你用 ChatGPT、Claude 这些 AI 的时候,有没有想过一个问题:为什么同一个系统提示词、同一份文档,你每次提问都要重新“喂”给模型?模型是不是每次都在重新读一遍?
答案是:技术上确实在重新计算,但 API 厂商想了个办法帮你省钱—— Prompt Caching 。这个机制跟浏览器缓存网页、CPU 缓存指令是同一个思路,但在大模型领域有自己的独特实现。今天就把这件事从底层原理到实际省钱策略,彻底讲清楚。

两个概念别搞混
在聊缓存之前,先厘清两个经常被混在一起的概念:
KV Cache 是模型推理层面的技术优化,所有大模型都在用,你感知不到它的存在。
Prompt Caching 是 API 计费层面的商业功能,需要你主动配置或满足特定条件才能触发,直接关系到你的钱包。
这两层缓存解决的是不同层面的问题,下面分开讲。
KV Cache:模型推理的“记忆”
大模型生成文本是一个字一个字吐出来的,这个过程叫 自回归生成。
每生成一个新字,模型都要“回头看”一遍之前所有的字,计算它们和当前字的关系。这个计算发生在 Transformer 的注意力机制(Attention)里,具体来说就是三个矩阵:Q(Query)、K(Key)、V(Value)。
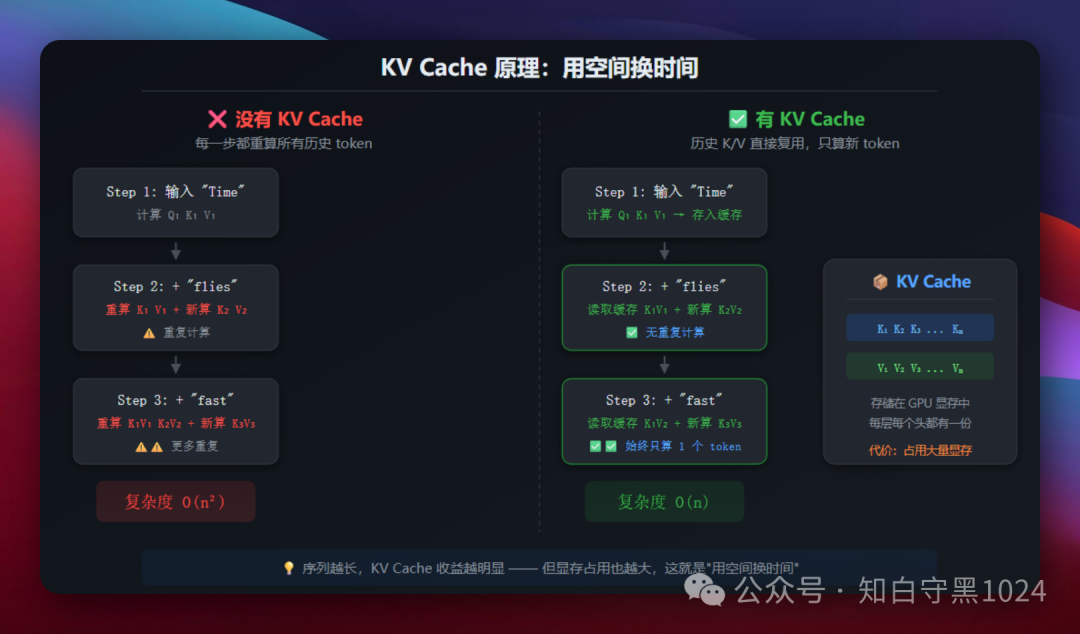
没有缓存的情况
假设你要让模型生成 “Time flies like an arrow”:
- 生成 “flies” 时,要计算 “Time” 和 “flies” 的关系
- 生成 “like” 时,要重新计算 “Time”、“flies” 和 “like” 的关系
- 生成 “an” 时,又要把 “Time”、“flies”、“like” 全部重算一遍
越往后生成,需要重复计算的量越大。如果输入有 1 万个 token,生成第 1 万个 token 时,前面 9999 个 token 的 K 和 V 矩阵都要重算。总计算量是 O(n²)。
有缓存的情况
KV Cache 的思路很简单:把算过的 K 和 V 存下来,下次直接用。
- 生成 “flies” 时,算出 K₁、V₁,存进缓存
- 生成 “like” 时,从缓存读取 K₁、V₁,只新算 K₂、V₂
- 生成 “an” 时,读取 K₁V₁、K₂V₂,只新算 K₃、V₃
每一步只需要计算当前这一个 token 的 K 和 V,加上一次查询操作。总计算量降到了 O(n)。
这就是“用空间换时间”——KV Cache 占用了大量 GPU 显存来存储历史 token 的 K、V 矩阵,但把生成速度提升了一个数量级。
KV Cache 的代价
KV Cache 不是免费的午餐。它的显存占用非常可观:
- 一个 7B 参数的模型,32 层,32 个注意力头,每个 token 的 KV Cache 大约占用 1MB
- 输入 8k 个 token,KV Cache 就要吃掉约 8GB 显存
- 这就是为什么长文本推理需要更大显存的显卡
所以你看到各大模型厂商都在做 KV Cache 的压缩优化(比如 GQA 分组查询注意力、MQA 多头查询注意力),本质上都是为了在缓存效果和显存占用之间找平衡。
Prompt Caching:API 厂商的“会员折扣”
KV Cache 是模型内部的事,你作为 API 调用者管不了。但 Prompt Caching 是你能直接控制的省钱手段。
原理也很直观:如果你连续多次调用 API,每次都带着相同的 system prompt 和文档内容,只有最后的问题不同,那 API 厂商为什么要把相同的前缀每次都重新计算一遍?
