云原生技术与AI基础设施的深度融合,使得大模型在 Kubernetes 上的生产级部署成为了当前行业的核心课题。在千亿参数模型日益普及的今天,单机显存早已无法承载,TP(张量并行)与PP(流水线并行)已成为分布式推理的标配。然而,这种分布式范式的转变,也让习惯于处理无状态微服务的Kubernetes原生工作负载抽象(如Deployment/Service)显得力不从心。
在KCD Beijing + vLLM 2026大会上,相关技术专家分享了《云原生架构下分布式大模型推理的编排与调度实践:从PD分离到拓扑感知的全链路优化》。本文将基于会议内容,深度解析 Kthena 与 Volcano 的协同架构如何解决多角色拓扑依赖、状态感知缺失等核心难题,从而构建稳定、高效的生产级大模型推理服务。


分布式大模型推理的云原生痛点
当前,基于原生Kubernetes部署大模型推理服务,主要面临三大工程挑战:
1. 多维度拓扑约束缺失
TP并行组内需要进行高频的all-reduce通信,这对网络延迟极度敏感。K8s原生调度器极易将同一并行组的Pod打散到不同物理节点,甚至跨越骨干网。高昂的跨交换机通信延迟会直接吞噬模型并行带来的性能红利,严重拖垮吞吐量等核心SLA指标。
2. PD分离架构下的编排断裂
为优化长上下文处理效率,业界普遍采用Prefill(计算密集型)与Decode(访存密集型)分离架构。由于K8s缺乏多角色原子化编排能力,这两种负载特性截然不同的角色难以实现独立的精细化弹性扩缩。单一角色的配比失衡极易导致整体推理链路拥塞或服务中断。
3. 流量网关的“状态盲区”
