你是否经常发现,随着AI使用越来越频繁,模型似乎总在“忘事”?
无论是上下文一长就开始丢失关键信息,还是多轮对话进行到后面就开始胡言乱语,这背后都指向同一个核心问题:底层模型自身的记忆能力存在天花板。目前最强的商用大模型,有效上下文通常也就停留在百万(1M)token级别。相比之下,有研究估算,人类一生能存储和调用的信息量级高达数亿token,两者差距巨大。
行业此前探索的主要路径有两条:一是无限拉长上下文窗口,但这会带来计算成本的二次方增长,难以持续;二是外挂RAG检索系统,但这种方式存在检索与生成的割裂,精度存在理论上限。如今,这两条路似乎都已触及瓶颈。
就在大家思考破局方向时,EverMind团队在GitHub悄然开源了MSA(Memory Sparse Attention,内存稀疏注意力) 项目。它提供了一条全新的思路:既不强行拉长上下文,也不外挂检索,而是将记忆直接嵌入模型注意力机制本身。
项目开源后迅速引发关注,短时间内便在GitHub斩获超过2600个星标。
一句话理解MSA
对比传统的RAG方案,MSA构建了完全不同的记忆机制。
你可以将传统RAG理解为给模型配备了一个外置硬盘,需要时得手动查询。而MSA则是为模型植入了原生的“记忆芯片”,让记忆成为模型自身能力的一部分。这意味着信息检索与调用的过程不再是两个割裂的步骤,而是被整合进同一个神经网络,实现了端到端的处理。
模型自身学会了决定哪些信息值得记忆、如何高效查找以及如何合理运用。整个过程没有人工规则的干预,也无需复杂的管道适配。
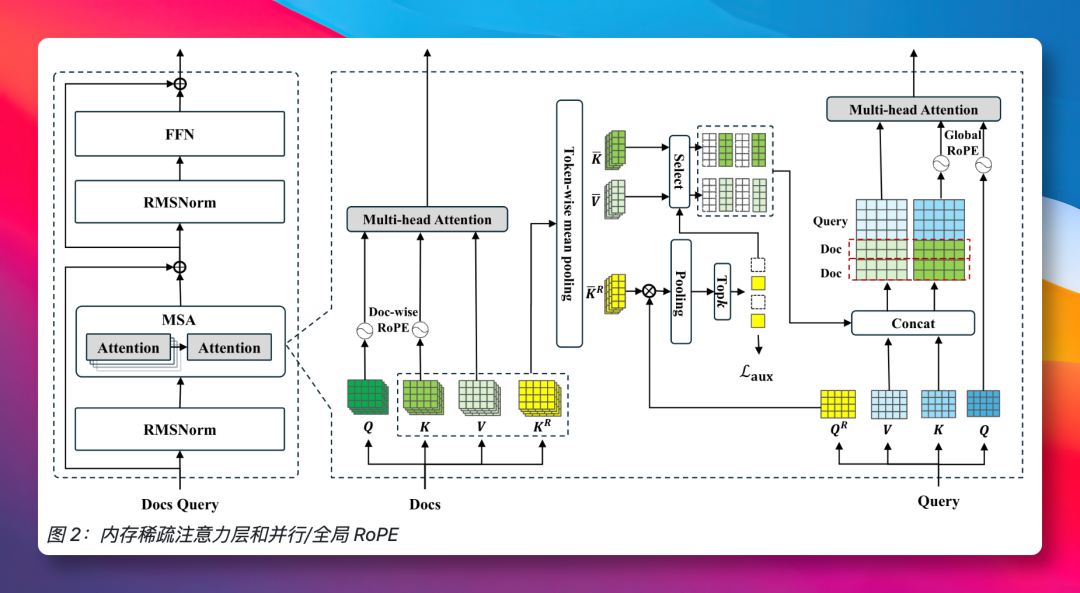
更关键的是,MSA具备“即插即用”的特性。开发者只需将标准Transformer架构中的Self-Attention层替换为MSA层即可,无需改动模型的整体架构。其实现依赖几个核心的技术细节:
- 通过压缩技术,将1亿token级别的记忆存储降至硬件可承受的范围;
- 采用GPU存放路由索引、CPU存放内容详情的策略,使得总记忆容量取决于系统内存而非有限的显存;
- 引入稀疏路由机制,将计算复杂度从O(L²)降低到O(L);
- 为每篇文档的位置编码进行独立编号,使模型在训练时仅需接触64K上下文,便能外推支持高达100M的超长记忆。
实际效果有多强?