不如把计算结果缓存起来,下次遇到相同的前缀直接复用,给你打个折。
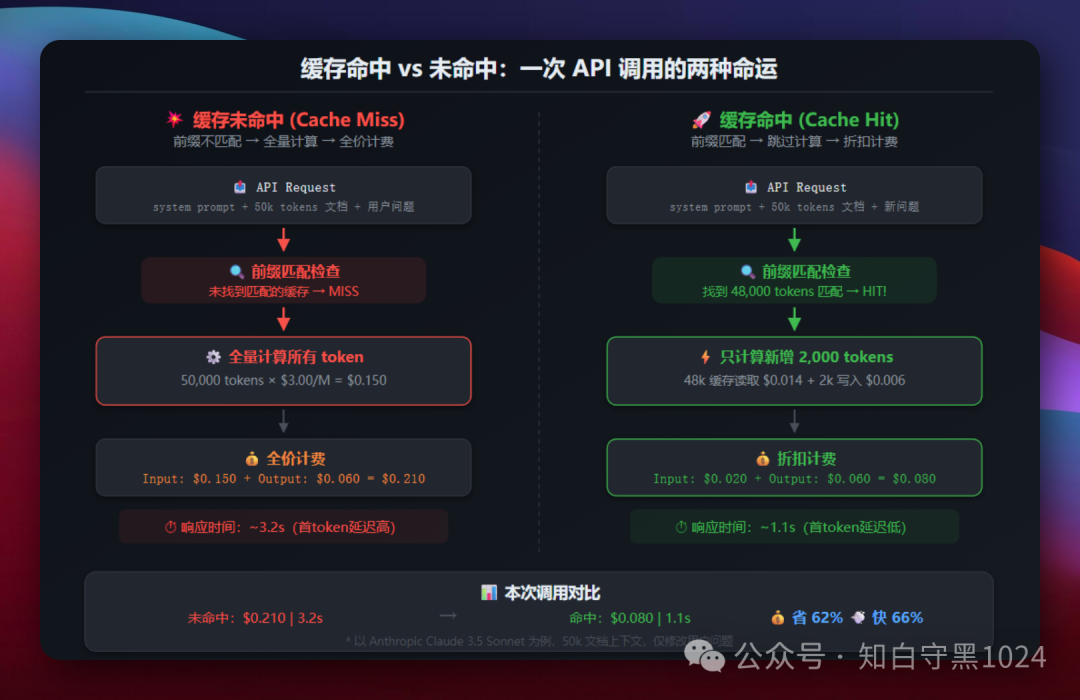
缓存命中 vs 未命中
一次 API 调用发生了什么:
缓存未命中(Cache Miss):API 检查你发送的 prompt 前缀,发现没有匹配的缓存。于是对全部 50k 个 token 执行完整的注意力计算,按全价收费。
缓存命中(Cache Hit):API 发现你的 prompt 前 48k 个 token 跟上次一模一样,直接复用之前的计算结果。只对新增的 2k 个 token 做计算,前 48k 个 token 按折扣价收费。
关键区别在于 首 token 延迟(TTFT)——缓存命中时,模型不需要重新处理那 48k 个 token,响应速度会快很多。
三大厂商怎么收费的
Anthropic Claude:手动标记模式。你在 API 请求里用 cache_control 标记需要缓存的文本块,最多设 4 个断点。缓存有效期 5 分钟,也可以付费延长到 1 小时。缓存读取价格是原价的 1/10,折扣力度最大。
OpenAI GPT-4o:全自动模式。不需要任何配置,API 自动检测前缀匹配。最低 1024 tokens 触发,有效期 5-10 分钟。写入不额外收费,读取是原价的 半价。简单粗暴,零门槛。
Google Gemini:显式缓存模式。通过 Context Caching API 创建缓存对象,最低 32768 tokens,按小时计存储费。缓存读取是原价的 1/4。适合大规模、长时间的批量任务。
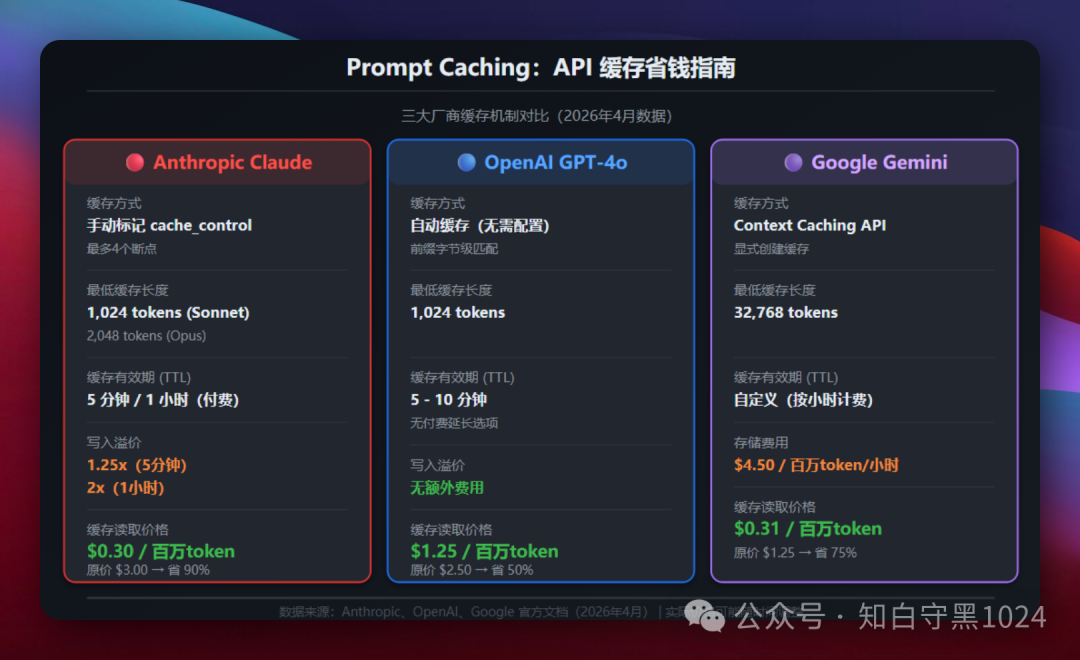
怎么选?
- 追求最大折扣 → Anthropic(90% off),但需要手动标记
- 不想改代码 → OpenAI(自动缓存,零配置)
- 超长上下文批量任务 → Google(按需创建,灵活控制 TTL)