提升长文本推理效率的核心在于复用KV Cache。然而,K8s原生的Ingress或Service均为无状态设计,无法感知各个Decode实例GPU显存中的Cache分布状况。如果采用轮询等传统策略盲目分发请求,会导致Cache命中率骤降,引发大量的重复计算和资源浪费。
Kthena:声明式 LLM 编排底座
面对上述挑战,Volcano社区推出了 Kthena 项目。Kthena通过深度集成Volcano的批处理调度能力,将复杂的分布式推理任务转化为具备拓扑约束的原子调度单元,并结合智能路由框架实现从调度到流量的完整闭环。
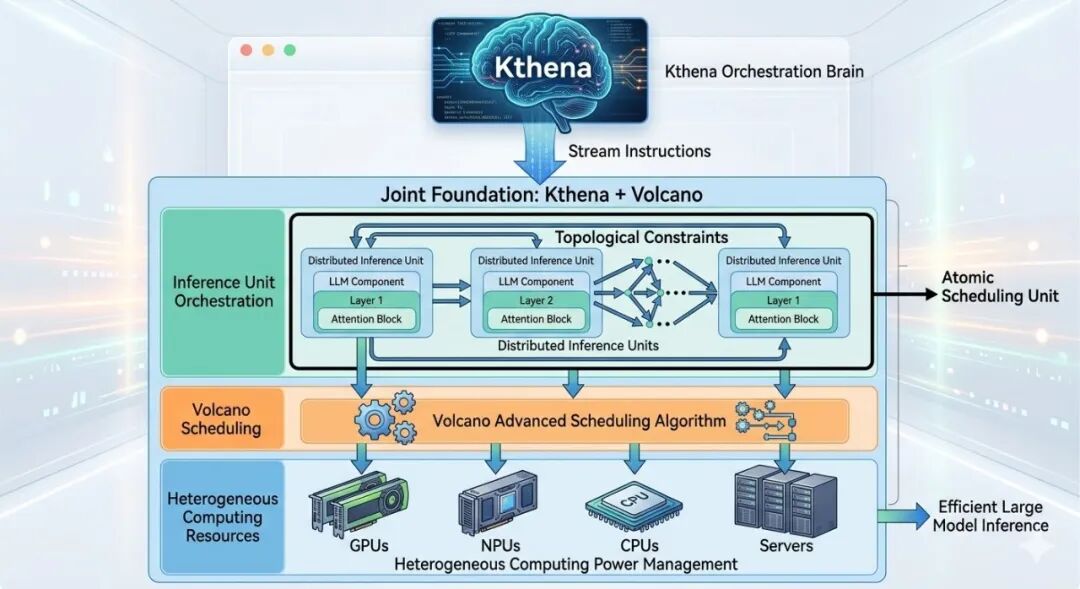
Kthena + Volcano 联合架构
ModelServing:专为LLM设计的负载建模
ModelServing是Kthena架构中承载实际推理计算任务的执行单元,通常是运行着vLLM-Ascend等先进推理引擎的容器化Pod。其负载建模分为三层,充分考虑了分布式大模型推理的复杂性。
ModelServing 三层架构
- ModelServing层:定义整体推理服务,管理多个ServingGroup实例,负责全局拓扑感知调度与Gang Scheduling。用户只需声明需要多少个Prefill和Decode实例,该层会自动处理这些实例的生命周期。
- ServingGroup层:是独立完成一次推理任务的最小原子单位(例如,一个Prefill节点与多个Decode节点组成一个Group),支持平滑重构,能够在服务升级或配置变更时降低中断风险。
- Role层:定义具体的功能角色,如Prefill或Decode,支持Entry/Worker双Pod模板设计,优化了节点内的通信效率。
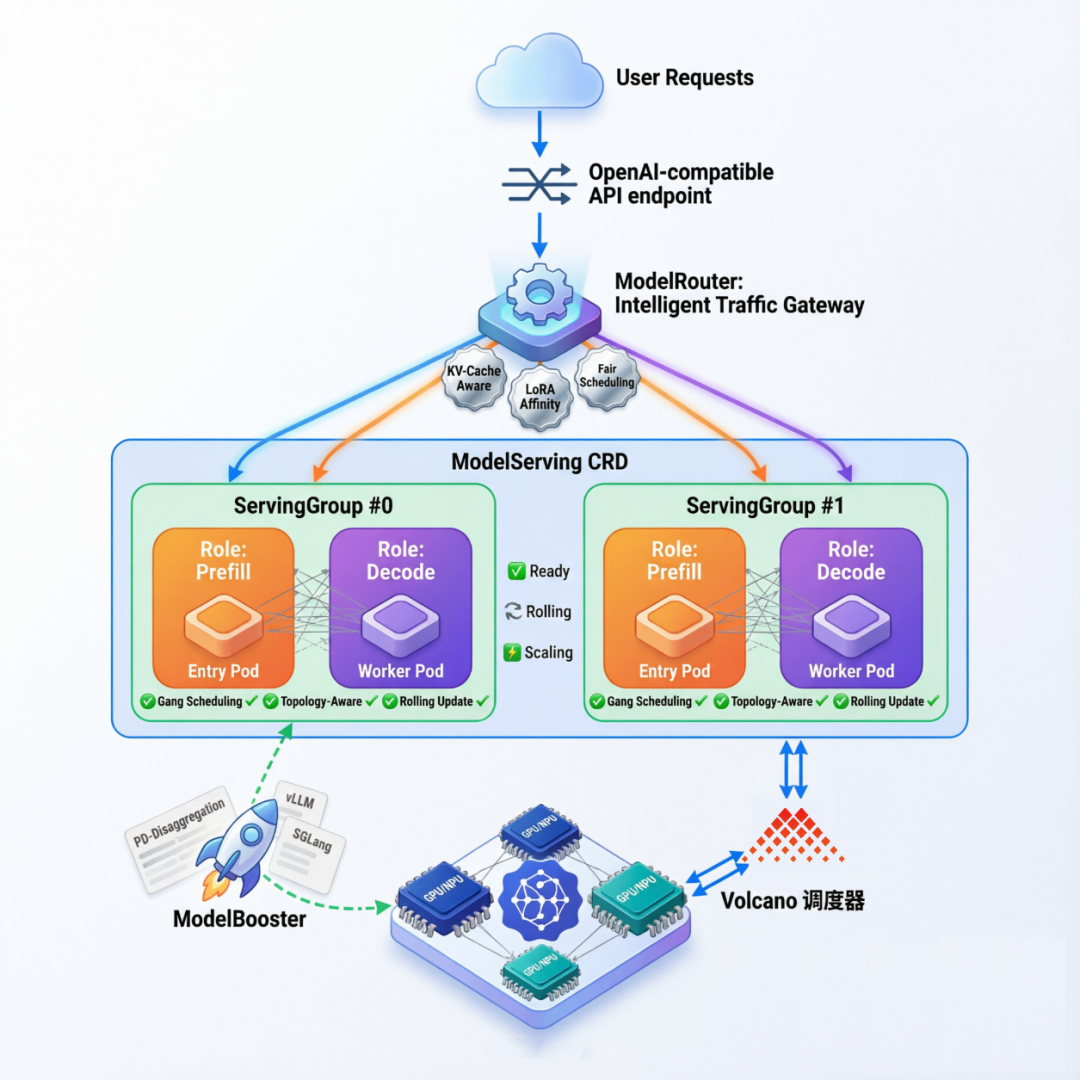
Kthena Router:云原生LLM推理的智能流量枢纽
