“现代 GPU 架构已转向基于芯粒的多芯片设计……然而 CUDA/HIP 执行模型并未适应这一架构变迁。尤其是,没有直接的方法来表达工作组群之间的数据亲和性,或将工作限定到特定芯粒的内存层次。”
来自 AMD 的研究者们在《Fleet: Hierarchical Task-based Abstraction for Megakernels on Multi-Die GPUs》这篇文章中揭示了当前 AI 算力基础设施的一个隐秘痛点:当 GPU 硬件已经进入“联邦制”的多芯粒时代,编程模型却仍停留在“中央集权”的单片逻辑中。
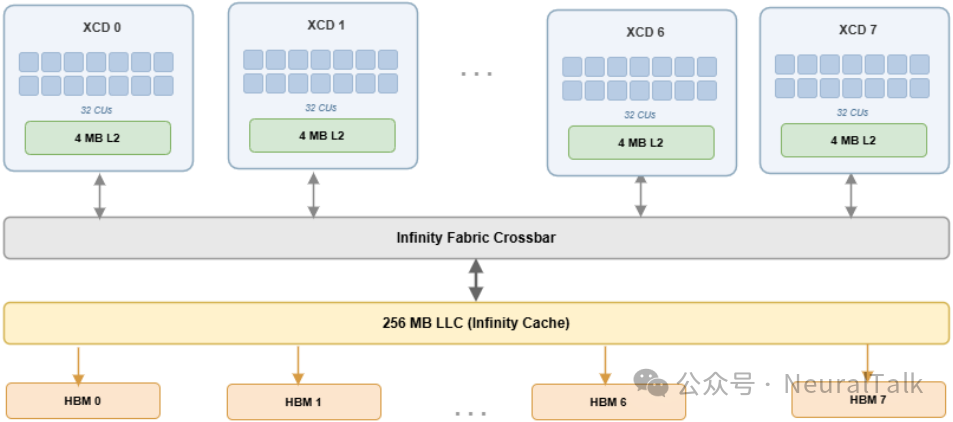
拿 AMD Instinct MI300X/MI350 来说,其将 8 个 XCD 加速计算芯粒封装于一体,每个芯粒独享 4MB L2 缓存;NVIDIA Blackwell 同样采用双 Die 设计。硬件架构的深刻裂变,与软件抽象的停滞不前,构成了一对尖锐的矛盾。

Fleet 的研究团队用一组数据揭示了代价:在标准 LLM 解码中,线性层操作占据 95%的时延,但其 L2 命中率仅有 16.4%。这意味着大量权重数据在不同芯粒的 L2 中被重复加载,HBM 带宽被低效消耗。
Fleet 的核心洞察在于:问题的根源不在于缓存容量不足,而在于缺乏一种能够“感知”并“利用”芯粒边界进行协同调度的编程抽象。其给出的解决方案是引入 Chiplet-task——一个精确映射到 XCD 边界的任务层级,并通过持久化内核运行时实现芯片粒感知的协同执行。
实验结果令人瞩目:在 AMD Instinct MI350 上运行 Qwen3-8B,Fleet 表现为:
- 在批大小为 1-8 时将每 token 解码延迟降低至 vLLM 的 1.3-1.5 倍;
- 在批大小 32 时,通过协同权重分块,L2 命中率从 12%跃升至 54%,HBM 读流量减少 37%,相对芯片粒无感知基线提速 1.27-1.30 倍。
这不仅是 LLM 推理的一次性能跃升,更是指向了一种全新的 GPU 编程范式:将内核视为一个持久运行的微型操作系统,在硬件边界内精细调度任务与数据。
一、架构断裂:当“单片思维”撞上“芯粒现实”
表 1 揭示了 GPU 内存层次与编程抽象之间的映射断裂。
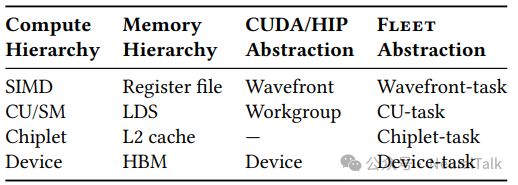
在单片 GPU 时代,每个硬件层次都有清晰的软件对应:SIMD 对应寄存器,CU/SM 对应 LDS 共享内存,设备对应 HBM 全局内存。L2 缓存作为设备级资源,被所有 CU 平等访问,程序员无需关心数据驻留位置。
而多芯粒架构打破了这一对称美。
以 AMD CDNA3/CDNA4 架构为例,8 个 XCD 各自拥有私有的 4MB L2 缓存,L2 从“设备级”降格为“芯粒级”资源。然而 HIP 编程模型对此一无所知——它仍将设备视为扁平的整体,将工作组随机分配到各 XCD,导致同一份权重数据在不同芯粒的 L2 中被重复缓存,既浪费了宝贵的 L2 空间,又产生了冗余的 HBM 流量。

理解这一断裂需要深入芯片的访存路径。当 XCD i 上的 CU 发起一次全局内存加载时,请求首先查询本地 L2。若未命中,请求穿越 Infinity Fabric 到达 IO Die,再路由至 HBM 或持有脏数据的对等 XCD。AMD 的缓存一致性由内存指令中的范围位(SC1, SC0)和非时序位(NT)控制。默认的波前范围(SC1=0, SC0=0)下,L2 将数据视为 XCD 本地所有——不发出跨 XCD 一致性探测,也不使对等 XCD 上的陈旧副本失效。这意味着若两个不同 XCD 上的 CU 读取同一权重行,数据将从 HBM(或 MALL)获取两次,并分别缓存于两个 L2 分区。更隐蔽的代价在于:内核边界处的设备级同步(如 buffer_wbl2 栅栏)会强制刷新脏缓存行以确保跨 XCD 可见性,这使得内核间无法保留 L2 中的权重数据,每次算子调用都需从 HBM 重新加载。
这种“架构-编程模型”断裂在 LLM 解码场景中被急剧放大。Qwen3-8B 每层权重矩阵总大小 368MB(bf16),而批大小 128 时的激活矩阵仅 1MB——权重加载主导了内存流量。vLLM 等标准服务系统为每个算子启动独立内核,单 token 解码跨越 36 层需要近 250 次内核调用。每次调用后 L2 内容被清空,下一算子被迫从 HBM 重新加载所有权重。
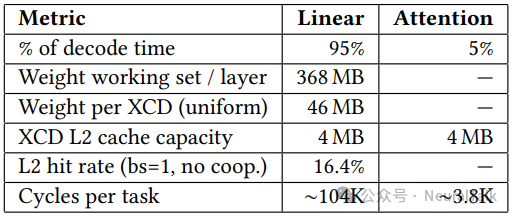