无论架构设计多么精妙,最终仍需用数据说话。MSA基于Qwen3-4B模型构建,经过159B token的持续预训练,展现出以下几项突出的核心能力:
不仅记得多,还记得准
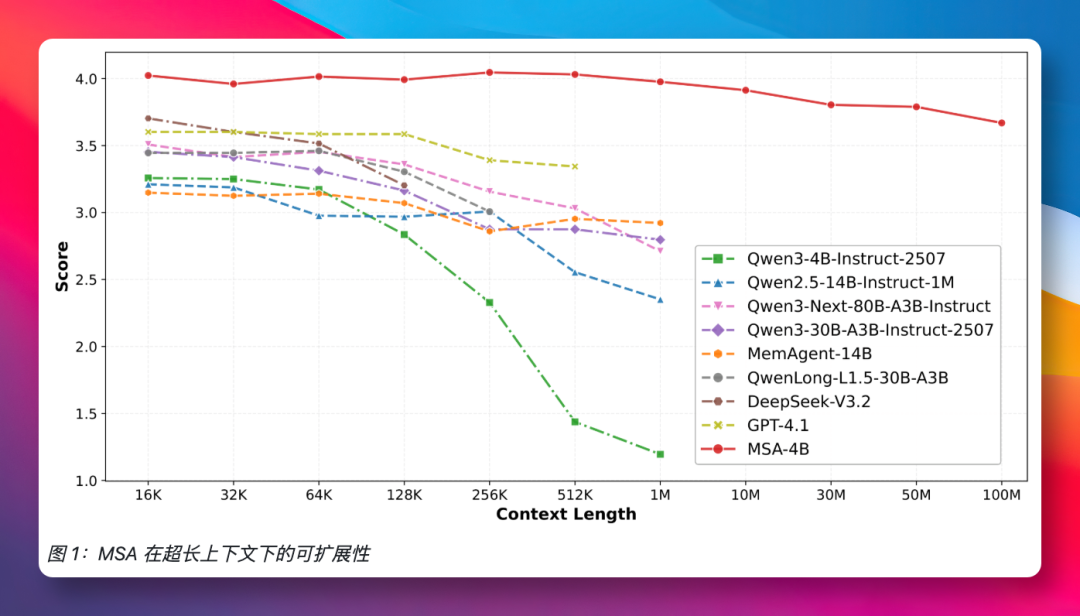
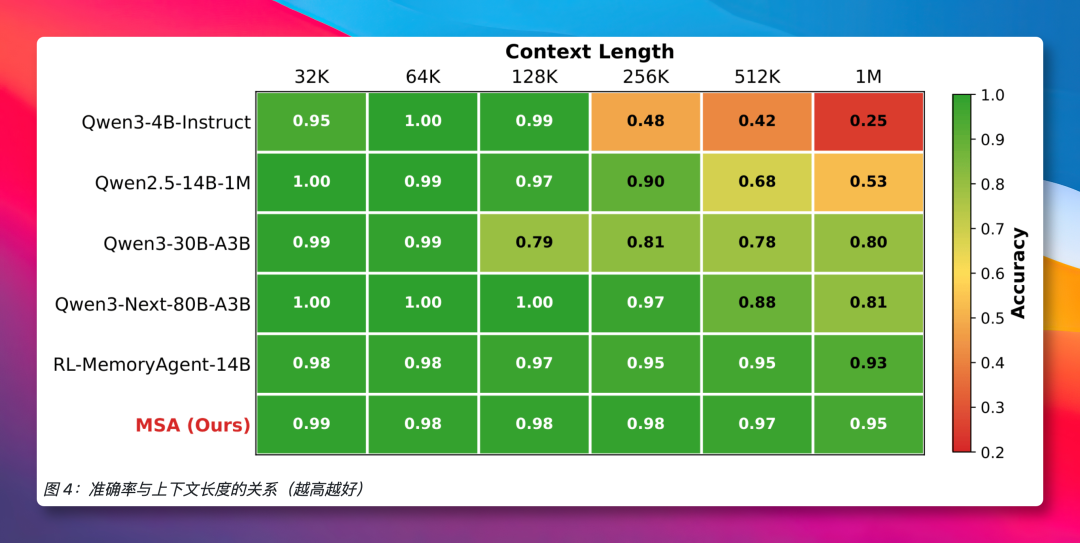
从处理1万多token到1亿token,上下文长度跨越近四个数量级,然而MSA的回答质量仅下降了不到9%。这好比别人读完一本书就开始遗忘,而MSA在读完上百本类似《红楼梦》的著作后,依然能准确复述出第三本第四十七回的细节。
小模型逆袭大模型
在9项标准问答测试中,使用仅40亿参数的MSA模型,其平均得分就比传统RAG方案高出16%。更令人惊讶的是,当面对由顶级检索器配合2350亿参数大模型组成的“豪华阵容”时,MSA依然在多项测试中胜出。参数量相差近60倍,效果却更优。这清晰地表明,在解决AI记忆问题上,正确的架构设计远比单纯堆砌模型参数更重要。
硬件门槛极低
整个项目可以轻松运行在配备两张A800显卡的服务器上,无需集群或特殊硬件支持。这意味着,从此刻起,中小型团队甚至个人开发者也有机会驾驭亿级token的长期记忆能力。
团队背景与研发历程
MSA项目来自盛大旗下的EverMind团队。该团队此前曾推出在GAIA榜单达到SOTA水平的多智能体框架Omne,以及开源记忆平台EverOS。
在将Omne框架落地到真实业务场景时,他们深刻意识到,智能体的记忆缺失问题无法在应用层得到根本解决,必须从模型底层入手。从项目立项到论文完成,历时九个多月,过程并非一帆风顺。
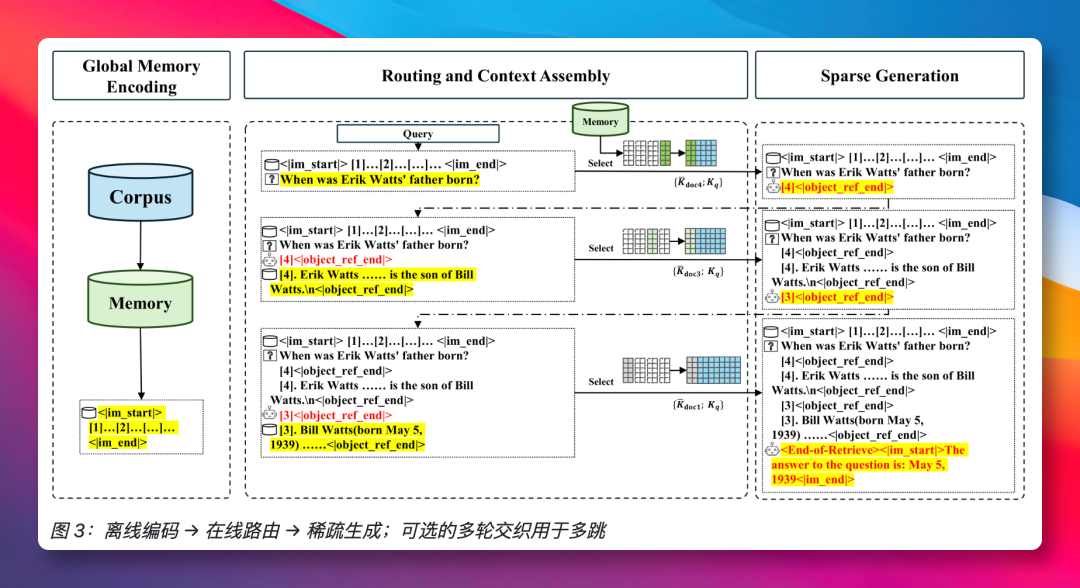
首个版本的模型在一些看似简单的任务上表现不佳,一度让团队怀疑技术方向是否正确。关键的转折点源于一个核心洞察:模型在“检索信息”和“生成答案”这两个阶段,所需的信息粒度和处理方式是不同的。