Kthena Router是整个系统的智能流量枢纽,其核心智能化体现在多个维度:
- 智能请求路由:支持基于模型名称、自定义Header或URI模式的精准转发,内置Least Request、Random等多种插件化评分算法。
- PD分离原生支持:可将Prefill和Decode阶段的路由请求智能分发到不同的专用推理实例,极大提升异构硬件的利用率。
- KV Cache感知(核心能力):通过ScorePlugin机制,Router能优先将具有相同前缀的请求路由到存有对应KV Cache的节点。具体实现上,它会收集各Decode实例的Cache信息,构建“知识图谱”。当新请求到来时,计算其Token序列与每个实例Cache的重叠度(block matching),并选择能带来最大缓存命中收益的实例。实验证明,该策略可将吞吐量提升达2.7倍,首字延迟(TTFT)降低约73.5%。
- 企业级能力:支持LoRA适配器热插拔与按需路由、Token级限流、灰度发布及故障自动转移。
Kthena Autoscaler:面向大模型推理的智能弹性伸缩
传统的Kubernetes HPA主要基于CPU/内存使用率,这对于复杂的大模型推理负载是远远不够的。Kthena Autoscaler的设计理念是深度感知推理服务的独特负载模式。
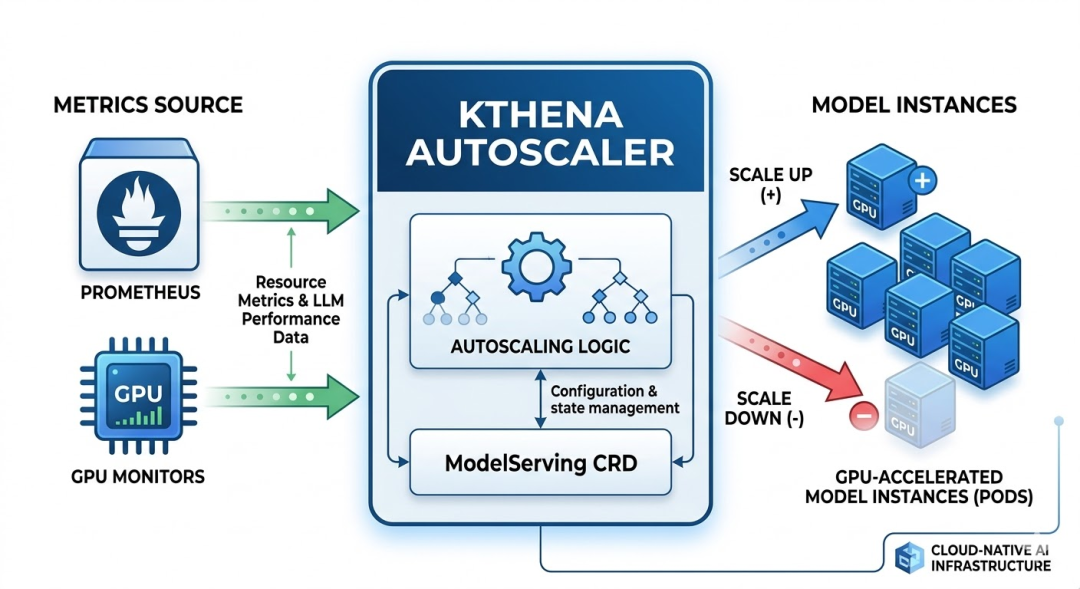
Kthena Autoscaler 弹性伸缩架构
它会分别监控Prefill实例的请求队列长度和Decode实例的GPU利用率、KV Cache占用等指标,然后进行独立的扩缩容决策。例如,当Prefill请求队列积压时,自动扩展Prefill实例;当Decode成为瓶颈时,则精准扩容Decode实例。这种面向角色的精细化伸缩,确保了资源的高效利用。