表 2 的数据佐证了问题的严重性:线性层操作占据 95%的解码时延,但在无协同调度下,XCD 的 4MB L2 仅能捕获 16.4%的命中率,每个任务的周期数高达约 104K。这组数据暴露了一个残酷事实:即便拥有 5.3TB/s 的 HBM 带宽,糟糕的 L2 利用率仍使实际性能远低于硬件潜力。
二、Fleet 任务模型:为内存层次“量体裁衣”
表 3 展示了 Fleet 的四级任务层次,其设计哲学朴素而深刻:任务应在与其资源需求相匹配的硬件粒度上编写。
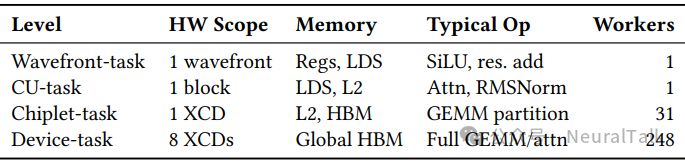
Fleet 的多层次打破了传统 GPU 编程中“一刀切”的网格调度模式,将控制权交还给程序员,使其能够显式地将算子映射到特定的内存范围。从波前任务到设备任务,每一级都精确锚定一个硬件边界:
- 波前任务在 64 线程内利用寄存器和 LDS 执行逐元素操作;
- CU 任务占据单个计算单元,通过 LDS 进行块内通信;
- 芯粒任务是 Fleet 的核心创新,将 XCD 上所有 worker (31 个 CU)编组为单一执行单元,显式管理 4MB L2 预算;
- 设备任务则协调 8 个芯粒任务,在全局 HBM 层面聚合结果。
这种分层设计不仅恢复了被扁平编程模型掩盖的内存拓扑信息,更为后续的协同优化提供了“脚手架”。
2.1 Chiplet-task:芯粒级抽象的深层意义
Chiplet-task 的价值远不止于“多了一个层级”。它所解锁的关键能力是:程序员现在可以精确指定一个 XCD 内所有 worker 在 L2 缓存中的协作模式。
以一个[M,K] × [K,N]的 GEMM 为例,Fleet 将输出矩阵按列划分为 8 个独立子矩阵,每个芯粒任务计算一个[M,K] × [K,N/8] = [M,N/8]的切片。这一划分策略使得:
- 每个芯粒处理独立的权重列分区,无需跨 XCD 同步即可完成其分配的计算;
- 芯粒内的 31 个 worker 可以围绕同一权重分片进行协同缓存访问——第一个 worker 从 HBM 加载权重块到 L2,后续 worker 直接从 L2 命中;
- 不同芯粒间的缓存完全隔离,消除了虚假共享和一致性开销。
这一设计的精妙之处在于它同时解决了三个问题:
- 通过列向划分消除了跨芯粒通信需求(N 维分割天然无依赖)
- 通过芯粒内协同放大了 L2 的有效容量
- 通过将调度单元从 CU 提升至 XCD 减少了任务分派开销
Fleet 的任务依赖通过事件表达,每个芯粒任务只需一个事件即可代表整个 XCD 上所有 worker 的完成状态——这相比逐 worker 的事件模型减少了 W 倍的跨芯粒同步事件数(W=31),这是后文将深入分析的性能增益来源之一。
2.2 协同权重分块:将 L2 命中率从 12%推向 54%的数学逻辑
M-major 遍历是 Fleet 协同权重分块策略的核心。
- 在标准的分块调度中,同一 XCD 上的 worker 被分配处理不同的 GEMM 输出块,各自加载不同的权重列——这导致 L2 缓存被多个不相干的权重流同时冲刷,命中率极低。
- Fleet 的 M-major 窗口化遍历改变了这一模式:芯粒内的每个 worker 先完整计算一个输出块[m,n],遍历所有 K 维度的权重[0:K,n]和激活[m,0:K],然后再推进到下一权重列。这意味着所有 worker 在相近的时间窗口内访问相同的权重列,形成一种“流水线式”的 L2 复用。
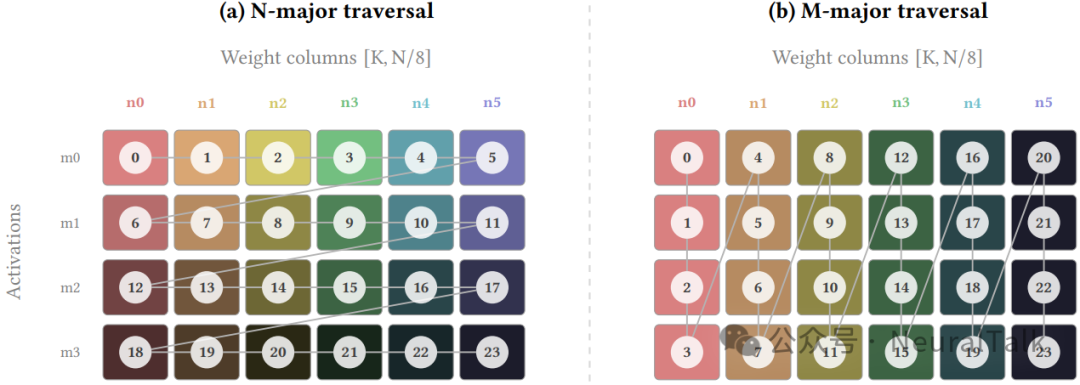
这一策略的数学本质可以用一个简洁的模型刻画。设 $W_{worker}$ 为共享同一权重块的芯粒内 worker 数量,其中 $W_{xcd}$ 是每个 XCD 的 worker 数(MI350 上为 31),$m_{tiles}$ 是沿批维度的分块数。
在 M-major 遍历下,预期 L2 命中率为:
$命中率 = 1 - \frac{1}{W_{worker}} = 1 - \frac{1}{W_{xcd} / m_{tiles}}$
这个公式揭示了两个关键洞察:
- 当批大小较小时(如 bs=1,$m_{tiles}=1$),$W_{worker}=31$,模型预测零权重复用,实际测得的约 17%命中率源于融合算子(如 SiLU 与 GEMM 融合)带来的激活数据复用,而非权重共享;
- 当批大小增至 32($m_{tiles}=2$),$W_{worker}=15.5$,理论命中率跳升至 50%,实测 51.0%,与模型高度吻合;
- 当批大小继续增至 64($m_{tiles}=4$),$W_{worker}=7.75$,理论命中率 75%,实测 61.4%——差距来自 L2 容量限制导致的权重块相互驱逐。
