告别算力苦等 KV 缓存,DeepSeek 全面重构底层链路,令多轮推理吞吐量翻倍。
随着大模型全面向 Agent 智能体演进,系统推理的瓶颈已实质性转移至 KV-Cache 的存储 I/O 环节。
面对动辄数万 token 的极长上下文与高频多轮交互,现有的主流分离架构暴露出严重的硬件资源闲忙不均问题。近日,DeepSeek 联合北京大学、清华大学提出 DualPath 双路径架构,通过系统级重构充分释放了集群全局的存储网络带宽。
这项底层基础设施优化,显著提升了 Agent 任务的吞吐量上限,最高使离线推理吞吐量提升 1.87 倍。这项扎实的底层系统工程,不仅解决了当下的算力浪费,更让外界对传言中主打多智能体协同的 DeepSeek V4 充满遐想。

论文标题:
DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference
论文链接:
https://arxiv.org/pdf/2602.21548

算力没见底,网卡先堵死
Agent 任务具备长上下文、短追加的显著特征。由于历史 Context 在数十甚至数百轮的交互中高度复用,单次推理的 KV-Cache 命中率通常高达 95% 以上。此时 GPU 计算核心绝大部分时间处于等待缓存数据加载的闲置状态,系统呈现极端的 I/O 密集型表现。
在单轮平均仅追加 429 个 token(约 98.7% 命中率)的典型场景下,以 DeepSeek-V3.2 模型为例,其 Cache-Compute 比例高达 22 GB/PFLOP,对存储带宽构成了极其严苛的挑战。