ModelBooster:极简一站式部署能力
ModelBooster提供了对用户最友好的极简入口,旨在简化部署流程。
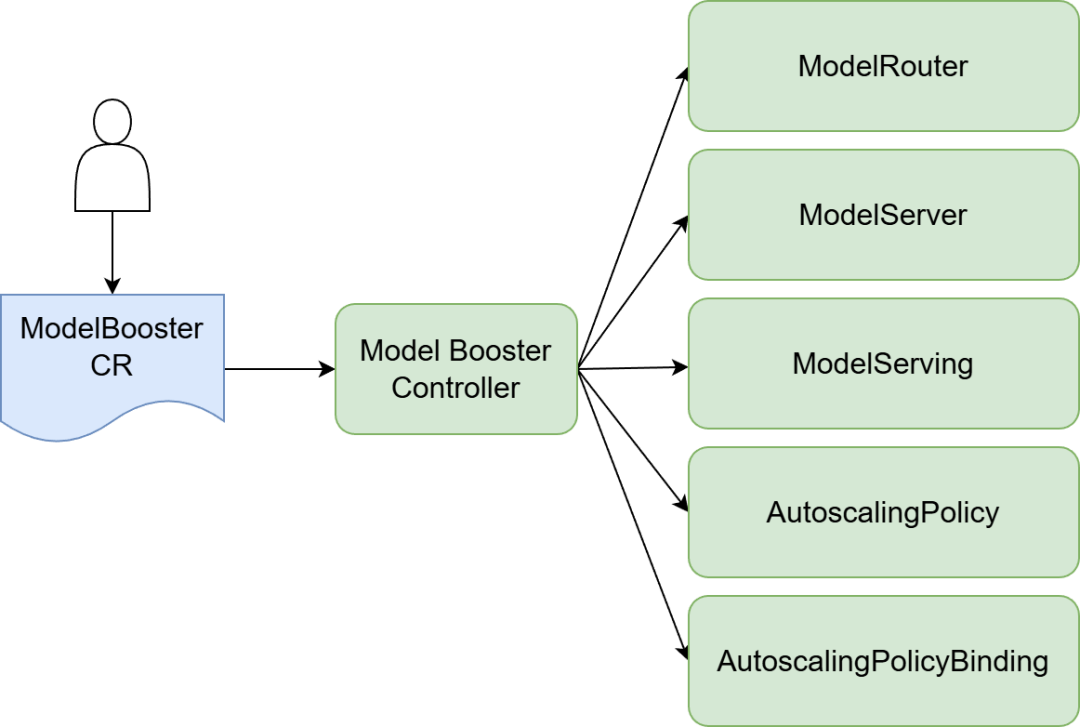
ModelBooster一站式部署
在传统方案中,部署一个推理服务需要创建多个Kubernetes资源。ModelBooster则允许用户只关心核心的模型信息,剩下的资源创建与配置管理工作全部由其自动完成,极大降低了运维复杂度。
与Volcano的深度集成:多级拓扑感知与原子化调度
Kthena声明式编排能力的落地,深度依赖于Volcano调度器的两大核心能力:
- 多级网络拓扑感知:Volcano引入了HyperNode自定义资源(CRD),将物理数据中心的机架、ToR交换机抽象为标准调度资源。这使得调度器能够将强通信依赖的推理实例“锁定”在同一个ToR交换机或机架内,将网络延迟控制在极致的1-2微秒范围内。
- 原子化Gang调度:针对多Pod启动的“碎片化”问题,Volcano通过PodGroup机制,将分布式推理集群内的所有Prefill与Decode实例视为一个统一实体。调度器严格保障全组实例同时获取资源并启动,彻底杜绝了因资源不足导致的“部分启动”和死锁风险。
实践:基于 vLLM-Ascend 的生产部署
以国产化算力生态为例,基于vLLM-Ascend引擎,Kthena大幅降低了在昇腾(Ascend)芯片上部署复杂模型的工程门槛。
vLLM-Ascend:让 vLLM 在 Ascend 无缝运行
vLLM-Ascend的安装非常简便,通过pip即可快速完成环境准备:
pip install vllm==0.13.0 vllm-ascend==0.13.0