这一分析表明,Fleet 的优化效果并非玄学调参的结果,而是可预测、可建模的系统行为。它本质上是一种“批大小驱动的时间局部性放大”:通过强制多个 worker 在时间上对齐权重访问模式,将原本平摊到各 worker 的独立访存流,合并为一条被 L2 有效截获的复用流。
2.3 缓存修饰符策略:给 L2 装上“流量指挥灯”
Fleet 对 AMD 缓存修饰符的三层策略运用堪称精妙。CDNA3/CDNA4 架构允许每条内存指令携带范围位(SC1, SC0)和非时序位(NT),精确控制 L2 的分配和逐出行为。Fleet 将流量分为三类并配置差异化策略:
- 权重加载:缓存流式(sc1=1, nt=1)。该策略指示 L2 临时分配缓存行以服务短期复用,但在需要空间时立即标记为可逐出。这恰好匹配权重在 M-major 遍历中的访问模式——权重块被连续的 worker 短时间内密集访问,但不会跨层持久保留。流式策略既捕获了协同复用的窗口,又防止权重污染 L2 中更持久的数据。
- 激活存储:非时序(NT=1)。GEMM 输出、RMSNorm 结果和 SiLU 激活等中间数据绕过 L2 直接写回 HBM。这避免了瞬态数据驱逐正在被协同复用的权重块——在标准缓存策略下,写分配会为每个存储操作分配 L2 行,快速冲刷掉宝贵的权重缓存。
- 调度器通信:差异化范围。跨 XCD 事件轮询使用非时序加载,绕过可能陈旧的 L2 副本直接读取 HBM 中的最新值;XCD 内部通信则使用易失性加载,充分利用共享 L2 的低延迟。
这一策略组合的本质是对 L2 替换策略的“软件定义”改造。在硬件 LRU 策略下,任何访问都会将数据推向 MRU 位置,流式访问和瞬态中间结果很容易相互驱逐。Fleet 通过显式标注每个内存访问的语义意图(复用权重 vs. 一次性激活 vs. 控制消息),使 L2 的行为更接近程序员意图而非硬件启发式规则。论文数据显示,仅将 SiLU 融合进 gate+up GEMM 芯粒任务这一项优化,就将 bs=1 时的 L2 命中率从 9.4%提升至 17.4%——消除了中间缓冲区的读写循环,将激活数据保留在寄存器/LDS 中而不流经 L2。
三、运行时系统设计:一个微型的 GPU 操作系统
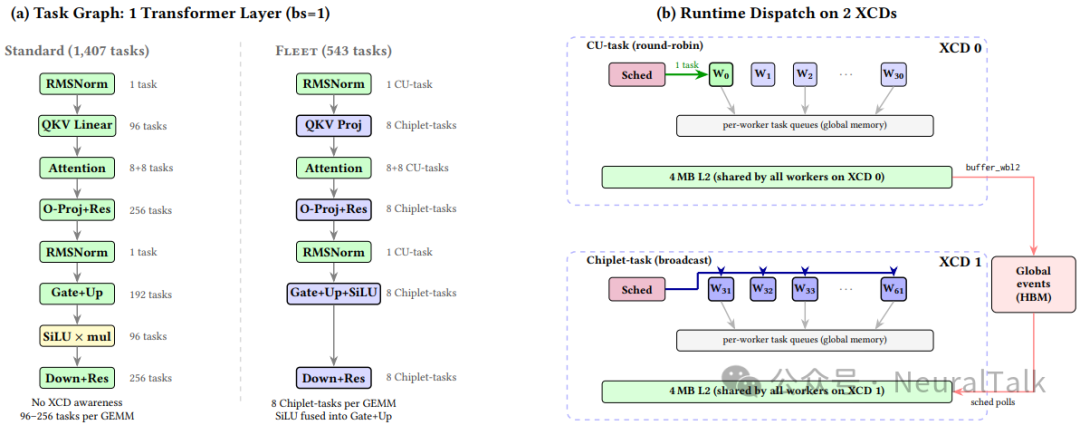
图 4 呈现了 Fleet 系统架构的全貌。(a)部分展示了单个 Transformer 层在 bs=1 时的任务图对比:
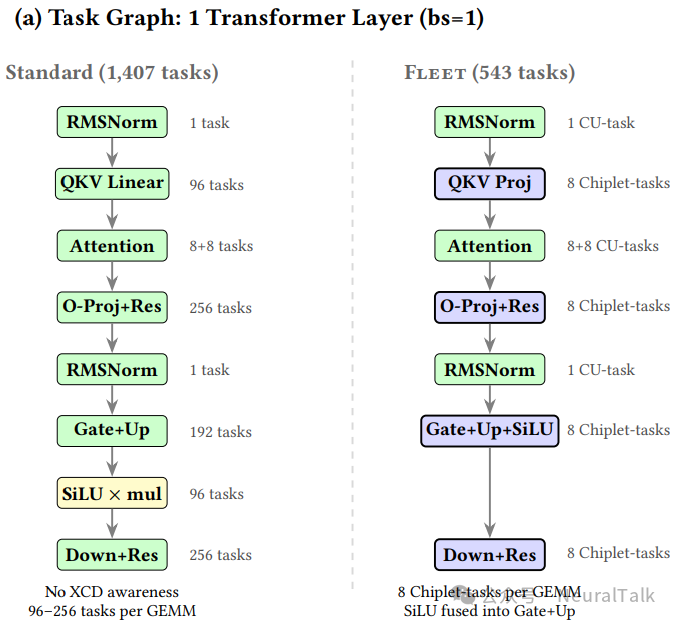
可以看出:
- 标准调度将每个 GEMM 分解为 96-256 个独立的 CU 任务(总计 1,407 个);
- Fleet 仅用 8 个芯粒任务表示每个 GEMM(总计 543 个,减少 2.6 倍),且将 SiLU 融合进 gate+up 芯粒任务。
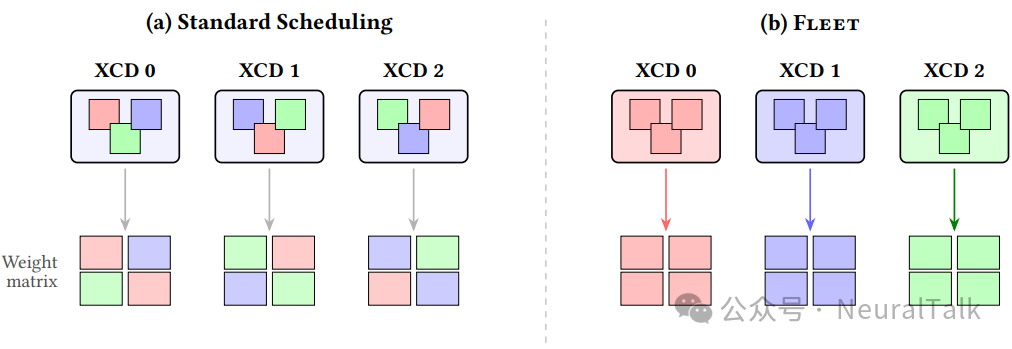
而 图 4(b) 则揭示了运行时调度的核心机制:每个 XCD 有一个调度器工作组,其余作为 worker 。调度器从设备内存中的任务描述符结构拉取任务,并按芯粒本地亲和性进行分发。
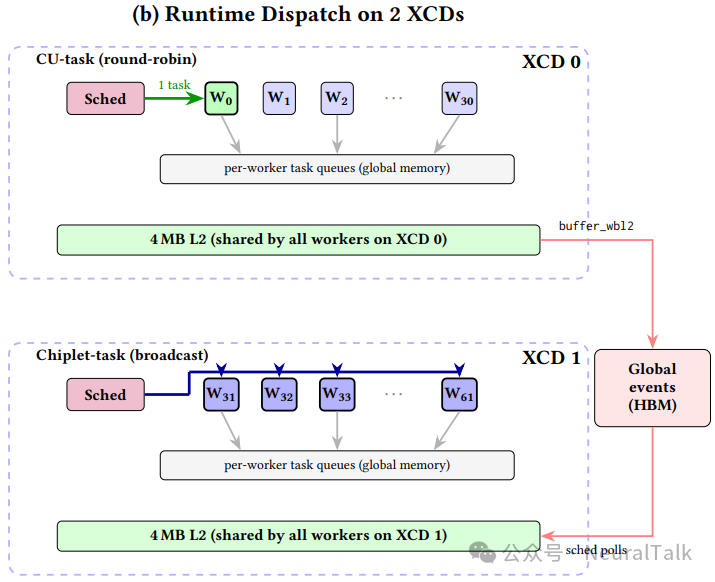
图 5 则详细刻画了分级同步协议的时序逻辑:
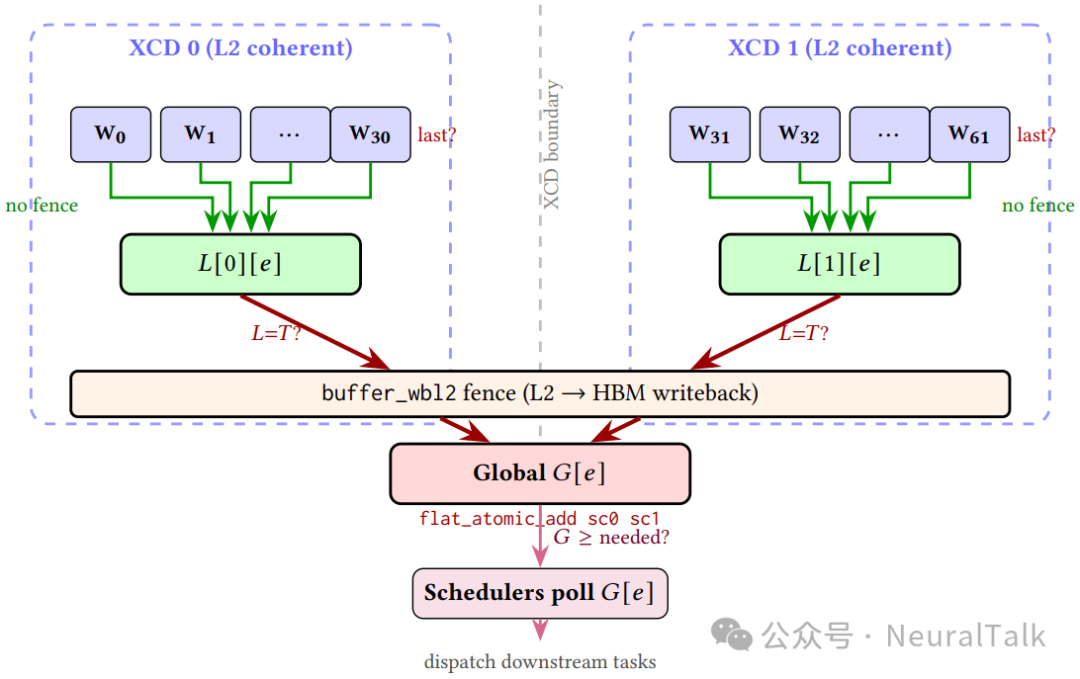
- worker 在 XCD 本地 L2 计数器上累加完成状态,无需栅栏(图中绿色部分);
- 仅每个 XCD 的最后一个 worker 发出单个 buffer_wbl2 栅栏并更新全局 HBM 计数器(图中红色部分);
- 调度器轮询全局计数器以触发下游任务。
这一设计将跨 XCD 栅栏从每 worker 一次降低为每芯粒每事件一次。
3.1 持久化内核运行时:一次性启动,持续运行
Fleet 的运行时延续并深化了 Mirage MPK 的持久化内核理念,但注入了芯粒感知的关键改造。
传统 GPU 编程中,每个算子对应一次内核启动——启动开销包含主机到设备的命令推送、设备端调度器初始化、以及内核完成后的同步。对于 LLM 解码这类需要数百次算子调用的场景,累积开销不容忽视。vLLM 虽通过 CUDA Graph 降低了启动成本,但 Graph 需为每个批大小预先录制,且跨内核的数据复用(尤其是 L2 驻留)因内核边界处的隐式同步而丧失。
Fleet 的解决方案是一次性启动一个占据全部 256 个 CU 的持久化内核,该内核在整个推理生命周期内驻留。具体组织方式为:每个 XCD 指定一个工作组(32 个 CU 中占 1 个)作为调度器,其余 31 个作为 worker 。调度器通过读取硬件 HW_ID 寄存器获知其 XCD 身份,并在全局内存中维护每 worker 任务队列。这 8 个调度器并行工作,各自负责本芯粒的任务分发,形成一种“联邦式调度”拓扑。