表1. 主流大模型在Agent场景下的Cache-Compute比例
在当前工业界标配的 Prefill-Decode 分离架构中,海量的历史 KV-Cache 数据均由 Prefill 节点直接从远程外部存储单向加载。这种架构设计将所有的存储 I/O 压力集中在 Prefill 端的存储网卡上,导致其带宽长时间处于满载的饱和状态。
与此形成鲜明对比的是,Decode 节点配置的存储网卡却因为无事可做而处于严重的资源闲置状态。
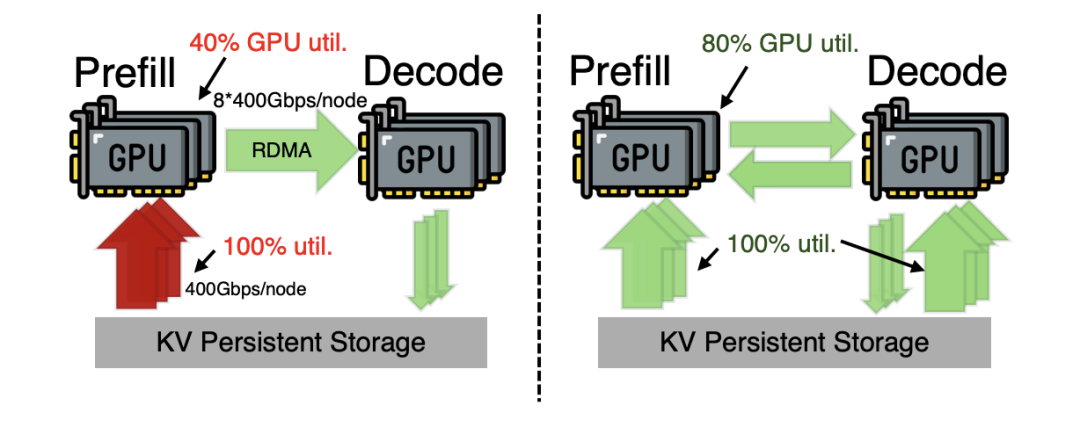
图1. 现有分离架构单点瓶颈与DualPath双路径架构对比
硬件底层架构的演进趋势进一步放大了这一矛盾。近年来 GPU 计算能力的增长曲线异常陡峭,但网络带宽与高带宽内存容量的攀升速度却相对滞后。I/O 能力与算力爆发的严重脱节,使得 AI 集群在处理 Agent 负载时极易撞上内存墙与通信墙,从 NVIDIA Ampere 到 Blackwell,I/O 与计算的比例下降了 14.4 倍。
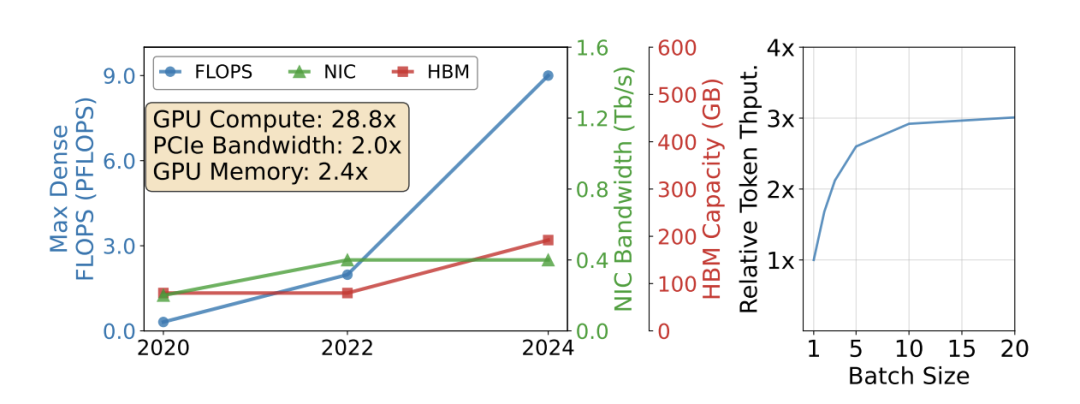
图2. GPU硬件算力与网络通信带宽演进脱节趋势

DualPath:双路径打破物理墙
破局的关键,在于掀翻 Prefill 中心化的旧规矩。DualPath 在传统的 Storage-to-Prefill 经典路径之外,极具开创性地引入了全新的 Storage-to-Decode 数据链路。
