Paged Attention 是一种解决 KV Cache 内存浪费问题、让 LLM 同时服务更多用户的核心技术,彻底优化大模型显存利用率。
1. 核心数据结构:BlockTable(块表)
这是“页表”的直接实现,每个请求(sequence)都持有一张自己的 BlockTable。
# vllm/v1/worker/block_table.py(简化关键结构)
class BlockTable:
def __init__(self, block_size: int, max_num_reqs: int, max_num_blocks_per_req: int, ...):
self.block_size = block_size
# 实际是一个 [max_num_reqs, max_num_blocks_per_req] 的 tensor
# 每行存该请求的逻辑块 -> 物理块ID映射(-1 表示未分配)
self.block_table = torch.full(..., -1, dtype=torch.int32, device='cpu', pin_memory=True)
# 还有 kernel_block_size(有时为 1,用于某些 kernel 兼容)
- 逻辑含义:第 i 个逻辑块对应第 i×block_size 个 token 的 KV。
- 更新时机:
- 预填充(prefill)时:一次性分配足够块,填满 BlockTable。
- 解码(decode)时:每生成一个 token,如果当前块满了,就调用 allocator 申请新物理块,追加到 BlockTable 末尾。
- 共享优化:多个请求如果前缀 KV 相同(parallel sampling、beam search),它们的 BlockTable 前几行可以指向同一个物理块,实现零拷贝共享。
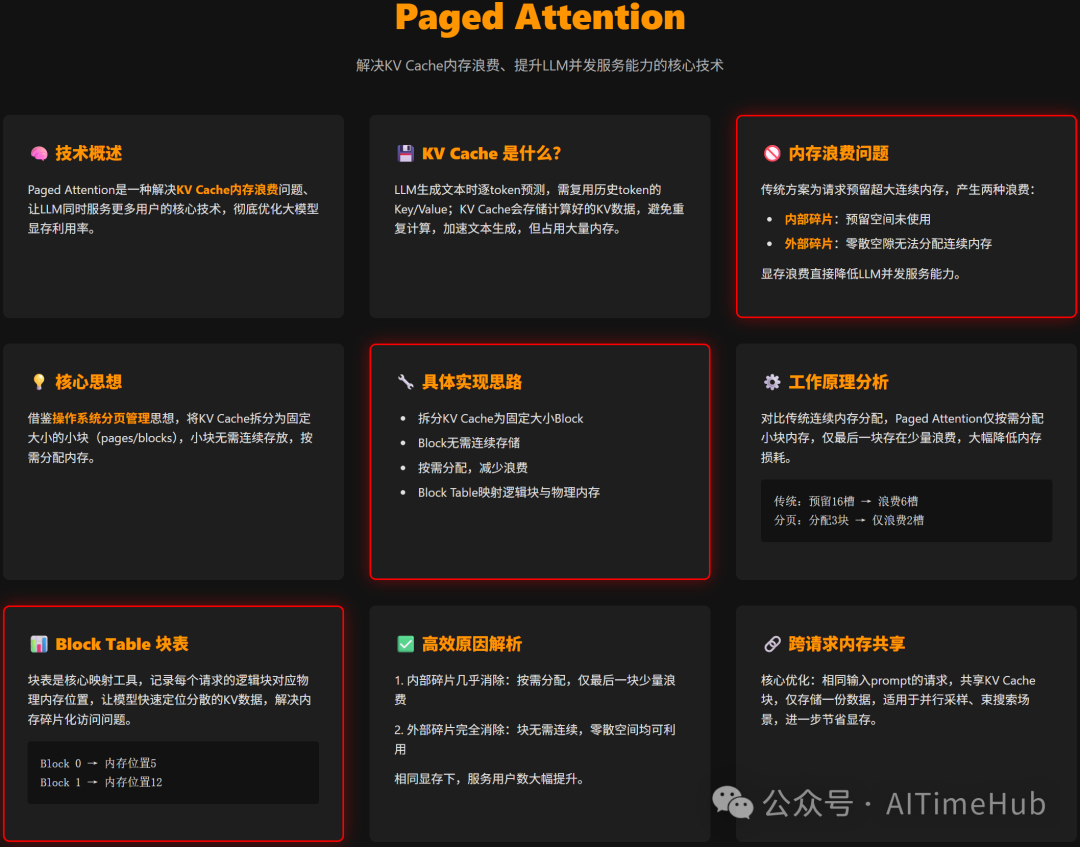
2. 内存分配层:BlockManager / KVCacheManager + BlockAllocator
这是“分页分配器”。vLLM 用一个全局空闲块池(free block queue,通常是双向链表 + deque 实现 O(1) 操作)管理所有物理块。
关键逻辑(来自 kv_cache_utils.py 和 block_pool 相关模块):
# 简化后的 BlockAllocator / FreeBlockQueue
class BlockAllocator:
def __init__(self, num_blocks: int, block_size: int):
self.free_block_ids = deque(range(num_blocks)) # 空闲物理块 ID
self.used = set()
def allocate(self, num_blocks_needed: int) -> List[int]:
if len(self.free_block_ids) < num_blocks_needed:
# 触发 swapping 或 eviction(vLLM v1 支持)
raise OutOfMemory
return [self.free_block_ids.popleft() for _ in range(num_blocks_needed)]
def free(self, block_ids: List[int]):
for bid in block_ids:
self.free_block_ids.append(bid) # 归还到池子
- BlockPool:负责实际的 GPU 内存池,KV Cache 是两个大 tensor:
k_cache: [num_blocks, num_kv_heads, head_size // x, block_size, x](key 布局优化为 coalesced 访问)v_cache: [num_blocks, num_kv_heads, head_size, block_size](value 按 token 列主序)
- 按需分配:请求生成时,只分配当前需要的块,最后一个块可能有少量内部碎片(block_size - 剩余 token),外部碎片彻底消失。
3. KV Cache 存储布局
- 物理 KV Cache 不是连续的 [batch, seq_len, ...],而是块化的。
- 每个物理块固定存
BLOCK_SIZE(默认 16)个 token 的 KV。
- 访问公式(Python 侧):
logical_block_idx = token_idx // block_size
offset_in_block = token_idx % block_size
physical_block = block_table[seq_idx][logical_block_idx]
# 然后去 k_cache[physical_block, kv_head, :, offset_in_block, :] 读
这就是 BlockTable 发挥作用的地方——把逻辑位置翻译成物理位置。
4. 注意力 Kernel 核心:paged_attention_kernel(CUDA)
这是最关键的性能部分,位于 csrc/attention/attention_kernels.cu。它不要求 KV 连续,而是通过 BlockTable 做 indirection(间接寻址)。
内核签名(模板化,高度优化):
template<typename scalar_t, int HEAD_SIZE, int BLOCK_SIZE, int NUM_THREADS, ...>
__device__ void paged_attention_kernel(
scalar_t* __restrict__ out, // 输出
const scalar_t* __restrict__ q, // 当前 query [num_seqs, num_heads, head_size]
