看着 API 账单上的数字一路飙升,你的第一反应是不是「不如自己买卡跑」?打住。
本地大模型到底什么时候比 API 划算?这是一道由「日均 token × 持续时间 × 真实 TCO × 业务约束」构成的算术题,而不是一句口号。
这篇文章会把这笔账拆开给你看,顺便还原两个真实案例作为参照。读完你至少能避开三类最常见的拍脑袋决策。
01 核心拆解
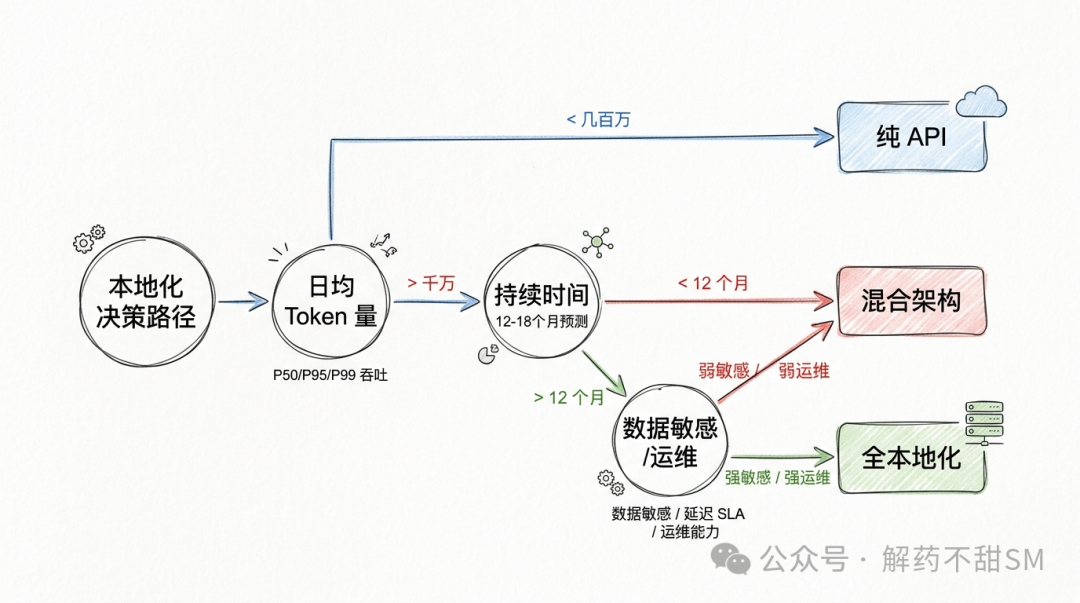
想把账算明白,判断顺序至关重要。
先算 token 量,再拍 36 个月 TCO,最后用数据敏感度、延迟要求、运维能力来决定要不要走混合架构。
以下经验区间,可以作为一个更直观的入门参考:
- 日均不到几百万 token,老老实实用 API;
- 日均上千万 token 且业务能稳定 12-18 个月以上,本地化才具备初步的测算价值;
- 中间灰区,混合架构通常是更稳健的现实解。
注意:这只是入口判断,不是终局答案。最终的结论必须用本文给出的公式套你自己的业务参数来推演。
接下来的内容会把这道题涉及的几个关键变量逐一摊开,并给出两个对照案例作为参照——分别代表高吞吐生产的 Stripe 和中小企业渐进式落地的阿里 OpenClaw。
02 为什么不能拍脑袋
我见过的最常见决策错误有三种:
坑1、看着 API 账单焦虑直接拉硬件:
算了 GPU 价格,却没算电费、运维、人头、安全和利用率;半年后发现总成本反而高于 API。
坑2、把 Ollama 单机 demo 当生产证据:
本地跑通就以为可以直接上线,把开发态工具直接挂上公网;过去一段时间,已有多类高危漏洞被披露——模型加载器内存越界、未鉴权敏感数据泄露等,足以让 prompt、系统提示甚至 API key 跟着漏掉。
坑3、把「本地化」和「自建集群」画等号:
完全忽略掉混合架构这个最朴素的折中方案。
这三个坑都有同一个根源:既没把账算清楚,也没把约束条件列齐全。 下面我们来一步步把这笔账拆明白。
03 盈亏平衡点:以日均 token 量作为衡量标尺
业内经过反复测算形成了几条经验区间:
| 日均 token 量 |
推荐路线 |
前提条件 |
| 几十万到几百万级 |
纯 API |
业务波动期 / 团队无 GPU 运维能力 / 延迟可接受公网调用 |
| 几百万到上千万级 |
混合架构 |
有数据敏感场景 / 峰谷波动明显 / 想分层降本 |