该架构首先将底层持久化存储中的 KV-Cache 读取至 Decode 引擎分配的内存缓冲区内,随后借助节点间超高带宽的计算网卡,利用 RDMA协议将数据高速透传至 Prefill 引擎进行注意力计算。
通过全局调度器动态分配这两条数据通路的流量,DualPath 成功唤醒了 Decode 端一直沉睡的存储网卡带宽,将原本受限于单点的 I/O 瓶颈转化为整个集群全局共享的高速资源池。
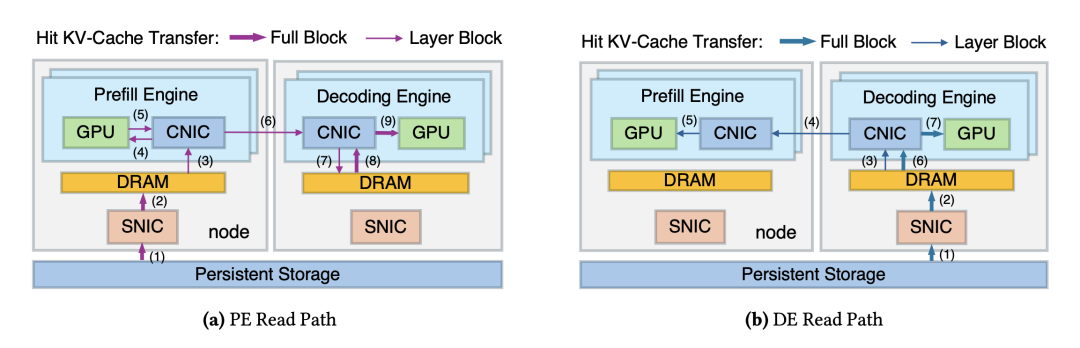
图3. 双路径加载的具体数据流向拆解
双路径必然引入海量数据搬运。为了防止计算网卡和内存总线被意外堵死,团队从底层软硬件拓扑入手,给出了一份极为严苛的数学证明。
以预填充端(PE)和解码端(DE)的读取链路为例,单节点存储网卡带宽为 $Bs$ ($Bg$ 为计算网卡带宽,$g$ 为单节点GPU数量)。
在理想负载均衡下,PE 端的 PCIe 读方向总流量为 $(P/(P+D)) * Bs$ 。由于实际硬件中 $Bs << g * Bg$ 恒成立,因此该读方向流量天然无瓶颈。
同理,DE 端的读操作总流量被约束为 $(D/(P+D)) * Bs$ 。对于半双工的 DRAM,系统同时将 DE 端的读写总压力限制在内存物理带宽 $M$ 以下。
汇总上述推导,论文明确给出了 Prefill 与 Decode 节点数量比例 $P/D$ 的终极安全约束空间:
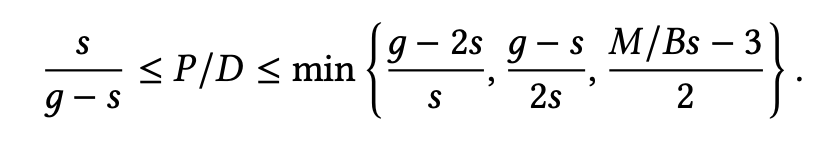
