

一款“反直觉”的产品,往往最能折射一个产业的真实需求。
近日,北大系 AI Coding 创企硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型:aiX-apply-4B。
模型团队公开的基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%。这一成绩不仅大幅超越了同级基座模型 Qwen3-4B(准确率 62.6%),甚至比肩参数量达千亿级别的通用大模型 DeepSeek-V3.2(准确率 92.5%)。
此外,在同一代码变更应用任务场景下的对比测试中,aiX-apply-4B 的推理速度高出 DeepSeek-V3.2 达 15 倍,而算力成本仅为后者的 5%,单张消费级显卡即可高效运行。

“小而专”带来的极致性能
据了解,为了保障模型在实际企业环境中的应用效果,硅心科技团队结合真实场景下的代码提交记录构建了 aiX-apply-4B 的训练数据集。他们基于高性能强化学习框架开展训练,将训练与评测进行一体化闭环设计,同时采用了严格的工程化约束,纳入了对各种边界情况的考量。
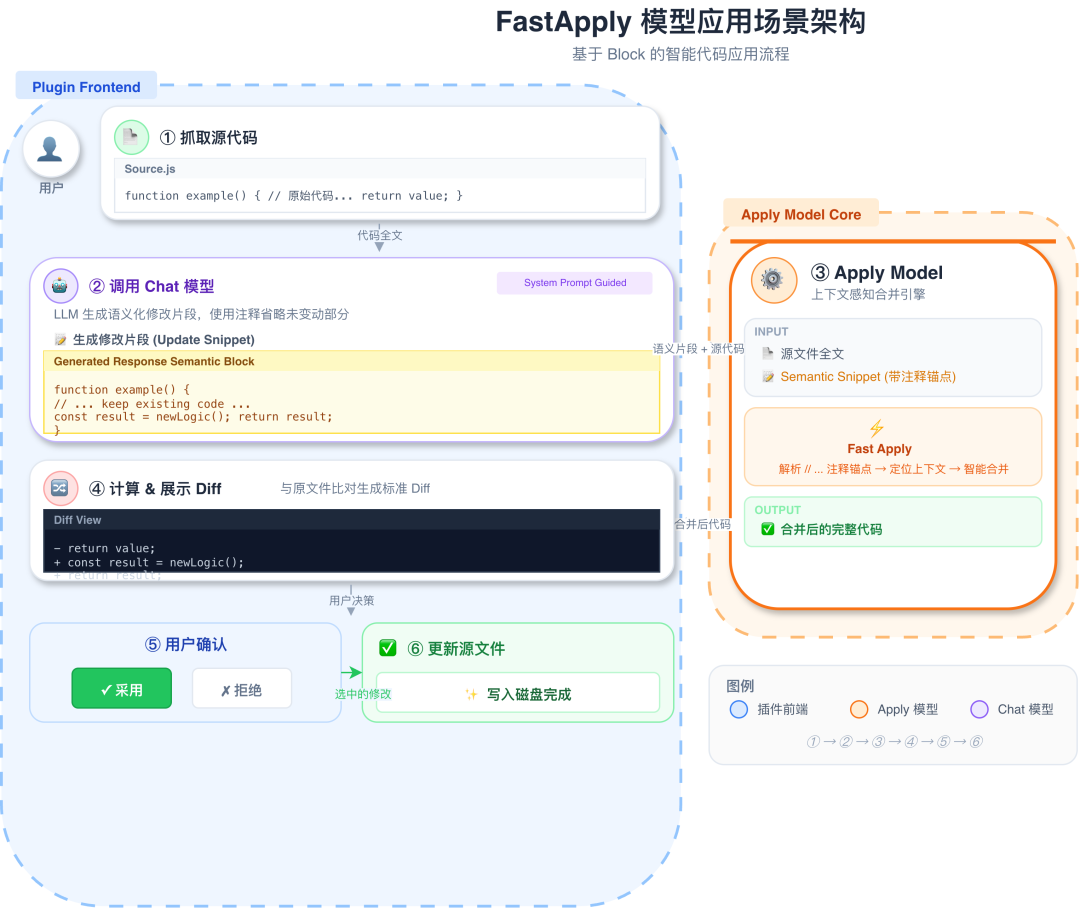
aiX-apply-4B 模型应用场景架构
与“什么都会”的通用大模型不同,aiX-apply-4B 的目标非常专注:自动识别修改意图、精准定位目标区域、严格保持原有格式与上下文结构,最终高效地将修改后的代码片段合并到原始文件中。
在推理效率方面,aiXcoder 引入了自适应投机采样技术,极大压缩了端到端延迟。企业级生产环境实测显示,aiX-apply-4B 的推理速度每秒可达 2000 tokens,在单张 RTX 4090 消费级显卡上即可高效运行。