同时,也支持通过容器一键拉取预构建镜像:
quay.io/ascend/vllm-ascend:latest
项目已在GitHub开源 (https://github.com/vllm-project/vllm-ascend)。核心基准测试表明,vLLM-Ascend能够充分发挥Ascend芯片的硬件性能。
vLLM-Ascend + Kthena 生产级架构
下图清晰地展示了vLLM-Ascend与Kthena结合的生产级分层架构:
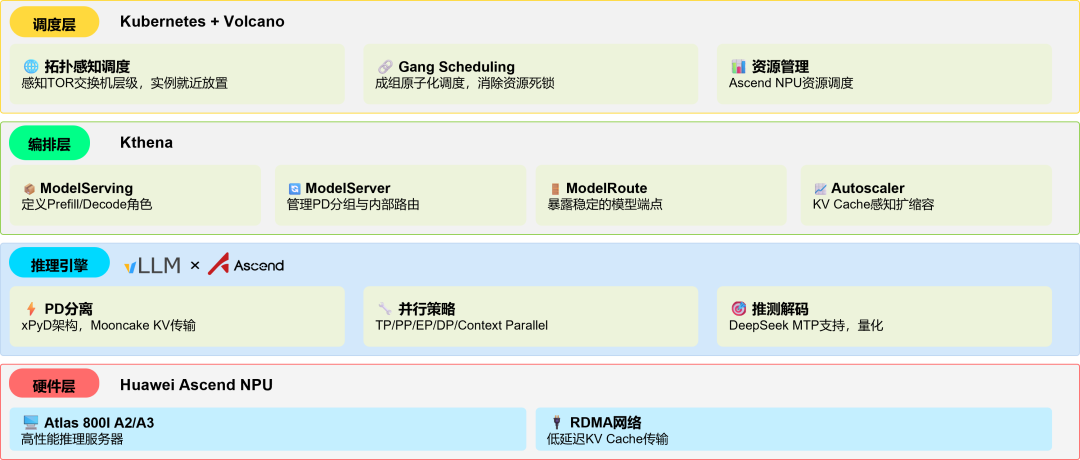
vLLM-Ascend + Kthena 生产级架构
整个架构职责清晰:基础设施层提供Kubernetes集群与Volcano调度器;Kthena核心组件层(Controller, Router, Autoscaler)负责编排与路由;最上层的推理引擎层则由vLLM-Ascend实例承载实际计算。
Qwen3-235B 双机推理部署案例
以Qwen3-235B模型的双机推理部署为例(16卡×2机),部署过程简洁明了,体现了声明式编排的优势:
- 创建启动脚本ConfigMap(包含模型路径、并行度等配置):
kubectl apply -f config.yaml -n vllm-project
- 创建ModelServing工作负载(包含推理Pod模板):
kubectl apply -f model_server.yaml -n vllm-project
- 创建ModelServer和ModelRoute(即路由层):
kubectl apply -f router.yaml -n vllm-project