该分析从理论层面论证了在主流数据中心硬件配置下,双路径调度能够实现无拥塞的高效运转。

生产级落地的系统工程细节
顶层架构的创新需要精细到比特级别的底层工程实现作为骨架。引入全新的缓存传输路径势必在计算网络内产生额外的复杂流量,如何避免干扰对延迟要求苛刻的模型推理集合通信,是架构落地的首要技术挑战。
DualPath 在流量调度上采用全面以计算网卡为中心的管控策略。系统将所有的主机到设备数据拷贝全部交由计算网卡接管,并深度调用底层硬件的 QoS 机制实现了严格的物理隔离。
在 InfiniBand 网络中,这一机制体现为虚拟通道(Virtual Lanes, VLs),系统将约 99% 的权重分配给专供推理通信使用的高优先级通道。而在 ROCE 网络环境下,则通过区分服务代码点(DSCP)打标与硬件流量分类(TC)机制来实现对等的保障。低优先级通道则利用剩余带宽穿插执行 KV-Cache 搬运,在保障计算毫无阻塞的前提下利用网络余量。
跨引擎维度的任务分发由一套动态适应算法主导。全局调度器会实时拉取各个节点的两项核心健康指标:本地磁盘读取队列长度与当前积压待处理的 token 规模。系统设定了短读取队列阈值与未完成 Token 规模上限,将所有计算引擎划分为不同优先级的类别。调度决策会优先将新任务分配给磁盘队列较短且算力存在盈余的节点,避免单节点队列堆积压垮局部 I/O。

图4. 跨引擎预填充调度分发算法控制流
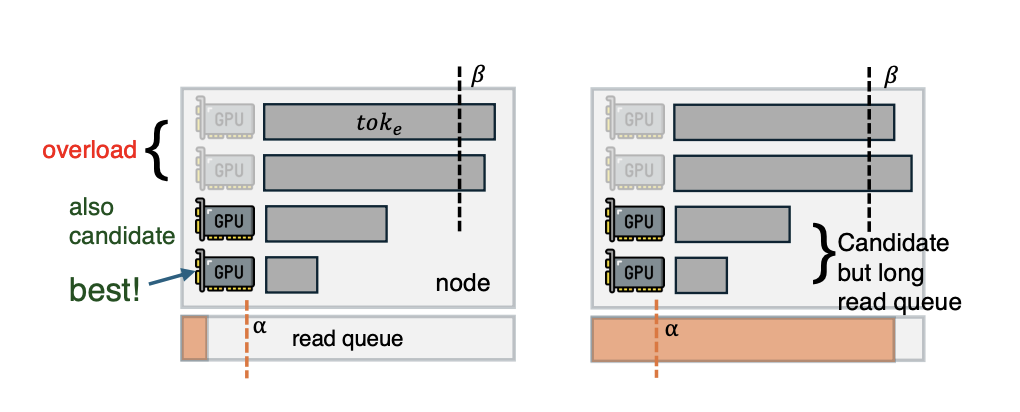
图5. 跨引擎预填充调度的优先级判定示意