一个常被忽视的细节是:调度器占用的 CU(8/256=3.1%)不参与计算。作者指出,由于调度器仅执行轻量级控制操作(计数器读取、队列写入、指针运算), worker 极少因等待任务分配而停顿。但在任务执行时间极短的场景下,调度开销可能成为瓶颈——这为后续优化留下了伏笔。
3.2 分级同步:将跨芯粒栅栏减少两个数量级
分级同步是 Fleet 运行时设计中最具技术深度的部分。理解其价值需要先理解跨芯粒同步的代价。在 MI350X 上,一个设备范围的原子操作必须对所有 8 个 XCD 可见,这需要跨芯粒互联结构的一致性流量,延迟远高于 L2 本地操作。更严重的是,设备范围栅栏(buffer_wbl2)会刷新本地 L2 中所有脏缓存行以确保跨 XCD 可见性——该操作的开销与脏行数量成正比,并阻塞后续内存访问直至刷新完成。
Fleet 的分级同步协议通过匹配通信模式到最窄的充分内存范围,系统性地规避了这些开销:
- 任务队列(只读):任务描述符的全局队列在内核启动前填充完毕,执行期间不可变。 worker 和调度器读取任务元数据无需任何同步。
- 调度器 → worker 分派(L2 本地):调度器使用设备范围存储和原子操作写入本芯粒 worker 的每 worker 队列。由于调度器及其 worker 位于同一 XCD,这些访问在本地 L2 中解析,无跨 XCD 一致性流量。
- worker ↔ worker 协调(L2 本地): 芯粒任务内的 worker 使用设备范围原子操作在每 XCD 计数器上累加子任务完成数。这些操作同样在本地 L2 解析。无需栅栏,因为所有参与 worker 共享同一 L2 分区。
- XCD→ 全局信令(GPU 范围):仅当某 XCD 上最后一个 worker 完成时,才发出单个 threadfence 并更新全局事件计数器(使用 GPU 范围原子操作 flat_atomic_add with sc0 sc1)。这把昂贵的跨 XCD 一致性成本均摊到整个 XCD 的所有 worker 上。一旦全局计数器达到阈值,完成的 worker 将事件入队到负责调度器的队列,触发下游任务。
这一协议的分析价值体现在数量级上:对于芯粒任务,两级计数为每个事件最多触发每个 XCD 一次栅栏,在无任务的 XCD 上则为零次栅栏。Fleet 的线性事件精确对应 8 个任务(每 XCD 一个),因此每个事件仅触发恰好 8 次栅栏。相比之下,若每个 worker 都进行全局信令,将产生 $8 \times 31 = 248$ 次跨 XCD 栅栏——分级同步将其减少了 31 倍。这一减少直接转化为更低的任务切换延迟和更高的调度吞吐。
3.3 任务注册与代码生成:编译器支持
Fleet 的代码生成流程基于 Mirage 编译器扩展。Mirage 在模型加载时将抽象任务图编译为运行时描述,其中包含每个节点的库代码。为生成基于芯粒任务的图,Fleet 向 Mirage 编译器提供不同的输入代码,但暂未启用编译器的超优化搜索——论文明确指出这一方向留待未来工作,仅需为芯粒任务设计合适的成本模型即可。
当算子被分解为芯粒任务时,编译器在代码生成阶段计算每个分块的指针。例如,对于跨 8 个 XCD 的权重分区,任务 k 接收的指针为 base_ptr + k × (N/8) × K × sizeof(bf16)。这意味着 GPU 内核代码无需感知正在执行哪个芯粒任务——它仅读取指向当前数据块的指针。每个芯粒任务内,所有 CU 接收相同的指针,调度器无需在任务分派时进行指针运算。取而代之的是,从 Mirage 编译器发出的调用被修改为包含 XCD 内的分块索引,生成对_execute_xcd_task(tile_idx)的调用,库实现负责根据分块索引为每个 CU 执行不同行为。
这种设计体现了编译器与运行时之间清晰的职责分离:编译器负责静态的数据分区和指针预计算,运行时负责动态的任务调度和同步协调。两者通过简洁的接口(分块索引)耦合,既保持了灵活性,又避免了运行时的复杂指针运算开销。
四、端到端评估:数据背后的技术叙事
图 6 绘制了四条性能曲线的对决:vLLM(外部基线,hipBLASLt GEMM,每算子独立内核)、Mirage MPK(内部基线,持久化内核但芯粒无感知)、Fleet M-split(芯粒任务调度但无协同权重共享)、Fleet M-tile(芯粒任务调度+协同权重共享)。
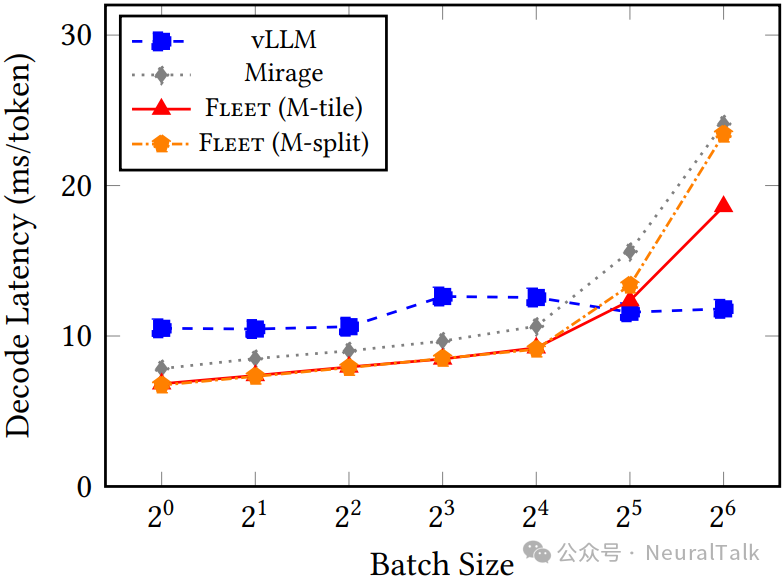
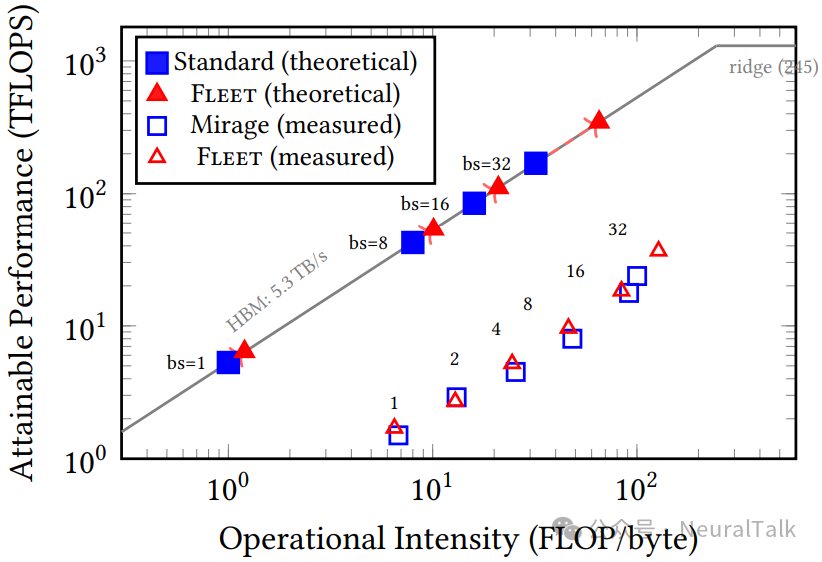