| 持续上千万级且 ≥12 个月 |
全本地化 |
数据敏感 / 延迟敏感 / 团队能 hold 住 GPU + K8s |
这些数字不是定律,是入口。
GPU 单卡基础部署年成本通常在万美元量级,企业级多 GPU 高可用起步更在十万美元量级。这些钱要靠 token 量和持续时间一起摊销。如果最终核算下来量不够,结果就是妥妥的负杠杆。
一个最小可复算的成本公式
对本地 LLM 成本核算概念还比较模糊的朋友,可以参考下面这个算法公式,套你自己的业务来算清楚:
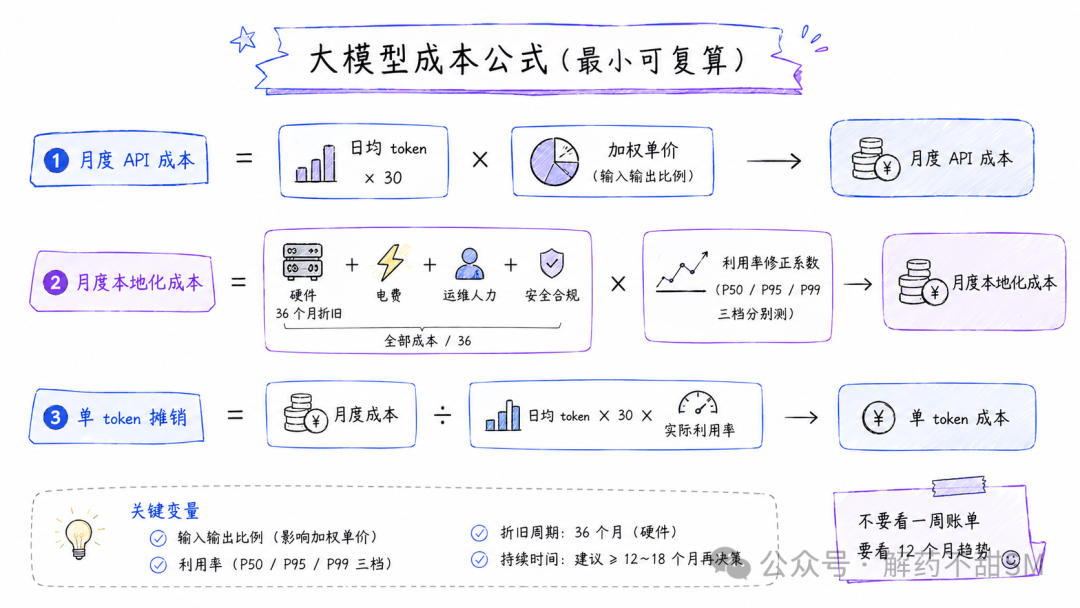
关键变量:
- 输入输出比例(一般 2:1 到 5:1,编码场景偏输出,问答偏输入)
- 利用率修正:用 P50(常态)、P95(高峰)、P99(极端峰)三档分别测算,不要只用平均值
- 折旧周期:硬件按 36 个月,模型规格变化按 12-18 个月做敏感度分析
一个简化样例
某团队日均 300 万 token、输入输出 3:1、计划稳定运行 18 个月以上:
1、API 路线:
取行业主流闭源模型加权单价区间,月度成本通常落在数千到一两万美元。
2、本地化路线(双 GPU + 7B 量化):
硬件折旧 + 电费 + 0.5 人运维 + 合规预算,按 36 个月摊销下来,月度成本同样落在几千美元量级。但前提是利用率要达到 P50 设计目标。
3、结论:
在这个量级和持续时间下,两条路成本是接近的。最终决策要回到数据敏感度、延迟和团队能力这些非成本变量上。
这就是为什么在「01 核心拆解」中特别强调「判断顺序」——成本只是入口。
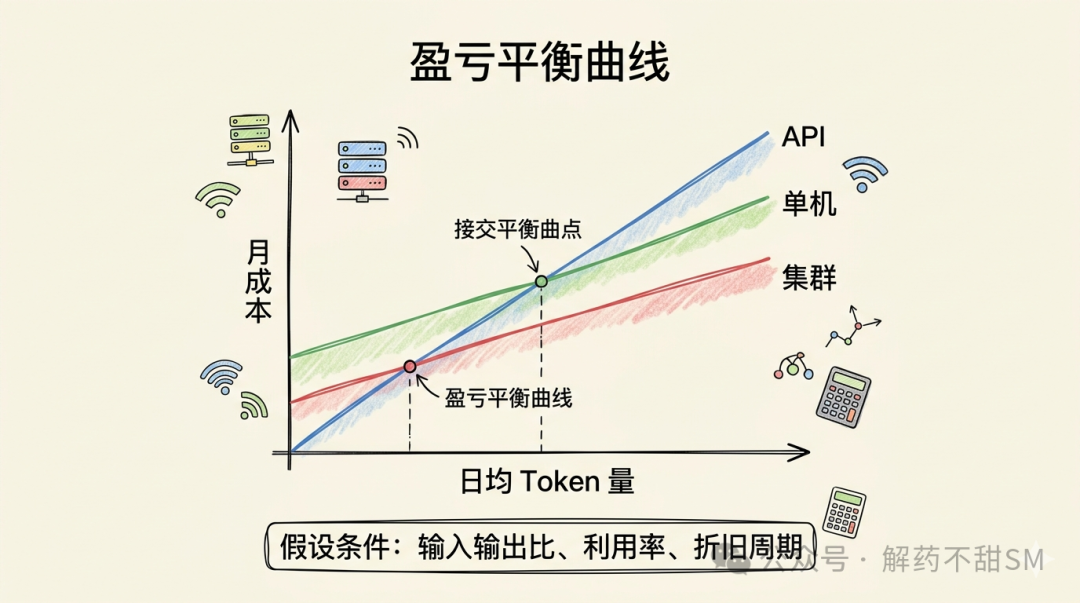
关键陷阱:不要看一周账单做决策,要看 12 个月的趋势。 业务还在波动期就锁定硬件,要么吃满折旧,要么资源闲置。
04 TCO 必须算 5 项,不是 1 项
很多人算本地化成本只盯着 GPU 价格,这是头号误区。真实的总拥有成本至少涵盖 5 个维度:
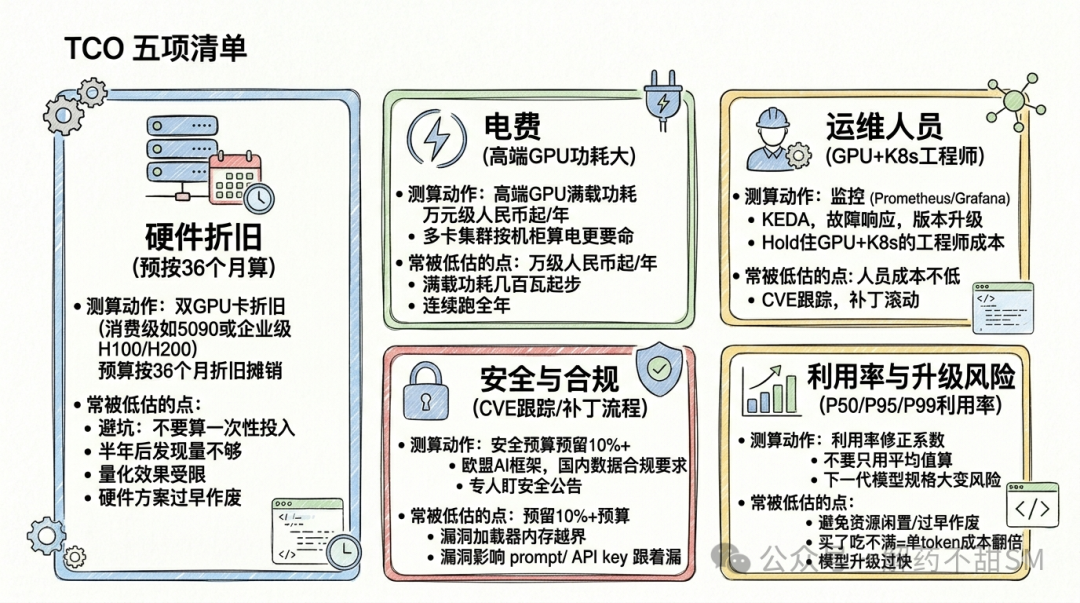
- 硬件折旧:消费级双卡(如 RTX 5090 双卡)能逼近部分 70B 模型推理表现,企业级 H100/H200 则是另一档报价。预算池要按 36 个月折旧算,不要当一次性投入。 具体型号选型和性能数据会在系列后续文章里展开测算。