用户只需准备好声明式配置文件并执行几条kubectl apply命令,即可完成复杂的分布式大模型服务部署,相比手动创建数十个资源的方式,运维效率得到质的提升。
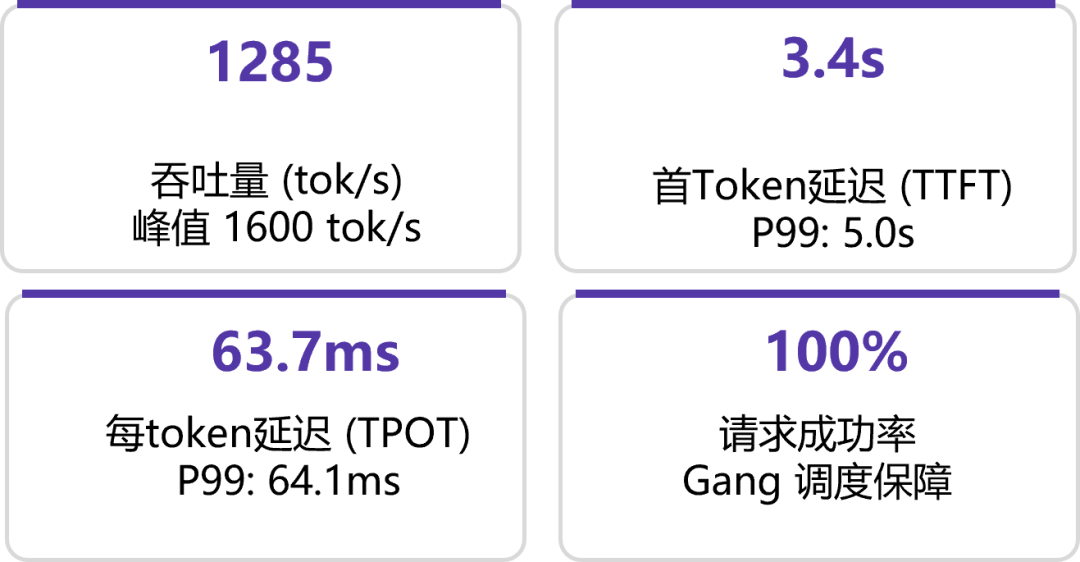
Qwen3-235B 双机推理部署性能
总结与展望
通过对Kthena核心组件及其与Volcano调度器协同机制的深入分析,我们可以看到,Kthena并非简单地将LLM推理任务包装成Kubernetes作业,而是构建了一套完整的、面向生产的工程范式。它成功地将分布式大模型推理这一复杂的“黑盒”应用,逐步转化为一门可声明、可预测、可扩展的标准化 云原生 工程。
Kthena的实践表明,未来的大模型推理平台必然建立在成熟的云原生技术栈之上。通过扩展Kubernetes的API和调度能力,能够优雅地解决许多初始设计时未曾预料到的复杂问题。
展望未来,我们有望看到更多开箱即用的最佳实践被社区沉淀,例如针对不同模型架构的专用调度策略、更智能的缓存替换算法,以及与服务网格的深度集成等。Kthena正在成为工程师驾驭下一代AI负载的标准工具之一。对这类云原生AI工程化话题感兴趣的开发者,也可以在 云栈社区 找到更多相关的深度讨论与实践分享。
参考资料
- Kthena 官网: https://kthena.volcano.sh/
- Volcano GitHub: https://github.com/volcano-sh
- Kthena GitHub: https://github.com/volcano-sh/kthena/
 发表于 2026-3-25 23:53:06
|
查看: 132|
回复: 0
发表于 2026-3-25 23:53:06
|
查看: 132|
回复: 0