检索阶段需要宏观判断,以定位哪些文档与问题相关;而生成阶段则需要微观细节,以精确引用具体的句子。早期版本试图用同一套机制完成两项任务,结果导致两头都没做好。将这两种职能拆分开,由专门的模块分别处理,并配合更精细的训练策略后,模型性能实现了质的飞跃。
团队在论文中也坦诚指出了当前方案的局限:在需要跨多篇文档进行复杂关联和深度推理的场景中,纯内在记忆方案仍面临挑战。这种对技术边界保持敬畏的坦诚态度,反而增强了外界对团队判断力及项目长期发展潜力的信心。
写在最后
如果MSA所代表的技术路线能够成功落地,当前AI行业面临的诸多记忆瓶颈问题或将迎刃而从真正拥有长时记忆的那一刻起,AI助手才算开始真正“认识”它的使用者。它会记住你数月前提及的饮食偏好,跟上你上周讨论的项目进展,了解你家孩子的性格和你对周末出游的喜好。这一切无需你反复提醒,而是基于它自身的记忆。
更进一步,长期记忆能力将打开巨大的产品想象空间。真正个性化的AI教育、能够追踪患者完整病史的医疗助手、可积累十年项目经验的企业知识库……这些因模型“记性差”而难以实现的产品形态,都可能因记忆层的突破而变为现实。
MSA的发展方向还引出一个极具潜力的概念:记忆即服务(Memory as a Service)。记忆层未来可能成为一个独立、可插拔的模块,与各类大模型自由组合。这意味着用户的记忆资产将不再被锁定于单一模型或厂商。模型可以更换,但属于你的记忆将永久留存、伴随成长。这或许将成为AI时代下一项关键的基础设施。
目前,相关技术论文已经发布,核心代码也已开源,模型权重预计后续开放。对这项前沿技术感兴趣的朋友,可以前往GitHub仓库了解更多详情。关于更多前沿技术的深度讨论与资源共享,欢迎关注云栈社区。
 发表于 2026-4-8 07:00:11
|
查看: 189|
回复: 0
发表于 2026-4-8 07:00:11
|
查看: 189|
回复: 0