- 电费:高端 GPU 满载功耗几百瓦起步,连续跑全年电费会跑到万元人民币量级。多卡集群按机柜算电更要命。
- 运维:监控(Prometheus/Grafana)、自动扩缩容(KEDA)、故障响应、版本升级——这些都要人。一个能 hold 住 K8s + GPU 的工程师可不便宜。
- 安全与合规:CVE 跟踪、补丁滚动、访问控制、审计日志、合规审查(欧盟 AI 监管框架在陆续生效,国内数据安全合规要求也在加码)。必须有专人盯安全公告和升级节奏。
- 利用率与升级风险:买了用不满,单 token 成本就可能翻倍;下一代模型规格大变,硬件方案可能过早作废。请用 P50 / P95 / P99 三档业务量分别测算单 token 成本,并对未来 12-18 个月模型可能升级的方向做敏感度分析。
把这 5 项算齐,一些「看上去本地更划算」的场景就会立刻反转。
算账时建议直接列 36 个月 TCO + 三档利用率,不要只列单月平均值。
05 Ollama 不是生产级答案,但替换它也并不等于生产就绪
这条单独拎出来讲,因为它常被双向误读。
Ollama 的边界:它在 GitHub 上累积了十几万 Stars,体验流畅,是开发期 PoC(概念验证)的神器。但如果直接把它挂到生产环境的公网,就会出大事:已披露的多类高危漏洞涉及模型加载器内存读越界、未鉴权敏感数据提取等,能泄漏整个进程内存,包括用户 prompt、系统提示、环境变量里的 API key 和 token。
更广泛的生产陋习:
OLLAMA_HOST=0.0.0.0 被大面积使用,行业研究披露的暴露实例数量级在十万级以上。这是个长期问题,而非单个版本的事故。
但这里要澄清一个常见的概念偷换:
很多文章会写「生产级推理引擎应该是 vLLM / SGLang / TensorRT-LLM」,这话只说对了一半。
1、vLLM / SGLang / TensorRT-LLM 解决的是推理服务和性能优化问题:
高吞吐、显存调度、批处理、量化加速。
2、它们本身并不自动提供生产治理能力:
鉴权、限流、审计、隔离、补丁滚动、SLA 保障,这些要靠 API 网关、Service Mesh、K8s、监控告警和安全策略一起兜底。
所以,一个生产级方案通常组件包括:
- 高性能推理服务(vLLM / SGLang / TensorRT-LLM)
- API 网关鉴权限流
- 监控告警
- 审计日志
- 补丁流程
- 隔离策略
这一整套,不是「换个引擎就等于生产就绪」。
