理运行一天,背后的算力成本可能在1000至5000美元之间。如果不引导用户转向按用量付费的API模式,即便是巨头也难以为继。
Token浪费触目惊心,指数级消耗成普遍问题
面对涨价,用户在感到肉疼的同时,也不禁产生疑问:完成同样的任务,Token消耗真的需要这么多吗?
今年3月,一位名叫shelvenzhou的开发者就在GitHub上记录了自己使用OpenClaw处理日常工作时的Token消耗轨迹。测试结果令人震惊:
- 第一轮对话成本:0.0050美元(看起来很划算)
- 第五轮对话成本:0.0665美元(开始不对劲)
- 第十轮对话成本:0.13美元(成本爆炸式增长)
第十轮对话的成本已是第一轮的26倍。这种指数级的增长模式,揭示了当前智能体架构下一个普遍存在却常被忽视的问题:Token浪费。
其根本原因在于“上下文的无序膨胀”。随着智能体与用户的对话轮次增加,历史文件、过往记录不断累积。为了让智能体准确理解当前任务并找到相关信息,系统往往采取“宁可错杀,不可放过”的策略,在每次交互时都可能重新读取全部历史上下文。用户每输入一次,智能体就可能需要重新计算完整的对话记录和文件数据,从而导致成本呈指数级攀升。
这不是个案。《财经》杂志统计,今年一季度,GitHub上关于“Token Waste”(令牌浪费)议题的讨论和问题数量激增至超过4000个,相比上一季度增长了近五倍。
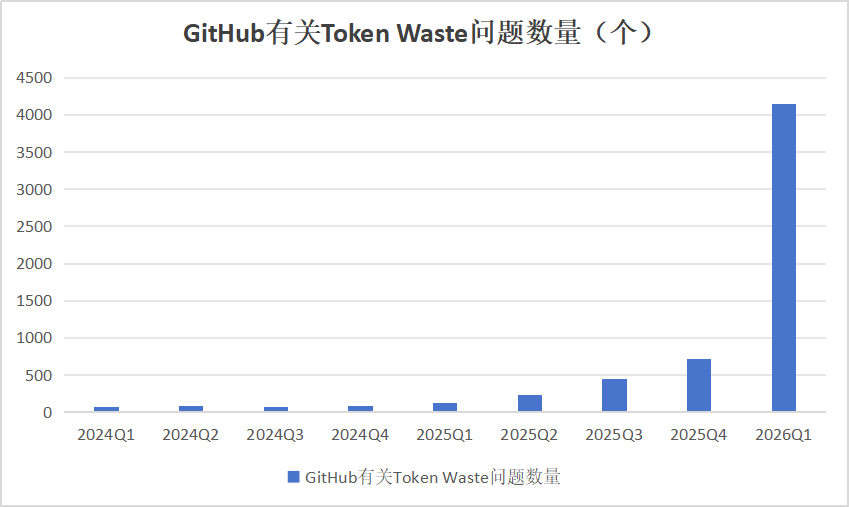
数据来源:《财经》
出路何在:让智能体跑得更“经济”
想要降低使用成本,让AI技术真正普惠,路径无非两条:增加供给,或优化需求。
增加供给意味着生产更多、更便宜的AI芯片。然而,目前国产AI芯片产能仍面临制约。即便在国内,华为昇腾服务器系列也在3月底传出涨价消息,其中910C(A3)1TB内存版本单台价格上涨约16万至32万元。这条路的见效周期显然较长。
因此,更现实且紧迫的路径是优化需求,即让智能体变得更“聪明”,减少无谓的Token消耗。
目前业界已有一些成熟或探索中的技术方向:
- 优化缓存机制:采用“KV Cache”(键值缓存)等技术,对已计算过的上下文结果进行缓存,避免重复计算,这是目前比较成熟的做法。
- 模型分层与分工:将复杂的规划、推理任务交给强大的旗舰模型(如GPT-5.4),而将简单、高频的执行任务(如代码库检索、文件审阅)交给更轻量、廉价的子模型(如GPT-5.4 Mini)。OpenAI的Codex升级已经体现了这种分层逻辑,让Token“用在刀刃上”。
- 引入“Harness”(约束)理念:最近在AI圈流行的“Harness”概念,原意是马具,引申为对智能体进行约束和引导。这涉及到如何为模型分配合适的工具、如何设计高效的上下文工程、如何管理长时记忆、如何规划最优工作流等一系列工程优化问题。
当前的智能体仍处于“能跑”的起步阶段,就像一匹充满活力但方向不定的小马驹,虽然最终能到达目的地,但过程中会浪费大量体力(算力)。未来的进化方向是让它“越跑越稳”、“越跑越经济”。
在AI智能体从热潮走向成熟的“Harness”时代,谁能用更少的Token完成同样的任务,谁就将在激烈的产业洗牌中占据优势。对于广大开发者和技术爱好者而言,关注并参与到云栈社区等平台的技术讨论中,分享和探索成本优化方案,或许是应对当前算力紧缩时代的一个务实选择。
Token经济的正向循环不会自动形成。要想让智能体技术不再成为少数人的游戏,持续的技术优化与合理的成本控制至关重要。否则,2026年这场被寄予厚望的智能体普及浪潮,或许会在算力不足的现实中,提前挤出普通的参与者和创新者。
 发表于 2026-4-21 18:39:49
|
查看: 228|
回复: 0
发表于 2026-4-21 18:39:49
|
查看: 228|
回复: 0