调度算法的介入带来了直观的负载均衡收益:相较于轮询调度(Round Robin),多节点间存储网卡流量的 Max/Avg 极值比从 1.53 降至 1.18。在引擎内部,在任务执行的前 5% 阶段,同组 GPU 间 Attention 算子执行时间的 Max/Avg 比例被控制在 1.06,有效减少了跨卡同步等待产生的计算气泡。
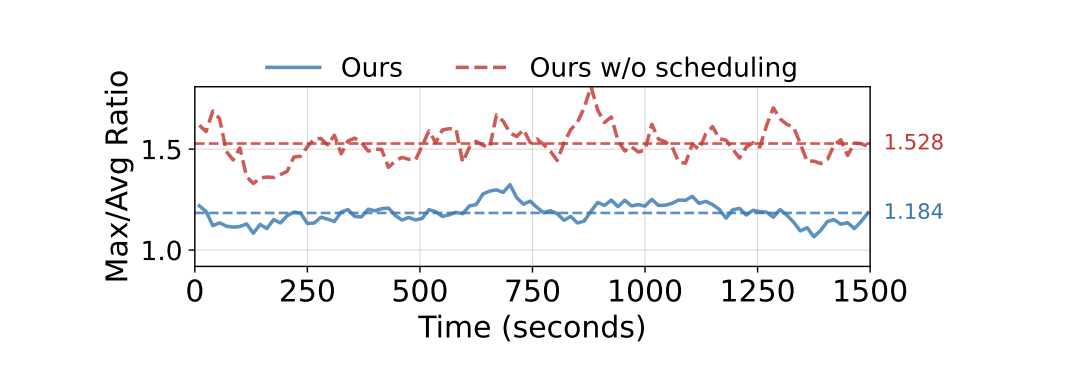
图6. 存储网卡流量的负载均衡效果展示
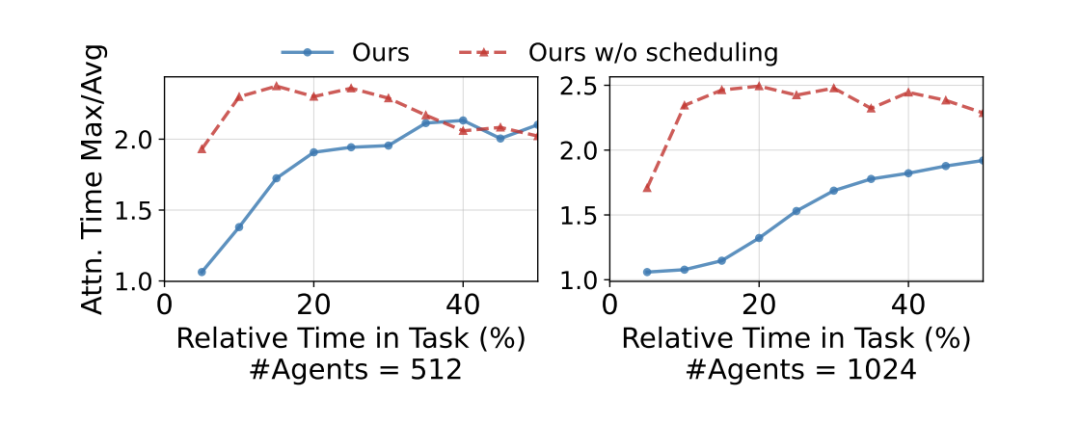
图7. Attention算子执行时间的负载均衡效果展示
针对数据并行模式下不同请求会导致各 GPU Attention 层计算耗时参差不齐的难题,系统在 Prefill 引擎内部引入了计算配额机制。通过二分查找动态切分单次前向传播包裹的 token 数量块,系统将同组内所有 GPU 的执行时间强行拉齐,极限压缩了 GPU 空转气泡。
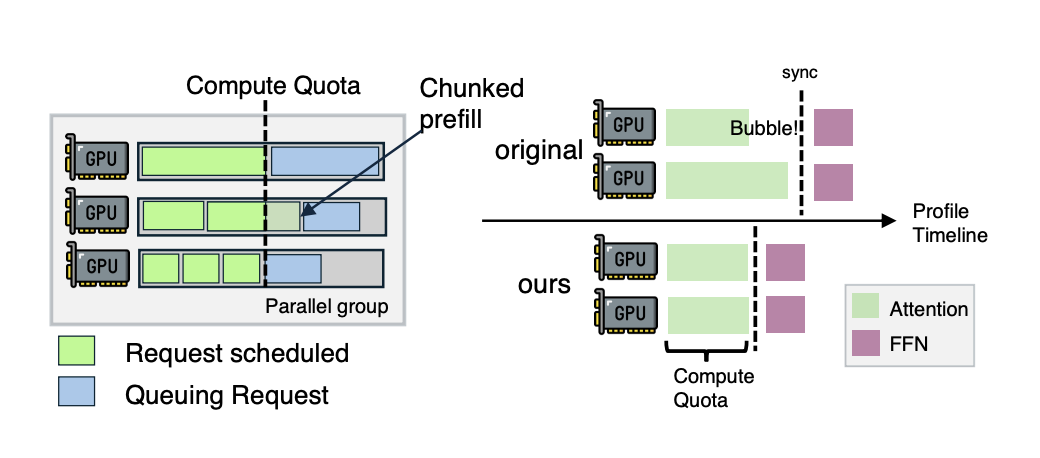
图8. 引擎内部Chunked Prefill与GPU Timeline气泡压缩

工业级测试验证
研究团队在部署了 1152 张 NVIDIA Hopper 架构 GPU 的生产级集群上,针对包含 DeepSeek-V3.2 660B、具备 GQA 架构的 Qwen2.5-32B 以及内部实验基座 DS 27B 等多个前沿模型进行了详尽评估。