如果这个决策错了,后面所有关于「本地化省钱」的论证,都将建立在沙子上。
具体的 CVE 编号、影响版本和补丁版本,建议直接以 NVD、Ollama release notes 和官方安全公告为准。本文不试图锚定具体版本号,避免文章写成「过期就过时」。
06 两个对照案例(看的是结构,不是结论)
案例一:Stripe 迁 vLLM
「高吞吐场景的胜利样本」
| 字段 |
说明 |
| 场景 |
大规模生产 LLM 推理服务,业务长期稳定 |
| 规模 |
日 API 调用量级在数千万级(行业公开报道);注意:调用次数不直接等于 token 量,需要用平均请求 token 数换算 |
| 关键约束 |
已有完整 SRE/运维能力,长期承诺,性能 SLA 严格 |
| 公开结论 |
从 Hugging Face Transformers 迁到 vLLM 后,GPU 数量与推理成本均出现明显下降(行业报道数据,具体百分比以 Stripe 工程博客为准) |
| 可迁移的部分 |
「日 token 远超平衡点 × 业务长期稳定 × 团队能 hold 住运维」三条同时成立时,本地化复利就能跑出来 |
| 不能套的部分 |
普通公司没有这个量级,也没有 Stripe 级别的工程团队——不要拿大厂样本强行套自己的业务 |
案例二:阿里 OpenClaw + Qwen-7B
「中小企业的渐进式玩法」
| 字段 |
说明 |
| 场景 |
企业内部 AI 助理,混合数据敏感度(内部机密 + 通用问题) |
| 规模 |
中小团队级别使用量,不在百万/千万 token 量级 |
| 关键约束 |
CPU 实例 + 量化模型,效果会受量化精度和小模型能力上限约束——更适合分类、检索、固定模板任务,不适合开放式复杂推理 |
| 公开结论 |
通过意图路由层把内部机密走本地 Qwen-7B 量化版(CPU 实例),通用问题走云端 API,月度 AI 成本可压到较低水平(具体口径以原案例为准) |
| 可迁移的部分 |
数据敏感度和成本曲线一起决定路由——这是混合架构最朴素也最实用的玩法 |
| 不能套的部分 |
任务复杂度高、对效果敏感的场景,CPU + 7B 量化版扛不住,需要换成更强的本地模型或回归 API |
把这两个案例放在一起看,意义在于:不是要二选一,而是要把「日 token 量、长期稳定性、数据敏感度、效果要求、团队能力」这些维度一起摆出来。每一条决策,都得落到这几个维度上对齐。