图 7 的 Roofline 分析为这个故事提供了数学注脚:Fleet 的 L2 复用将有效算术强度从名义值 $AI_{nom}=B$(批大小)推高至 $AI_{eff}=B/(1-HR_{L2})$,使操作点在 Roofline 图上向右平移。在 bs=32 时,51%的命中率使有效强度从 32 翻倍至 65 FLOP/字节,将操作从带宽瓶颈区推向计算瓶颈区的边缘。
4.1 实验设置与基线选择
作者在单卡 AMD Instinct MI350X 系统上进行评估。该设备拥有 256 个 CU(分布于 8 个 XCD,每 XCD 32 CU)、每 XCD 4MB L2、256MB 共享 MALL(Infinity Cache)、288GB HBM3。对比两条基线:
- Mirage MPK(移植至 MI350X):芯粒无感知的持久化内核,使用标准 2D GEMM 分块无协同调度。作为内部基线,隔离 Fleet 芯粒感知优化的效果。
- vLLM v0.17.2 on ROCm(--enforce-eager):标准每算子内核启动,无持久化内核。作为外部基线,代表当前服务框架的 SOTA 水平。
性能指标通过 HIP 级计时 API、GPU 片上周期计数器、性能计数器和底层追踪的组合采集。所有端到端延迟结果使用 64 个输入 token 和 1024 个输出 token,报告仅解码 TPOT(每输出 token 时间),通过 GPU 侧每迭代时间戳(s_memrealtime)测量,排除预填充阶段。
4.2 延迟分解:调度开销 vs. L2 复用
在 bs=1 时,vLLM 的 TPOT 为 10.51ms,Mirage MPK 为 7.83ms(1.34 倍加速),Fleet M-tile 和 M-split 分别为 6.82ms 和 6.73ms(相对 vLLM 加速 1.54 倍和 1.56 倍)。这一阶段的加速几乎全部来自持久化内核消除启动开销,以及芯粒任务减少调度器- worker 通信开销。
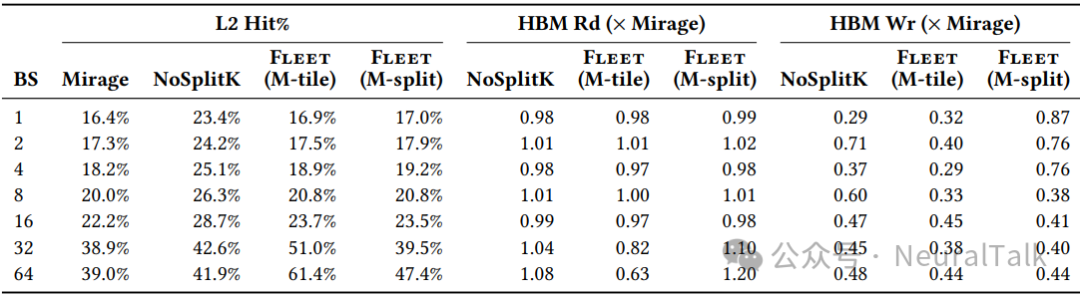
表 4 的数据佐证了这一判断:
- bs=1-8 时,三种配置的 L2 命中率和 HBM 读流量几乎相同(命中率约 16-24%,HBM 读约 2400-2800 GB)。加速源于芯粒任务调度将每 GEMM 的分派从 96-256 次 CU 级调度压缩为 8 次 XCD 级调度。
- 当 bs 增至 32 时,故事发生转折。两者之间的差距(约 1ms)完全归因于 L2 权重复用——M-tile 的 HBM 读流量为 3,190GB(相对 Mirage 的 3,906GB 减少 18%),而 M-split 反而增至 4,295GB。
- m_tiles 从 1 变为 2,协同权重共享激活。M-tile 达到 51.0% L2 命中率,相对 Mirage 提速 1.27 倍(12.35ms vs. 15.62ms);
- M-split 仅达到 39.5%命中率,加速降至 1.17 倍(13.37ms)。
- bs=64 时,协同复用的主导地位更加显著。
- M-tile 的命中率攀升至 61.4%,TPOT 降至 18.61ms(相对 Mirage 24.10ms 提速 1.30 倍),HBM 读流量从 6,203GB 锐减至 3,925GB(降幅 37%)。
- M-split 则跌落至几乎与 Mirage 持平(23.40ms,1.03 倍加速),HBM 读流量增至 7,426GB。
值得注意的是,在 bs≥32 时,vLLM 的延迟曲线趋于平坦(约 11-12ms),因为 hipBLASLt 的 GEMM 内核采用了波级 K-split 优化,在计算密集区表现优异。Fleet M-tile 在 bs=32 时仍比 vLLM 快 1.06 倍,但在 bs=64 时被反超——论文坦承其持久化内核的 GEMM 实现尚未集成 K-split 优化和注意力优化。这一局限性在“进阶分析”部分将被深入审视。
4.3 Roofline 视角下的优化本质
Roofline 分析为 Fleet 的优化提供了宏观框架下的解释。名义算术强度 $AI_{nom}=B$ FLOP/字节(批大小即每加载一字节权重所执行的浮点操作数)。在标准调度下,bs=32 时的 AI 为 32,远低于 MI350 的脊点(约 245),操作被内存带宽瓶颈牢牢限制。
Fleet 的 L2 复用改变了有效算术强度的计算方式。设 $HR_{L2}$ 为 L2 命中率,则实际从 HBM 加载的权重比例降为 $1-HR_{L2}$。有效算术强度变为:
$AI_{eff} = \frac{B}{1 - HR_{L2}}$