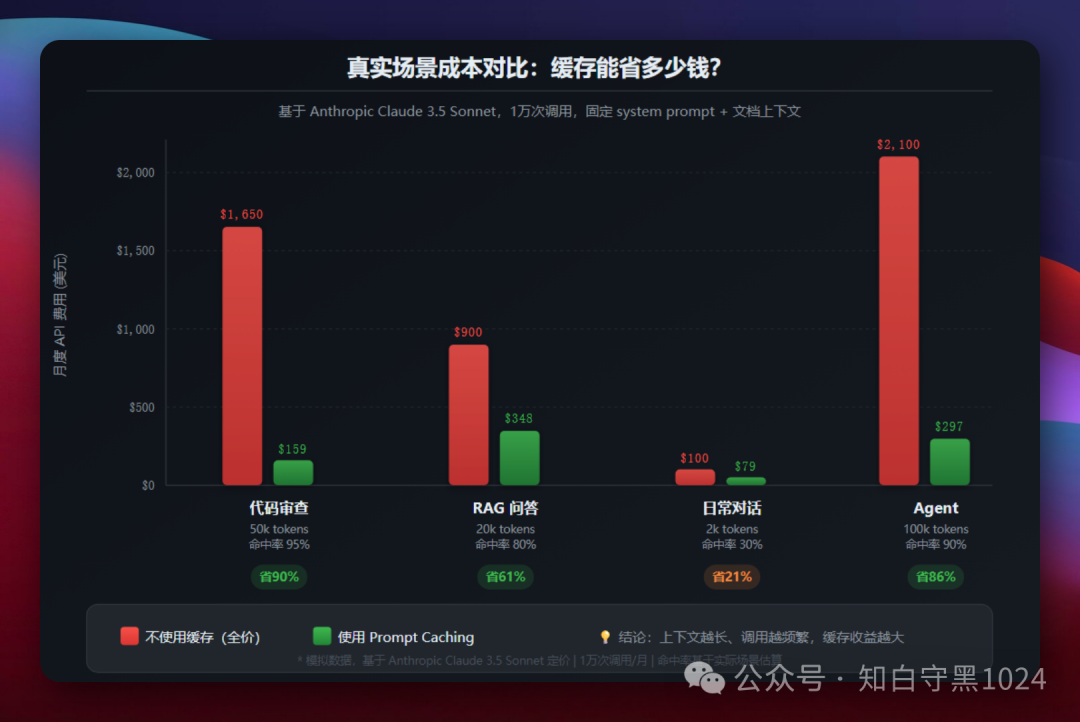
真实场景能省多少
光说折扣比例不直观,看几个真实场景:
代码审查场景:每次把整个代码仓库(约 50k tokens)发给模型,只改最后的问题。命中率可以做到 95%。一个月 1 万次调用,不用缓存要 $1,650,用缓存只要$159,省 90%。
RAG 问答场景:每次检索出相关文档片段(约 20k tokens)作为上下文。不同问题的上下文会有部分重叠,命中率约 80%。从 $900 降到$348,省 61%。
AI Agent 场景:Agent 在多轮对话中维护完整的工具定义和对话历史(可达 100k tokens)。每一轮对话的前缀几乎完全相同,命中率 90% 以上。从 $2,100 降到$297,省 86%。
日常对话场景:上下文短(2k tokens),每轮对话内容变化大,命中率只有 30%。从 $100 降到$79,省 21%。这种场景缓存意义不大。
规律很清楚:上下文越长、调用越频繁、前缀越固定,缓存收益越大。
提高命中率的实操技巧
缓存能不能省钱,核心看 命中率。几个实用技巧:
1. 固定前缀顺序
把不变的内容放在 prompt 最前面。system prompt → 工具定义 → 文档内容 → 用户问题。这个顺序每次都一样,前缀匹配的概率就高。
千万别把用户问题放在前面,文档放在后面——这样每次问题的不同会导致整个前缀失效。
2. 合理设置缓存断点
Anthropic 允许设 4 个缓存断点。建议断点设在:
- system prompt 之后(这部分几乎不变)
- 工具定义之后(Agent 场景)
- 文档内容之后(RAG 场景)
这样即使文档内容有变化,system prompt 和工具定义的缓存依然有效。
3. 控制缓存粒度
不要把所有东西都塞进一个缓存块里。如果你有 10 个工具定义,但每次调用只用 3 个,那就把工具定义拆开,只缓存常用的那几个。
4. 注意 TTL