07 决策动作清单
如果你正在做这道题,建议按以下顺序来推进决策:
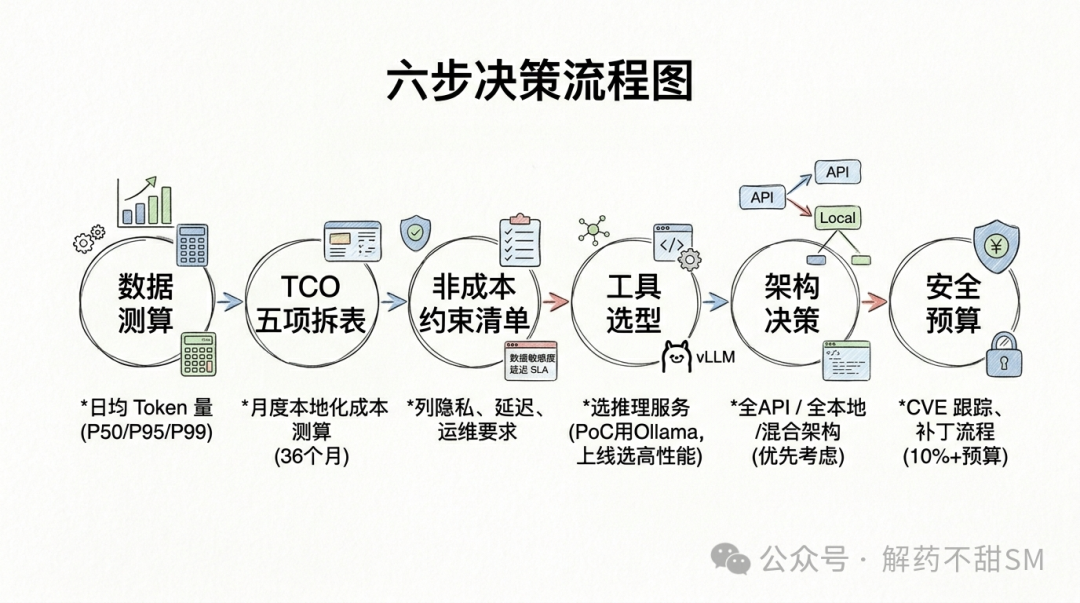
- 测一周日均 token 量,拆出 P50 / P95 / P99 三档:以业务高峰期为准,× 30 得到月度量;峰值利用率将决定本地化是否吃得饱。
- 拍 36 个月 TCO 表(5 项必须齐全):硬件折旧 + 电 + 运维 + 安全 + 利用率/升级风险,这五列必须全都算进去。
- 列非成本约束清单:数据敏感度、延迟 SLA、模型能力差距、可用性要求、团队 GPU 运维能力——任意一条不达标,本地化都不能只看 token 量就做决策。
- 把 Ollama 框死在 PoC 阶段:上线时,选择 vLLM / SGLang / TensorRT-LLM,并配齐 API 网关、鉴权、限流、监控、审计和补丁流程。
- 优先考虑混合架构:除非明确达到日均上千万 token、有长期承诺、且上述所有非成本约束都齐备,否则,混合架构总是优于全本地化。
- 预留安全预算:CVE 跟踪、合规审查、漏洞响应——强烈建议这部分预算不低于总成本的 10%。
08 下篇预告
这篇文章讲清了「要不要做」。
下一篇《vLLM / SGLang / TensorRT-LLM 选型实战》将解决决策之后的第一道工程题——用什么引擎。
我们会用同一套测试口径,去比较冷启动时间、峰值吞吐、稳态延迟、运维复杂度这几条关键指标。具体测试条件和数据会在下一篇里完整交代清楚,避免任何「反直觉的结论」流于口号。
09 延伸阅读
- 安全公告:Ollama 官方 release notes 与 NVD 漏洞库——上线前请先核对一遍 CVE 状态
- 工程博客:Stripe《Migrating to vLLM》——高吞吐场景迁移的真实样本
- 行业研报:Premai《Private LLM Deployment Guide》——TCO 经验值与盈亏平衡测算口径
- 官方文档:vLLM 官方文档 docs.vllm.ai——推理引擎部分的入门必读
系列文章
- 篇一:算清这笔账:本地大模型什么时候比 API 划算(本篇)
 发表于 2026-5-9 23:18:19
|
查看: 122|
回复: 0
发表于 2026-5-9 23:18:19
|
查看: 122|
回复: 0