离线与在线吞吐量双双翻倍:在强化学习训练极度依赖的离线跑批(Rollout)场景下(覆盖 32K 至 64K 超长上下文),DS 660B 任务完成时间最高提速 1.87 倍,极为逼近零I/O开销的理论极限(Oracle)。
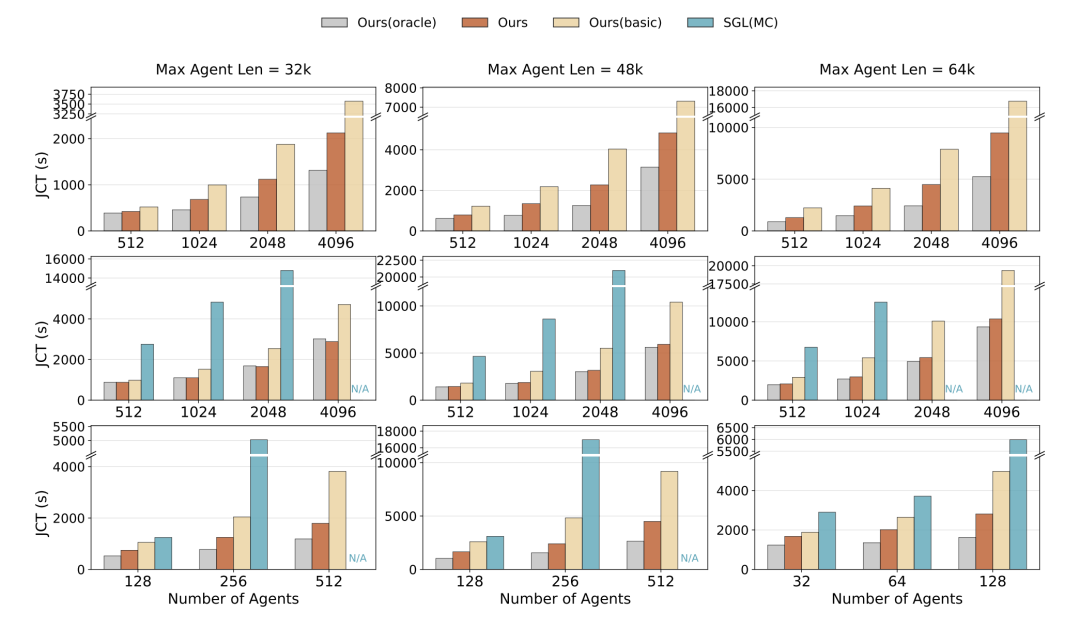
图9. 各大模型在离线推理环境下的性能拉升幅度对比
在严守首字延迟(TTFT)4 秒以内、单字解码延迟(TPOT)不超过 50ms 的在线服务中,系统承载并发率(APS)平均飙升 1.96 倍。
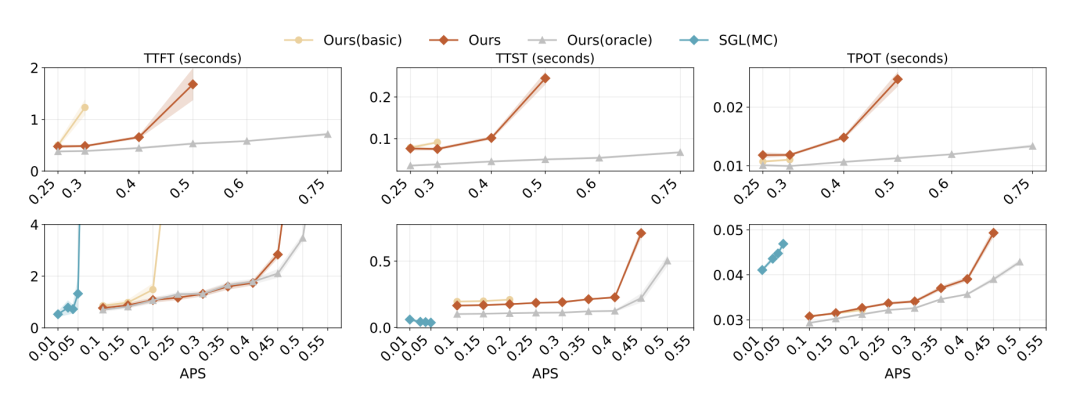
图10. 在线服务并发率拉升对关键延迟指标的压测表现
各项优化的独立价值(消融实验):相较于未优化的 Basic 架构,仅开启层级预填充即可降低 17.21% 的任务耗时;在此基础上叠加双路径加载,累计 JCT 降幅扩大至 38.19%;最终结合定制化的动态调度算法后,整体 JCT 较 Basic 基线大幅下降了 45.62%。
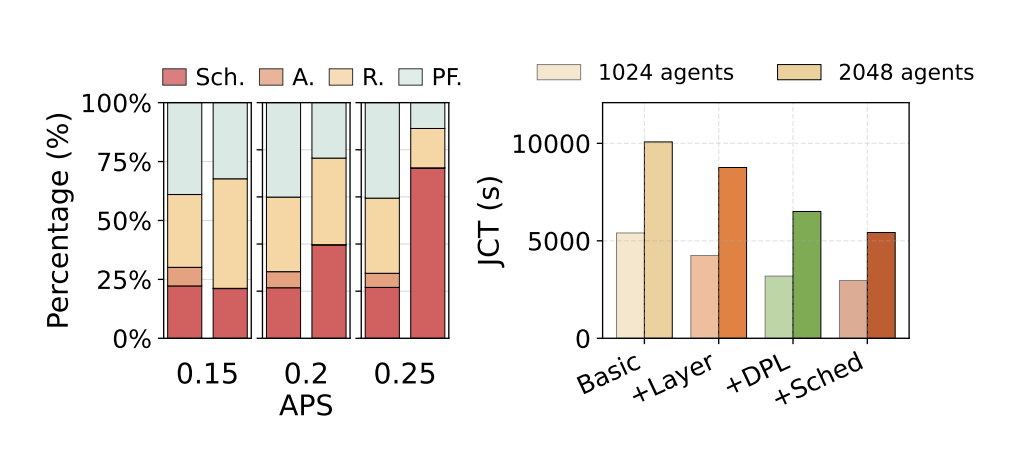
图11. 首字延迟切片分析与消融实验结果
锁定瓶颈的控制变量铁证:节点分配比例(P/D)的对比实验显示,DualPath 1P1D 架构与 Basic 2P1D 的吞吐量表现几乎完全等同。因为这两种配置下系统可用的总存储网卡带宽严格一致,这一硬核数据直接证实了存储网卡带宽正是限制整体系统的绝对短板。
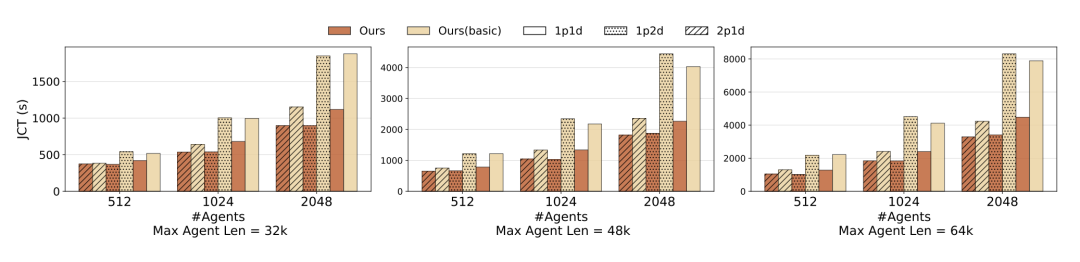
图12. 不同 P/D 比例配置对离线推理性能的影响