缓存的命脉是时间窗口。Anthropic 免费缓存只有 5 分钟,如果你的调用间隔超过这个时间,缓存就失效了。对于低频场景,考虑付费延长到 1 小时。
5. 监控缓存指标
Anthropic 的 API 响应里会返回 cache_creation_input_tokens 和 cache_read_input_tokens 两个字段。用这两个数据算命中率:
命中率 = cache_read_input_tokens / total_input_tokens
持续监控这个指标,低于 50% 就要检查是不是前缀结构有问题。
一个容易忽略的坑
缓存写入是有溢价的。Anthropic 的 5 分钟缓存写入价格是原价的 1.25 倍,1 小时缓存是 2 倍。
这意味着:如果一段缓存写入后没有被命中过,你不仅没省钱,还多花了 25% 到 100%。
所以缓存不是无脑开启就行的。只有当一段前缀在有效期内能被命中至少 2 次,才值得写入缓存。对于低频、一次性调用的场景,不开缓存反而更划算。
写在最后
KV Cache 和 Prompt Caching,一个是模型工程师关心的推理优化,一个是 API 用户关心的成本优化。它们解决的是同一个根本问题:大模型的注意力计算太贵了,得想办法少算点。
理解了这两层缓存,你就能搞清楚为什么长文本 API 那么贵、为什么 Agent 的 token 消耗那么大、以及怎么通过调整 prompt 结构来实打实地降低账单。
对于高频使用 AI API 的开发者来说,Prompt Caching 可能是最不需要改代码就能省钱的优化手段。更多实战省钱的技巧与讨论,欢迎到 云栈社区 一起交流。
命中率 = cache_read_input_tokens / total_input_tokens
 发表于 2026-5-23 03:11:09
|
查看: 210|
回复: 0
发表于 2026-5-23 03:11:09
|
查看: 210|
回复: 0