当 bs=32 且 $HR_{L2}=0.51$ 时,$AI_{eff}=65$,是名义值的两倍。操作点在 Roofline 图上向右平移,更接近计算瓶颈区。下图 7 中的实测点(空心标记)与理论预测(实心标记)高度吻合,验证了这一分析框架的有效性。
从 Roofline 视角看,Fleet 的优化本质是“通过缓存复用将访存密集型操作伪装成计算密集型操作”。它并未改变硬件的峰值带宽或算力,而是通过减少有效 HBM 流量,使操作在 Roofline 图上的投影位置发生横向位移。这一洞察的价值超越了 LLM 推理本身——任何具有数据复用机会但在扁平调度下被带宽瓶颈限制的工作负载,都可能从类似的芯粒感知调度中获益。
4.4 每 GEMM 权重分析与 L2 命中率模型验证
表 5 列出了 Qwen3-8B 每层四个 GEMM 的权重尺寸。
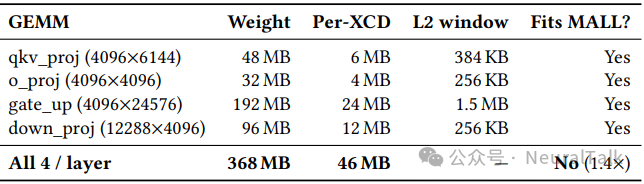
qkv_proj、o_proj、gate_up、down_proj 的每 XCD 分区分别为 6MB、4MB、24MB、12MB。这些分区尺寸无一能完整装入 4MB L2。然而,协同分块的关键在于:实际驻留在 L2 中的是“活跃工作集”——每个 worker 当前处理的 K 维分块(约 32KB),31 个 worker 合计约 1MB,远小于 L2 容量。
表 5 还回答了一个关键问题:MALL(256MB Infinity Cache)能否容纳所有权重? 所有四层 GEMM 的每 XCD 权重总和为 46MB,8 个 XCD 合计 368MB,超出 MALL 容量(256MB)1.4 倍。这意味着 MALL 无法作为权重的完全驻留层,L2 的协同复用仍至关重要。
公式(1)的命中率模型在实验数据中获得了良好验证。
- bs=1($m_{tiles}=1$)时模型预测零复用,实测 17%来自融合算子带来的激活复用(未融合时约 9%);
- bs=32($m_{tiles}=2$)时模型预测 50%,实测 51%;
- bs=64($m_{tiles}=4$)时模型预测 75%,实测 61%。
差距源于 L2 容量限制导致的权重块相互驱逐,这是模型未考虑的二级效应。
Fleet 通过 Chiplet-task 抽象和 M-major 协同权重分块,在 MI350 上将 Qwen3-8B 的解码延迟降低至 vLLM 的 1.3-1.5 倍(bs=1-8),并在 bs=32 时将 L2 命中率从 38.9%提升至 51.0%, HBM 读流量减少 18%,相对芯粒无感知基线提速 1.27 倍。
Roofline 分析揭示了优化的本质:通过缓存复用将有效算术强度翻倍,使操作从带宽瓶颈区向计算瓶颈区平移。
五、相关工作:在“图计算”与“芯粒感知”的交叉点上
Fleet 的研究贡献需要置于三条技术脉络的交叉点上审视:LLM 推理的 Megakernel 化、GPU 缓存感知调度、以及芯粒架构下的系统软件适配。本节通过对比分析,厘清 Fleet 与现有工作的继承、差异与突破。
5.1 Megakernel 路线:从 FlashAttention 到全模型融合
Megakernel 范式在 LLM 推理中的演进路径清晰可循。
- FlashAttention 开创了 IO 感知的算子融合先河,将注意力机制的多个步骤融合为单一内核,显著减少了 HBM 读写。
- HazyResearch 的 Megakernel 将这一思路推向极致——将整个 Llama 解码器融合进一个持久化内核,通过片上 GPU 解释器编排算子执行,在 bs=1 时达到 H100 内存带宽的 78%。
- FlashFormer 采用类似的全模型融合方案,使用流水线共享缓冲区。
- Mirage MPK 引入编译器生成的任务图和事件驱动同步,在 A100/H100 上相对 SGLang/vLLM 取得 1.0-1.7 倍加速。
这些工作的共同前提是“单片 GPU 假设”——它们都面向具有统一 L2 缓存的 NVIDIA GPU,无需考虑芯粒边界。Fleet 的价值不在于发明了 Megakernel 或持久化内核,而在于识别出当这一范式迁移至芯粒架构时,扁平的任务调度将导致严重的 L2 碎片化和利用率塌陷。Fleet 的芯粒任务调度是对 Megakernel 范式的“架构适配层”,使其能够跨越从单片到芯粒的硬件断层。
5.2 缓存感知与芯粒感知调度:从启发式到显式控制
线程块交错调度和 CUTLASS 持久化 GEMM 通过调整工作组访问模式来改善 L2 复用,但它们假设统一的 L2 缓存。
- HipKittens 将 ThunderKittens 移植至 AMD CDNA3/CDNA4,引入 XCD 分组机制,在独立 GEMM 上取得最高 19%的提升。