惊人的线性扩展能力:在极限扩展测试中,集群配置从基础的 2P4D 暴力拉升至最高 48P96D 的千卡阵列时,系统在保持相似推理延迟周期的前提下,实现了极高的吞吐量线性增长(例如在线服务扩展至 44P88D 时实现了 22 倍的吞吐量拉升)。
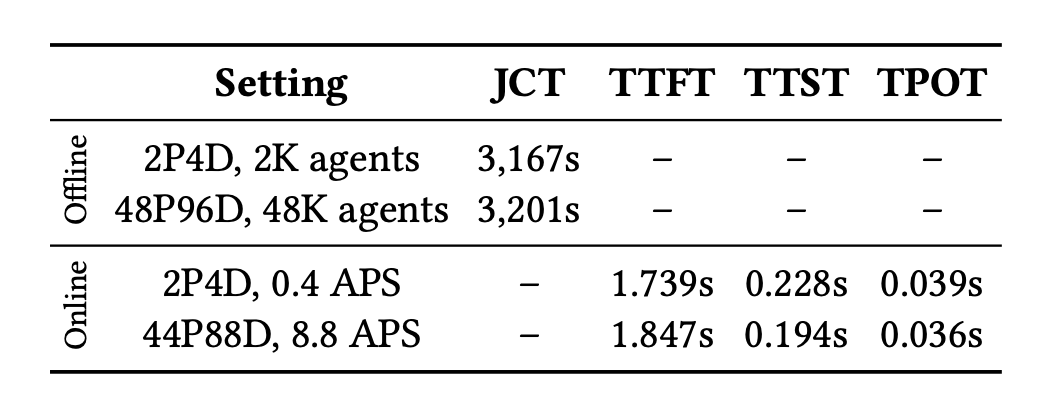
表2. 高达1152张GPU的生产级集群扩展性验证
尽管在千亿参数级别的大模型上表现优异,原论文也披露了该架构在小尺寸模型上的局限性。在测试较小的 DS 27B 模型时,无论是 Basic 还是 DualPath,其 TPOT(单字解码延迟)均显著高于纯理论的 Oracle 基线。这表明,基础的 Prefill-Decode 跨节点数据传输开销在小模型推理中占据了过大的比重,仍有待未来进一步攻克。

结语
DualPath 架构精准识别出存储瓶颈,打破了僵化的物理资源绑定关系,将原本孤立的网卡总线深度重组为高流动性的全局吞吐资源池。这种下潜至网络通信协议层面的软硬协同创新,拓宽了单数据中心集群承载极限长文本与多轮交互任务的性能边界。
当 DeepSeek 在基础设施端已经构建起如此高效的全局统筹机制时,其下一代 V4 大模型在多智能体协同场景下的表现,无疑具备了极高的技术起点。欢迎在云栈社区讨论更多关于大模型系统架构与性能优化的前沿话题。
 发表于 2026-3-3 18:21:31
|
查看: 223|
回复: 0
发表于 2026-3-3 18:21:31
|
查看: 223|
回复: 0