相比之下,若要部署 DeepSeek-V3.2 这样的模型,通常需要八卡 H200 高端集群。综合不同的硬件部署成本与推理速度来看,aiX-apply-4B 仅用约 5% 的算力成本,便实现了 15 倍的效率提升。
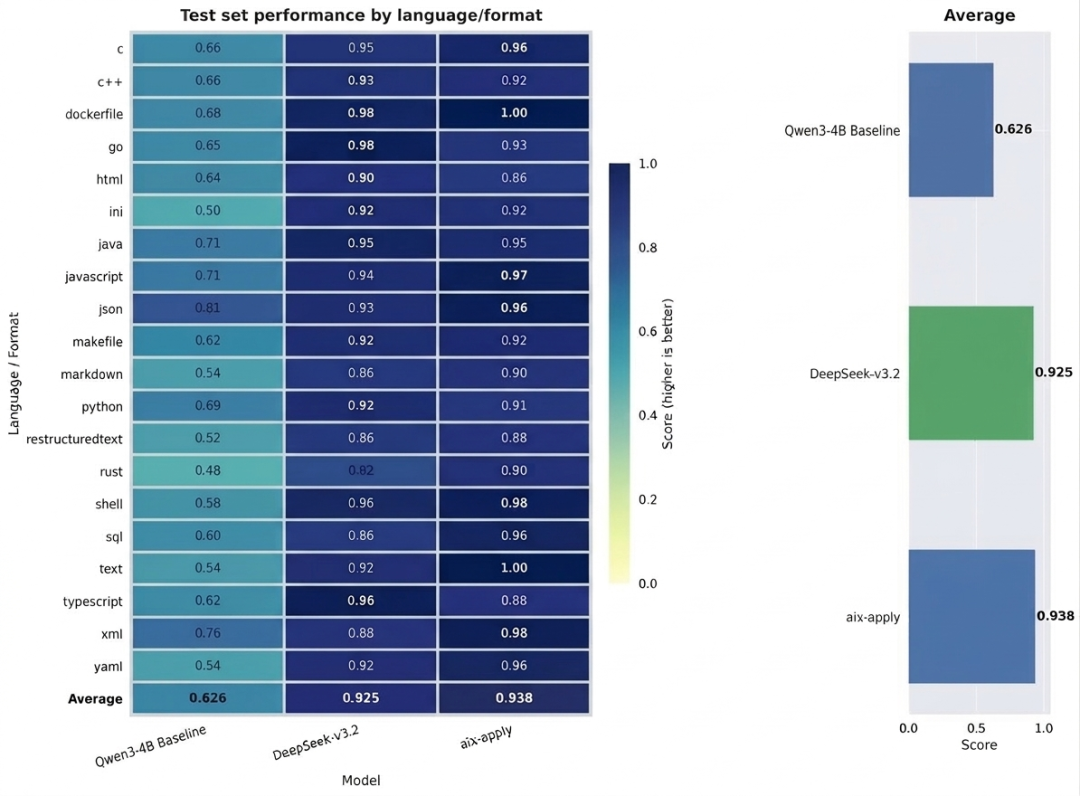
基准测试性能对比(得分越高越好)
在准确率方面,aiX-apply-4B 在覆盖 20 余种编程语言及文件类型的 1600 余条测试集上,表现优异。
在泛化能力方面,该模型同样展现出了媲美 DeepSeek-V3.2 的准确性和稳定性。
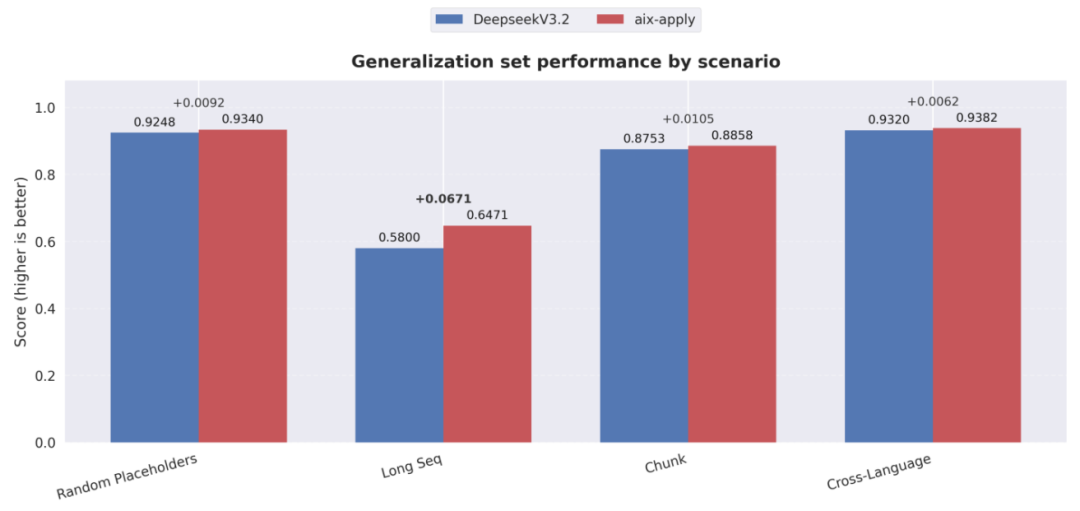
泛化能力测试对比(得分越高越好)
无论是面对超长代码文件的精确编辑,还是在训练数据中占比极低甚至未显式出现的编程语言场景下,该模型都保持了良好的范式泛化能力,这充分验证了其在真实企业级开发环境中的实用价值。
凭借低成本、高性能、易部署的特色,aiX-apply-4B 让研发算力有限的企业、团队乃至个人开发者也能轻松采用。在高准确率和严格工程化约束的加持下,该模型可极大减少因 AI 幻觉导致的意外变更,显著降低人工审查压力、减少线上故障风险,从而保障企业研发流程的稳定性与规范性。关于这类人工智能模型的最新实践,开发者社区常有深入探讨。
让每一分算力都用在刀刃上
从行业发展趋势来看,随着智能体框架的普及,企业 AI 应用正从单次模型调用走向多智能体协作,对算力的需求呈指数级增长。一个复杂任务的完成往往需要 10 到 50 次模型调用,并发场景下的 Token 消耗更是达到传统模式的数倍甚至数十倍。
这一变化直接加剧了企业的算力压力。尤其对于金融、通信、能源、航天等关键领域企业来说,私有化部署的算力资源固定且极其宝贵。每一次额外的模型调用,都在消耗本就紧张的算力,推高延迟的同时挤占并发能力。当多智能体协作成为常态,如何精细化控制算力成本成为企业面临的核心挑战之一。