然而,这些方法都局限于“每内核”优化——它们优化的是单个内核内的 L2 行为,无法跨算子保留缓存状态。
Fleet 的突破在于将芯粒感知从“单内核优化”提升至“全模型持久化运行时”层面。它通过分级同步协议,使得权重数据能够在跨越多个算子的持久化内核生命周期中驻留于 L2,而不被内核边界处的栅栏冲刷。这一能力是独立内核优化无法企及的——因为内核边界本身就是状态破坏性的。
5.3 线程块集群与拓扑感知执行:硬件支持的可能性
NVIDIA 在 Hopper/Blackwell 中引入的线程块集群提供了一定的硬件支持:协同调度同一 GPC 上的块,提供集群范围栅栏和 DSMEM 共享,以及 TMA 多播。然而,GPC 是比芯粒更细的粒度,且缺乏与 L2 层级的直接对应。Fleet 的芯粒任务模型允许线程跨整个 L2 范围协调,且完全以软件实现,不依赖特定硬件特性。
两者的关系是互补而非竞争:线程块集群为更细粒度的协作提供硬件加速,Fleet 为更粗粒度的芯粒级协调提供软件抽象。未来的 GPU 架构若能将 Fleet 式的芯粒感知原语固化为硬件支持,将可能进一步降低同步开销。
5.4 LLM 服务系统:vLLM 与 SGLang 的局限
vLLM(PagedAttention)和 SGLang(RadixAttention)作为主流开源服务框架,在内存管理和请求调度层面贡献卓著。然而,也存在如下局限:
- 它们在内核执行层面依赖 CUDA/HIP 图捕获或直接调用 rocBLAS/hipBLASLt。
- 图捕获虽然减少了启动开销,但仍需为每个批大小单独录制,且内核边界处的 L2 刷新不可避免。
- 底层库虽可实现某些 L2 优化,但难以表达应用级的数据局部性意图。
Fleet 与这些服务系统的关系是“互补的层次”:vLLM/SGLang 管理“哪些请求一起处理”(批形成、KV 缓存管理),Fleet 管理“如何在芯片上执行这些批次”(芯粒级任务调度、L2 协同复用)。两者可以集成——服务系统将批处理好的请求交给 Fleet 持久化内核执行,享受其芯粒感知优化,同时保留上层调度灵活性。
5.5 Mirage 超优化器:融合什么 vs. 调度何处
Fleet 直接构建于 Mirage 的 MPK 运行时之上,但添加了芯粒感知维度。两者的分工清晰:Mirage 的 muGraph 超优化决定“哪些算子应该融合”,Fleet 决定“融合后的任务应该调度到哪个芯粒、以何种协同模式执行”。论文明确指出两者的互补性,并提到编译器驱动的超优化(仅需为芯粒任务设计成本模型)是未来工作方向。
这一分工折射出 AI 编译器领域的一个深层趋势:优化决策正从“单一层级”向“跨层级协同”演进。传统编译器关注指令级和寄存器级优化,Mirage 将优化提升至算子图级,Fleet 进一步将硬件拓扑信息(芯粒边界、L2 分区)纳入优化空间。这种“从逻辑到物理”的优化粒度下沉,是弥合软件抽象与硬件实现之间日益扩大的鸿沟的必然路径。
六、结论与展望
6.1 结论总结
Fleet 提出并验证了一套面向多芯粒 GPU 的层次化任务模型与运行时系统。其核心贡献体现在三个层面:
抽象层面:引入 Chiplet-task 作为编程模型的新原语,填补了 CU/workgroup 与设备/grid 之间的语义空缺。这一抽象将芯粒边界从“隐式的性能影响因素”提升为“显式的可编程资源”,使程序员能够精确控制工作组在 L2 缓存中的协作模式。
机制层面:设计了分级同步协议,将跨芯粒栅栏数量从每 worker 一次压缩至每芯粒每事件一次(减少 31 倍)。通过将同步范围精确匹配到通信需求(L2 本地用于芯粒内协调,GPU 全局仅用于跨芯粒汇聚),系统性规避了芯粒架构下昂贵的一致性流量。
算法层面:提出 M-major 窗口化权重遍历策略,使同一芯粒内的多个 worker 在时间窗口内对齐权重访问,将 L2 命中率从 12-39%提升至 51-61%。Roofline 分析揭示该策略的本质是将有效算术强度翻倍,使操作从带宽瓶颈区向计算瓶颈区平移。
在 AMD Instinct MI350X 上,Fleet 将 Qwen3-8B 的解码延迟降低至 vLLM 的 1.3-1.5 倍(bs=1-8),相对芯粒无感知基线提速 1.27-1.30 倍(bs=32-64)。这些数据证明,软件管理的调度能够在无需硬件改动的情况下,有效恢复被芯粒架构碎片化的 L2 局部性。
6.2 进阶分析
抛开论文作者的自然倾向,从问题解决的底层逻辑进行冷峻审视,Fleet 的工作存在若干需要坦诚面对的边界条件与潜在问题。
根本性 vs.缓解性
Fleet 是否从根本上解决了芯粒 GPU 的 L2 割裂问题,还是在特定假设下的阶段性缓解?