const scalar_t* __restrict__ k_cache, // 分块后的 Key
const scalar_t* __restrict__ v_cache, // 分块后的 Value
const int* __restrict__ block_tables, // [num_seqs, max_blocks_per_seq] 的 BlockTable
const int* __restrict__ context_lens, // 每个 seq 已有的上下文长度
...
)
计算流程(伪代码 + 关键片段):
- 加载 Query(每个 thread group 负责一个 query token):
// 共享内存缓存 query
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
// coalesced 读取
-
遍历所有逻辑块(外循环):
for (int block_idx = 0; block_idx < num_blocks; ++block_idx) {
int physical_block = block_tables[seq_idx * max_blocks + block_idx];
if (physical_block == -1) break; // 未分配块,结束
// 计算当前块的起始 token
int start_token = block_idx * BLOCK_SIZE;
// 内循环遍历块内每个 token
for (int token_in_block = 0; token_in_block < BLOCK_SIZE; ++token_in_block) {
int token_idx = start_token + token_in_block;
if (token_idx >= context_len) break; // 掩码
// 计算物理地址
const scalar_t* k_ptr = k_cache + physical_block * kv_block_stride
+ kv_head_idx * kv_head_stride
+ token_in_block * x; // x 是向量化宽度
// 加载 K_vec
K_vec k_vecs[...] = load(k_ptr);
// QK dot-product(跨 thread reduction)
float qk = scale * Qk_dot<...>::dot(q_vecs[...], k_vecs);
logits[token_idx - start] = (mask) ? 0.f : qk;
}
}
- Warp 级 Softmax(qk_max、exp_sum 规约)。
- Value 累加(类似 QK,但做 logits × V):
for (每个块) {
for (每个 token_in_block) {
v_vec = load_v_from_physical_block(physical_block, token_in_block);
accs[i] += logits_vec * v_vec; // 点积累加
}
}
- 最终规约输出到 out tensor。
内核通过 thread group + warp + block 三级并行,保证内存访问 coalesced,同时用 shared memory 缓存 logits 和 query,性能损失只有 5-10%(相比连续 KV Cache)。
5. 完整工作流程(一次 decode 步)
- Scheduler 选一批请求 → 准备 inputs。
- 对于每个请求:查 BlockTable,看是否需要新块 → 调用 allocator.allocate() → 更新 BlockTable。
- 把当前 batch 的 所有 BlockTable 打包成一个大 tensor 传给 kernel。
- Kernel 执行 paged_attention_kernel → 得到新 token 的 logits。
- 生成新 token 后,把它的 K/V 写回最后一个物理块(offset = 当前长度 % block_size)。
- 请求结束时:BlockTable 对应的所有物理块归还到 free pool。
6. 额外亮点:内存共享 & 高级特性
- 前缀共享:BlockTable 支持多个 seq 指向相同物理块(prefix caching)。
- vLLM v1 的优化:引入 BlockPool + FreeKVCacheBlockQueue(双向链表 sentinel 节点),分配/释放都是 O(1)。
- Swapping / Eviction:显存不够时可把冷块 swap 到 CPU(vLLM v1 已支持)。
总结
一句话总结代码实现:BlockTable + 块化 KV Cache + 间接寻址的 CUDA Kernel,把“连续大块预分配”变成了“按需小块 + 页表映射”。这正是 vLLM 能把相同显存下推理吞吐量提升数倍的核心原因。如果你想查看更多类似的高质量技术文档或参与源码分析的讨论,欢迎访问云栈社区。
参考
- https://docs.vllm.ai/en/latest/design/paged_attention/
- W. Kwon et al., “Efficient memory management for large language model serving with PagedAttention,” arXiv:2309.06180.
- T. Dao et al., “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,” arXiv:2205.14135.
 发表于 2026-4-14 05:34:50
|
查看: 267|
回复: 0
发表于 2026-4-14 05:34:50
|
查看: 267|
回复: 0