公有云按 Token “烧钱”的模式往往无法满足企业严格的数据安全需求,而私有化部署千亿级、万亿级大模型则成本高昂,且容易因场景不匹配导致算力空转浪费。如何将有限的私有化算力实现最优配置,让每一份算力都能精准落到最需要的研发场景中去,是行业亟待解决的核心问题。
在这样的背景下,aiX-apply-4B 这类轻量级垂直模型在企业私有化部署和工程化落地中便展现出显著优势。它能够高效处理特定高频任务,避免了高端算力的浪费,从而充分释放企业有限算力的价值。
场景定义模型
据悉,这并不是硅心科技针对研发场景定义的第一款小模型。该团队此前就已推出过参数量为 7B 的代码补全小模型,能够精准预测开发者意图,专为日常编码的高频场景设计。这类针对性的模型实践,也是开源实战领域关注的方向之一。

基于“场景定义模型”这一理念,硅心科技已构建起覆盖多个研发关键环节的小模型矩阵,并创新性地提出了“大模型+小模型”协同架构:
通用大模型聚焦于复杂意图理解、代码逻辑分析、修改方案制定等需要深度推理的工作,发挥其智能优势;而垂直场景小模型则承接高频、确定的工程任务,以轻量化特性实现快速、精准的执行。
这种架构设计可以让企业的有限算力得到分层和高效利用。小模型支持专项场景任务的高效完成,从而节约出更多宝贵的算力资源,用于支撑大模型处理更复杂的推理任务。
“通才”大模型与“专才”小模型各司其职、优势互补的时代已经来临。对于开发者而言,了解并善用这些专有工具,将能极大提升研发效率。如果你想了解更多此类工具的深度解析和实战技巧,可以关注 云栈社区 上的相关讨论。
 发表于 2026-3-28 03:21:22
|
查看: 285|
回复: 0
发表于 2026-3-28 03:21:22
|
查看: 285|
回复: 0