答案是后者。Fleet 的核心策略——M-major 遍历与协同分块——依赖于一个关键前提:批大小足够大,使得 $m_{tiles} > 1$,从而 $W_{worker} < W_{xcd}$,协同复用方能激活。当 bs=1 时(这是 LLM 服务中常见的交互式场景),$m_{tiles}=1$,权重复用完全无法发生,加速仅来自调度开销的降低。
论文数据显示 bs=1 时 Fleet 的 L2 命中率为 16.9%,与 Mirage 的 16.4%几乎持平。这意味着 Fleet 对“内存墙”的根本性突破仅存在于批处理场景,而在对延迟最敏感的单请求场景中,其优化效果并未触及 L2 复用这一核心机制。真正根本性的解决方案可能需要硬件层面的变革——例如支持跨芯粒的 L2 共享或一致性协议优化。
方法论边界与隐性成本
论文实验设计存在若干未充分讨论的边界条件。
- 第一,所有评估基于单 GPU、单模型(Qwen3-8B 密集架构)。对于需要张量并行的更大模型、MoE 架构的稀疏模型、或混合精度(FP8/INT8)场景,Fleet 的芯粒分区策略是否依然有效,尚无数据支撑。
- 第二,论文坦承持久化内核将所有任务类型编译进单一函数,导致寄存器压力将占用率压制为每 SIMD 单波,丧失了波切换的延迟隐藏能力。“每一 L2 未命中直接阻塞 MFMA 流水线”这一代价的量化分析缺席——我们不知道在更差 L2 命中率的场景下,这种占用率损失是否会反噬性能。
- 第三,调度器占用的 8 个 CU(3.1%算力)在论文中被轻描淡写,但在算子执行时间极短的情况下(如逐元素激活),调度开销可能从“可忽略”变为“主导性”。
性能反超的场景分析
图 6 中最引人注目但未获充分讨论的现象是:在 bs=64 时,vLLM 的延迟(约 11.5ms)反超了 Fleet M-tile(18.61ms)。
作者将此归因于“持久化内核的 GEMM 实现尚未集成 K-split 优化”。这暴露出一个深层问题:Fleet 的软件调度栈在追求跨算子 L2 驻留的同时,牺牲了在单个 GEMM 内核内部的极致优化能力(如波级 K-split、自动调优的分块尺寸)。这构成了一种“跨算子复用 vs. 单算子极致”的张力——当批大小增大到使单算子成为计算瓶颈时,算子内部的优化优先级上升,Fleet 的持久化融合策略可能不再是帕累托最优。
这一洞察的推论是:最优策略可能是混合式的——在小批大小下使用 Fleet 式持久化融合,在批大小突破阈值后切换至 hipBLASLt 式独立优化内核。这种自适应调度在论文中未被探讨。
可移植性的“软硬边界”
Fleet 对 AMD 缓存修饰符(sc1/nt 位)的依赖意味着其 L2 策略高度绑定 CDNA3/CDNA4 架构。NVIDIA Blackwell 虽有多 Die 设计,但其缓存一致性模型和内存指令修饰符与 AMD 有本质差异。
作者声称“任何具有分区 L2 缓存的芯粒 GPU 都可实现 Chiplet-task”,这一论断在抽象层面成立,但在具体实现层面掩盖了大量平台相关的适配工作——同步原语、缓存控制指令、调度器硬件 ID 获取方式,都需要逐平台重新实现。
6.3 未来工作
原文计划
论文在多个位置明确指出了未来研究方向:
- 编译器驱动的超优化:当前 Fleet 依赖手工编写输入代码来生成芯粒任务图,未启用 Mirage 的 muGraph 超优化搜索。论文指出,仅需为芯粒任务设计合适的成本模型,即可将超优化扩展至芯粒感知维度。
- 张量并行的多 GPU 评估:当前实验限于单 GPU。论文提出,张量并行(TP)先将权重矩阵跨 GPU 分片,Fleet 再在每个 GPU 内部进行芯粒级分区。两者自然组合(TP 是跨 GPU 分区,Fleet 是 GPU 内分区),但缺乏实测验证。
- 预填充性能评估:论文仅评估了解码阶段(内存瓶颈),未涉及预填充阶段(计算瓶颈)。芯粒感知调度在计算密集场景下的效果是未解问题。
- 寄存器压力缓解:论文承认持久化内核的寄存器占用限制了波级并行度。提出的潜在解决方案包括:每任务独立编译(但会牺牲单次启动特性),或硬件支持动态寄存器分配(如 AMD RDNA 架构中的图形工作负载特性)。
- MLIR 集成:论文提出将 Fleet 的芯粒感知调度与 MLIR 内核编译器集成,在统一 IR 中共同表达芯粒感知调度和分块级代码生成。
延伸视角
从更宏观的领域趋势与技术瓶颈出发,Fleet 的成果可能在以下方向催生新的研究路径:
- “可编程内存层次”编程模型:Fleet 的核心贡献实质上是将 L2 缓存从“透明的硬件自动管理资源”转变为“可显式寻址和控制的软件管理资源”。这一思路若推广至整个内存层次——包括 MALL(Infinity Cache)、HBM、甚至跨设备的 NVMe 缓存——可能催生一种新的编程范式:程序员以“内存范围”为第一公民组织计算,运行时系统负责在这些范围间编排数据移动与任务调度。 这与当前流行的“Triton 式”分块编程形成有趣的对比与互补。
- 自适应融合策略:作者揭示的“小批融合占优,大批独立占优”现象指向一个更通用的研究问题:如何根据运行时特征(批大小、序列长度、硬件拓扑)动态选择融合粒度?一个可能的方向是在持久化内核中内置轻量级性能模型,在每次迭代前评估是“保持融合”还是“切换到独立优化内核”。 这本质上是将 Fleet 的静态任务图扩展为“动态可重配置任务图”。
- 芯粒架构的软硬件协同设计:Fleet 完全以软件方式实现芯粒感知,证明了软件的灵活性足以弥补硬件抽象的缺失。但这也引发反向思考:未来的 GPU 架构是否应该提供更直接的硬件支持?例如:硬件管理的芯粒本地任务队列、跨芯粒的轻量级栅栏、可编程的缓存分区策略。Fleet 的设计为这类硬件特性的价值提供了“存在性证明”和量化依据。
- 稀疏模型与 MoE 的芯粒感知:当前评估限于密集模型。在 MoE 架构中,专家的稀疏激活天然具有“数据并行”特性——不同专家可以驻留在不同芯粒的 L2 中,门控网络将 token 路由至对应芯粒。这种模式与 Fleet 的芯粒任务抽象高度契合,可能实现比密集模型更显著的加速比。
- 持久化内核的安全性与隔离性:当 GPU 被多个租户共享时(如云环境),持久化内核的长时间驻留特性带来了新的安全挑战——如何防止一个租户的持久化内核通过侧信道(如 L2 缓存竞争)泄露另一个租户的信息?Fleet 未涉及多租户场景,但这是其走向生产环境的必经之路。
Fleet 的价值不仅在于 LLM 推理的 30-50%加速,更在于它揭示了 GPU 编程模型演进的一个必然方向:当硬件进入“联邦制”的多芯粒时代,软件抽象必须从“扁平化”走向“层次化”,从“硬件透明”走向“拓扑感知”。Chiplet-task 是这一方向上的第一个显式原语,但绝不会是最后一个。对于希望深入理解现代 计算机架构 与高性能计算编程范式的开发者而言,这类前沿研究提供了宝贵的洞察。更多关于 大语言模型 推理优化与底层系统设计的深度讨论,欢迎在云栈社区继续交流。
 发表于 2026-4-23 04:15:32
|
查看: 177|
回复: 0
发表于 2026-4-23 04:15:32
|
查看: 177|
回复: 0
